











Die Katastrophenbewältigung geht selten um die Katastrophe selbst; vielmehr geht es um die Zerbrechlichkeit der Strukturen, die wir vor dem Sturm errichten. Bei unserem jüngsten Vorfall wurde ein scheinbar geringfügiger Fehler bei der Datenbank-Schemagestaltung zum Engpass für den gesamten Wiederherstellungsprozess. Schuld war ein Entitäts-Beziehungs-Diagramm (ERD), das die Datenabhängigkeiten der Produktionsumgebung nicht korrekt widerspiegelte. Was eigentlich eine vierzigfünfminütige Operation hätte sein sollen, dehnte sich auf drei Stunden manueller Eingriffe und Datenausgleich aus. 🕰️
Dieser Artikel beschreibt die technische Aufschlüsselung dieses Fehlers, die spezifischen Schema-Inkonsistenzen, die die Verzögerung verursachten, und die prozeduralen Änderungen, die wir umgesetzt haben, um eine Wiederholung zu verhindern. Wir werden untersuchen, wie die Datenintegrität stark von der Genauigkeit der Designdokumentation abhängt, nicht nur vom Code selbst.
Die entscheidende Rolle von ERDs für die Datenresilienz 🛡️
Entitäts-Beziehungs-Diagramme sind die Baupläne der digitalen Infrastruktur. Sie zeigen Tabellen, Felder, Primärschlüssel und Fremdschlüssel auf und definieren, wie Daten miteinander verbunden und fließen. Wenn eine Katastrophe eintritt, sind diese Diagramme der erste Anhaltspunkt für Ingenieure, die den Zustand wiederherstellen wollen. Wenn die Karte falsch ist, verzögert sich die Reise.
Im Kontext der Katastrophenbewältigung erfüllt ein ERD drei Hauptaufgaben:
- Validierung: Es bestätigt, dass das wiederhergestellte Schema mit dem erwarteten Zustand der Anwendung übereinstimmt.
- Abhängigkeitszuordnung: Es identifiziert, welche Tabellen von anderen abhängen, und legt die Reihenfolge der Wiederherstellung fest.
- Einschränkungsprüfung: Es stellt sicher, dass die Regeln für die Referenzintegrität während des Importvorgangs korrekt angewendet werden.
Wenn das ERD nicht mit der tatsächlichen Datenbankkonfiguration übereinstimmt, scheitern die Wiederherstellungsskripte beim Validierungsschritt. Dies zwingt die Ingenieure, anzuhalten, zu untersuchen und das Schema manuell zu korrigieren. Genau an diesem manuellen Schritt geht die Zeit verloren. ⏳
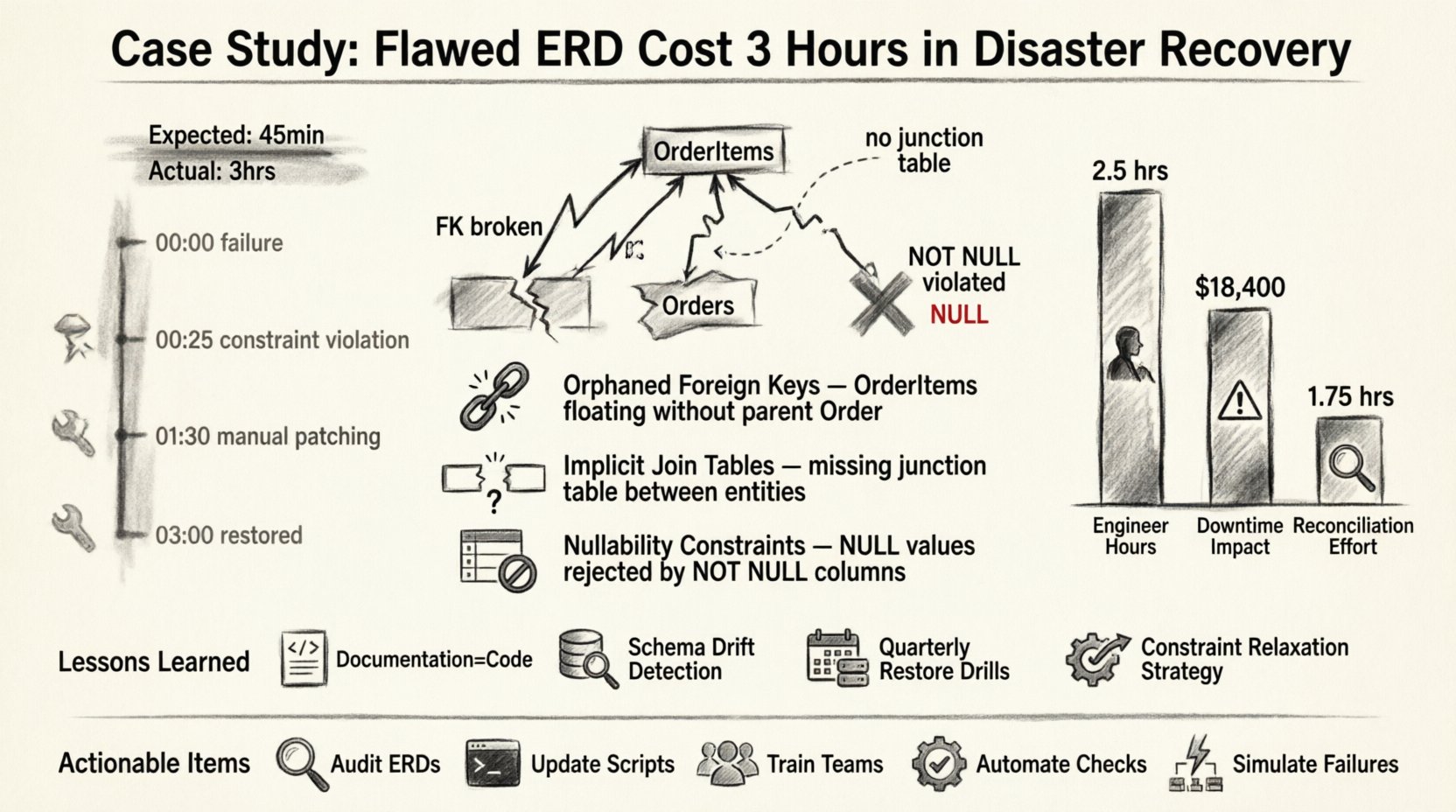
Der Vorfall: Eine Zeitleiste von Fehlern 📉
