











In der Welt der Softwarearchitektur haben wenige Konzepte so viel Gewicht wie das Entitäts-Beziehungs-Diagramm (ERD). Es ist der Bauplan Ihrer Daten, die Karte, die Entwickler durch das komplexe Gelände von Tabellen, Schlüsseln und Beziehungen führt. Wenn eine Anwendung langsam reagiert, ist die erste Reaktion oft, die Schema-Struktur zu beschuldigen. Die Annahme ist klar: Wenn das Diagramm perfekt ist, muss die Leistung perfekt sein.
Dies ist eine verbreitete Verwechslung. 🧐 Obwohl ein gut gestaltetes ERD grundlegend ist, ist es kein Allheilmittel für Geschwindigkeit. Ein fehlerfreies logisches Modell übersetzt sich nicht automatisch in eine schnelle physische Ausführung. Das Verständnis der Lücke zwischen Gestaltungstheorie und Laufzeitrealität ist entscheidend, um Systeme zu bauen, die auch unter Druck reaktionsschnell bleiben.
Diese Anleitung untersucht, warum ein perfektes ERD keine schnellen Antwortzeiten garantiert, und welche anderen entscheidenden Faktoren die Datenbankleistung beeinflussen. Wir werden die Ebenen der Datenverarbeitung von Speicher-Engines bis hin zu Netzwerk-Latenz analysieren, um die eigentlichen Treiber der Anwendungs-Geschwindigkeit aufzudecken.
📐 Verständnis des Entitäts-Beziehungs-Diagramms
Bevor wir uns mit Leistungsmetriken beschäftigen, müssen wir klären, was ein ERD eigentlich darstellt. Ein ERD ist ein logisches Artefakt. Es beschreibt wasDaten existieren und wiesie sich zu anderen Daten verhalten. Es definiert Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel).
- Entitäten:Weltliche Objekte, dargestellt als Tabellen.
- Attribute:Eigenschaften dieser Objekte, gespeichert in Spalten.
- Beziehungen:Die Verbindungen zwischen Entitäten, die oft über Primär- und Fremdschlüssel durchgesetzt werden.
- Kardinalität:Die numerische Beziehung zwischen Entitäten (eins-zu-eins, eins-zu-viele).
