











Die Gestaltung der Datenarchitektur für ein großskaliges Backend-System ist eine grundlegende Aufgabe, die die Haltbarkeit und Stabilität der gesamten Anwendung bestimmt. Ein Entity-Relationship-Diagramm, häufig abgekürzt als ERD, dient als Bauplan für diese Architektur. Es visualisiert die Struktur der Daten und definiert, wie verschiedene Informationsstücke innerhalb des Systems miteinander verbunden, verknüpft und interagieren. In einem Unternehmenskontext, in dem Datenkonsistenz, Integrität und Skalierbarkeit von entscheidender Bedeutung sind, ist die Einhaltung etablierter ERD-Standards nicht nur eine bewährte Praxis, sondern eine Notwendigkeit.
Ohne einen standardisierten Ansatz für die Datenmodellierung laufen Backend-Systeme Gefahr, instabil zu werden. Inkonsistente Namenskonventionen, mehrdeutige Beziehungen und mangelhafte Normalisierung können zu Leistungsbottlenecks, schwierigen Wartungszyklen und Datenkorruption führen. Dieser Leitfaden untersucht die entscheidenden Standards und Methodologien, die erforderlich sind, um robuste Datenbank-Schemata für komplexe Unternehmensumgebungen zu erstellen. Wir werden die zentralen Komponenten, Notationssysteme, Normalisierungsregeln und Governance-Strategien untersuchen, die professionelle Teams einsetzen, um sicherzustellen, dass ihre Datenebenen über die Zeit hinweg zuverlässig bleiben.
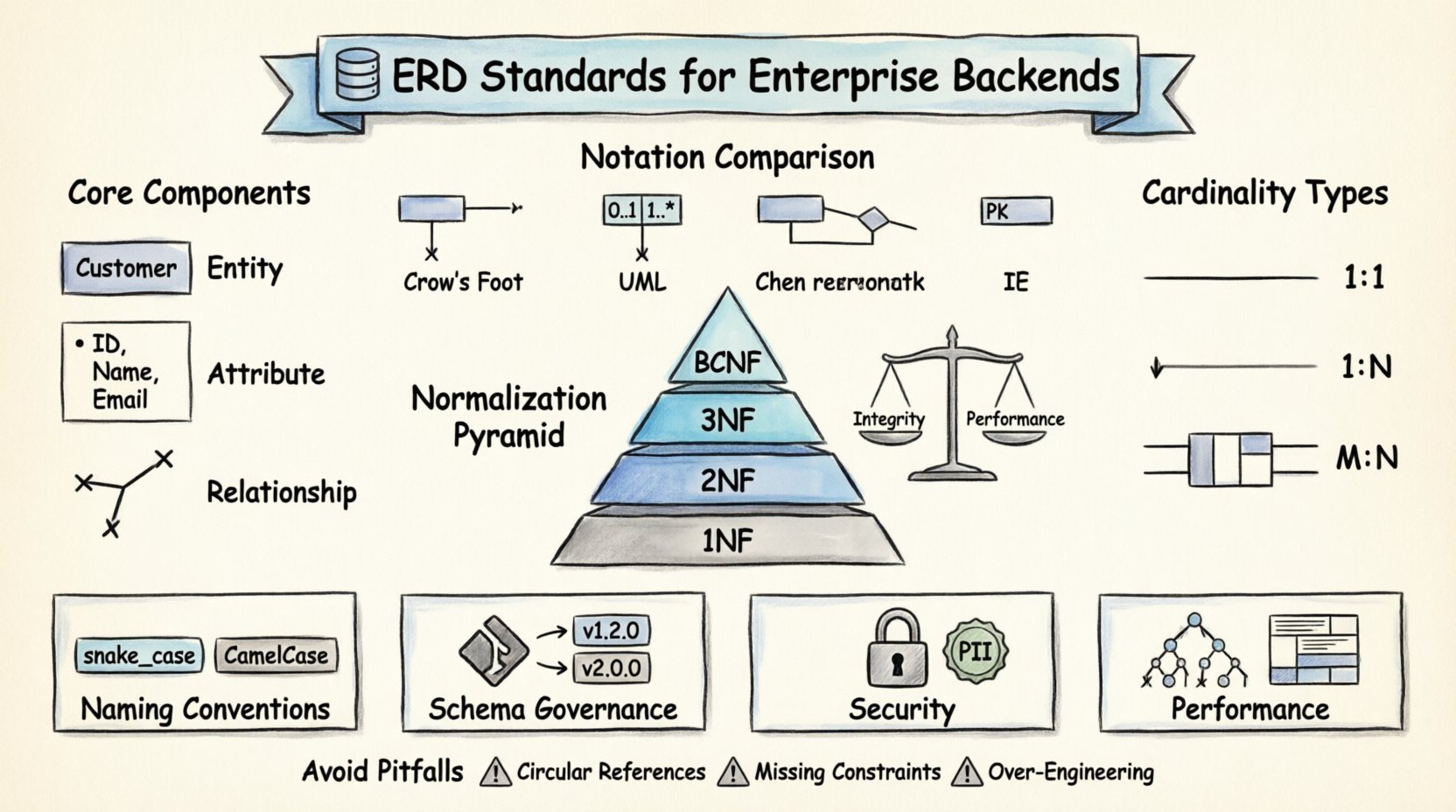
Kernkomponenten eines Enterprise-ERD 🧩
Bevor wir uns den spezifischen Standards zuwenden, ist es unerlässlich, die grundlegenden Bausteine zu verstehen, aus denen ein ERD besteht. Jedes Diagramm in einer professionellen Umgebung beruht auf drei Hauptelementen. Diese Elemente arbeiten zusammen, um die logische Struktur der Daten zu beschreiben.
- Entitäten: Diese stellen Gegenstände oder Konzepte der realen Welt dar, über die Daten gespeichert werden. Im Backend-Kontext entspricht eine Entität oft direkt einer Datenbanktabelle. Beispiele sindKunde, Bestellung, oderProdukt. Entitäten müssen eindeutig definiert sein, um sicherzustellen, dass jedes Datensatz eine eindeutige Identität besitzt.
