











Die Gestaltung einer robusten Datenbankstruktur erfordert Präzision. Das Entität-Beziehungs-Diagramm (ERD) dient als Bauplan für diese Struktur und übersetzt komplexe Geschäftslogik in ein visuelles Format, das Entwickler und Stakeholder verstehen können. Dennoch werden ERDs trotz ihrer Nützlichkeit häufig zu Quellen von Missverständnissen während der Modellierungsphase. Mehrdeutigkeit bei Symbolen, falsche Interpretation der Kardinalität und Verwirrung bezüglich Attributtypen können zu erheblichem Nacharbeitungsbedarf im späteren Verlauf des Entwicklungszyklus führen.
Diese Anleitung bietet eine detaillierte Untersuchung der spezifischen Komponenten innerhalb eines ERDs, die häufig zu Spannungen zwischen Datenbankarchitekten und Ingenieuren führen. Durch die Klärung der Unterschiede zwischen starken und schwachen Entitäten, die Aufschlüsselung von Beziehungssymbolen und die Analyse von Attributklassifizierungen können wir Fehler reduzieren und sicherstellen, dass das resultierende Datenmodell die operativen Anforderungen genau widerspiegelt.
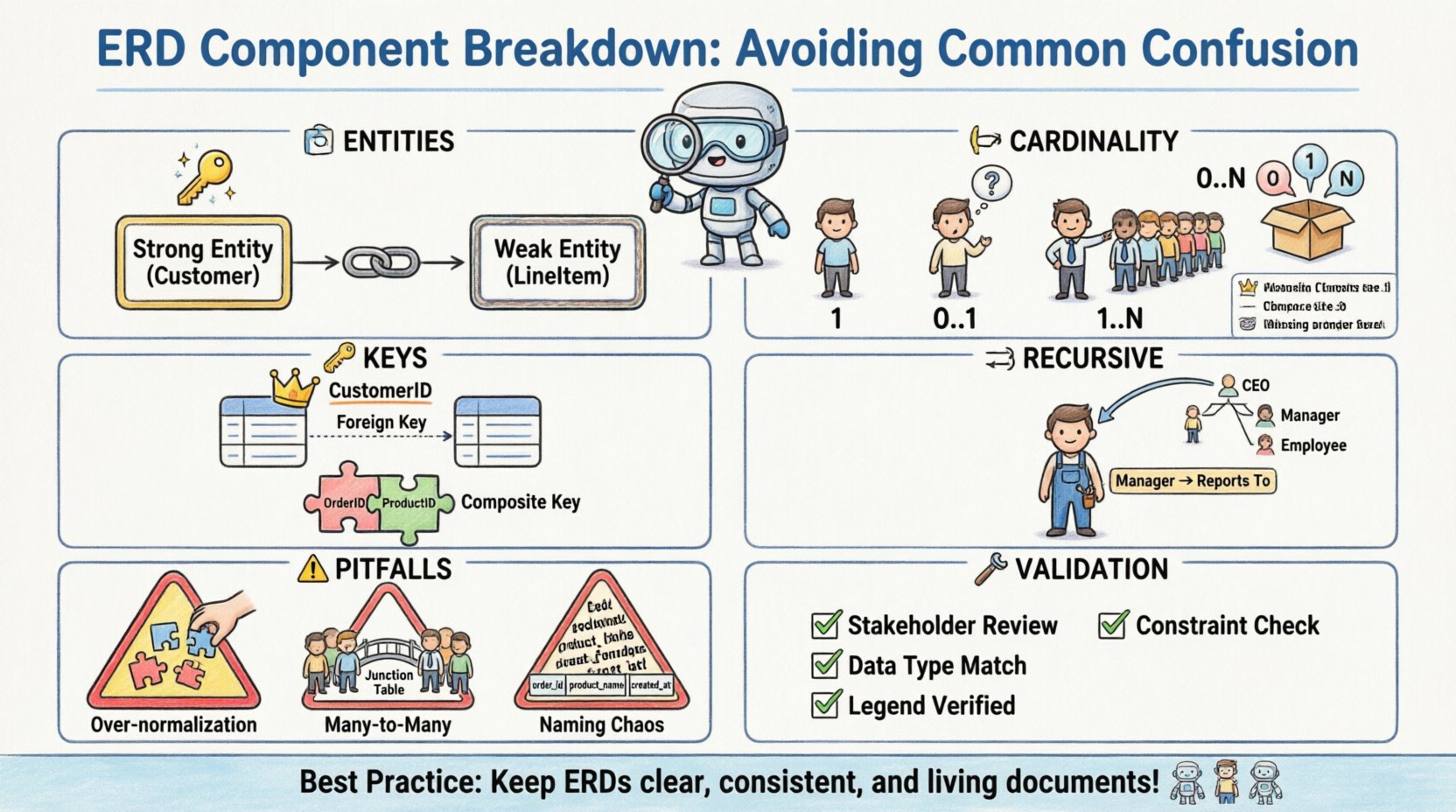
🏗️ Entitätstypen: Unterscheidung zwischen starken und schwachen
Im Kern jedes ERDs stehen Entitäten. Diese stellen die Objekte oder Konzepte dar, über die Daten gespeichert werden. Während die meisten Fachleute das Konzept einer Tabelle verstehen, entsteht an der Unterscheidung zwischen starken und schwachen Entitäten oft der erste große Verwirrungspunkt.
