











Xây dựng phần mềm cho đám mây đòi hỏi sự thay đổi trong tư duy. Các kiến trúc truyền thống dạng khối thường dựa vào các thành phần gắn kết chặt chẽ chia sẻ bộ nhớ và hệ thống tệp cục bộ. Tuy nhiên, các ứng dụng nhạy cảm với đám mây hoạt động trên môi trường phân tán, thường xuyên trải dài qua nhiều mạng lưới và ranh giới bảo mật khác nhau. Để vượt qua sự phức tạp này, các kỹ sư cần có những biểu diễn trực quan rõ ràng về cách thông tin di chuyển trong hệ thống. Đây chính là lúc sơ đồ luồng dữ liệu (DFD) trở thành công cụ thiết yếu. Bằng cách mô phỏng luồng dữ liệu giữa các quá trình, kho lưu trữ và các thực thể bên ngoài, các đội ngũ có thể thiết kế các hệ thống bền vững, mở rộng được và an toàn mà không cần dựa vào suy đoán.
Hướng dẫn này khám phá cách áp dụng các nguyên tắc DFD một cách cụ thể vào bối cảnh nhạy cảm với đám mây. Chúng ta sẽ xem xét các thành phần cốt lõi, những điều chỉnh cần thiết cho các hệ thống phân tán, và các bước thực tế để tạo ra các sơ đồ vẫn hữu ích khi hạ tầng thay đổi. Dù bạn đang thiết kế một hệ sinh thái microservices hay một chuỗi hàm serverless, việc hiểu rõ về chuyển động dữ liệu chính là nền tảng của kỹ thuật đáng tin cậy.
🌩️ Hiểu rõ sự chuyển dịch sang mô hình hóa nhạy cảm với đám mây
Trong môi trường truyền thống tại chỗ, một hệ thống thường tồn tại trong một ranh giới vật lý duy nhất. Dữ liệu di chuyển cục bộ giữa các quá trình. Trong môi trường nhạy cảm với đám mây, các ranh giới trở nên linh hoạt. Một ứng dụng logic duy nhất có thể bao gồm hàng chục dịch vụ độc lập đang chạy trong các container, được điều phối qua các khu vực hoặc vùng sẵn sàng khác nhau. Độ trễ mạng, tính nhất quán tạm thời và các chính sách bảo mật tạo ra những biến số không tồn tại trong các thiết kế dạng khối.
Khi tạo sơ đồ luồng dữ liệu cho môi trường này, bạn phải tính đến:
- Ranh giới mạng lưới:Dữ liệu thường xuyên vượt qua các mạng công cộng hoặc các VPC bảo mật. Mỗi lần chuyển tiếp đại diện cho một điểm tiềm ẩn có thể gây lỗi hoặc độ trễ.
- Quản lý trạng thái:Các dịch vụ đám mây thường không lưu trạng thái. Các quá trình phải truy xuất trạng thái từ các kho lưu trữ bên ngoài thay vì giữ nó trong bộ nhớ.
- Giao tiếp bất đồng bộ:Các lời gọi đồng bộ (yêu cầu-đáp ứng) không phải lúc nào cũng phù hợp nhất. Các hàng đợi tin nhắn và luồng sự kiện thay đổi cách dữ liệu di chuyển giữa các thành phần.
- Vùng bảo mật:Dữ liệu đi vào một khu vực phải được xác thực và mã hóa trước khi đến được các quá trình nội bộ.
Việc trực quan hóa các ràng buộc này từ sớm giúp ngăn ngừa nợ kiến trúc. Một sơ đồ bỏ qua việc phân đoạn mạng lưới hoặc yêu cầu không lưu trạng thái sẽ dẫn đến hệ thống khó gỡ lỗi và mở rộng. Mục tiêu không chỉ là hiển thị dữ liệu đi đến đâu, mà còn làm nổi bật nơi dữ liệu được chuyển đổi, lưu trữ và bảo vệ.
