











Projektowanie solidnej architektury danych wymaga głębokiego zrozumienia, jak informacje się łączą, wzajemnie się odnoszą i utrwalają. W centrum tego projektowania znajduje się diagram relacji encji (ERD). Choć tradycyjnie kojarzony z bazami danych relacyjnymi, semantyka ERD ewoluowała, aby spełniać różne potrzeby nowoczesnych środowisk NoSQL. Ten przewodnik bada subtelności modelowania relacji danych w różnych paradygmatów przechowywania danych, zapewniając integralność strukturalną bez poświęcania wydajności.
Podstawowe koncepcje modelowania danych 🏗️
Zanim przejdziemy do konkretnych typów baz danych, konieczne jest ustalenie wspólnej terminologii. Diagram relacji encji pełni rolę wizualnego projektu. Określa encje (tabelki, kolekcje lub dokumenty), ich atrybuty (kolumny, pola lub właściwości) oraz relacje łączące je ze sobą.
- Encja: Odrębny obiekt lub pojęcie w zakresie domeny biznesowej. W kontekście bazy danych może to być Użytkownik, Produkt lub Zamówienie.
- Atrybut: Właściwość opisująca encję. Przykłady to id, nazwa, utworzono_w, lub status.
- Relacja: Powiązanie między dwiema encjami. Określa, jak dane w jednej encji łączą się z danymi w drugiej.
- Moc relacji: Aspekt liczbowy relacji. Określa, czy relacja jest jedno-do-jednego, jedno-do-wielu lub wiele-do-wielu.
Podczas tworzenia ERD celem jest odwzorowanie logiki rzeczywistego świata aplikacji. Dobrze skonstruowany diagram zmniejsza niepewność dla programistów i zapewnia, że zapytania mogą być pisać efektywnie w późniejszych etapach cyklu rozwoju.
Semantyka w środowiskach relacyjnych 🗃️
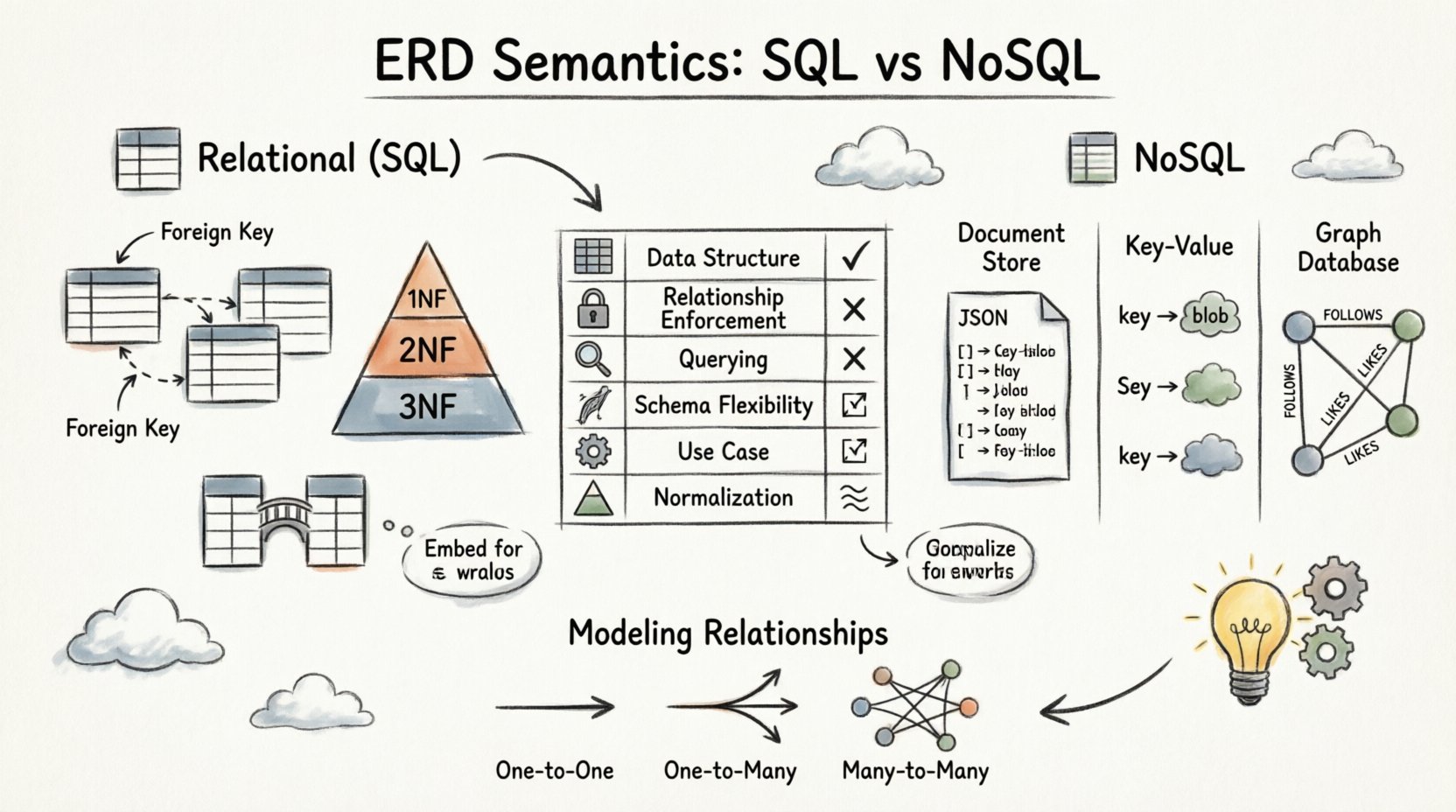
W modelu relacyjnym dane są przechowywane w tabelach z ściśle określonymi schematami. Semantyka ERD tutaj jest sztywna i kierowana zasadami teorii zbiorów oraz zasadą pierwszej postaci normalnej. Każda relacja jest wymuszana przez silnik bazy danych w celu zachowania integralności referencyjnej.
1. Rola kluczy obcych