Das primäre Ziel eines ERD ist die Datenintegrität. Er stellt sicher, dass Daten über die Zeit hinweg konsistent, genau und nutzbar bleiben. Er verhindert verwaiste Datensätze und gewährleistet die Referenzintegrität. Doch Integrität ist nicht dasselbe wie Geschwindigkeit. Ein Schloss, das eine Tür verschließt, schützt den Inhalt, macht die Tür aber nicht schneller auf.
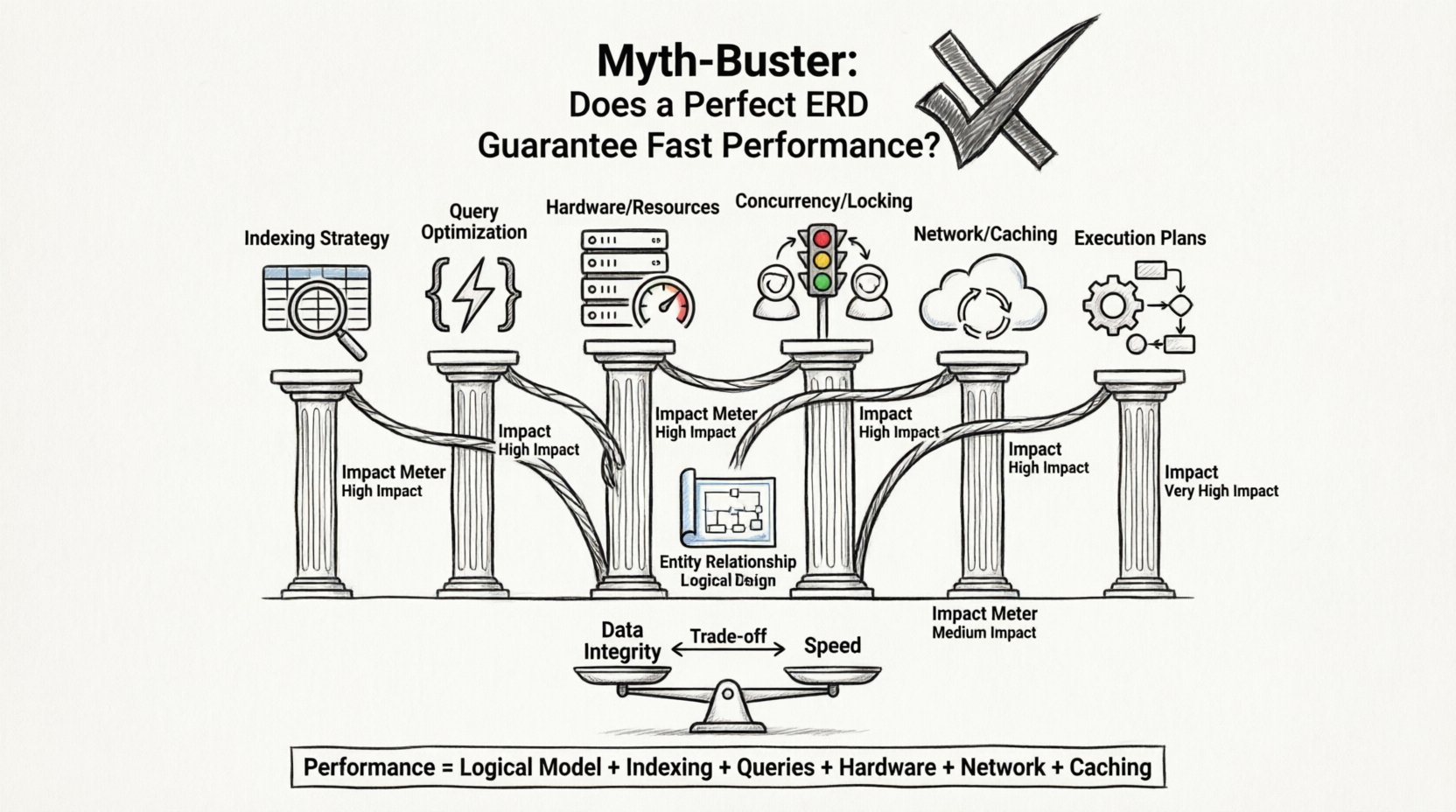
⚡ Die Leistungs-Gleichung: Jenseits des Schemas
Die Antwortzeit der Anwendung ist die Summe vieler Komponenten. Die Datenbank ist nur ein Teil dieser Gleichung. Selbst wenn die Datenbank-Engine Daten sofort abruft, kann die Anwendung dennoch langsam wirken, weil an anderer Stelle Engpässe auftreten.
Hier sind die entscheidenden Faktoren, die die Geschwindigkeit beeinflussen, die oft das Schema-Design überstrahlen:
1. Indexstrategie
Ein ERD definiert Primärschlüssel und Fremdschlüssel, die oft automatisch Indizes erzeugen. Diese Standardindizes sind jedoch selten ausreichend für komplexe Abfragen. Die Leistung hängt stark von sekundären Indizes ab, die spezifischen Abfrage-Mustern angepasst sind.
- Fehlende Indizes:Ohne einen Index in einer häufig gefilterten Spalte muss die Datenbank eine vollständige Tabellen-Suche durchführen. Dabei werden alle Zeilen gelesen, was bei großen Datensätzen exponentiell langsamer ist.
- Index-Aufwand:Zu viele Indizes verlangsamen Schreibvorgänge. Jeder Einfüge- oder Aktualisierungsvorgang erfordert die Aktualisierung jedes Index, der mit dieser Tabelle verknüpft ist.
- Selektivität:Ein Index in einer Spalte mit geringer Selektivität (z. B. Geschlecht oder Status) kann vom Abfrage-Optimierer ignoriert werden.
2. Abfrageoptimierung
Die Art und Weise, wie Daten abgerufen werden, ist wichtiger als die Art und Weise, wie sie gespeichert werden. Eine schlecht geschriebene Abfrage kann ein perfektes Schema lahmlegen. Häufige Probleme sind:
- N+1-Probleme:Abrufen eines übergeordneten Datensatzes und anschließendes Durchlaufen, um die untergeordneten Datensätze einzeln abzurufen. Dies erzeugt mehrere Rundreisen zur Datenbank anstelle eines einzigen JOINs.
