











创建数据流图(DFD)是系统分析与设计中的关键步骤。这些视觉化表示方法描绘了数据在系统中的流动,突出显示输入、输出和存储。当准确绘制时,DFD可作为开发人员和利益相关者的蓝图,确保所有人都理解信息的逻辑和流动。然而,创建精确的图表需要纪律性并遵循特定标准。本指南概述了在不依赖特定软件工具的情况下,绘制有效数据流图的基本实践。
🔍 理解DFD的目的
在深入细节之前,理解这些图表为何重要至关重要。数据流图并非流程图,它不展示控制流或类似“如果-那么”语句的决策点。相反,它严格聚焦于数据本身。它回答的问题包括:数据来自何处?它将去往何处?它是如何被转换的?它被保存在何处?
- 沟通工具: 它弥合了技术团队与业务利益相关者之间的差距。
- 分析辅助: 它有助于识别瓶颈、缺失的数据或冗余流程。
- 设计基础: 它为数据库设计和代码架构提供了结构基础。
🧱 DFD的核心组件
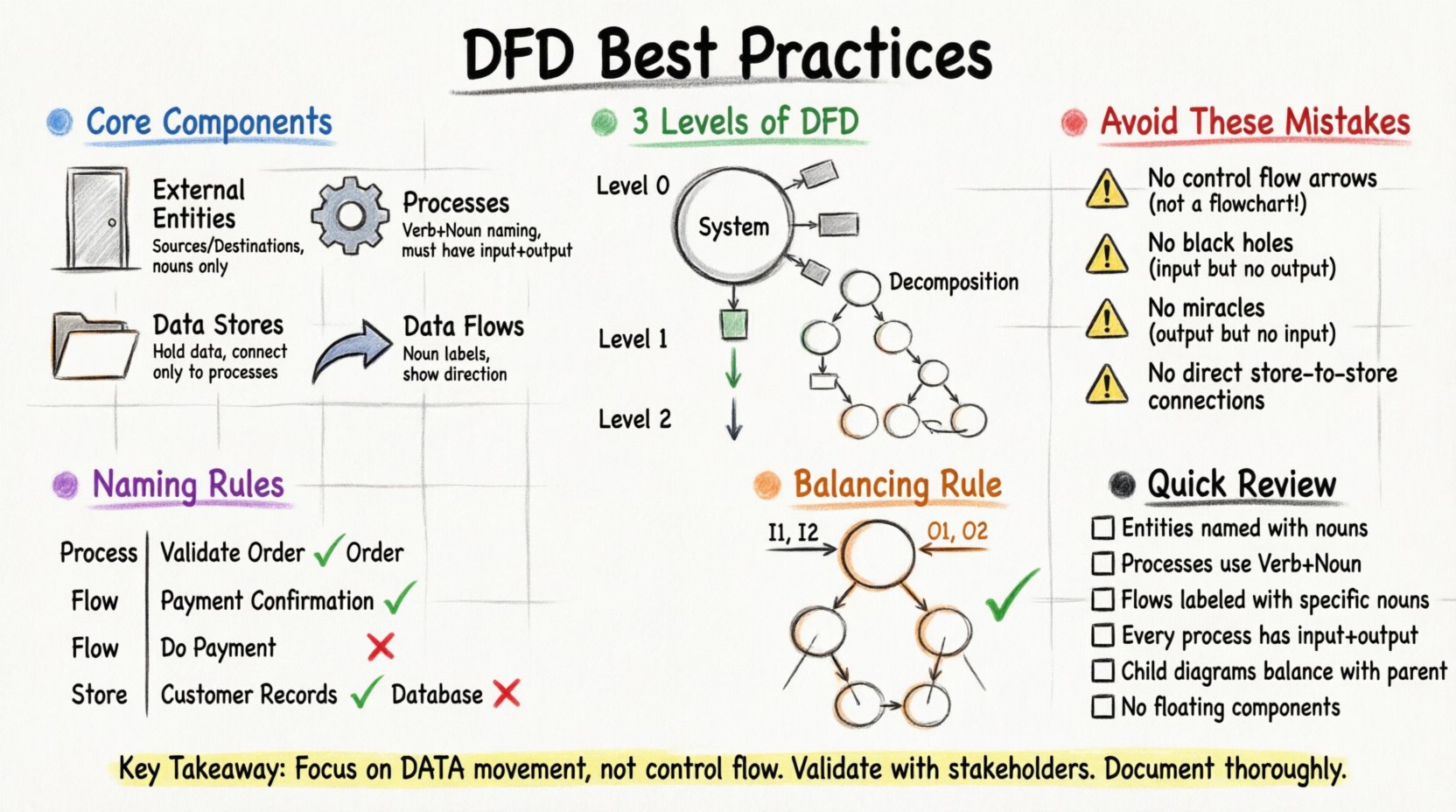
要绘制准确的图表,必须掌握四种基本符号。每个符号都有严格的定义,必须遵循以保持一致性。
1. 外部实体(源与目标) 🚪
它们代表与您的系统交互的人、组织或系统。它们是您范围的边界。数据从它们流入或流出。它们本身不属于系统。
- 示例: 客户、供应商或外部支付网关。
- 规则: 不要将系统内部的用户与外部实体混淆。只有外部源或汇点才属于此处。
2. 处理过程(转换) ⚙️
处理过程是数据发生变化的地方。它们接收输入数据,对其进行操作,并生成输出数据。它们是系统的核心。每个处理过程都必须至少有一个输入和一个输出。
- 示例: 计算税款、验证登录、生成报告。
- 规则: 使用动词命名处理过程。处理过程是一种动作,而非名词。
3. 数据存储(仓库) 📂
数据存储用于保存后续使用的数据。它们代表数据库、文件,甚至物理文件柜。与处理过程不同,数据存储不会改变数据,仅用于保存。
- 示例: 客户数据库、订单日志、库存清单。
- 规则: 数据存储必须与处理过程相连。没有处理过程的参与,数据不能凭空出现或消失。
