











在系统分析和软件开发的复杂环境中,清晰性至关重要。当利益相关者、开发人员和分析师试图理解信息如何在系统中流动时,模糊性可能导致代价高昂的错误。这时,数据流图(DFD)就成为一种关键工具。它提供了一种结构化的方式来表示系统内部信息的流动,将逻辑过程与物理实现分离开来。
数据流图不仅仅是一张图;它是一种沟通工具。它使团队能够在不陷入代码细节的情况下,可视化数据输入、转换和输出。通过绘制这些流程,组织可以识别瓶颈,确保数据完整性,并将业务目标与技术能力对齐。本指南探讨了现代信息系统中数据流图的机制、组成部分及其战略价值。
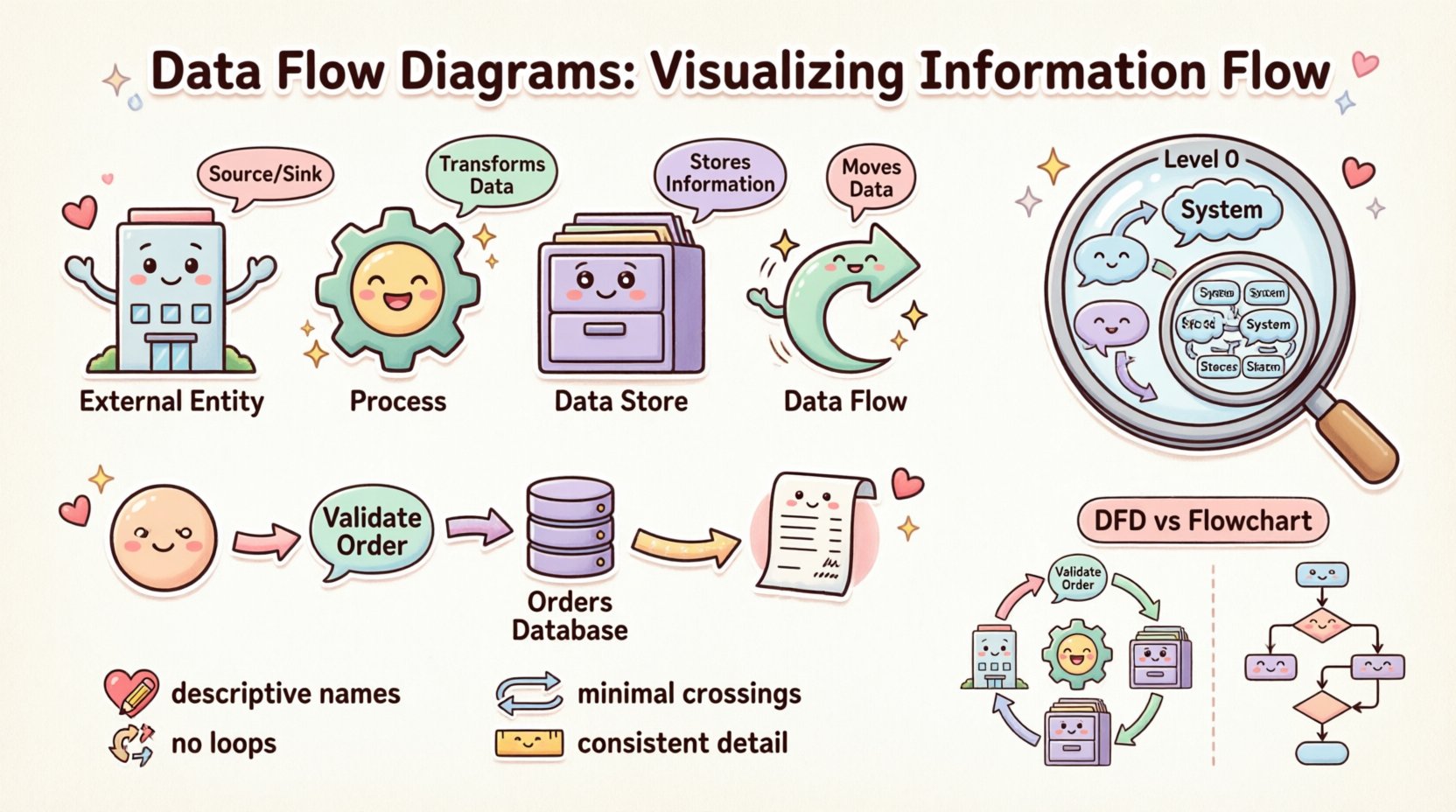
理解核心目的 🎯
数据流图的主要功能是描述什么系统做什么,而不是如何它如何实现。这一区别在需求收集阶段至关重要。虽然代码片段或数据库模式展示了实现方式,但数据流图展示的是系统的行为。它充当系统逻辑的蓝图。
以银行应用程序为例。流程图可能展示用户点击按钮的顺序。而数据流图则关注资金从用户账户流向交易账本的过程。它突出了数据的转换。这种抽象使分析师能够与非技术利益相关者讨论系统的逻辑,而不会引起混淆。
为什么可视化很重要
- 沟通: 它弥合了业务需求与技术实现之间的差距。
- 分析: 它揭示了缺失的数据点或冗余的流程。
- 文档: 它可作为未来维护和更新的参考。
- 验证: 它有助于验证所有数据输入是否都被记录并正确处理。
四个基本组成部分 🧱
每个数据流图都由四个基本构建模块构成。理解这些元素是绘制准确图表的前提。每个组件在信息流生态系统中都扮演着特定角色。
1. 外部实体(源与汇) 🏢
外部实体代表存在于被分析系统边界之外的人、组织或其他系统。它们作为进入系统的数据来源,或数据离开系统的终点。
- 术语: 通常被称为源、汇或参与者。
- 功能: 它们启动一个过程或接收最终输出。
- 示例: 客户、银行、供应商或外部支付网关。
2. 处理过程(转换) ⚙️
过程表示将输入数据转换为输出数据的活动。它们是图表中的主动元素。过程会改变数据的状态或形式。
- 术语: 也称为功能或转换。
- 功能: 它接收数据,对其进行修改,然后发送出去。
- 示例: “计算税款”、“验证用户登录”或“生成发票”。
3. 数据存储(内存) 🗄️
数据存储表示信息被保存以供后续使用的场所。它们不会主动发起动作,而是在系统边界内保留数据。这可能是一个物理数据库、一个文件,甚至在传统系统中是一张物理档案柜。
- 术语: 数据库、文件、仓库或队列。
- 功能: 数据的存储与检索。
- 示例: “客户数据库”、“订单历史日志”或“库存文件”。
4. 数据流(流动) 🔄
数据流表示实体、过程和存储之间信息的流动。它们是将图表连接在一起的纽带。数据流必须有一个名称,用以描述所传输的信息。
- 术语: 箭头、流或线条。
- 功能: 将数据从点A传输到点B。
- 方向: 流向具有方向性。从过程指向存储的箭头表示写入数据;从存储指向过程的箭头表示读取数据。
比较各个组件
为了确保清晰,将这些组件并列对比会很有帮助。此表格概述了每个元素在图表结构中所扮演的独立角色。
| 组件 | 角色 | 符号形状 | 回答的问题 |
|---|---|---|---|