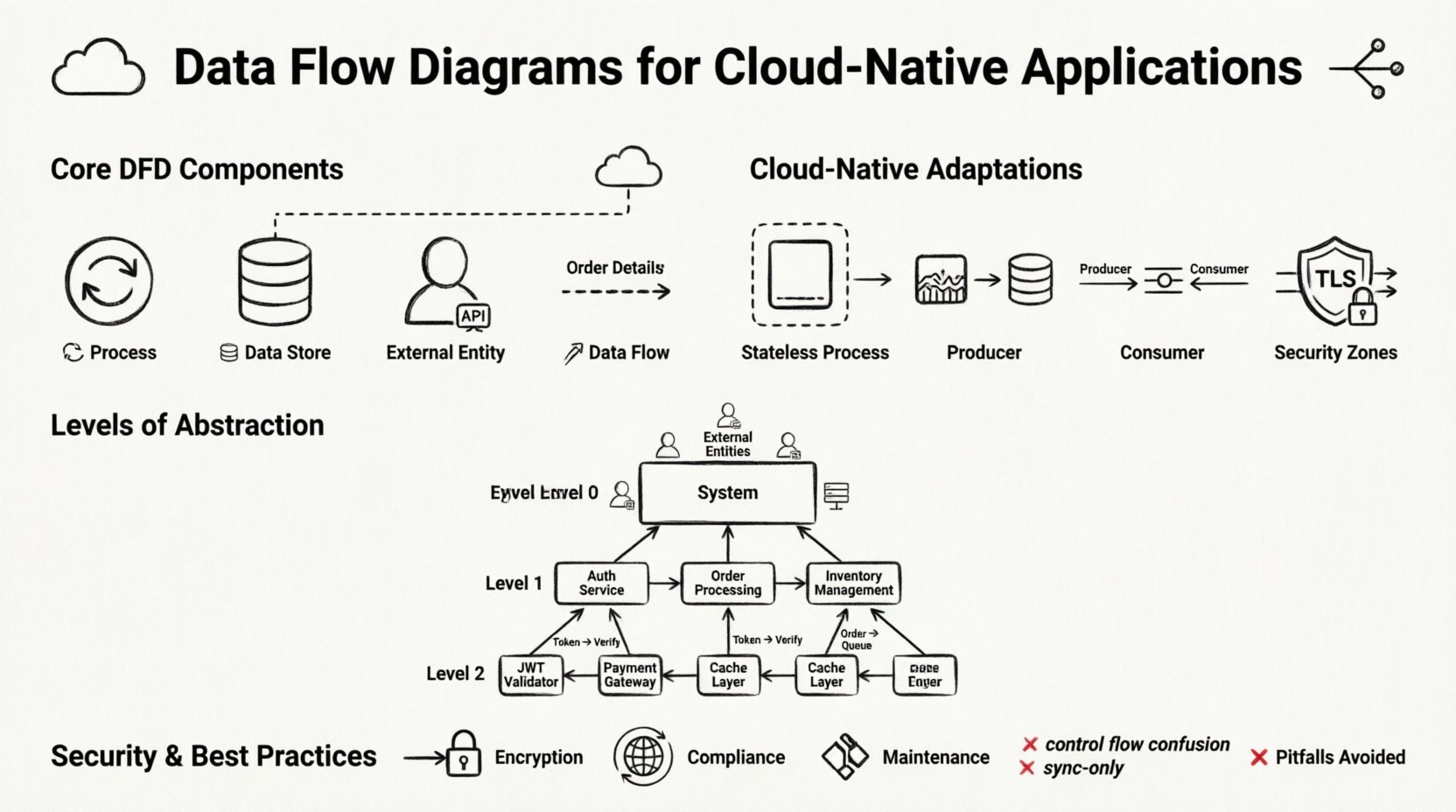
🧩 Các thành phần cốt lõi của sơ đồ luồng dữ liệu
Trước khi điều chỉnh các sơ đồ này cho đám mây, chúng ta cần xác lập các khối xây dựng chuẩn. Sơ đồ luồng dữ liệu (DFD) không phải là sơ đồ luồng; nó không thể hiện logic điều khiển hay thời gian. Nó thể hiện sự di chuyển của dữ liệu. Bốn thành phần chính vẫn giữ nguyên, ngay cả trong các hệ thống phân tán.
