











Bei der Entwicklung der Softwarearchitektur gibt es wenige Herausforderungen, die so beständig sind wie die Spannung zwischen der historischen Datenmodellierung und den modernen Anforderungen an Skalierbarkeit. Viele Organisationen finden sich damit konfrontiert, Backend-Systeme zu verwalten, die auf Entitäts-Beziehungs-Diagrammen (ERDs) basieren, die vor Jahren entworfen wurden und oft unter anderen Annahmen hinsichtlich Last, Konkurrenz und Hardware entstanden sind. Wenn ein veraltetes Schema hohen Durchsatzanforderungen ausgesetzt ist, ist die Leistungseinbuße nicht bloß eine Belästigung; es handelt sich um einen strukturellen Versagen. Dieser Leitfaden untersucht die technischen Realitäten der Optimierung dieser Diagramme, ohne die darin verankerte Geschäftslogik aufzugeben.
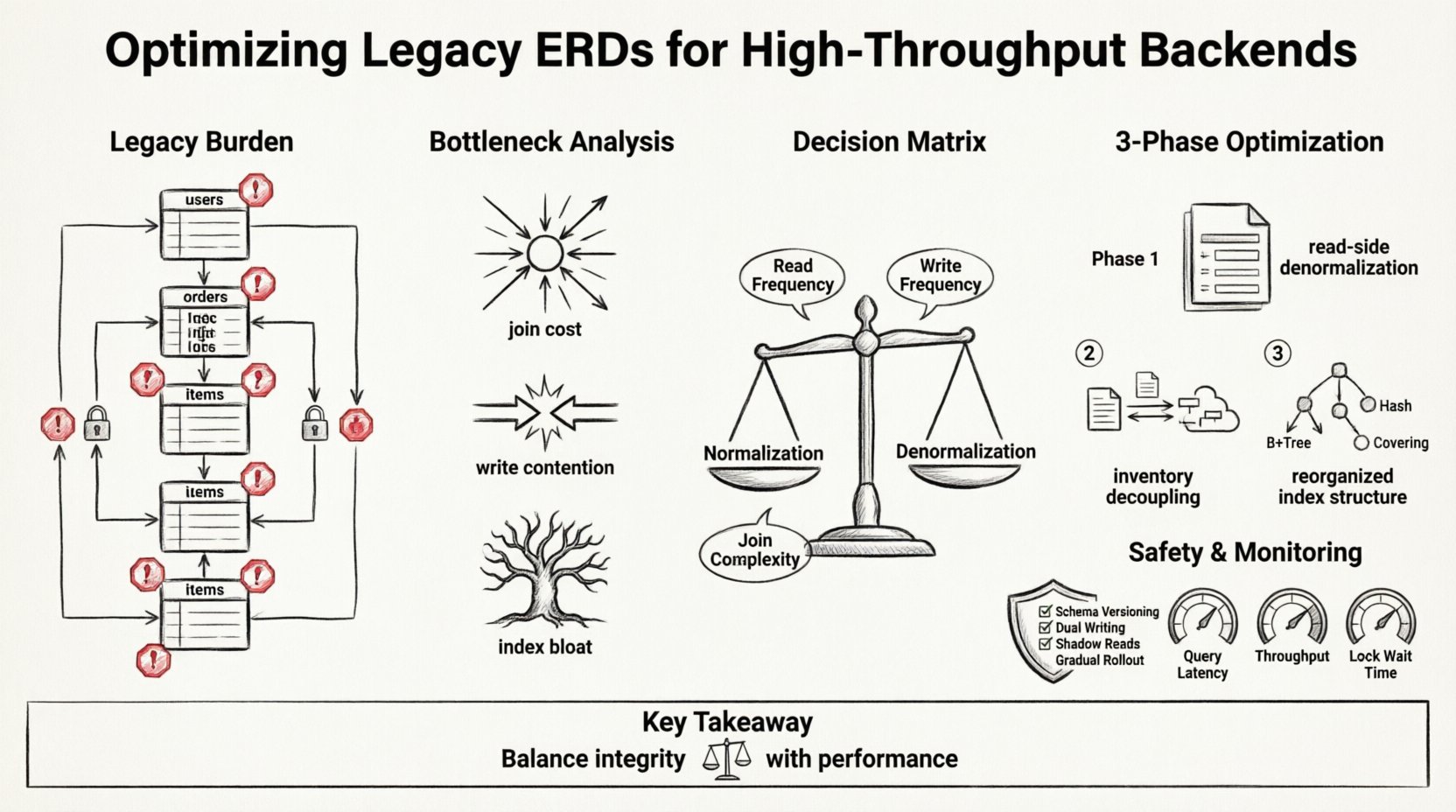
Verständnis der veralteten Last 💾
Veraltete ERDs spiegeln oft die Anforderungen der Vergangenheit wider. Sie stellen die Datenintegrität und Normalisierung über alles andere. In einer Umgebung mit einem einzigen Knoten und moderatem Datenverkehr funktioniert dieser Ansatz gut. Die strikte Einhaltung der Dritten Normalform (3NF) minimiert Redundanz und gewährleistet Konsistenz. Wenn das System jedoch auf Millionen von Transaktionen pro Sekunde skaliert, werden die Kosten dieser Beziehungen untragbar.
Berücksichtigen Sie die folgenden häufigen Merkmale, die in älteren Schemata vorkommen:
- Tiefe Join-Ketten:Abfragen, die fünf oder mehr Joins erfordern, um ein einzelnes Datenelement abzurufen.
- Schwere Fremdschlüssel-Constraints:Starre Integritätsprüfungen, die gleichzeitige Schreibvorgänge blockieren.
- Zentralisierte Sperrung:Hotspots in bestimmten Tabellen, die bei Spitzenlasten zu Engpässen werden.