Der Vorfall begann mit einem Ausfall im primären Datenspeicher. Ein katastrophaler Hardwarefehler löste den Failover in unsere sekundäre Umgebung aus. Die Standardvorgehensweise bestand darin, das Wiederherstellungsskript zu starten, das auf einer statischen ERD-Version basierte, die in unserer Dokumentationsdatenbank gespeichert war.
Hier ist die Zeitleiste des Fehlers:
- 00:00 – Ausfall des primären Systems erkannt. Alarm löst die Vorfallreaktion aus.
- 00:05 – Ingenieurteam mobilisiert. Zugriff auf die sekundäre Umgebung gewährt.
- 00:15 – Wiederherstellungsskript auf Basis des Dokumentations-ERD gestartet.
- 00:25 – Skript angehalten. Fremdschlüsselverletzung erkannt.
- 00:30 – Untersuchung beginnt. Unterschied zwischen ERD und laufendem Schema festgestellt.
- 01:30 – Schema-Patching und manuelle Datenausgleichung begonnen.
- 03:00 – System wieder in betriebsbereiten Zustand versetzt.
Die dreistündige Verzögerung wurde nicht durch Netzwerklatenz oder Hardwareverzögerungen verursacht. Sie wurde durch die Logiklücke zwischen dem Entwurfsdokument und der physischen Realität verursacht. 🧩
Die Spezifischen Schema-Fehler, die Identifiziert Wurden 🔍
Bei der Überprüfung der laufenden Datenbank im Vergleich zum ERD haben wir drei kritische Abweichungen identifiziert. Es handelte sich nicht um Syntaxfehler; es waren logische Auslassungen, die erst dann offensichtlich wurden, als das System versuchte, Beziehungen durchzusetzen.
1. Verwaiste Fremdschlüssel
Der ERD zeigte eine strenge ein-zu-viele-Beziehung zwischenAufträge und Auftragspositionen. Die tatsächliche Datenbank enthielt jedoch Legacy-Daten, bei denen Auftragspositionen existierte, ohne dass ein entsprechender AuftragDatensatz existierte, da eine frühere Migration keine Einschränkungen durchgesetzt hatte. Der ERD berücksichtigte diesen verwaisten Zustand nicht. Als das Wiederherstellungsskript versuchte, den Fremdschlüssel wiederherzustellen, lehnte die Datenbank die Daten ab, weil der übergeordnete Datensatz fehlte oder die Einschränkung anders durchgesetzt wurde als dokumentiert.
2. Implizite Verbindungstabellen
Eine viele-zu-viele-Beziehung wurde im ERD als direkte Verbindung zwischen zwei Tabellen dargestellt. In der physischen Implementierung wurde dies über eine Verbindungstabelle behandelt. Die Wiederherstellungslogik erwartete die direkte Verbindung und versuchte, Daten in die falschen Spalten einzufügen. Dies führte zu einer Kaskade von Typenkonflikten, die manuelle Schemaänderungen erforderten.