1. Các quá trình 🔄
Một quá trình đại diện cho một hoạt động biến đổi dữ liệu đầu vào thành dữ liệu đầu ra. Trong bối cảnh nhạy cảm với đám mây, một quá trình thường là một hàm, một ứng dụng được đóng gói trong container hoặc một thể hiện microservice. Rất quan trọng khi đặt tên cho các quá trình dựa trên việc chúng làm gì, chứ không phải tên kỹ thuật. Ví dụ, thay vì “API UserService”, hãy dùng “Xác thực thông tin đăng nhập người dùng”. Điều này giúp sơ đồ tập trung vào logic chuyển đổi dữ liệu.
- Chuyển đổi:Mọi quá trình đều phải thay đổi dữ liệu theo một cách nào đó. Nếu dữ liệu đi qua mà không bị thay đổi, thì nó không nên được biểu diễn như một quá trình.
- Bao đóng:Trong microservices, mỗi quá trình đều được bao đóng. Logic bên trong bị ẩn đi; chỉ có các giao diện đầu vào và đầu ra là quan trọng đối với sơ đồ.
- Không lưu trạng thái:Hầu hết các quá trình đám mây đều tạm thời. Chúng không lưu lại bộ nhớ về các tương tác trước đó. Điều này phải được phản ánh trong yêu cầu luồng dữ liệu.
2. Kho lưu trữ dữ liệu 🗄️
Một kho lưu trữ dữ liệu đại diện cho nơi dữ liệu được lưu trữ khi không đang được xử lý. Trong đám mây, điều này có thể là cơ sở dữ liệu quan hệ, kho tài liệu NoSQL, thùng lưu trữ đối tượng hoặc bộ nhớ đệm phân tán. Khác với hệ thống tệp, các kho lưu trữ dữ liệu đám mây thường được truy cập qua mạng lưới.
- Bền vững:Dữ liệu phải được lưu vào kho nếu nó cần tồn tại sau khi quá trình bị lỗi hoặc khởi động lại.
- Mô hình truy cập: Các kho lưu trữ chủ yếu đọc khác với các kho lưu trữ chủ yếu ghi. Sơ đồ nên chỉ ra loại truy cập nếu nó ảnh hưởng đáng kể đến kiến trúc.
- Bảo mật:Các kho lưu trữ dữ liệu nhạy cảm yêu cầu các kiểm soát truy cập khác nhau. Sự phân biệt này rất quan trọng đối với các cuộc kiểm toán bảo mật.
3. Các thực thể bên ngoài 👥
Các thực thể bên ngoài là nguồn hoặc điểm đến của dữ liệu nằm ngoài ranh giới hệ thống. Chúng có thể là người dùng, các API bên thứ ba, các hệ thống cũ, hoặc các thiết bị phần cứng. Trong sơ đồ hướng tới đám mây, các thực thể bên ngoài thường đại diện cho biên giới của internet hoặc các dịch vụ đám mây khác.
- Được tin cậy so với Không được tin cậy:Phân biệt dữ liệu đến từ một dịch vụ nội bộ đã biết so với lưu lượng truy cập từ internet công cộng.
- Kích hoạt:Các thực thể thường khởi tạo luồng dữ liệu. Một yêu cầu từ người dùng kích hoạt một quá trình; một công việc được lên lịch sẽ kích hoạt việc đồng bộ hóa dữ liệu.
4. Luồng dữ liệu 📡
Các luồng dữ liệu là những mũi tên kết nối các thành phần. Chúng đại diện cho việc truyền dữ liệu. Trong môi trường đám mây, các luồng này thường đi qua mạng. Các nhãn trên mũi tên là rất quan trọng. Chúng nên mô tả gói dữ liệu, chứ không phải giao thức. Ví dụ, hãy gán nhãn mũi tên là “Chi tiết đơn hàng” thay vì “HTTP POST”. Điều này giúp sơ đồ không phụ thuộc vào giao thức và có thể thích nghi trong tương lai.