- Attribute: Attribute beschreiben die spezifischen Eigenschaften oder Merkmale einer Entität. Sie entsprechen den Spalten innerhalb einer Tabelle. Für eineKundeEntität könnten Attribute wieKundenID, VollständigerName, undE-Mail-Adresse. Die korrekte Definition der Datentypen für Attribute ist entscheidend für die Datenintegrität.
- Beziehungen: Beziehungen definieren, wie Entitäten miteinander interagieren. Sie legen die Einschränkungen und Verknüpfungen zwischen Tabellen fest. Zum Beispiel kann ein einzelnerKunde mehrereBestellungen. Diese Beziehung bestimmt die Fremdschlüsselbeschränkungen und Join-Logik, die im Backend erforderlich sind.
In der Enterprise-Entwicklung sind diese Komponenten nicht nur abstrakte Konzepte; sie bilden die Grundlage für die Abfrageoptimierung, den Zugriffskontroll und Strategien für die Datenmigration. Ein gut dokumentiertes ERD ermöglicht es Entwicklern, den Datenfluss zu verstehen, ohne jede Zeile des Codes untersuchen zu müssen.
Notationsstandards und visuelle Konventionen 📐
Es gibt keine einheitliche universelle Syntax zum Zeichnen von ERDs, aber es gibt weit verbreitete Standards, die Klarheit und Konsistenz über verschiedene Teams hinweg gewährleisten. Die Wahl einer Notation und die Einhaltung dieser ist eine entscheidende Governance-Entscheidung.
Chen-Notation im Vergleich zu Crow’s Foot
Historisch gesehen war die Chen-Notation der Standard, wobei Rechtecke für Entitäten und Rauten für Beziehungen verwendet wurden. Obwohl sie klar ist, wird sie in modernen Softwareentwicklungstools weniger häufig verwendet. Die Crow’s-Foot-Notation hat sich aus mehreren Gründen als Branchenstandard etabliert:
- Klarheit in der Kardinalität: Sie verwendet spezifische Symbole (Linien, Kreise und „Füße“), um ein-zu-eins-, ein-zu-viele- und viele-zu-viele-Beziehungen visuell darzustellen.