- Starke Entitäten: Diese Entitäten verfügen über einen eigenen Primärschlüssel. Sie sind unabhängig und hängen nicht von anderen Entitäten zur Identifizierung ab. Zum Beispiel hat eine
KundeEntität typischerweise eine eindeutige Kunden-ID, was sie zu einer starken Entität macht. - Schwache Entitäten: Diese Entitäten können nicht allein durch ihre eigenen Attribute eindeutig identifiziert werden. Sie hängen von einer Beziehung zu einer anderen Entität ab, die als identifizierender Elternentität bekannt ist, um zu existieren. Eine
Zeilein einem Bestellsystem könnte nur im Kontext einer bestimmtenBestellung.
Die Verwirrung entsteht oft aus der visuellen Darstellung. Eine starke Entität wird typischerweise als ein Standardrechteck dargestellt. Eine schwache Entität wird oft mit einem doppelten Rechteck dargestellt. Das Versäumnis, diese visuell zu unterscheiden, kann zu Fehlern bei der Datenbankimplementierung führen, bei denen die Tabelle für die schwache Entität ohne die erforderlichen Fremdschlüsselbeschränkungen erstellt wird, die ihre Abhängigkeit sicherstellen sollen.
Folgen einer falschen Klassifizierung
Wenn eine schwache Entität als starke modelliert wird, kann die Datenbank Datensätze zulassen, die ohne Elternentität existieren. Dies führt zu verwaisten Daten. Umgekehrt zwingt die Modellierung einer starken Entität als schwach eine unnötige Abhängigkeit, was die Verwendbarkeit der Entität außerhalb ihres primären Kontexts möglicherweise einschränken kann. Es ist entscheidend, vor der Zuweisung eines starken Entitätstyps zu prüfen, ob ein Objekt unabhängig existieren kann.
- Unabhängigkeitstest: Kann dieser Datensatz ohne Verbindung zu einem anderen Datensatz existieren?
- Quelle des Identifikators: Kommt die eindeutige ID von der Entität selbst oder von der Beziehung?
- Existenzabhängigkeit: Führt das Löschen des Elternobjekts automatisch zum Löschen des Kindobjekts?
🔗 Beziehungskardinalität und Optionalfunktion
Beziehungen definieren, wie Entitäten miteinander interagieren. Die Kardinalität gibt an, wie viele Instanzen einer Entität mit jeder Instanz einer anderen Entität assoziiert sein können oder müssen. Dies ist möglicherweise der häufigste Verwirrungspunkt aufgrund unterschiedlicher Notationsstile.
Kardinalitätsnotationen
Es gibt mehrere Möglichkeiten, die Kardinalität in einem Diagramm darzustellen. Einige verwenden Textbeschriftungen wie „1“ oder „N“, andere verwenden die Krähenfuß-Notation. Die Mischung dieser Stile oder die falsche Deutung der Symbole führt zu logischen Lücken im physischen Schema.
| Symbol / Beschriftung | Bedeutung | Beispiel-Szenario |
|---|---|---|
| 1 | Genau eine | Eine Person hat genau eine Sozialversicherungsnummer. |
| 0..1 | Null oder eine | Eine Person kann keinen oder einen Mittelnamen haben. |
| 1..1 | Genau eine und keine andere | Ein Projekt muss genau einem Projektmanager zugewiesen sein. |
| 0..N | Null bis viele | Eine Bestellung kann null oder viele Zeilenpositionen haben. |
| 1..N | Eins zu vielen | Eine Abteilung muss mindestens einen Mitarbeiter haben. |
Optionalität und Nullbarkeit
Die Optionalität bezieht sich darauf, ob eine Beziehung obligatorisch oder optional ist. Dies beeinflusst direkt die Definition des Fremdschlüssels in der Datenbanktabelle. Wenn eine Beziehung obligatorisch ist, darf die Fremdschlüsselspalte nicht null sein. Wenn sie optional ist, darf sie null sein.
