











Die Gestaltung einer robusten Datenarchitektur erfordert ein tiefes Verständnis dafür, wie Informationen miteinander verbunden, verknüpft und persistiert werden. Im Zentrum dieses Entwurfs steht das Entitäts-Beziehungs-Diagramm (ERD). Obwohl ERDs traditionell mit relationalen Datenbanken assoziiert werden, haben sich ihre Semantiken entwickelt, um die vielfältigen Anforderungen moderner NoSQL-Umgebungen zu berücksichtigen. Dieser Leitfaden untersucht die Feinheiten der Modellierung von Datenbeziehungen über verschiedene Speicherparadigmen hinweg und stellt sicher, dass die strukturelle Integrität gewahrt bleibt, ohne die Leistung zu beeinträchtigen.
Grundlegende Konzepte der Datenmodellierung 🏗️
Bevor man sich spezifischen Datenbanktypen widmet, ist es unerlässlich, einen gemeinsamen Wortschatz zu etablieren. Ein Entitäts-Beziehungs-Diagramm dient als visueller Bauplan. Es definiert die Entitäten (Tabellen, Sammlungen oder Dokumente), ihre Attribute (Spalten, Felder oder Eigenschaften) sowie die Beziehungen zwischen ihnen.
- Entität: Ein eindeutiges Objekt oder Konzept im Geschäftsbereich. Im Datenbankkontext könnte dies ein Benutzer, ein Produkt oder eine Bestellung sein.
- Attribut: Eine Eigenschaft, die die Entität beschreibt. Beispiele sind id, name, erstellt_am, oder status.
- Beziehung: Die Verbindung zwischen zwei Entitäten. Dies definiert, wie Daten in einer Entität mit Daten in einer anderen verknüpft sind.
- Kardinalität: Der numerische Aspekt einer Beziehung. Sie legt fest, ob eine Beziehung ein-zu-eins, ein-zu-viele oder viele-zu-viele ist.
Beim Erstellen eines ERD soll die logische Struktur der realen Welt der Anwendung dargestellt werden. Ein gut gestaltetes Diagramm reduziert die Mehrdeutigkeit für Entwickler und stellt sicher, dass Abfragen später im Entwicklungszyklus effizient formuliert werden können.