- Hướng đi:Các luồng là một chiều. Nếu dữ liệu di chuyển qua lại, hãy vẽ hai mũi tên riêng biệt.
- Khối lượng:Các luồng dữ liệu khối lượng cao có thể yêu cầu hạ tầng khác biệt (ví dụ: băng thông riêng) so với các luồng điều khiển khối lượng thấp.
- Mã hóa:Các luồng đi qua các ranh giới bảo mật phải được đánh dấu là đã mã hóa để nhấn mạnh các yêu cầu tuân thủ.
☁️ Điều chỉnh DFD cho các hệ thống phân tán
Các DFD tiêu chuẩn giả định một hệ thống thống nhất. Các hệ thống hướng tới đám mây là phân tán. Để DFD trở nên hữu ích trong bối cảnh này, bạn phải mô hình hóa rõ ràng bản chất phân tán của hạ tầng. Điều này bao gồm việc thêm các lớp trừu tượng đại diện cho kiến trúc mạng và ranh giới dịch vụ.
Ranh giới dịch vụ
Các microservice là các khối xây dựng tiêu chuẩn cho các ứng dụng hướng tới đám mây. Mỗi dịch vụ nên là một quá trình riêng biệt trong sơ đồ của bạn. Tuy nhiên, việc vẽ từng dịch vụ riêng lẻ có thể dẫn đến sự lộn xộn. Một cách tiếp cận phổ biến là nhóm các dịch vụ liên quan vào một miền logic, chẳng hạn như “Miền hóa đơn” hoặc “Miền quản lý người dùng”. Điều này giúp bạn nhìn thấy luồng cấp cao trong khi giữ kín độ phức tạp bên trong.
Cổng API
Hầu hết các ứng dụng hướng tới đám mây đều nằm phía sau một Cổng API hoặc Bộ cân bằng tải. Thành phần này hoạt động như điểm vào duy nhất. Trong DFD, cổng là một quá trình định tuyến yêu cầu. Nó xử lý xác thực, giới hạn tốc độ và chuyển đổi giao thức. Không nên coi cổng như một ống dẫn đơn thuần; nó thực sự thay đổi luồng dữ liệu.
Kiến trúc dựa trên sự kiện
Nhiều hệ thống hiện đại sử dụng mẫu dựa trên sự kiện. Một nhà sản xuất tạo ra một sự kiện, và người tiêu dùng xử lý nó sau này. Điều này phá vỡ mối liên kết đồng bộ giữa quá trình và luồng dữ liệu. Trong DFD, bạn biểu diễn điều này bằng cách sử dụng hàng đợi sự kiện hoặc luồng như một kho lưu trữ dữ liệu. Nhà sản xuất ghi sự kiện; người tiêu dùng đọc nó. Việc tách rời này rất quan trọng đối với độ bền.
| Thành phần | Hệ thống monolith truyền thống | Sự thích nghi với hệ thống hướng tới đám mây |
|---|---|---|
| Quá trình | Hàm trong bộ nhớ | Dịch vụ vi mô được đóng gói trong container / Hàm không máy chủ |
| Kho lưu trữ dữ liệu | Tập tin cục bộ / Cơ sở dữ liệu SQL | Cơ sở dữ liệu đám mây được quản lý / Lưu trữ đối tượng |
| Luồng | Gọi bộ nhớ cục bộ | HTTP / gRPC / Hàng đợi tin nhắn |
| Trạng thái | Bộ nhớ chia sẻ | Kho lưu trữ trạng thái bên ngoài |
📉 Các mức độ trừu tượng trong kiến trúc đám mây
Các hệ thống phức tạp yêu cầu nhiều mức độ biểu đồ. Việc cố gắng ghi lại mọi chi tiết trong một cái nhìn duy nhất sẽ dẫn đến sự nhầm lẫn. Cách tiếp cận DFD tiêu chuẩn với các mức 0, 1 và 2 hoạt động tốt cho các hệ thống đám mây khi được áp dụng đúng cách.