| 外部实体 | 源/汇 | 矩形 | 谁或什么与系统交互? |
| 处理 | 转换器 | 圆形或圆角矩形 | 对数据进行了哪些工作? |
| 数据存储 | 存储库 | 开放矩形 | 数据保存在哪里? |
| 数据流 | 运输者 | 箭头 | 数据如何移动? |
抽象层次 📉
单一图表很少能捕捉整个系统的复杂性。为了管理这种复杂性,数据流图(DFD)会在不同详细程度下创建。这种技术被称为分解。它使分析人员能够深入或跳出系统架构。
上下文图(第0层) 🌍
上下文图是最高层次的视图。它将整个系统表示为一个单一的处理过程。它定义了系统的边界,并识别出所有与系统交互的外部实体。该图回答的问题是:“系统的总体目的是什么?”
- 范围:一个核心处理过程。
- 细节:极少。仅显示主要的输入和输出。
- 目标:为利益相关者定义系统边界。
第1层图(主要过程) 🔍
在确立上下文后,核心过程被分解为主要的子过程。此第1层图将系统分解为其主要功能区域。它展示了数据在这些主要组件与外部实体之间如何流动。
- 范围:3到7个主要过程。
- 细节: 高层次的内部交互。
- 目标: 理解主要的功能模块。
第二级图(详细流程)🔬
第二级进行进一步的分解。第一级中的特定流程被拆分为更细粒度的步骤。这是逻辑变得具体的地方。通常用于开发团队理解编码所需的精确需求。
- 范围: 详细子流程。
- 详细信息: 具体的数据转换。
- 目标: 指导实现和逻辑设计。
平衡概念 ⚖️
在创建DFD时,一个关键规则是平衡。父流程的输入和输出必须与子图(下一级)的输入和输出相匹配。如果一级流程接收“订单数据”,那么该流程在二级的分解不能随意消失这些数据;它仍必须将“订单数据”作为输入。
违反平衡规则会导致系统模型不一致。这暗示数据凭空产生或无影无踪地消失。保持平衡可确保系统在所有抽象层级上的逻辑完整性。
数据流图与流程图 🆚
人们常常混淆数据流图与流程图。尽管它们在视觉上相似,但其目的和结构存在显著差异。
- 流程图: 关注 控制流。它们展示步骤、决策和循环的顺序。它们回答“接下来会发生什么?”通常用于描述特定算法或用户界面交互的逻辑。
- 数据流图: 关注 数据流。它们展示信息的流动。它们回答“数据去往何处?”通常不会明确显示循环或决策点;而是展示数据的转换。
使用错误的图表类型会使开发团队感到困惑。如果需要记录带有错误处理的用户登录流程,流程图更合适。如果需要记录用户数据如何从表单流向数据库,数据流图则更为恰当。
清晰度的最佳实践 ✨
创建数据流图是一项需要自律的练习。遵循既定的规范可确保图表在长时间内保持可读性和实用性。
1. 命名规范 📝
标签必须具有描述性。避免使用“流程1”或“数据A”等模糊术语。对于流程,应使用动词+名词的组合,例如“验证密码”。对于数据流,应使用描述内容的名词,例如“收货地址”或“付款收据”。一致的命名有助于用户无需猜测即可浏览图表。
2. 避免数据流循环 🚫
数据流不应立即循环回到同一处理过程。虽然数据在经过其他组件后可以返回到某个过程,但直接的自循环通常表明存在逻辑错误或对过程边界的误解。一个过程应接收输入,对其进行转换,然后输出。如果它直接将输出返回到自身,就意味着无限处理。
3. 最小化交叉 🧵