Klucze obce są fundamentem ERD relacyjnych. Fizycznie łączą ze sobą tabele. Gdy ERD pokazuje linię łączącą dwie tabele, implementacja opiera się na kolumnie klucza obcego w tabeli potomnej, która odwołuje się do klucza podstawowego tabeli nadrzędnej.
- Realizacja: Wartość liczbową lub alfanumeryczną przechowywaną w kolumnie.
- Ograniczenie: Silnik bazy danych zapobiega powstawaniu zaniedbanych rekordów. Nie możesz wstawić wartości do kolumny klucza obcego, chyba że istnieje ona w odniesionej kolumnie klucza podstawowego.
- Kaskadowość: Działania na rekordzie nadrzędnym (usunięcie lub aktualizacja) mogą automatycznie rozprzestrzeniać się na rekordy potomne na podstawie zdefiniowanych reguł.
2. Normalizacja i integralność
Relacyjne schematy ERD priorytetowo ustawiają normalizację. Ten proces zmniejsza nadmiarowość danych poprzez grupowanie atrybutów w logiczne zbiory. Dobrze znormalizowany schemat ERD zwykle wygląda bardziej skomplikowanie ze względu na liczbę zaangażowanych tabel.
- 1NF: Zapewnia atomowość; każda komórka zawiera jedną wartość.
- 2NF: Usuwa zależności częściowe; atrybuty zależą od całego klucza głównego.
- 3NF: Usuwa zależności przechodnie; atrybuty niekluczowe zależą wyłącznie od klucza głównego.
Ta struktura zapewnia spójność danych. Jeśli użytkownik zmienia swoje imię, zmiana następuje w jednym miejscu, a każdy rekord odnoszący się do tego użytkownika widzi zmianę od razu.
3. Obsługa relacji wiele do wielu
Relacje wiele do wielu są semantycznie różne w systemach relacyjnych. Nie możesz bezpośrednio połączyć dwóch tabel w tym przypadku. Zamiast tego wymagana jest tabela pośrednia (tabela połączeniowa).
- Struktura: Tabela zawierająca klucze główne obu powiązanych encji.
- Funkcja: Ta tabela działa jako most, umożliwiając wielu rekordom w encji A łączenie się z wieloma rekordami w encji B.
- Zapytania: Pobieranie tych danych wymaga operacji
JOINoperacji, która może być obliczeniowo kosztowna na dużych zestawach danych, jeśli nie jest poprawnie indeksowana.