- Lücken bei der De-Normalisierung:Ein Mangel an redundanten Datenspeichern für lesedichte Operationen.
Diese Muster sind nicht intrinsisch „falsch“. Sie waren für ihre Zeit korrekt. Die Herausforderung besteht darin, sie an eine verteilte, hochkonkurrierende Umgebung anzupassen, in der Latenz die primäre Währung ist.
Analyse der Engpässe 🔍
Bevor das Diagramm verändert wird, muss man verstehen, wo das System an Leistung verliert. Hochdurchsatz-Backends sind oft durch I/O-Operationen, Netzwerklatenz zwischen Diensten und Sperrkonflikten begrenzt. Das ERD bestimmt, wie Daten abgerufen werden, was diese Metriken direkt beeinflusst.
1. Join-Kosten
Jeder Join ist eine Festplatten-Leseoperation und ein CPU-Zyklus. In einem veralteten System könnte eine einzelne Anfrage für ein Benutzerprofil eine Kaskade von Abfragen über fünf Tabellen auslösen. Je höher der Datenverkehr wird, desto mehr Zeit verbringt die Datenbank damit, Beziehungen zu durchlaufen, statt Logik auszuführen. Dies gilt besonders, wenn Indizes den gesamten Join-Pfad nicht abdecken können.
2. Schreibkonkurrenz
Die Normalisierung erfordert das Schreiben von Daten an mehrere Stellen, um die Integrität zu gewährleisten. Wenn eine Transaktion ein Benutzerprofil aktualisiert und ein Aktivitätsereignis protokolliert, müssen zwei Tabellen geändert werden. Wenn diese Tabellen auf dem gleichen Shard liegen, verlängert sich die Sperrdauer. Wenn sie verteilt sind, wird die Transaktion zu einem Zweiphasen-Commit, was erheblichen Overhead verursacht.
3. Index-Schwellenwert
Um komplexe Joins zu unterstützen, sammeln veraltete Systeme Indizes an. Im Laufe der Zeit verlangsamen diese Indizes Schreibvorgänge. Die Datenbank muss jeden Index bei jedem Einfügen oder Aktualisieren aktualisieren. In Hochdurchsatz-Szenarien kann diese Schreibverstärkung das Speichersubsystem überlasten.