Verwirrung entsteht oft, wenn das Diagramm eine durchgezogene Linie gegenüber einer gestrichelten Linie zeigt. Ohne eine klare Legende können Entwickler obligatorische Beziehungen annehmen, die gar nicht bestehen, was bei der Dateneingabe zu Verletzungen von Einschränkungen führt. Es ist unerlässlich, die Bedeutung der Linienstile innerhalb der Modeldokumentation explizit zu dokumentieren.
- Obligatorische Beziehung: Das Kind-Record muss existieren, damit das Eltern-Record gültig ist.
- Optionale Beziehung: Das Kind-Record kann ohne Eltern erstellt werden, oder das Eltern-Record kann ohne Kind existieren.
- Fremdschlüssel-Beschränkung: Muss auf
NICHT NULLfür obligatorisch,NULList für optional erlaubt.
🔑 Attribute und Schlüsselidentifikation
Attribute sind die Eigenschaften einer Entität. Obwohl dies scheinbar einfach erscheint, führt die Klassifizierung von Attributen in Schlüssel, Fremdschlüssel und einfache Attribute häufig zu Fehlern bei der Normalisierung und der Abfrageleistung.
Primär- vs. Fremdschlüssel
Der Primärschlüssel (PK) identifiziert eine Zeile eindeutig. Der Fremdschlüssel (FK) verknüpft eine Zeile mit einer übergeordneten Tabelle. Verwirrung entsteht, wenn natürliche Schlüssel anstelle von künstlichen Schlüsseln verwendet werden, oder wenn der PK nicht konsistent über das Diagramm hinweg definiert ist.
- Natürlicher Schlüssel:Ein Schlüssel, der in den Daten natürlich vorkommt, beispielsweise eine Sozialversicherungsnummer oder eine E-Mail-Adresse. Diese können sich ändern und zu Integritätsproblemen führen.
- Künstlicher Schlüssel:Ein künstlicher Schlüssel, der vom System generiert wird, beispielsweise eine automatisch hochzählende Ganzzahl. Diese werden im Allgemeinen aufgrund ihrer Stabilität bevorzugt.
Komposite Schlüssel
Ein kompositer Schlüssel besteht aus zwei oder mehr Spalten, die gemeinsam eine Aufzeichnung eindeutig identifizieren. Dies ist bei Verbindungstabellen üblich, die verwendet werden, um viele-zu-viele-Beziehungen aufzulösen. Die Verwirrung entsteht hierbei in Bezug auf die Reihenfolge der Spalten und in welcher Tabelle der Schlüssel gespeichert ist.
Wenn die Reihenfolge der Spalten in einem kompositen Schlüssel nicht konsistent über die zugehörigen Tabellen hinweg beibehalten wird, schlagen Joins fehl oder erfordern komplexe Umwandlungen. Es ist entscheidend, die genaue Spaltenreihenfolge in der Definition des Primärschlüssels zu dokumentieren.
🔁 Rekursive Beziehungen
Eine rekursive Beziehung tritt auf, wenn eine Entität sich selbst verknüpft. Dies wird häufig für hierarchische Strukturen wie Organigramme oder Stücklisten verwendet. Die Verwirrung entsteht aus der visuellen Darstellung, da die Linie die Entität mit sich selbst verbindet.
Ohne klare Beschriftung ist oft unklar, welche Seite der Beziehung den Eltern- und welche den Kind-Bezug darstellt. Beispielsweise verwalten in einer Mitarbeiter-Tabelle ein Mitarbeiter einen anderen. Die Beziehung muss explizit festlegen, dass ein Mitarbeiter andere Mitarbeiter verwalten kann.
- Selbstverweis: Der Fremdschlüssel in der Tabelle verweist zurück auf den Primärschlüssel derselben Tabelle.