Mức 0: Sơ đồ ngữ cảnh
Sơ đồ ngữ cảnh hiển thị toàn bộ hệ thống như một quá trình duy nhất. Nó làm nổi bật các thực thể bên ngoài tương tác với hệ thống. Đối với ứng dụng đám mây, điều này xác định ranh giới. Nó trả lời câu hỏi: ‘Điều gì vào hệ thống, và điều gì ra khỏi hệ thống?’ Đây là góc nhìn cấp cao nhất, hữu ích cho các bên liên quan cần hiểu phạm vi mà không cần chi tiết kỹ thuật.
- Trọng tâm:Ranh giới hệ thống và các giao diện bên ngoài.
- Chi tiết:Tối thiểu. Một quá trình trung tâm.
- Trường hợp sử dụng:Xác định phạm vi dự án và lập kế hoạch bảo mật cấp cao.
Mức 1: Các quá trình chính
Mức 1 chia quá trình trung tâm thành các tiểu quá trình chính. Trong bối cảnh đám mây gốc, đây thường là các lĩnh vực chức năng chính. Ví dụ, sơ đồ mức 1 cho một nền tảng thương mại điện tử có thể hiển thị ‘Xử lý đơn hàng’, ‘Quản lý kho hàng’ và ‘Xử lý thanh toán’ như các quá trình riêng biệt. Mức độ này tiết lộ cách dữ liệu di chuyển giữa các nhóm dịch vụ chính.
- Trọng tâm:Các mô-đun chức năng chính và sự tương tác giữa chúng.
- Chi tiết:Đầu vào và đầu ra cho mỗi mô-đun chính.
- Trường hợp sử dụng:Xem xét kiến trúc và phân rã dịch vụ.
Mức 2: Logic chi tiết
Mức 2 đi sâu vào các tiểu quá trình cụ thể. Đây là nơi các chi tiết triển khai kỹ thuật trở nên quan trọng. Ví dụ, quá trình ‘Xử lý thanh toán’ có thể được mở rộng để hiển thị ‘Xác thực thẻ’, ‘Nạp tiền tài khoản’ và ‘Cập nhật hóa đơn’. Mức độ này được sử dụng bởi các nhà phát triển triển khai các dịch vụ cụ thể.
- Tập trung:Logic nội bộ của các dịch vụ cụ thể.
- Chi tiết:Các phép biến đổi dữ liệu cụ thể và các kho lưu trữ dữ liệu cục bộ.
- Trường hợp sử dụng:Các tình huống triển khai phát triển và kiểm thử.
🔒 Bảo mật và tuân thủ trong bản đồ dữ liệu
Bảo mật không phải là điều được xem xét sau cùng trong phát triển ứng dụng gốc đám mây; nó là một yêu cầu thiết kế. Sơ đồ luồng dữ liệu là công cụ tuyệt vời để xác định các rủi ro bảo mật. Bằng cách theo dõi hành trình của dữ liệu, bạn có thể phát hiện nơi thông tin nhạy cảm có thể bị lộ hoặc lưu trữ không đúng cách.
Xác định dữ liệu nhạy cảm
Không phải mọi luồng dữ liệu đều giống nhau. Thông tin nhận dạng cá nhân (PII), hồ sơ tài chính và dữ liệu sức khỏe đòi hỏi xử lý nghiêm ngặt hơn. Trong sơ đồ của bạn, hãy đánh dấu các luồng chứa dữ liệu nhạy cảm. Điều này đảm bảo rằng mọi quy trình tiếp xúc với dữ liệu này đều được xem xét về mặt tuân thủ.
- Mã hóa trong quá trình truyền:Các luồng vượt qua ranh giới mạng phải được mã hóa (TLS/SSL). Hãy đánh dấu rõ ràng các luồng này.
- Mã hóa khi lưu trữ:Các kho lưu trữ dữ liệu chứa thông tin nhạy cảm phải được mã hóa. Hãy ghi chú điều này trong nhãn kho lưu trữ.