- Verwendung von SELECT *:Das Abrufen aller Spalten erhöht den Netzwerkverkehr und den Speicherverbrauch, selbst wenn nur eine benötigt wird.
- Implizite Umwandlungen:Der Vergleich einer Zeichenkette mit einer Zahl oder eines Datums mit einem Zeitstempel kann die Verwendung von Indizes verhindern.
- Komplexe JOINs:Das Verknüpfen mehrerer großer Tabellen ohne angemessene Filterung erhöht die Rechenlast erheblich.
3. Hardware und Infrastruktur
Die Effizienz der Software kann physische Grenzen nicht überwinden. Die zugrundeliegende Hardware bestimmt die Obergrenze für die Leistung.
- Speichertyp:Solid-State-Laufwerke (SSDs) sind für zufällige I/O-Operationen deutlich schneller als Festplattenlaufwerke (HDDs).
- Speicher (RAM):Wenn die Arbeitsmenge an Daten in den RAM passt, sind Abfragen nahezu sofortig. Wenn Daten von der Festplatte abgerufen werden müssen, steigt die Latenz.
- CPU-Leistung:Komplexe Berechnungen, Sortierungen und Aggregationen erfordern Verarbeitungsleistung.
- Netzwerklatenz:Der Abstand zwischen dem Anwendungsserver und dem Datenbankserver fügt jeder Anfrage Millisekunden hinzu.
4. Concurrentie und Sperren
Wenn mehrere Benutzer gleichzeitig auf das System zugreifen, muss die Datenbank Konflikte verwalten. Genau hier verschlechtert sich die Leistung oft.
- Sperrkonflikte:Wenn eine Transaktion eine Sperre für eine Zeile hält, müssen andere warten. Hohe Konflikte führen zu Zeitüberschreitungen und langsamen Antwortzeiten.
- Totalsperren:Zwei Transaktionen, die aufeinander warten, können eine systemweite Blockade verursachen.
- Isolationsstufen:Höhere Isolationsstufen (z. B. serialisierbar) bieten stärkere Garantien, reduzieren aber die Konkurrenzfähigkeit und Geschwindigkeit.
📊 Einfluss des ERD im Vergleich zu anderen Leistungsaspekten
Um den Einfluss des ERD im Vergleich zu anderen Variablen zu visualisieren, betrachten Sie die folgende Aufteilung. Diese Tabelle zeigt, wo der ERD Wert schafft und wo er versagt.
| Faktor | Einfluss auf Lese-Geschwindigkeit | Einfluss auf Schreib-Geschwindigkeit | Rolle des ERD |
|---|---|---|---|
| Tabellen-Schema-Struktur | Mittel | Mittel | Definiert Beziehungen und Normalisierung. |
| Indizierung | Hoch | Niedrig | ERD definiert Schlüssel, aber nicht alle Indizes. |
| Abfrage-Logik | Sehr hoch | Mittel | ERD legt keine Abfrage-Syntax fest. |
| Hardware-Ressourcen | Hoch | Hoch | Keine. Unabhängig vom Schema. |
| Netzwerk-Latenz | Hoch | Mittel | Keine. Unabhängig vom Schema. |
| Verbindungspooling | Mittel | Mittel | Keine. Anwendungskonfiguration. |
🧱 Der Kompromiss bei der Normalisierung
Ein der am meisten diskutierten Themen im Datenbankdesign ist die Normalisierung. Der ERD zielt typischerweise auf die Dritte Normalform (3NF) ab, um Redundanz zu reduzieren. Während dies Platz spart und Konsistenz gewährleistet, kann es die Leistung beeinträchtigen.
Wenn Daten stark normalisiert sind, wird ein einzelner Informationsbestand an einer Stelle gespeichert. Um ihn abzurufen, muss das System mehrere JOINs durchlaufen. Jeder JOIN fügt rechnerischen Overhead hinzu.
Betrachten Sie eine Situation, in der Sie das Profil eines Benutzers zusammen mit seiner letzten Bestellung und den Produktdetails anzeigen müssen. In einem normalisierten ERD könnte dies das Verknüpfen von vier Tabellen erfordern. Wenn diese Tabellen groß sind, verbringt die CPU erhebliche Zeit mit Sortieren und Abgleichen von Zeilen.