Semantik in relationalen Umgebungen 🗃️
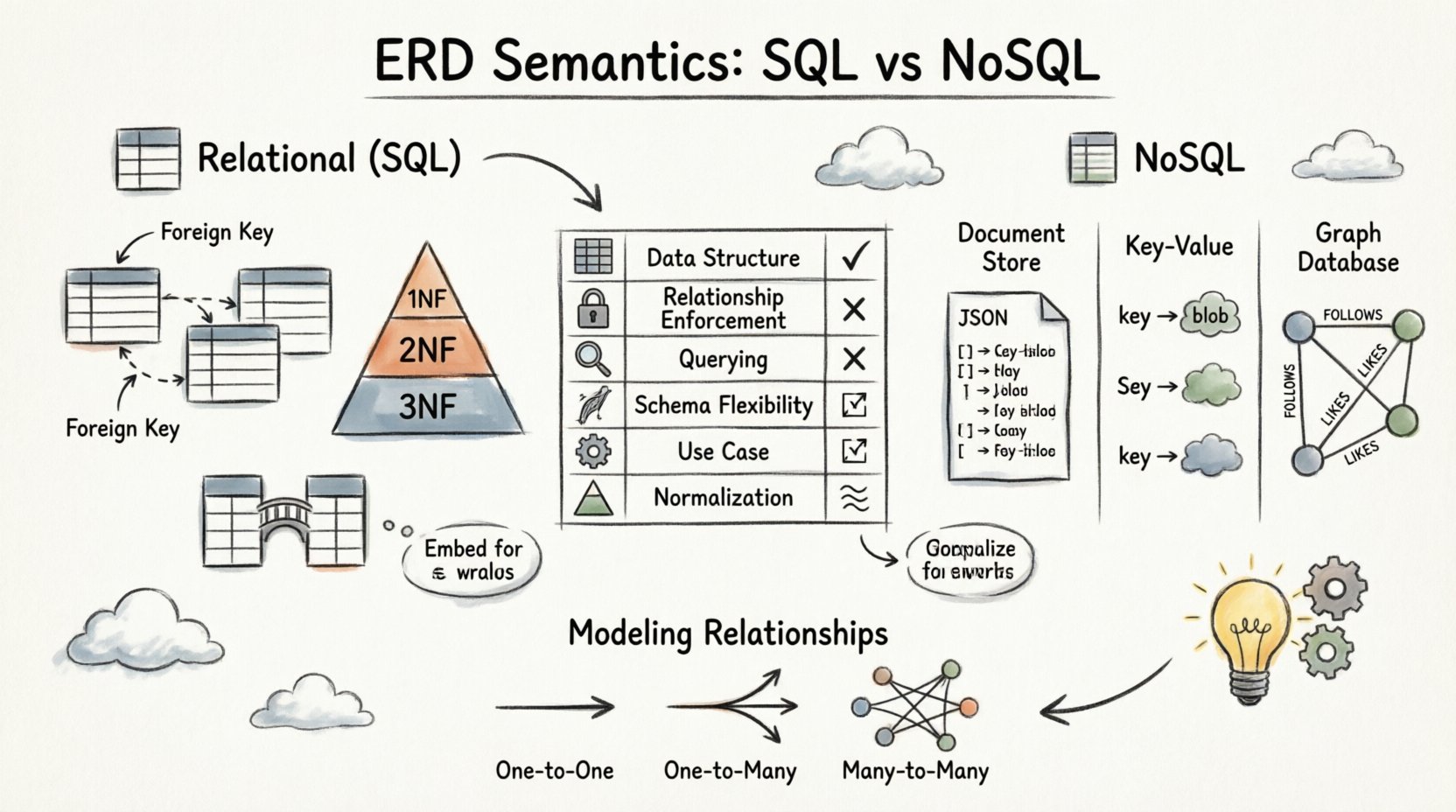
Im relationalen Modell werden Daten in Tabellen mit strengen Schemata gespeichert. Die Semantik des ERD hier ist streng und wird durch die Mengenlehre und die Prinzipien der ersten Normalform bestimmt. Jede Beziehung wird vom Datenbank-Engine erzwungen, um die Referenzintegrität zu gewährleisten.
1. Die Rolle von Fremdschlüsseln
Fremdschlüssel sind die Grundlage relationaler ERDs. Sie verknüpfen Tabellen physisch miteinander. Wenn ein ERD eine Linie zeigt, die zwei Tabellen verbindet, beruht die Implementierung auf einer Fremdschlüsselspalte in der Kindtabelle, die auf den Primärschlüssel der Elterntabelle verweist.
- Implementierung: Ein numerischer oder alphanumerischer Wert, der in einer Spalte gespeichert ist.
- Einschränkung: Die Datenbank-Engine verhindert verwaiste Datensätze. Sie können keinen Wert in eine Fremdschlüsselspalte einfügen, es sei denn, er existiert bereits im referenzierten Primärschlüssel.
- Kaskadierung: Aktionen am übergeordneten Datensatz (Löschen oder Aktualisieren) können basierend auf definierten Regeln automatisch auf die untergeordneten Datensätze übertragen werden.
2. Normalisierung und Integrität
Relationale ERDs legen Wert auf Normalisierung. Dieser Prozess reduziert Datenredundanz, indem Attribute in logische Gruppen organisiert werden. Ein gut normalisierter ERD wirkt typischerweise komplexer, da viele Tabellen beteiligt sind.
- 1NF: Stellt Atomarität sicher; jedes Feld enthält einen einzelnen Wert.
- 2NF: Beseitigt partielle Abhängigkeiten; Attribute hängen vom gesamten Primärschlüssel ab.
- 3NF: Beseitigt transitive Abhängigkeiten; Nicht-Schlüssel-Attribute hängen nur vom Primärschlüssel ab.