- Kiểm soát truy cập:Xác định quy trình nào được phép đọc hoặc ghi vào các kho lưu trữ dữ liệu cụ thể. Điều này giúp thiết lập kiểm soát truy cập dựa trên vai trò (RBAC).
Ranh giới tuân thủ
Các khu vực khác nhau có luật về chủ quyền dữ liệu khác nhau. Dữ liệu có thể cần phải ở lại trong một ranh giới địa lý cụ thể. Sơ đồ luồng dữ liệu giúp trực quan hóa các ràng buộc này. Nếu một quy trình ở Khu vực A gửi dữ liệu sang Khu vực B, luồng này cần được đánh dấu để xem xét pháp lý. Điều này ngăn ngừa vi phạm vô tình các quy định như GDPR hoặc CCPA.
⚠️ Những sai lầm phổ biến và cách tránh chúng
Việc tạo sơ đồ luồng dữ liệu cho hệ thống đám mây là thách thức. Có những sai lầm phổ biến mà các đội thường mắc phải, thường xuất phát từ việc cố gắng chuyển đổi các mẫu cũ sang môi trường mới. Tránh những sai lầm này đảm bảo sơ đồ của bạn vẫn chính xác và hữu ích.
1. Trộn lẫn logic điều khiển và luồng dữ liệu
Sơ đồ luồng dữ liệu không nên thể hiện logic điều khiển. Đừng vẽ mũi tên để chỉ “nếu điều này thì điều đó”. Sử dụng các điểm quyết định hoặc ghi chú bên ngoài cho logic, nhưng hãy giữ các mũi tên tập trung vào chuyển động dữ liệu. Trong các hệ thống đám mây, nơi logic điều khiển thường được xử lý bởi các nền tảng điều phối, sơ đồ luồng dữ liệu nên tập trung vào dữ liệu truyền tải.
2. Bỏ qua các luồng bất đồng bộ
Các hệ thống đám mây hiếm khi đồng bộ 100%. Các công việc chạy ngầm. Nếu bạn chỉ vẽ các luồng yêu cầu-đáp ứng đồng bộ, sơ đồ của bạn sẽ không đầy đủ. Luôn luôn bao gồm các công việc chạy ngầm và luồng sự kiện như các luồng dữ liệu vào hoặc ra khỏi kho lưu trữ dữ liệu.
3. Tối ưu hóa quá mức cho các công cụ cụ thể
Đừng thiết kế sơ đồ của bạn dựa trên khả năng của một công cụ hoặc nền tảng cụ thể. Nếu bạn chọn một cơ sở dữ liệu hoặc broker tin nhắn cụ thể, sơ đồ có thể trở nên lỗi thời khi bạn chuyển đổi công nghệ. Hãy tập trung vào luồng dữ liệu logic, chứ không phải triển khai vật lý.
4. Bỏ qua các luồng lỗi
Các hành trình thành công dễ vẽ. Các hành trình thất bại khó hơn nhưng cần thiết. Trong môi trường đám mây, các dịch vụ thường xuyên thất bại. Hãy chỉ rõ nơi dữ liệu lỗi được ghi nhật ký hoặc nơi cơ chế thử lại được kích hoạt. Điều này giúp thiết kế các hệ thống giám sát và cảnh báo mạnh mẽ.
🔄 Bảo trì sơ đồ theo thời gian
Một sơ đồ chỉ hữu ích nếu nó chính xác. Các ứng dụng gốc đám mây thay đổi nhanh chóng. Các dịch vụ mới được thêm vào, các dịch vụ cũ bị loại bỏ, và mô hình dữ liệu thay đổi. Nếu sơ đồ không khớp với hệ thống đang chạy, nó sẽ trở thành tài liệu gây hiểu lầm. Dưới đây là cách để bảo trì chúng.
- Kiểm soát phiên bản:Xem sơ đồ như mã nguồn. Lưu chúng vào hệ thống kiểm soát phiên bản cùng với mã nguồn ứng dụng của bạn. Điều này đảm bảo lịch sử và khả năng truy vết.