4. 数据流(移动) 🔄
这些是连接组件的箭头。它们表示数据移动的方向。每个箭头都必须有一个标签,准确描述正在移动的数据。
- 示例:订单详情、支付确认、用户凭证。
- 规则:箭头应使用名词进行标注,而不是动词。标签描述的是数据流的内容。
📉 数据流图中的抽象层次
复杂系统无法在单页上展示。通常的做法是将系统分解为多个层次,这被称为分解。
第0层:上下文图 🌍
上下文图是最高层次的视图。它将整个系统表示为一个单一的圆泡。它将这个单一过程与所有外部实体连接起来。它清晰地定义了系统的边界。
- 关注点:仅关注输入和输出。
- 细节:极少。不包含内部过程或数据存储。
第1层:主要过程 🔢
第1层将上下文图中的单一圆泡分解为主要的子过程。在这里,你开始看到系统的内部逻辑。它通常包含系统的主要功能区域。
- 关注点:主要功能组。
- 细节:包含主要的数据存储以及主要过程之间的数据流。
第2层:详细分解 🔍
第2层将第1层中的某个特定过程进行分解。当某个特定过程过于复杂,无法在第1层视图中理解时,就会使用此层次。
- 关注点:特定且复杂的操作。
- 细节:高度细化。展示该特定功能的每一步。
✍️ 命名规范以确保清晰
命名是数据流图中最常见的混淆来源。清晰的命名可以防止分析师与开发人员之间的误解。
过程名称
始终使用动词加名词的结构。这描述的是对数据执行的动作。
- 良好: “验证用户登录”
- 不良: “登录” 或 “用户登录流程”
数据流名称
使用表示移动数据包的特定名词。
- 良好: “已验证凭据”
- 不良: “登录数据” 或 “执行登录”
数据存储名称
使用表示数据集合的名词。
- 良好: “用户账户”
- 不良: “用户” 或 “数据库”
⚖️ 数据的平衡与守恒
DFD设计中最关键的规则之一是平衡性。当你将父过程分解为子过程时,输入和输出必须保持一致。
什么是平衡?
想象你有一个名为“处理订单”的一级过程。该过程接收“客户订单”并输出“发货确认”。如果你将“处理订单”分解为二级子过程,这些子过程合起来仍必须接收“客户订单”并生成“发货确认”。
为什么这很重要?