Diese Struktur stellt sicher, dass die Daten konsistent sind. Wenn ein Benutzer seinen Namen ändert, wird dies an einer Stelle aktualisiert, und jeder Datensatz, der auf diesen Benutzer verweist, sieht die Änderung sofort.
3. Behandlung von Many-to-Many-Beziehungen
Many-to-Many-Beziehungen sind in relationalen Systemen semantisch unterschiedlich. Sie können zwei Tabellen nicht direkt verknüpfen. Stattdessen ist eine Zwischentabelle erforderlich.
- Struktur: Eine Tabelle, die die Primärschlüssel beider verwandten Entitäten enthält.
- Funktion: Diese Tabelle fungiert als Brücke, sodass mehrere Datensätze in Entität A mit mehreren Datensätzen in Entität B verknüpft werden können.
- Abfragen: Die Abfrage dieser Daten erfordert eine
JOINOperation, die bei großen Datensätzen, wenn sie nicht korrekt indiziert sind, rechnerisch kostspielig sein kann.
Semantik in NoSQL-Umgebungen 📦
NoSQL-Datenbanken bieten Flexibilität. Die Semantik des ERDs verschiebt sich von der strukturellen Durchsetzung hin zur logischen Darstellung. Das Diagramm wird mehr zu einem Leitfaden für Gestaltungsmuster als zu einer strikten Schema-Definition. Verschiedene NoSQL-Modelle behandeln Beziehungen unterschiedlich.
1. Dokumentenspeicher und Einbetten
In dokumentenorientierten Datenbanken werden Daten als JSON-ähnliche Dokumente gespeichert. Der ERD schlägt oft vor, verwandte Daten direkt innerhalb eines einzelnen Dokuments einzubetten, um die Leseleistung zu optimieren.
- Eins-zu-Viele: Ein übergeordnetes Dokument kann ein Array von Kindobjekten enthalten. Dies vermeidet die Notwendigkeit von Joins bei der Abrufung.
- Auswirkung: Aktualisierungen der Kinddaten erfordern das Neuschreiben des gesamten übergeordneten Dokuments. Dies kann zu Konflikten führen, wenn das übergeordnete Dokument sehr groß wird.
- Lesen gegenüber Schreiben: Dieser Ansatz optimiert für Lesevorgänge. Es wird Leistung beim Schreiben und Datenredundanz gegen Geschwindigkeit getauscht.
2. Schlüssel-Wert-Speicher
Schlüssel-Wert-Speicher behandeln Daten als undurchsichtige Blöcke. Die ERD-Semantik hier ist minimal. Beziehungen werden oft von der Anwendungsschicht abgeleitet, anstatt vom Datenbank-Engine.
- Verweisung:Dokumente enthalten oft eine Referenz-ID auf ein anderes Dokument, ähnlich einem Fremdschlüssel, jedoch ohne Durchsetzung.
- Verantwortung:Die Anwendungslogik muss sicherstellen, dass die referenzierte ID existiert und gültig ist. Es gibt keine Einschränkung auf Datenbankebene.
- Anwendungsfall:Am besten geeignet für Caching, Sitzungsverwaltung oder sehr flexible Datenstrukturen, bei denen Beziehungen nicht im Vordergrund stehen.
3. Graphen-Datenbanken
Graphen-Datenbanken sind speziell für Beziehungen konzipiert. Das ERD in diesem Kontext entspricht direkt Knoten und Kanten. Dies ist vielleicht die wörtlichste Interpretation eines Entitäts-Beziehungs-Diagramms.
- Knoten:Stellen Entitäten dar (z. B. Person, Ort).
- Kanten:Stellen Beziehungen dar (z. B. LEBT_IN, KENNT).
- Eigenschaften:Sowohl Knoten als auch Kanten können Attribute haben.
- Durchlauf:Abfragen folgen den Kanten. Eine Beziehung ist kein Suchvorgang; es ist ein Pfad-Durchlauf.