- Toolunterstützung: Die meisten modernen Datenbank-Design-Tools und Reverse-Engineering-Tools unterstützen Crow’s Foot oder UML-abgeleitete Symbole natively.
- Lesbarkeit: Sie ist im Allgemeinen kompakter und leichter lesbar, wenn es um komplexe, miteinander verbundene Schemata geht.
Vergleich von Notationssystemen
| Notationsstil | Darstellung von Entitäten | Darstellung von Beziehungen | Beste Anwendungssituation |
|---|---|---|---|
| Crow’s Foot | Rechteck | Linien mit Symbolen (Crow’s Foot, Kreis, Linie) | Relationales Datenbankdesign |
| UML-Klassendiagramm | Klassenkasten mit Fachern | Pfeile mit Vielfachheiten (0..1, 1..*) | Objektorientierte Modellierung |
| Chen | Rechteck | Raute, die Entitäten verbindet | Akademische/theoretische Modelle |
| IE (Informationstechnik) | Rechteck mit Attributen | Linien mit Indikatoren für Primärschlüssel | Dokumentation veralteter Systeme |
Für Unternehmens-Backends wird die Crow’s-Foot-Notation im Allgemeinen empfohlen, da sie direkt auf relationale Einschränkungen abgebildet wird. Sie minimiert die Mehrdeutigkeit, wenn Entwickler das Diagramm während der Implementierung interpretieren.
Normalisierung: Sicherstellung der Datenintegrität 🔄
Die Normalisierung ist der Prozess der Organisation von Daten in einer Datenbank, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Obwohl moderne Systeme manchmal zur Leistungssteigerung die Normalisierung aufheben, ist das Verständnis der Normalisierungsregeln entscheidend für die Gestaltung einer soliden Ausgangsschema.
Die Normalformen
- Erste Normalform (1NF):Jede Spalte muss atomare Werte enthalten. Listen von Werten in einer einzigen Zelle sind verboten. Dadurch wird sichergestellt, dass jeder Schnittpunkt aus Zeile und Spalte einen einzelnen, unteilbaren Datenbestand enthält.
- Zweite Normalform (2NF):Die Tabelle muss sich in 1NF befinden, und alle nichtschlüsselbasierten Attribute müssen vollständig vom Primärschlüssel abhängen. Dies verhindert partielle Abhängigkeiten, bei denen eine Spalte nur von einem Teil eines zusammengesetzten Schlüssels abhängt.
- Dritte Normalform (3NF):Die Tabelle muss sich in 2NF befinden, und es dürfen keine transitiven Abhängigkeiten bestehen. Nichtschlüsselattribute sollten nicht von anderen nichtschlüsselbasierten Attributen abhängen. Zum Beispiel, wenn Stadt abhängt von PLZ, und PLZ abhängt von ID, Stadtsollte in eine separate Tabelle verschoben werden.
- Boyce-Codd-Normalform (BCNF):Eine strengere Version der 3NF. Es wird verlangt, dass für jede funktionale Abhängigkeit X → Y, X eine Superkey sein muss. Dies behandelt bestimmte Sonderfälle in der 3NF, bei denen ein Determinant ein Kandidatenschlüssel, aber kein Primärschlüssel ist.
Normalisierungs-Kompromisse
| Ebene | Vorteil | Kosten |
|---|---|---|
| Hohe Normalisierung (3NF/BCNF) | Minimale Redundanz, hohe Integrität | Mehr Joins sind für Abfragen erforderlich |
| Niedrige Normalisierung (Denormalisiert) | Schneller Leseleistung | Höheres Risiko von Dateninkonsistenzen |
Unternehmenssysteme zielen typischerweise auf 3NF in ihren transaktionalen Schemata ab. Wenn die Leseleistung zu einer Engstelle wird, wird die Denormalisierung gezielt auf bestimmte Ansichten oder Berichtstabellen angewendet, anstatt das zentrale transaktionale Schema zu verändern.