Deknormalisierung ist eine Technik, die eingesetzt wird, um dies zu kompensieren. Sie beinhaltet die Duplizierung von Daten, um die Notwendigkeit von JOINs zu reduzieren. Dies verbessert die Leseleistung, hat aber die Komplikationen bei Schreibvorgängen und das Risiko von Dateninkonsistenzen zur Folge. Ein perfektes ERD entscheidet nicht automatisch, wo diese Grenze gezogen werden soll. Es handelt sich um eine strategische Entscheidung, die auf dem Verhältnis von Lese- zu Schreiboperationen basiert.
🔍 Tiefgang: Abfrage-Ausführungspläne
Die Datenbankengine führt Abfragen nicht genau so aus, wie sie geschrieben wurden. Sie analysiert die Anforderung und generiert einen Ausführungsplan. Dieser Plan bestimmt die Reihenfolge der Operationen, welche Indizes verwendet werden sollen, und ob eine Suche oder eine vollständige Durchsuchung durchgeführt werden soll.
Ein ERD liefert Metadaten zu Datentypen und Einschränkungen. Der Optimierer verwendet jedoch Statistiken über die Datenverteilung, um Entscheidungen zu treffen. Wenn die Statistiken veraltet sind, könnte der Optimierer einen suboptimalen Plan wählen und die besten verfügbaren Indizes ignorieren.
Zum Beispiel könnte der Optimierer entscheiden, dass eine vollständige Durchsuchung billiger ist als ein Index-Suchvorgang, wenn eine Tabelle 10 Millionen Zeilen hat, die Statistiken aber nur 100 annehmen. Dies führt zu einer langsamen Leistung, trotz eines gut strukturierten ERDs.
🛡️ Datenintegrität gegenüber Geschwindigkeit
Es besteht eine inhärente Spannung zwischen der Gewährleistung von Datenintegrität und der Maximierung der Geschwindigkeit. Ein ERD setzt Integritätsregeln wie Einschränkungen und Trigger durch.
- Fremdschlüssel-Einschränkungen: Sorgen für die Referenzintegrität. Bei Lösch- oder Aktualisierungsvorgängen muss das System verwandte Tabellen überprüfen. Dies fügt Latenz bei Schreibvorgängen hinzu.
- Trigger: Automatisierte Skripte, die bei Datenänderungen ausgeführt werden. Obwohl sie für Logik nützlich sind, fügen sie jeder Transaktion Verarbeitungszeit hinzu.
- Einzigartige Einschränkungen: Erfordern, dass das System vorhandene Werte überprüft, bevor neue eingefügt werden.
In Systemen mit hoher Durchsatzrate werden diese Überprüfungen manchmal deaktiviert oder hinausgeschoben, um die Geschwindigkeit zu verbessern. Ein perfektes ERD enthält alle diese Regeln, aber ein hochleistungsfähiges System könnte einen modifizierten Ansatz erfordern.
🚦 Praktische Schritte zur Optimierung
Wenn Ihre Anwendung langsam ist, zeichnen Sie Ihr ERD nicht sofort neu. Folgen Sie einem systematischen Ansatz, um die Engstelle zu identifizieren.
1. Analysieren Sie langsame Abfragen
Aktivieren Sie die Abfrageprotokollierung, um langlaufende Anweisungen zu erfassen. Verwenden Sie Profiling-Tools, um zu sehen, wo die Zeit verbracht wird. Wartet es auf Sperren? Durchsucht es Zeilen? Verarbeitet es Logik?
2. Überprüfen Sie die Indextechnik
Überprüfen Sie, welche Indizes tatsächlich verwendet werden. Unbenutzte Indizes verbrauchen Speicherplatz und verlangsamen Schreibvorgänge. Erstellen Sie Indizes, die den WHERE- und JOIN-Klauseln Ihrer häufigen Abfragen entsprechen.
3. Optimieren Sie die Hardwarezuweisung
Stellen Sie sicher, dass der Datenbankserver ausreichend RAM hat, um den Arbeitsbereich zu cachen. Wenn die Datenbank hauptsächlich durch den Speicher begrenzt ist, führt der Zusatz von RAM zu sofortigen Ergebnissen. Wenn sie hauptsächlich durch die CPU begrenzt ist, müssen Sie möglicherweise den Prozessor aktualisieren oder den Code optimieren.