Vergleichende Analyse von Modellierungsansätzen 📊
Das Verständnis der Unterschiede zwischen diesen Umgebungen hilft bei der Auswahl des richtigen Werkzeugs für die Aufgabe. Die folgende Tabelle zeigt, wie ERD-Semantik in diesen Systemen übertragen wird.
| Funktion | Relational (SQL) | Dokumentenspeicher | Graphen-Datenbank |
|---|---|---|---|
| Datenstruktur | Tabellen mit Zeilen und Spalten | JSON-Dokumente | Knoten und Kanten |
| Durchsetzung von Beziehungen | Fremdschlüssel (streng) | Manuell / Anwendungsebene | Native Kantenreferenzen |
| Abfragen von Beziehungen | JOIN-Operationen | Abfrage oder Einbetten | Pfadtraversierung |
| Schemaflexibilität | Festes Schema | Dynamisches Schema | Halbstrukturiert |
| Primärer Anwendungsbereich | Transaktionsintegrität | Inhaltsverwaltung / Hierarchien | Netzwerke / Soziale Graphen |
| Normalisierung | Hoch (3NF / BCNF) | Niedrig (Entnormalisiert) | Nicht anwendbar |
Modellierung von Beziehungen: Eine detaillierte Betrachtung 🔗
Die Art und Weise, wie Beziehungen in einem ERD dargestellt werden, bestimmt die Abfragemuster und Leistungsmerkmale der Anwendung. Betrachten wir nun bestimmte Kardinalitäten im Detail.
Ein-zu-eins-Beziehungen
Dies ist die einfachste Beziehung. Ein Datensatz in Tabelle A entspricht genau einem Datensatz in Tabelle B.
- SQL-Implementierung: Ein Fremdschlüssel in einer der Tabellen mit einer eindeutigen Beschränkung.
- NoSQL-Implementierung: Häufig in einem einzigen Dokument zusammengeführt, um Abfragen zu vermeiden, oder getrennt gespeichert mit einer eindeutigen Referenz.
- Wann verwenden: Benutzerprofile, die von Authentifizierungsdetails getrennt sind, oder Konfigurationseinstellungen, die bestimmten Umgebungen zugeordnet sind.
Ein-zu-viele-Beziehungen
Dies ist der häufigste Beziehungstyp. Ein Datensatz in Tabelle A steht in Beziehung zu vielen Datensätzen in Tabelle B.
- SQL-Implementierung: Ein Fremdschlüssel in Tabelle B, der auf Tabelle A verweist.
- Dokumentenspeicher: Integrieren Sie die „Viele“-Seite innerhalb des Dokuments der „Einen“-Seite als Array. Dies ist effizient, um die gesamte Hierarchie auf einmal zu lesen.
- Graphdatenbank: Erstellen Sie eine Kante vom „Einen“-Knoten zu mehreren „Viele“-Knoten.
- Berücksichtigung: Wenn die „Viele“-Seite erheblich wächst, kann die Einbettung in einem Dokumentenspeicher die Speicherbegrenzungen erreichen. Ein hybrider Ansatz (Verweise statt Einbettung) könnte notwendig sein.
Mehrzeilige-zu-Mehrzeilige-Beziehungen
Diese Beziehung erfordert in SQL eine Brückentabelle, verhält sich aber in anderen Systemen anders.
- SQL-Implementierung: Eine Verbindungstabelle, die IDs aus beiden Eltern-Tabellen enthält.
- Dokumentenspeicher: Häufig nicht normalisiert. Jedes Dokument enthält eine Liste von IDs oder vollständigen Objekten aus der zugehörigen Entität. Dies führt zu Datenverdoppelung, beschleunigt aber die Abrufzeit.
- Graphdatenbank: Dies ist die natürliche Stärke des Modells. Knoten sind direkt miteinander verbunden, ohne dass eine Zwischentabelle erforderlich ist.
- Konsistenz-Herausforderung: In Dokumentenspeichern ist es schwierig, die Listen über mehrere Dokumente hinweg synchron zu halten. Änderungen an einer gemeinsam genutzten Entität müssen manuell an alle verweisenden Dokumente weitergegeben werden.