- 一致性: 它确保在分解过程中不会丢失任何数据。
- 可追溯性: 它使你能够从顶层追溯到底层的每一条数据。
- 验证: 它可以作为检查遗漏需求的手段。
如何检查平衡性
- 列出父过程的所有输入和输出。
- 列出子过程的所有输入和输出。
- 比较这两个列表。它们必须完全匹配。
🚫 需要避免的常见错误
即使是经验丰富的分析师也会犯错。避免这些常见陷阱将显著提高你图表的质量。
1. 将控制流与数据流混合
DFD 不是流程图。不要使用箭头来表示事件或决策的顺序。如果做出决策,数据仍然会流向处理结果的流程。箭头代表的是数据,而不是控制。
2. 黑洞与奇迹
- 黑洞: 一个有输入但无输出的流程。这意味着数据消失了,这在逻辑上是不可能的。
- 奇迹: 一个有输出但无输入的流程。这意味着数据凭空产生。
3. 未连接的组件
每个组件都必须通过数据流与至少一个其他组件相连。一个孤立的流程或断开连接的数据存储表示逻辑错误。
4. 没有流程的数据存储
数据存储不能直接相互交流。两个数据存储之间必须始终存在一个流程。这确保了数据在存储或检索之前经过验证或转换。
📋 DFD 审查检查清单
使用此表格在最终确定图表前验证你的工作。这能确保高精度标准。
| 检查 | 标准 | 通过/未通过 |
|---|---|---|
| 实体命名 | 所有外部实体是否都用名词命名? | ⬜ |
| 流程命名 | 所有流程是否都用动词+名词命名? | ⬜ |
| 数据流命名 | 所有数据流是否都用具体的名词标注? | ⬜ |
| 守恒性 | 每个流程是否至少有一个输入和一个输出? | ⬜ |
| 平衡 | 子图是否与父图的输入/输出匹配? | ⬜ |
| 连接性 | 是否存在未连接的组件? | ⬜ |
| 数据存储 | 数据存储是否仅与处理过程相连? | ⬜ |
| 外部实体 | 外部实体是否从不与其他实体相连? | ⬜ |
🔄 逻辑型与物理型DFD
区分系统的逻辑视图和物理视图非常重要。两者都有效,但用途不同。
逻辑型DFD
它关注业务需求。忽略系统实际是如何构建的。它回答“业务做什么?”
- 示例:“处理付款”是一个处理过程。
- 优点:即使技术发生变化,它依然有效。
物理型DFD
它关注实现。它回答“系统是如何构建的?”它包括具体的硬件、软件模块或人工任务。
- 示例:“运行信用卡API”或“在激光打印机上打印收据”。
- 优点:它能直接指导开发人员和工程师。
🤝 利益相关者参与
DFD是一种沟通工具。如果利益相关者不理解它,或者它不能反映他们的现实,那么它就毫无用处。
- 演示: 安排会议,逐步向利益相关者展示图表。
- 反馈循环: 允许利益相关者指出缺失的数据流或错误的流程名称。
- 验证: 确保图表与他们对业务运作方式的心理模型一致。
当利益相关者确认图表后,它在某种程度上就成为了一种合同。这证实了系统设计满足了业务需求。这降低了在开发周期后期需要返工的风险。
🛠️ 长期维护图表
系统会不断演变,需求也会变化。昨天准确的DFD今天可能已经过时。为了保持文档的价值,你必须持续维护它。
- 版本控制: 保留DFD不同版本的记录,以追踪随时间的变化。
- 更新触发条件: 制定规则,明确在什么情况下需要更新DFD(例如,新功能请求、流程变更)。
- 中心存储库: 将图表存储在全团队均可访问的位置。
🔎 深入探讨:处理复杂的数据流
有时,数据流会很复杂。它们可能携带多条信息,或根据条件发生变化。以下是处理这些情况而不使图表杂乱的方法。
数据分组
不要为每个单独的数据字段都画一个箭头。将相关数据分组为一个逻辑数据包。
- 示例: 不要分别为“姓名”、“地址”和“电话”单独画箭头,而是画一个标有“客户信息”的箭头。
条件流
虽然DFD通常不显示决策逻辑,但有时数据仅在特定条件下流动。你可以通过标注箭头来表明这一点。
- 示例: 将箭头标注为“已批准订单”,以区别于“已拒绝订单”。
📝 文档编写最佳实践
图表只是故事的一部分。你必须记录组件的定义,以确保清晰明了。
- 术语表: 为图表中使用的所有术语创建术语表(例如,“已验证用户”是如何定义的?)。
- 流程规范: 对于复杂的流程,编写一段简短的逻辑说明。
- 数据字典: 定义数据存储和数据流的结构。
文档支持图表。它提供了视觉符号无法传达的必要背景信息。没有它,图表就容易产生歧义。
🎯 关键要点总结
准确的数据流图建立在一致性、清晰性和严格遵守规则的基础上。通过遵循此处列出的实践,您可以创建出能有效传达系统逻辑的图表。
- 聚焦数据: 专注于数据流动,而非控制流。
- 使用一致的命名: 过程使用动词,数据使用名词。
- 谨慎分解: 保持各层级之间的平衡。
- 与利益相关者共同验证: 确保模型反映实际情况。
- 详细记录: 在图表旁提供背景信息。
花时间绘制准确的数据流图,能够减少开发错误并提升沟通清晰度,为任何系统分析项目奠定坚实基础。