杂乱的图表是无用的图表。应合理安排组件,使数据流自然进行,通常从左到右或从上到下。尽量减少箭头交叉的数量。如果线条交叉,追踪特定数据的路径就会变得困难。使用曲线或断点来保持视觉流畅性。
4. 保持一致的粒度 📏
在单个图表中,细节层次应保持一致。不要将高层次的过程与低层次的子过程混在一起。如果一个过程被分解为三个步骤,那么该视图中的所有其他主要过程也应处于相同的分解层次。
常见陷阱与解决方案 ⚠️
即使是经验丰富的分析师在绘制图表时也会遇到错误。识别这些常见陷阱可以在评审过程中节省时间。
黑洞
当一个过程有输入但没有输出时,就会出现“黑洞”。数据进入该过程后便消失了。这通常表明缺少数据存储或缺少与外部实体的数据流。每个接收数据的过程都必须产生某种结果。
奇迹过程
这是黑洞的相反情况。奇迹过程有输出但没有输入。它在不消耗任何信息的情况下生成数据。这在物理上是不可能的。每个输出都必须源自某种输入数据。
幽灵数据
幽灵数据指的是那些被暗示但未画出的数据流。如果一个过程需要客户ID才能运行,但没有箭头将ID引入该过程,那么逻辑就是不完整的。每个数据需求都必须明确连接。
外部实体混淆
分析师有时会将内部组件误认为外部实体。如果一个组件属于系统边界之内,它就是一个过程或存储。如果它在系统之外,它就是一个实体。绘制边界线有助于明确区分这一点。
融入开发生命周期 🛠️
数据流图不是静态的产物;它们是随着项目不断演进的活文档。它们在软件开发生命周期的各个阶段都发挥着作用。
- 需求收集: DFD通过可视化数据如何进入和离开业务,帮助捕捉用户需求。它们验证所有必需的数据点是否已被识别。
- 系统设计: 它们指导数据库设计。DFD中的数据存储直接转化为数据库模式中的表或集合。
- 测试: 测试用例可以从数据流中推导出来。如果图表中存在某个数据流,就必须对其进行测试以确保数据完整性。
- 维护: 当发生变更时,DFD会被更新。它提供了一个高层次的概览,有助于新团队成员快速理解系统。
可视化心理学 🧠
为什么我们依赖图表而不是文字?人类大脑处理视觉信息的速度远快于文字。DFD利用空间推理来组织复杂逻辑,使观察者能够看到在一段文字中可能被忽略的关系。
当利益相关者看到图表时,他们能立即发现缺失的连接。箭头之间的空缺比需求文档中的空白更显眼。这种视觉上的即时性降低了误解的风险,有助于团队建立共享的心理模型。
数据可视化的未来 🔮
随着系统变得更加分布式和云原生,DFD的作用依然重要。现代系统涉及微服务、API和第三方集成。这些本质上都是外部实体和数据流。
自动化文档工具正开始从代码仓库生成数据流图(DFD)。尽管这些工具有助于保持一致性,但仍需人工审查以确保流程的逻辑正确性。无论技术栈如何,分解和平衡的核心原则始终保持不变。
战略价值摘要 💡
数据流图提供了一种结构化的方法来理解信息系统。它们将复杂性分解为可管理的组件。它们促进了技术团队与非技术团队之间的沟通。它们为数据库设计和流程优化奠定了基础。
通过遵循平衡、清晰命名和适当抽象的原则,分析人员可以创建经得起时间考验的图表。无论是构建新应用还是审计现有系统,数据流图始终是可视化信息流的基本工具。它将抽象的逻辑转化为具体的地图,指导开发并确保与业务目标保持一致。
当你下次开展系统分析任务时,请记住清晰是目标。使用数据流图来描绘数据的旅程。确保每条信息都有来源、目的地和路径。这种严谨性将带来更稳健的系统和更少的误解。