Schema-Evolution und Flexibilität 🔄
Softwareanforderungen ändern sich. Datenmodelle müssen sich entwickeln, ohne bestehende Anwendungen zu beschädigen. Die Semantik des ERD bestimmt, wie leicht diese Evolution erfolgen kann.
1. Schema-Migration in SQL
Das Ändern eines relationalen Schemas ist eine bedeutende Operation. Es erfordert oft das Sperren von Tabellen oder das Durchführen von Migrationen während der Ausfallzeit.
- Spalten hinzufügen: Im Allgemeinen sicher und schnell.
- Spalten umbenennen: Erfordert das Umschreiben der Tabellenstruktur und das Aktualisieren aller abhängigen Abfragen.
- Datentypen ändern: Kann riskant sein, wenn die Datenumwandlung fehlschlägt oder wenn die Anwendungslogik vom alten Typ abhängt.
2. Schema-Flexibilität in NoSQL
NoSQL-Systeme erlauben im Allgemeinen schema-less oder schema-on-read-Ansätze. Der ERD ist eine Richtlinie, keine Gesetzgebung.
- Felder hinzufügen: Sie können neue Felder zu bestimmten Dokumenten hinzufügen, ohne andere zu beeinflussen.
- Versionsverwaltung: Es ist üblich, Versionsnummern zu Dokumenten hinzuzufügen, um unterschiedliche Strukturen im Laufe der Zeit zu verwalten.
- Kompromiss: Die fehlende Durchsetzung bedeutet, dass Probleme mit der Datenqualität auftreten können. Die Anwendung muss die Daten vor dem Schreiben validieren.
Leistungsimplikationen von Modellierungsentscheidungen ⚡
Die Struktur Ihres ERD beeinflusst direkt die Abfragegeschwindigkeit. Es gibt keine allgemeingültige Lösung; das Design muss sich an den Zugriffsmustern der Anwendung ausrichten.
1. Leseintensive Workloads
Wenn die Anwendung Daten häufig liest, aber selten aktualisiert, ist die De-Normalisierung vorteilhaft.
- Strategie:Verwenden Sie eingebettete Daten, um die Anzahl der erforderlichen Abfragen zu reduzieren.
- Vorteil:Weniger I/O-Operationen und geringere Latenz.
- Kosten:Erhöhter Speicherverbrauch und komplexere Aktualisierungslogik.
2. Schreibintensive Workloads
Wenn die Anwendung Daten häufig aktualisiert, wird Normalisierung oder getrennte Speicherung bevorzugt.
- Strategie:Speichern Sie Daten in ihrer atomarsten Form und führen Sie Joins oder Verweise zur Abfragezeit durch.
- Vorteil:Ein einziges Quell-Dokument; Aktualisierungen erfolgen an einer Stelle.
- Kosten:Höhere Lese-Latenz aufgrund von Joins oder mehreren Abfragen.
3. Indizierungsstrategien
Unabhängig vom Datenbanktyp zeigt das ERD an, wo Indizes benötigt werden.
- Relational:Indizes werden auf Fremdschlüssel und Spalten platziert, die in
WHEREKlauseln verwendet werden. - Dokument:Indizes werden auf Felder platziert, die häufig abgefragt werden. Verschachtelte Felder können eine spezifische Indizierungssyntax erfordern.
- Graph:Indizes werden auf Knotenbeschriftungen und Kanten-Eigenschaften platziert, um die Ausgangspunkte für die Durchquerung zu beschleunigen.
Hybride Umgebungen und Polyglot-Persistenz 🧩
Moderne Architekturen verwenden häufig gleichzeitig mehrere Datenbanktechnologien. Dies wird als Polyglot-Persistenz bezeichnet. Die ERD-Semantik muss diese Lücken überbrücken.
1. Muster der Datenkonsistenz
Wenn Daten mehrere Systeme überwinden, wird die Konsistenz komplex.