4. Implementieren Sie Caching
Nicht jeder Anfrage muss die Datenbank erreichen. Verwenden Sie einen Speicher im Arbeitsspeicher (wie Redis oder Memcached) für häufig abgerufene Daten. Dadurch wird die Datenbank bei Lesevorgängen vollständig umgangen.
5. Überwachen Sie die Konkurrenz
Achten Sie auf Sperrwartezustände. Wenn Benutzer Timeouts erleben, überprüfen Sie die Länge der Transaktionen. Halten Sie Transaktionen kurz, um Sperrungen schnell freizugeben.
🔄 Die Rolle der Schema-Evolution
Anwendungen ändern sich. Anforderungen verschieben sich. Das ERD muss sich mit dem Geschäft entwickeln. Ein Schema, das vor sechs Monaten perfekt war, kann heute veraltet sein, aufgrund neuer Funktionen oder erhöhter Datenmengen.
Migrationsstrategien sind wichtig. Das Verschieben von Daten von einer kleinen Tabelle zu einer großen partitionierten Tabelle kann die Leistung verbessern. Das Ändern von Datentypen vonVARCHAR zu INTkann Speicherplatz reduzieren und die Scangeschwindigkeit verbessern. Diese Entscheidungen werden nach der Erstellung des ursprünglichen ERD getroffen.
Statische ERDs berücksichtigen keine Datenwachstums. Wenn Daten skalieren, ändern sich die Leistungsmerkmale. Ein Design, das mit 10.000 Datensätzen funktionierte, könnte bei 10 Millionen versagen. Deshalb ist die Leistungsoptimierung ein fortlaufender Prozess, kein einmaliger Vorgang.
🧩 NoSQL-Überlegungen
Der Begriff eines ERD gilt am strengsten für relationale Datenbanken. In NoSQL-Umgebungen ist das Datenmodell anders. Dokumentenspeicher, Schlüssel-Wert-Speicher und Graphdatenbanken behandeln Beziehungen anders.
In einem Dokumentenspeicher könnten Daten eingebettet werden, um Joins zu vermeiden. Dies entspricht einer bewussten Denormalisierung. In einer Graphdatenbank sind Beziehungen Erstklassige Bürger, explizit gespeichert, um die Durchquerung zu optimieren.
Der Mythos der ERD-Garantie ist hier noch deutlicher ausgeprägt. In NoSQL ist das Schema oft flexibel oder dynamisch. Die Leistung hängt stark von den Zugriffsmustern ab, die im Anwendungscode definiert sind, und nicht von einem starren Diagramm.
🏁 Letzte Überlegungen zur Datenarchitektur
Ein schnelles Anwendungssystem erfordert einen ganzheitlichen Blick. Das ERD ist ein entscheidender Ausgangspunkt, der sicherstellt, dass die Daten logisch organisiert sind. Es verhindert Chaos und bewahrt die Integrität. Es ist jedoch nicht der Motor, der Geschwindigkeit erzeugt.
Leistung ist das Ergebnis einer Synergie zwischen:
- Ein solides logisches Modell.
- Strategisches Indexieren.
- Effizientes Abfragen.
- Adequate Hardware-Ressourcen.
- Richtige Netzwerkkonfiguration.
- Effektive Caching-Strategien.
Die Schuld am langsamen Antwortzeit auf das Schema zu schieben, ist ein Kurzschluss, der zu falschen Lösungen führt. Ein perfektes Diagramm auf Papier kann keine langsamen Festplatten, Netzwerk-Timeouts oder schlecht geschriebene Abfragen ausgleichen. Wirkliche Leistungsingenieurwesen erfordert, über den Bauplan hinauszusehen, hin zum eigentlichen Datenfluss.
Wenn Sie Ihr System auditieren, beginnen Sie mit dem ERD, um Korrektheit zu gewährleisten. Dann wechseln Sie zur Ausführungsplanung, um Effizienz zu gewährleisten. Schließlich bewerten Sie die Infrastruktur, um Kapazität zu gewährleisten. Erst durch die Berücksichtigung aller Ebenen können Sie die Reaktionsfähigkeit erreichen, die Benutzer erwarten.