Semantyka w środowiskach NoSQL 📦
Bazy danych NoSQL oferują elastyczność. Semantyka schematu ERD przesuwa się od wymuszania struktury do reprezentacji logicznej. Diagram staje się bardziej przewodnikiem wzorców projektowych niż ścisłym definicją schematu. Różne modele NoSQL obsługują relacje w różny sposób.
1. Magazyny dokumentów i osadzanie
W bazach danych zorientowanych na dokumenty dane są przechowywane jako dokumenty podobne do JSON. Schemat ERD często sugeruje osadzanie powiązanych danych bezpośrednio w jednym dokumencie w celu zoptymalizowania wydajności odczytu.
- Jeden do wielu: Dokument nadrzędny może zawierać tablicę obiektów potomnych. Pozwala to uniknąć potrzeby łączenia podczas pobierania danych.
- Skutki: Aktualizacje danych potomnych wymagają ponownego zapisania całego dokumentu nadrzędnego. Może to prowadzić do zawieszeń, jeśli dokument nadrzędny stanie się bardzo duży.
- Odczyt w porównaniu do zapisu: Ten podejście optymalizuje odczyt. Zmienia wydajność zapisu i nadmiarowość danych na korzyść prędkości.
2. Magazyny klucz-wartość
Magazyny klucz-wartość traktują dane jako przezroczyste bloki danych. Semantyka ERD tutaj jest minimalna. Relacje są często wnioskowane przez warstwę aplikacji, a nie przez silnik bazy danych.
- Odwoływanie się:Dokumenty często zawierają identyfikator odwołania do innego dokumentu, podobnie jak klucz obcy, ale bez zapewnienia integralności.
- Odpowiedzialność:Logika aplikacji musi zapewnić, że odwołany identyfikator istnieje i jest poprawny. Nie ma ograniczeń na poziomie bazy danych.
- Przypadek użycia:Najlepsze do buforowania, zarządzania sesjami lub bardzo elastycznych struktur danych, gdzie relacje nie są głównym zagadnieniem.
3. Bazy danych grafowych
Bazy danych grafowych są specjalnie zaprojektowane pod relacje. Diagram ERD w tym kontekście od razu odpowiada węzłom i krawędziom. Jest to może najdosłowniejsze rozumienie diagramu encji-relacji.
- Węzły:Reprezentują encje (np. Osoba, Lokalizacja).
- Krawędzie:Reprezentują relacje (np. MIESZKA_W, ZNAJE).
- Właściwości:Węzły i krawędzie mogą mieć dołączone do nich atrybuty.
- Przechodzenie:Zapytania śledzą krawędzie. Relacja nie jest wyszukiwaniem; jest przejściem po ścieżce.
Porównawcza analiza podejść modelowania 📊
Zrozumienie różnic między tymi środowiskami pomaga w wyborze odpowiedniego narzędzia do zadania. Poniższa tabela przedstawia, jak semantyka ERD przekłada się na te systemy.
| Cecha | Relacyjna (SQL) | Magazyn dokumentów | Baza danych grafowych |
|---|---|---|---|
| Struktura danych | Tabele z wierszami i kolumnami | Dokumenty JSON | Węzły i krawędzie |
| Wymuszanie relacji | Klucze obce (ściśle) | Ręczne / Poziom aplikacji | Zaawansowane odniesienia krawędzi |
| Zapytania dotyczące relacji | Operacje JOIN | Wyszukiwanie lub osadzanie | Przechodzenie po ścieżkach |
| Elastyczność schematu | Stały schemat | Dynamiczny schemat | Półstrukturalne |
| Główny przypadek użycia | Integralność transakcji | Zarządzanie treścią / Hierarchie | Sieci / Grafy społecznościowe |
| Normalizacja | Wysoka (3NF / BCNF) | Niska (nienormalizowana) | Nie dotyczy |
Modelowanie relacji: głęboka analiza 🔗
Sposób przedstawienia relacji na diagramie ERD określa wzorce zapytań i charakterystyki wydajności aplikacji. Przeanalizujmy szczegółowo konkretne liczności.