- Vòng kiểm tra:Bao gồm cập nhật sơ đồ trong quy trình kiểm tra mã nguồn. Nếu một nhà phát triển thay đổi luồng dữ liệu, sơ đồ phải được cập nhật trong cùng một commit hoặc yêu cầu kéo (pull request).
- Tự động hóa tạo dựng:Nơi có thể, hãy tạo sơ đồ từ mã nguồn hoặc định nghĩa hạ tầng dưới dạng mã. Điều này giúp giảm khoảng cách giữa tài liệu và thực tế.
- Đồng thuận với các bên liên quan:Thường xuyên xem xét sơ đồ cùng các bên liên quan không chuyên về kỹ thuật. Điều này đảm bảo mức độ trừu tượng vẫn phù hợp với đối tượng mục tiêu.
📋 So sánh DFD với các quan điểm kiến trúc khác
Rất phổ biến khi nhầm lẫn DFD với các sơ đồ khác như Sơ đồ thứ tự hoặc Sơ đồ kiến trúc hệ thống. Hiểu được sự khác biệt sẽ giúp bạn chọn đúng công cụ cho công việc.
| Loại sơ đồ | Chú trọng chính | Dùng tốt nhất cho |
|---|---|---|
| Sơ đồ luồng dữ liệu | Di chuyển và biến đổi dữ liệu | Thiết kế hệ thống, kiểm toán bảo mật, ánh xạ dữ liệu |
| Sơ đồ thứ tự | Tương tác dựa trên thời gian giữa các đối tượng | Tích hợp API, gỡ lỗi chuỗi gọi |
| Kiến trúc hệ thống | Hạ tầng và triển khai | DevOps, mở rộng, yêu cầu phần cứng |
| Thực thể – Quan hệ | Cấu trúc dữ liệu và mối quan hệ | Thiết kế cơ sở dữ liệu, lập kế hoạch lược đồ |
Một DFD bổ sung cho các quan điểm này. Trong khi sơ đồ kiến trúc cho thấy máy chủ được đặt ở đâu, thì DFD cho thấy thông tin di chuyển giữa chúng như thế nào. Trong khi sơ đồ thứ tự cho thấy thứ tự gọi, thì DFD cho thấy nội dung truyền tải. Sử dụng chúng cùng nhau sẽ cung cấp bức tranh toàn diện về hệ thống.
🚀 Xu hướng tương lai trong mô hình hóa đám mây
Khi công nghệ đám mây phát triển, nhu cầu về mô hình hóa cũng thay đổi theo. Sự trỗi dậy của tính toán không máy chủ (serverless) và tính toán biên (edge computing) mang lại những thách thức mới. Luồng dữ liệu đang trở nên phân tán hơn. Các quy trình đang chạy gần người dùng hơn. Sự thay đổi này đòi hỏi DFD phải tính đến các nút biên và các tài nguyên tính toán tạm thời.
Hơn nữa, việc tích hợp trí tuệ nhân tạo vào quy trình làm việc làm tăng thêm độ phức tạp. Các mô hình AI tiêu thụ dữ liệu và tạo ra thông tin hữu ích. Các quy trình này thường đòi hỏi dữ liệu lớn và phần cứng chuyên dụng. Các DFD tương lai sẽ cần biểu diễn các quy trình nặng về tính toán và các luồng dữ liệu cung cấp cho chúng. Các nguyên tắc cốt lõi vẫn giữ nguyên, nhưng độ chi tiết và phạm vi sẽ mở rộng.
Bằng cách tuân thủ các nguyên tắc cơ bản của Sơ đồ Luồng Dữ liệu trong khi thích nghi với thực tế của đám mây, các đội kỹ thuật có thể xây dựng các hệ thống minh bạch, an toàn và có thể mở rộng. Việc trực quan hóa dữ liệu không chỉ là một bài tập tài liệu hóa; đó là bước quan trọng trong quá trình thiết kế, giúp ngăn ngừa lỗi trước khi chúng xuất hiện trong môi trường sản xuất.