Refactoring-Strategie: Normalisierung gegenüber De-Normalisierung ⚖️
Der Kern der Optimierung liegt in der Neubewertung des Kompromisses zwischen Datenintegrität und Abfragegeschwindigkeit. Während die strikte Normalisierung Konsistenz gewährleistet, erfordern Hochleistungssysteme oft pragmatische De-Normalisierung. Das bedeutet nicht, die Struktur aufzugeben; es bedeutet, Redundanz zu akzeptieren, um die Latenz zu reduzieren.
Die folgende Tabelle zeigt die Entscheidungsmatrix für Schemaänderungen:
| Kriterien | Normalisiert belassen | De-Normalisierung anwenden |
|---|---|---|
| Lesehäufigkeit | Niedrig (Batch-Verarbeitung) | Hoch (Echtzeit-Dashboards) |
| Schreibhäufigkeit | Hoch (Kerntransaktionen) | Niedrig (Audit-Protokolle) |
| Konsistenzanforderung | Starke ACID | Eventuelle Konsistenz akzeptabel |
| Komplexität der Verknüpfung | Einfach (1-2 Verknüpfungen) | Komplex (3+ Verknüpfungen) |
| Datenvolatilität | Statisch (Referenzdaten) | Dynamisch (Benutzerzustand) |
Die Umsetzung dieser Strategie erfordert sorgfältige Planung. Sie verändern nicht nur Tabellen; Sie verändern, wie die Anwendung Daten wahrnimmt.
Fallstudie Schritt für Schritt: E-Commerce-Transaktions-Engine 🛒
Um diesen Prozess zu veranschaulichen, betrachten Sie eine fiktive E-Commerce-Plattform. Das Legacy-System verarbeitet Aufträge, verwaltet Lagerbestände und Kundenprofile. Das ERD wurde für eine einzelne Datenbankinstanz entworfen, wobei der Fokus auf der Vermeidung von Überverkäufen lag.
Der ursprüngliche Zustand
Im ursprünglichen Entwurf verwies die Tabelle orders verwies auf order_items, die auf products verwies. Die Tabelle products verwies auf inventory. Um eine Auftragsdetailseite anzuzeigen, führte der Backend-Server eine Abfrage aus, die alle vier Tabellen verknüpfte. Zudem erforderte jede Auftragsaktualisierung eine Sperrung der Lagerbestandstabelle, um Genauigkeit zu gewährleisten.
Identifizierte Hauptprobleme:
- Latenz: Die Ladezeiten der Seite stiegen während Verkaufsveranstaltungen auf 800 ms an.
- Totlagerungen: Hohe Konkurrenz bei Aktualisierungen des Lagerbestands führte zu Transaktionsrückgängen.
- Skalierbarkeit: Die Datenbank konnte die
LagerbestandTabelle aufgrund häufiger Join-Vorgänge über mehrere Shards nicht aufteilen.
Der Optimierungsprozess
Das Team entschied sich, das ERD in drei Phasen umzugestalten. Ziel war es, Lese- von Schreibpfaden zu entkoppeln.
Phase 1: Entnormalisierung der Lese-Seite
Der erste Schritt bestand darin, eine Momentaufnahme der Produktdaten innerhalb der Auftragsaufzeichnungen zu erstellen. Anstatt eine Verbindung zur ProdukteTabelle zur Abfragezeit herzustellen, kopierte das System den Produktnamen, den Preis und die Artikelnummer in die AuftragspositionenTabelle zum Zeitpunkt des Kaufs.
- Vorteil: Die Auftragsgeschichte bleibt auch dann korrekt, wenn die Produktdaten später geändert werden.
- Vorteil: Die Abfrage erfordert nun keine Verbindung mehr zur Produkttabelle.
- Risiko: Preisabweichungen, wenn ein Produkt nach dem Abschluss einer Bestellung aktualisiert wird.