3. Nullwert-Einschränkungen
Der ERD wies darauf hin, dass mehrere Felder optional (nullbar) waren. Das Produktions-Schema wurde jedoch im Laufe der Zeit aktualisiert, um für die Datenqualität nicht-null-Werte durchzusetzen. Der ERD wurde nicht aktualisiert, um diese Änderung widerzuspiegeln. Während der Wiederherstellung versuchte das Skript, NULL-Werte in nicht-null-Felder einzufügen, was sofort eine Rücksetzung der Transaktion verursachte.
Diese Abweichungen zeigen ein häufiges Problem in der technischen Dokumentation: Dokumentationsdrift. Das Dokument wird mit der Entwicklung des Systems veraltet und erzeugt ein falsches Gefühl der Sicherheit.
Kostenanalyse: Zeit vs. Genauigkeit 💰
Die finanziellen Auswirkungen der dreistündigen Ausfallzeit sind erheblich, aber die Reputationskosten sind noch höher. Unten finden Sie eine Aufschlüsselung der Ressourcen, die während der Verzögerung verbraucht wurden.
| Ressource | Verbrauchte Zeit | Auswirkung |
|---|---|---|
| Senior Ingenieure | 3 Stunden | Hohe Priorität abgelenkt von der Entwicklung |
| Systemausfall | 3 Stunden | Die Serviceverfügbarkeit wurde um 15 % reduziert |
| Datenausgleich | 1,5 Stunden | Manuelle Überprüfung erforderlich |
| Dokumentationsaktualisierung | 0,5 Stunden | Nach-Begebenheits-Nachholung |
Die Tabelle zeigt, dass der größte Teil der Kosten nicht die Wiederherstellung selbst war, sondern die Korrektur der Wiederherstellung. Hätte das ERD genau gewesen, wäre die Wiederherstellung reibungslos verlaufen.
Technische Analyse: Warum der Skript fehlgeschlagen ist 🛠️
Um die Schwere des Fehlers zu verstehen, müssen wir untersuchen, wie das Wiederherstellungsskript mit der Datenbankengine interagierte. Das Skript verfolgte eine standardmäßige Reihenfolge:
- Tabellen basierend auf ERD-Definitionen erstellen.
- Einschränkungen anwenden (Primärschlüssel, Fremdschlüssel).
- Integrität überprüfen.
3. Daten einfügen.
Als das Skript Schritt 2 erreichte, versuchte es, eine Fremdschlüsselbeschränkung zu erstellen, die Tabelle A mit Tabelle B. Die Datenbankengine durchsuchte Tabelle B nach vorhandenen Daten. Es fand Datensätze, die die Beschränkung verletzten, weil der übergeordnete Schlüssel fehlte. Da das Skript idempotent und sicher geschrieben war, wurde es gestoppt, um die Daten nicht zu beschädigen. Diese Sicherheitsfunktion, die zwar gut für die Datenintegrität ist, wirkte sich als Blockade auf den Wiederherstellungszeitplan aus.
Das Skript konnte nicht fortfahren, bis die Daten in Tabelle Bbereinigt waren. Die Datenbereinigung erfordert:
- Identifizieren der verwaisten Datensätze.
- Entscheiden, ob sie gelöscht oder Phantom-Übergeordnete erstellt werden sollen.
- Ausführen der Bereinigung manuell.
- Erneutes Ausführen der Beschränkungserstellung.
Jeder Schritt in dieser Kette fügt Zeit hinzu. Der ERD hätte bereits in der Entwurfsphase auf das Potenzial für verwaiste Daten hinweisen müssen, was eine Datenmigrationstrategie anstelle einer einfachen Schemareplikation hätte auslösen müssen.
Gelernte Erkenntnisse: Stärkung des Schema-Lebenszyklus 🔄
Nach dem Vorfall starteten wir eine gründliche Überprüfung unserer Schema-Management-Praktiken. Wir erkannten, dass die Abhängigkeit von einem statischen Dokument für die Katastrophenwiederherstellung unzureichend war. Wir benötigten einen dynamischen, versionskontrollierten Ansatz für die Schema-Design.
Hier sind die wichtigsten Erkenntnisse aus dem Vorfall:
- Dokumentation ist Code: Der ERD ist kein eigenständiges Artefakt; er ist Teil des Codebases. Er muss denselben Versionskontroll- und Überprüfungsprozessen unterzogen werden wie die Anwendungslogik.
- Erkennung von Schema-Abweichungen: Wir haben automatisierte Werkzeuge implementiert, um das laufende Datenbankschema mit dem versionierten ERD zu vergleichen. Jede Abweichung löst sofort eine Warnung aus.
- Testen der Wiederherstellung: Wir führen nun quartalsweise Wiederherstellungsübungen in einer Sandbox-Umgebung durch. Dadurch stellen wir sicher, dass der ERD den Wiederherstellungsweg genau widerspiegelt.