- Behandlung von Nullwerten: Der Wurzelpunkt der Hierarchie hat in der Spalte Manager-ID in der Regel einen Nullwert.
- Tiefenbeschränkungen:Rekursive Abfragen können zu Leistungsbremsschwellen werden, wenn die Hierarchie sehr tief ist.
⚠️ Häufige Modellierungsfallen
Abgesehen von spezifischen Elementen führen bestimmte strukturelle Muster häufig zu Verwirrung bei der Implementierung. Die frühzeitige Erkennung dieser Fallen verhindert kostspielige Schema-Migrationen.
1. Über-Normalisierung
Während die Normalisierung Redundanz reduziert, kann eine Über-Normalisierung die Lesbarkeit und Ausführung von Abfragen erschweren. Die Erstellung einer separaten Tabelle für jedes einzelne Attribut kann die Daten unnötig fragmentieren. Es ist wichtig, das Dritte Normalform (3NF) mit der praktischen Abfrageleistung abzustimmen.
2. Viele-zu-viele-Beziehung ohne Verbindungstabelle
In einer physischen Datenbank kann eine viele-zu-viele-Beziehung nicht direkt existieren. Sie muss mithilfe einer Verbindungstabelle (assoziative Entität) in zwei ein-zu-viele-Beziehungen aufgelöst werden. Das Vergessen dieses Schritts führt zu einem Modell, das in Standard-SQL nicht implementierbar ist.
- Logisch vs. Physisch: Das logische Modell kann eine direkte Linie zwischen zwei Entitäten mit Kardinalität N:N zeigen.
- Physische Implementierung: Diese Linie muss durch eine neue Tabelle aufgeteilt werden, die die Fremdschlüssel beider Seiten enthält.
3. Inkonsistente Namenskonventionen
Verwendung gemischter Namenskonventionen (z. B. customer_id vs CustomerID vs customerId) verursacht Verwirrung bei Entwicklern, die Abfragen schreiben. Es sollte zu Beginn des Projekts eine standardisierte Namenskonvention festgelegt werden.
- Kleinbuchstaben mit Unterstrichen:
order_line_items - PascalCase:
OrderLineItems - CamelCase:
orderLineItems
🛠️ Überprüfungsstrategien
Um sicherzustellen, dass das ERD genau und nutzbar bleibt, sollten während des Überprüfungsprozesses spezifische Validierungsschritte durchgeführt werden. Diese Schritte helfen, Verwirrungspunkte zu erkennen, bevor das Schema gesperrt wird.
- Durchgang mit Stakeholdern: Durchgehen Sie das Diagramm mit Geschäftsanwendern, um sicherzustellen, dass die Beziehungen ihrem mentalen Modell des Workflows entsprechen.
- Constraint-Überprüfung: Stellen Sie sicher, dass jeder Fremdschlüssel eine entsprechende Primärschlüssel-Referenz hat.
- Datentyp-Konsistenz: Stellen Sie sicher, dass Attribute, die in einer Tabelle als Ganzzahlen definiert sind, in einer anderen Tabelle nicht als Zeichenketten definiert sind.
- Legendeneinhaltung: Stellen Sie sicher, dass alle im Diagramm verwendeten Symbole mit der bereitgestellten Legende oder dem Standard übereinstimmen.
📝 Zusammenfassung der Best Practices
Die Klarheit in einem Entitäts-Beziehungs-Diagramm erfordert Disziplin. Durch Einhaltung der Standardnotation, klare Definition der Kardinalität und Unterscheidung zwischen Entitätstypen wird das Risiko von Missverständnissen erheblich reduziert. Das Ziel ist nicht nur, ein Bild zu zeichnen, sondern eine Spezifikation zu erstellen, die direkt in ein stabiles, zuverlässiges Datenbanksystem übersetzt werden kann.
Denken Sie daran, dass das Diagramm ein lebendiges Dokument ist. Sobald sich die Anforderungen ändern, sollte das ERD aktualisiert werden, um diese Änderungen widerzuspiegeln. Dadurch wird sichergestellt, dass das Datenmodell im Laufe der Zeit weiterhin die Geschäftsanforderungen genau erfüllt. Regelmäßige Überprüfungen und die Einhaltung der in diesem Artikel beschriebenen strukturellen Richtlinien helfen Teams, die häufigen Fallstricke zu vermeiden, die Datenbankprojekte in die Irre führen.