- Minderung: Die Benutzeroberfläche zeigt den Preis zum Zeitpunkt des Kaufs als „Historischen Preis“ an.
Phase 2: Entkopplung des Lagerbestands
Die Lagerbestandstabelle war die Quelle der Konflikte. Das Team verlegte die Lagerbestandsverwaltung in einen separaten, hochfrequenten Schreibspeicher. Das Bestellsystem sendet eine asynchrone Nachricht, um Vorräte zu reservieren, anstatt eine synchrone SQL-Sperre auszuführen.
- Vorteil: Die Schreibdurchsatzleistung stieg um 400 %.
- Vorteil: Es gibt keine Blockierung mehr bei der Hauptbestelltransaktion.
- Kompromiss: Bestellungen können abgegeben werden, auch wenn die Lagerbestände vorübergehend nicht synchronisiert sind.
- Minderung:Ein Hintergrundprozess klärt die Diskrepanzen zwischen dem Bestellsystem und dem Lagerbestand auf.
Phase 3: Index-Umbau
Bei denormalisierten Daten wurden die alten Indizes auf Fremdschlüssel überflüssig. Das Team entfernte sie und fügte zusammengesetzte Indizes hinzu, die für die neuen Abfragemuster optimiert sind. Zum Beispiel ersetzt ein Index auf(customer_id, erstellt_am) die Notwendigkeit, die gesamte Bestelltabellen zu scannen, ersetzte.
Implementierungsphasen und Sicherheit 🛡️
Die Änderung eines laufenden Schemas ist eine hochriskante Maßnahme. Die folgenden Phasen gewährleisten Stabilität während des Übergangs.
1. Schema-Versionierung
Löschen Sie alte Spalten nicht sofort. Behalten Sie sie bei, markieren Sie sie jedoch als veraltet. Dadurch kann die Anwendung bei einem Fehler der neuen Logik zurückgesetzt werden. Verwenden Sie Migrations-Skripte, die Spalten hinzufügen, bevor sie entfernt werden.
2. Doppeltes Schreiben
Während des Übergangs schreiben Sie Daten in die alte und die neue Struktur. Die Anwendungslogik leitet Lesevorgänge an die neue Struktur weiter, aber Schreibvorgänge erfolgen in beide. Dies bietet eine Rückfallmöglichkeit, falls das neue Schema unvollständig ist.
3. Schatten-Lesungen
Bevor Sie den Live-Verkehr umleiten, führen Sie die neuen Abfragen auf einer Kopie der Produktionsdaten aus. Vergleichen Sie die Ergebnisse der veralteten Abfragen mit denen der optimierten Abfragen, um die Datenkorrektheit zu gewährleisten.
4. Schrittweise Einführung
Verwenden Sie Funktions-Flags, um das neue Schema für einen kleinen Prozentsatz von Benutzern (z. B. 1 %) zu aktivieren. Überwachen Sie Fehlerquoten und Latenz. Wenn die Metriken stabil bleiben, erhöhen Sie den Prozentsatz schrittweise.
Überwachung und Validierung 📊
Die Optimierung ist kein einmaliger Vorgang. Sie erfordert eine kontinuierliche Überwachung, um sicherzustellen, dass die Änderungen unter Last bestehen bleiben. Schlüsselkennzahlen (KPIs) müssen vor Beginn der Umgestaltung festgelegt werden.
Kernmetriken zur Überwachung:
- Abfrage-Latenz: 95. und 99. Perzentil der Antwortzeiten.
- Durchsatz: Transaktionen pro Sekunde (TPS) ohne Fehler.
- Wartezeit für Sperren: Durchschnittliche Zeit, die eine Transaktion auf eine Sperrung wartet.
- Replikationsverzögerung: Verzögerung zwischen Primär- und Replikat-Knoten (falls zutreffend).
- Cache-Trefferquote: Wirksamkeit der Lese-Caching-Strategien.