- Lockerung von Einschränkungen: Wir haben die Wiederherstellungsskripte angepasst, um Fremdschlüsselbeschränkungen während des initialen Datenladens temporär zu deaktivieren und sie erst nach der Überprüfung aller Daten wieder einzuführen.
Best Practices für die ERD-Wartung 📝
Um zukünftige Verzögerungen zu vermeiden, haben wir eine Reihe von Best Practices für die Pflege von Entity-Relationship-Diagrammen übernommen. Diese Schritte stellen sicher, dass die Baupläne während des gesamten Lebenszyklus des Systems gültig bleiben.
1. Versionskontrolle für Diagramme
Speichern Sie ERD-Dateien im selben Repository wie den Quellcode. Kennzeichnen Sie jede Freigabe mit einer entsprechenden Diagrammversion. Dadurch können Ingenieure den genauen Zustand des Schemas zu jedem Zeitpunkt abrufen.
2. Automatisierte Generierung
Wo immer möglich, generieren Sie ERDs direkt aus dem Datenbankschema anstatt sie manuell zu zeichnen. Dadurch wird die Wahrscheinlichkeit menschlicher Fehler reduziert und sichergestellt, dass das Diagramm stets der Realität entspricht.
3. Regelmäßige Audits
Planen Sie einen vierteljährlichen Audit des ERD. Vergleichen Sie das Diagramm mit der Produktionsumgebung. Dokumentieren Sie alle Änderungen, die außerhalb des standardmäßigen Bereitstellungspipelines vorgenommen wurden.
4. Einbeziehung von Datenmigration-Notizen
Der ERD sollte nicht nur Tabellen zeigen; er sollte auch die Historie der Daten darstellen. Kennzeichnen Sie das Diagramm mit Notizen zu Daten, die verwaist oder veraltet sein könnten. Dies informiert das Wiederherstellungsteam, dass Abweichungen zu erwarten sind.
5. Überprüfung während der Sprint-Planung
Wenn eine neue Funktion eine Datenbankänderung erfordert, muss der ERD in derselben Ticket-Nummer aktualisiert werden. Erlauben Sie keine Bereitstellung von Schema-Änderungen ohne entsprechende Aktualisierung des Diagramms.
Der menschliche Faktor bei technischen Fehlern 🧑💻
Es ist einfach, das Diagramm oder das Skript zu beschuldigen, doch die Ursache war oft eine Kommunikationslücke. Der Entwickler, der das neue Feld hinzugefügt hat, hat das Diagramm nicht aktualisiert. Der Ingenieur, der den Code überprüft hat, hat die Schema-Dokumentation nicht überprüft.
Technische Prozesse sind nur so stark wie die Menschen, die sie befolgen. Wir haben eine Checkliste für die Bereitstellung eingeführt, die einen Schritt zur Schema-Überprüfung enthält. Jede Bereitstellung muss einen Diff-Bericht enthalten, der die Änderungen an der Datenbankstruktur zeigt. Dadurch wird Transparenz bei Schema-Änderungen erzwungen.
Abschließende Gedanken zur Resilienz 🏗️
Die Katastrophenwiederherstellung ist ein Maß für unsere Vorbereitung, nicht nur für unsere Reaktion. Die dreistündige Verzögerung war ein Symptom für ein größeres Problem: die Trennung zwischen Design und Implementierung. Indem wir das Entity-Relationship-Diagramm als lebendiges, atmendes Element unserer Infrastruktur betrachten, können wir die Wiederherstellungszeiten erheblich reduzieren.
Datenintegrität ist keine Funktion; sie ist eine Grundlage. Wenn diese Grundlage bricht, ist die gesamte Struktur gefährdet. Die Sicherstellung, dass unsere Baupläne genau sind, ist der erste Schritt hin zu einer resistenten Architektur. Wir müssen genauso viel Zeit in die Dokumentation investieren wie in den Code.
Zusammenfassung der Maßnahmen ✅
- Prüfung der aktuellen ERDs: Vergleichen Sie alle Dokumentationen sofort mit den aktiven Schemata.
- Aktualisierung der Skripte: Ändern Sie die Katastrophenwiederherstellungsskripte, damit sie Verletzungen von Einschränkungen reibungslos behandeln.
- Schulung der Teams: Stellen Sie sicher, dass alle Ingenieure die Bedeutung der Schemadokumentation verstehen.
- Automatisierung der Prüfungen: Implementieren Sie Werkzeuge, die bei Schemaverschiebungen warnen.
- Simulieren von Ausfällen: Führen Sie regelmäßige Katastrophenwiederherstellungsübungen durch, um die Genauigkeit der Dokumentation zu testen.
Durch Einhaltung dieser Praktiken können wir sicherstellen, dass zukünftige Vorfälle in Minuten, nicht in Stunden, behoben werden. Die Kosten der Genauigkeit sind weitaus geringer als die Kosten der Korrektur.