Namenskonventionen und Schema-Hygiene 🏷️
Eine konsistente Namenskonvention ist für die Wartbarkeit entscheidend. Wenn mehrere Teams am selben Backend arbeiten, führt Unsicherheit in der Namensgebung zu Fehlern. Ein Standard sollte dokumentiert und über Linting-Tools oder Schemavalidierungs-Skripte durchgesetzt werden.
Regeln für Tabellennamen
- Plural versus Singular: Es gibt eine Debatte, aber Konsistenz ist entscheidend. Plural-Bezeichnungen (z. B. Benutzer, Bestellungen) lesen sich in englischen Sätzen oft besser. Singular-Bezeichnungen (z. B. Benutzer, Bestellung) werden oft in objektorientierten Kontexten bevorzugt. Wählen Sie eine Variante und wenden Sie sie global an.
- Unterstriche versus CamelCase: Unterstriche (snake_case) sind Standard für SQL-Bezeichner. CamelCase (camelCase) ist im Anwendungscode üblich. Stellen Sie sicher, dass die Datenbank- und die Anwendungsschicht sich auf die Übersetzungsstrategie einigen.
- Vermeiden Sie reservierte Schlüsselwörter: Benennen Sie niemals eine Tabelle oder Spalte mit reservierten Datenbankschlüsselwörtern (z. B. Gruppe, Auswählen, Bestellung). Dies verhindert Syntaxfehler während der Abfrageerzeugung.
- Präfixe für Metadaten: Verwenden Sie Präfixe wie _audit, _log, oder _temp um Hilfstabellen von zentralen Geschäftsentitäten zu unterscheiden.
Benennungsregeln für Spalten
- Fremdschlüssel: Geben Sie die Beziehung deutlich an. Wenn eine Spalte auf die Tabelle Benutzer verweist, benennen Sie sie als benutzer_id anstatt benutzer_id oder fk_benutzer.
- Boolesche Flags: Verwenden Sie Präfixe wie ist_ oder hat_. Zum Beispiel ist_aktiv oder hat_abonnement.
- Datums- und Zeitfelder: Geben Sie den Bereich an. Verwenden Sie erstellt_am oder aktualisiert_am anstelle von generischen Datum oder Uhrzeit.
Beziehungen und Kardinalität 🔄
Das Verständnis der Kardinalität ist der Unterschied zwischen einer funktionierenden Datenbank und einer defekten. Die Kardinalität definiert die genaue Anzahl an Instanzen einer Entität, die mit jeder Instanz einer anderen Entität assoziiert sein können oder müssen.
Arten von Beziehungen
- Ein-zu-Eins (1:1): Eine Instanz der Entität A ist genau mit einer Instanz der Entität B verbunden. Dies ist im Kerngeschäftslogik selten, aber bei Sicherheits- oder Konfigurationsdaten üblich. Beispiel: Ein Benutzer hat ein Profil.
- Ein-zu-Viele (1:N): Eine Instanz der Entität A ist mit vielen Instanzen der Entität B verbunden. Dies ist die häufigste Beziehung. Beispiel: Eine Abteilung hat viele Mitarbeiter.
- Viele-zu-Viele (M:N): Viele Instanzen der Entität A sind mit vielen Instanzen der Entität B verbunden. Dazu ist eine Verbindungstabelle (assoziative Entität) erforderlich. Beispiel: Studenten und Kurse.
Optionale und Einschränkungen
Die Kardinalität erzählt nicht die ganze Geschichte; die Optionale tut es. Dies bezieht sich darauf, ob die Beziehung obligatorisch oder optional ist.
- Pflicht (Pflichtteilnahme): Eine Entitätsinstanz müssen mit einer anderen verknüpft sein. Zum Beispiel muss eine Bestellung müssen eine Kunde.