- ACID:Relationale Datenbanken bieten starke Konsistenz. Transaktionen erstrecken sich über mehrere Tabellen innerhalb derselben Datenbank.
- BASE:NoSQL-Datenbanken bevorzugen oft Verfügbarkeit und letztendliche Konsistenz. Transaktionen können auf ein einzelnes Dokument beschränkt sein.
- Saga-Muster: Für verteilte Transaktionen über Systeme hinweg verwaltet ein Saga-Muster langlaufende Operationen durch die Koordination lokaler Transaktionen.
2. Die Rolle des ERD in hybriden Systemen
Der ERD wirkt als konzeptionelle Karte. Er definiert die logischen Beziehungen, auch wenn die physische Speicherung unterschiedlich ist.
- Zuordnung:Entwickler verwenden den ERD, um zu entscheiden, welches Daten zu welchem Speicher gehören.
- Integration:Das Diagramm hilft dabei, visuell darzustellen, wo Daten-Synchronisation zwischen den Systemen erforderlich ist.
- Dokumentation:Es bietet eine einheitliche Sicht für Stakeholder, die die technischen Unterschiede zwischen den Speicher-Engines möglicherweise nicht verstehen.
Best Practices für robustes Datenmodellieren 🛡️
Um langfristige Wartbarkeit und Leistung zu gewährleisten, halten Sie sich bei der Gestaltung Ihrer ERDs an diese Prinzipien.
- Verstehen Sie den Bereich:Beginnen Sie mit den geschäftlichen Anforderungen. Modellieren Sie keine Daten, die kein spezifisches Anwendungsfall unterstützen.
- Wählen Sie das richtige Werkzeug:Wählen Sie die Datenbankart basierend auf den Datenbeziehungen, nicht nur auf Trends. Verwenden Sie Graphen für komplexe Netzwerke, Dokumente für Inhalte und SQL für Transaktionen.
- Dokumentieren Sie Beziehungen explizit:Beschreiben Sie die Kardinalität im Diagramm eindeutig. Mehrdeutigkeit führt zu Implementierungsfehlern.
- Planung für Wachstum: Berücksichtigen Sie, wie das Datenvolumen skaliert werden wird. Wird ein eingebettetes Array zu groß? Wird eine Verbindungstabelle zu einem Engpass?
- Iterieren Sie das Design: ERDs sind nicht statisch. Verfeinern Sie sie, während die Anwendung sich weiterentwickelt und neue Einschränkungen entdeckt werden.
- Validieren Sie auf der Anwendungsebene: Besonders bei NoSQL implementieren Sie Validierungslogik, um die Datenintegrität zu gewährleisten, da die Datenbank dies möglicherweise nicht durchsetzen kann.
Schlussfolgerung zu Modellierungssemantik 📝
Die Semantik eines Entitäts-Beziehungs-Diagramms ist nicht universell; sie passt sich der zugrundeliegenden Speichertechnologie an. In relationalen Systemen ist das ERD ein Vertrag, der von der Datenbankengine durchgesetzt wird. In NoSQL-Systemen ist es ein Musterleitfaden für die Anwendungsebene. Das Verständnis dieser Unterschiede ermöglicht Architekten, Systeme zu gestalten, die sowohl skalierbar als auch konsistent sind.
Durch sorgfältige Analyse der Kardinalität, Auswahl des geeigneten Speichermodells und Vorwegnahme zukünftiger Änderungen können Teams Datenebenen aufbauen, die komplexe Geschäftslogik unterstützen, ohne die Leistung zu beeinträchtigen. Der Schlüssel liegt darin, das logische Modell mit den physischen Fähigkeiten der gewählten Umgebung abzustimmen.
Unabhängig davon, ob mit Tabellen, Dokumenten oder Graphen gearbeitet wird, bleiben die grundlegenden Prinzipien zur Identifizierung von Entitäten und zur Definition ihrer Verbindungen konstant. Ein klares ERD dient als Grundlage für eine zuverlässige Softwarearchitektur und schließt die Lücke zwischen Geschäftsanforderungen und technischer Umsetzung.