Warnschwellen sollten auf Grundlage der vor den Änderungen gesammelten Baseline-Metriken festgelegt werden. Wenn die Latenz steigt, sollte das System automatisch auf das Legacy-Schema zurückwechseln oder den Datenverkehr auf einen Fallback-Service umleiten.
Häufige Fehler, die vermieden werden sollten ⚠️
Selbst mit einem soliden Plan taucht technische Schuld oft auf unerwartete Weise wieder auf. Seien Sie sich dieser häufigen Fehler bewusst.
- Ignorieren der Kosten für Datenmigration:Das Verschieben von Terabytes an Daten in neue Strukturen dauert Zeit. Planen Sie Wartungsfenster oder Hintergrundmigrationstools.
- Überoptimierung von Lesevorgängen: Wenn Sie die Normalisierung zu stark aufheben, leidet die Schreibleistung. Passen Sie das Verhältnis von Lesen und Schreiben Ihrer spezifischen Arbeitslast an.
- Vergessen der Anwendungslogik: Die Schemaänderung ist nur die halbe Miete. Der Anwendungscode muss aktualisiert werden, um die neue Datenstruktur zu verarbeiten.
- Unterlassen des Testens: Einheitstests decken oft nur die glücklichen Pfade ab. Stresstests sind erforderlich, um Rennbedingungen im neuen Schema zu finden.
Langfristige Wartungsstrategien 🔧
Sobald die Optimierung abgeschlossen ist, muss das Team die neue Architektur pflegen. Dokumentation ist entscheidend. Jede Tabelle, jeder Spalte und jede Beziehung sollte mit ihrem Zweck und der Verantwortung versehen sein.
Regelmäßige Audits:
Planen Sie vierteljährliche Überprüfungen des ERD. Identifizieren Sie Tabellen, die unverhältnismäßig wachsen, oder Abfragen, die langsamer werden. Der Datenbankwachstum offenbart oft neue Engpässe, die bei der ursprünglichen Umgestaltung nicht vorhanden waren.
Automatisierte Schema-Prüfungen:
Integrieren Sie die Schema-Validierung in die CI/CD-Pipeline. Verhindern Sie, dass Entwickler neue Joins hinzufügen oder kritische Einschränkungen ohne Genehmigung entfernen. Dadurch bleibt das System langfristig optimiert.
Team-Schulung:
Stellen Sie sicher, dass alle Backend-Entwickler das neue Datenmodell verstehen. Ein gemeinsames Verständnis des Schemas verringert die Wahrscheinlichkeit, dass durch ad-hoc-Abfragen neue technische Schuld entsteht.
Abschließende Gedanken zur Datenmodellierung 🔗
Die Optimierung eines veralteten Entity-Relationship-Diagramms ist ein Ausgleich zwischen historischer Genauigkeit und zukünftiger Skalierbarkeit. Es gibt kein einziges „richtiges“ Schema. Das richtige Modell ist das, das Ihre aktuellen Geschäftsziele unterstützt und gleichzeitig Platz für Wachstum lässt.
Indem Sie sich auf die spezifischen Engpässe Ihres Systems konzentrieren – ob es nun Join-Kosten, Lock-Konflikte oder Index-Bloat sind – können Sie gezielte Verbesserungen vornehmen. Der Fallstudie zeigt, dass selbst tief verwurzelte Strukturen ohne vollständige Neuschreibung modernisiert werden können. Der Schlüssel liegt darin, schrittweise vorzugehen, rigoros zu validieren und einen klaren Überblick über die dabei involvierten Kompromisse zu behalten.
Datenmodellierung ist nicht statisch. Sie entwickelt sich mit dem Datenverkehr, den sie bedient. Behandeln Sie Ihr ERD als ein lebendiges Dokument, das die gleiche Sorgfalt und Aufmerksamkeit erfordert wie der Code, der darauf zugreift. Mit der richtigen Herangehensweise können Sie ein veraltetes System in eine Hochleistungs-Engine verwandeln, die den Anforderungen des modernen Webs gewachsen ist.