- Optional (Optionale Teilnahme): Eine Entitätsinstanz kann ohne eine Beziehung existieren. Zum Beispiel kann ein Produkt ohne eine BestellungAufzeichnung noch existieren.
Die Durchsetzung dieser Regeln auf Datenbankebene mithilfe von Einschränkungen (NOT NULL, Fremdschlüssel) ist weitaus zuverlässiger als die Durchsetzung im Anwendungscode. Sie schützt vor Datenverschiebung und stellt sicher, dass das Schema die Quelle der Wahrheit bleibt.
Schema-Governance und Versionskontrolle 📜
In Unternehmensumgebungen ist das Datenbankschema Code. Es muss versioniert, überprüft und mit derselben Sorgfalt verwaltet werden wie der Anwendungsquellcode. Ein ERD ist kein statisches Dokument; er entwickelt sich weiter, je nachdem, wie sich die geschäftlichen Anforderungen ändern.
Migrationsstrategien
- Vorwärtskompatibilität: Änderungen sollten so gestaltet werden, dass sie alten Daten Rechnung tragen. Vermeiden Sie das sofortige Löschen von Spalten; markieren Sie sie stattdessen als veraltet.
- Rückwärtskompatibilität: Neue Schema-Versionen sollten bestehende Abfragen nicht brechen. Verwenden Sie Ansichten, um Änderungen von der Anwendungsebene abzukapseln.
- Atomare Änderungen: Jeder Migrations-Skript sollte eine einzelne logische Änderung darstellen. Dies erleichtert die Rückgängigmachung, falls ein Fehler auftritt.
Dokumentationspflege
Ein ERD, der nicht aktualisiert wird, ist eine Gefahr. Stellen Sie sicher, dass der Prozess zur Diagrammerstellung automatisiert ist. Idealerweise sollte der ERD direkt aus den Schema-Definitionen (DML) generiert werden, um eine Abweichung zwischen der Dokumentation und dem tatsächlichen Datenbankzustand zu vermeiden.
- Automatisieren Sie die ERD-Generierung bei jedem Commit.
- Fordern Sie eine Schema-Überprüfung im Pull-Request-Prozess an.
- Markieren Sie wichtige Schema-Versionen, um sie mit Anwendungsreleases zu verknüpfen.
Sicherheits- und Datenschutzüberlegungen 🔒
Unternehmensweite Backends verarbeiten sensible Informationen. Die Phase der ERD-Entwicklung muss Sicherheits- und Datenschutzanforderungen berücksichtigen, insbesondere im Hinblick auf personenbezogene Daten (PII).
Datenklassifizierung
- Öffentliche Daten:Informationen, die offen geteilt werden können. Keine besondere Behandlung erforderlich.
- Interne Daten:Informationen ausschließlich für Mitarbeiter. Zugriffssteuerungslisten (ACLs) sollten berücksichtigt werden.
- Eingeschränkte Daten:Sensible Daten wie Passwörter, Gesundheitsakten oder Finanzdetails. Diese Felder erfordern Verschlüsselung im Ruhezustand und während der Übertragung.
Maskierung und Anonymisierung
Markieren Sie im ERD Felder, die in Nicht-Produktionsumgebungen maskiert werden müssen. Dies hilft Entwicklern zu verstehen, welche Spalten während des Testens besondere Behandlung erfordern. Obwohl das Diagramm selbst keine Sicherheit erzwingt, leitet es die Umsetzung von Sicherheitsrichtlinien an.
- Identifizieren Sie Spalten, die PII enthalten, ausdrücklich.
- Definieren Sie Auditspalten (z. B. letzter_bearbeiter) zur Verfolgung, wer auf Daten zugegriffen oder diese geändert hat.
- Stellen Sie sicher, dass Fremdschlüssel keine internen IDs preisgeben, die enumeriert werden könnten.
Leistungs- und Skalierbarkeitsplanung 🚀
Während der ERD sich auf die Struktur konzentriert, muss er auch die Leistung berücksichtigen. Ein Schema, das logisch korrekt ist, aber physisch langsam, wird unter Last versagen.
Indizierungsstrategie
Die in der ERD definierten Beziehungen bestimmen, wo Indizes benötigt werden. Fremdschlüssel sollten indiziert werden, um Joins und Constraint-Prüfungen zu beschleunigen. Eine Überindizierung kann jedoch die Schreiboperationen verlangsamen.
- Primärschlüssel: Immer indiziert.
- Fremdschlüssel: Immer indiziert, um die Join-Leistung zu verbessern.
- Suchspalten: Spalten, die häufig in WHERE-Klauseln verwendet werden, sollten Indizes haben.
Partitionierung und Sharding
Für massive Datensätze könnte das ERD Hinweise auf Partitionierungsstrategien geben. Wenn Daten natürlicherweise gruppiert sind (z. B. nach Region oder Datum), sollte dies in der Schema-Design widergespiegelt werden. Dadurch kann die Datenbank die Last auf mehrere physische Knoten verteilen.
Häufige Fehler, die vermieden werden sollten ⚠️
Auch erfahrene Teams begehen Fehler. Das Erkennen häufiger Fehlermuster hilft dabei, ein widerstandsfähiges System zu entwickeln.
- Zirkuläre Referenzen: Vermeiden Sie Beziehungen, bei denen Entity A von B abhängt und B von A abhängt, was eine Schleife erzeugt, die die Löschung oder Aktualisierung von Daten erschwert.
- Fehlende Einschränkungen: Die Abhängigkeit von Anwendungscode zur Durchsetzung von Regeln (z. B. sicherstellen, dass eine Preis positiv ist) ist riskant. Verwenden Sie CHECK-Einschränkungen in der Datenbank.
- Überdimensionierung: Modellieren Sie nicht jedes mögliche zukünftige Szenario. Gestalten Sie die Lösung für die aktuellen Anforderungen mit ausreichender Flexibilität, um sich anzupassen, vermeiden Sie jedoch die Erstellung von Tabellen für hypothetische Anwendungsfälle.
- Hartkodierte Werte: Vermeiden Sie das Speichern von Statuscodes als Ganzzahlen ohne eine Abfrage-Tabelle. Verwenden Sie eine Referenztabelle für Status wie Bestellstatus um Klarheit zu gewährleisten.
Implementierung von Standards in Ihrem Arbeitsablauf 🛠️
Die Einführung dieser Standards erfordert eine Veränderung der Kultur. Es reicht nicht aus, einfach ein Diagramm zu zeichnen; das Diagramm muss den Entwicklungsprozess vorantreiben.
- Zuerst Design: Fordern Sie die Genehmigung des ERD an, bevor Sie Migrationsskripte schreiben.
- Code-Reviews: Fügen Sie Schema-Änderungen in die Standard-Checkliste für Code-Reviews ein.
- Schulung: Stellen Sie sicher, dass alle Backend-Entwickler die Konzepte der Normalisierung und Kardinalität verstehen.
- Werkzeuge: Investieren Sie in Schema-Design-Tools, die Zusammenarbeit und Versionsverwaltung unterstützen.
Indem man das Entity-Relationship-Diagramm als lebendiges, atmendes Element der Systemarchitektur behandelt, können Unternehmens-Teams sicherstellen, dass ihre Datenebenen stabil bleiben. Die in der Standardisierung der Entwurfsphase gesteckten Anstrengungen zahlen sich in Form reduzierten technischen Schulden und verbesserter Systemzuverlässigkeit aus. Eine gut strukturierte Datenbank ist die Grundlage, auf der skalierbare Anwendungen aufgebaut werden.
Wenn Sie Klarheit, Konsistenz und Integrität in Ihrer Datenmodellierung priorisieren, schaffen Sie eine Grundlage, die Wachstum unterstützt. Die hier aufgeführten Standards bieten einen Rahmen für diese Grundlage. Ihre Einhaltung stellt sicher, dass Ihr Backend auch bei der Skalierung Ihrer Organisation wartbar, sicher und effizient bleibt.