Relacje jeden do jednego
Jest to najprostsza relacja. Jeden rekord w tabeli A odpowiada dokładnie jednemu rekordowi w tabeli B.
- Wdrożenie w SQL: Klucz obcy w jednej z tabel z ograniczeniem unikalności.
- Wdrożenie w NoSQL: Często łączone w jednym dokumencie, aby uniknąć wyszukiwań, lub przechowywane oddzielnie z unikalnym odniesieniem.
- Kiedy stosować: Profil użytkownika rozdzielony od szczegółów uwierzytelniania, lub ustawienia konfiguracyjne powiązane z konkretnymi środowiskami.
Relacje jeden do wielu
Jest to najpowszechniejszy typ relacji. Jeden rekord w tabeli A jest powiązany z wieloma rekordami w tabeli B.
- Realizacja w SQL: Klucz obcy w tabeli B odnoszący się do tabeli A.
- Magazyn dokumentów: Umieść stronę „Wiele” w dokumencie strony „Jeden” jako tablicę. Jest to wydajne przy odczytywaniu całej hierarchii naraz.
- Baza danych grafów: Utwórz krawędź od węzła „Jeden” do wielu węzłów „Wiele”.
- Uwaga: Jeśli strona „Wiele” znacznie wzrośnie, osadzenie w magazynie dokumentów może osiągnąć limity pamięci. Może być konieczne podejście hybrydowe (odniesienia zamiast osadzania).
Relacje wiele do wielu
Ta relacja wymaga mostu w SQL, ale zachowuje się inaczej w innych systemach.
- Realizacja w SQL: Tabela pośrednia zawierająca identyfikatory z obu tabel rodzicielskich.
- Magazyn dokumentów: Często nieznormalizowane. Każdy dokument zawiera listę identyfikatorów lub pełnych obiektów z powiązanej jednostki. Duplikuje dane, ale przyspiesza ich pobieranie.
- Baza danych grafów: To naturalna siła modelu. Węzły są połączone bezpośrednio bez tabeli pośredniej.
- Wyzwanie spójności: W magazynach dokumentów trudno utrzymać listy w synchronizacji między wieloma dokumentami. Aktualizacje wspólnej jednostki muszą być ręcznie przekazywane do wszystkich dokumentów odnoszących się do niej.
Ewolucja schematu i elastyczność 🔄
Wymagania oprogramowania się zmieniają. Modele danych muszą ewoluować bez naruszania istniejących aplikacji. Semantyka ERD decyduje o tym, jak łatwo może nastąpić ta ewolucja.
1. Migracja schematu w SQL
Zmiana schematu relacyjnego to istotna operacja. Często wymaga blokowania tabel lub uruchamiania migracji w czasie przestojów.
- Dodawanie kolumn: Ogólnie bezpieczne i szybkie.
- Zmiana nazw kolumn: Wymaga ponownego zapisania struktury tabeli oraz aktualizacji wszystkich zależnych zapytań.
- Zmiana typów danych: Może być ryzykowne, jeśli konwersja danych nie powiedzie się lub jeśli logika aplikacji opiera się na starym typie.
2. Elastyczność schematu w NoSQL
Systemy NoSQL ogólnie pozwalają na podejście bez schematu lub z schematem na czas odczytu. ERD jest wytyczna, a nie prawem.
- Dodawanie pól: Możesz dodać nowe pola do określonych dokumentów, nie wpływając na inne.
- Wersjonowanie: Często dodaje się numery wersji do dokumentów, aby zarządzać różnymi strukturami w czasie.
- Zalety i wady: Brak wymuszania oznacza, że mogą pojawić się problemy z jakością danych. Aplikacja musi weryfikować dane przed zapisem.
Skutki dotyczące wydajności wyboru modelowania ⚡
Struktura Twojego ERD bezpośrednio wpływa na szybkość zapytań. Nie ma uniwersalnego rozwiązania; projekt musi odpowiadać wzorców dostępu aplikacji.
1. Obciążenia zdominowane odczytami
Jeśli aplikacja często odczytuje dane, ale rzadko je aktualizuje, denormalizacja jest korzystna.
- Strategia: Wstaw dane powiązane, aby zmniejszyć liczbę wymaganych zapytań.
- Zaleta: Mniejsza liczba operacji wejścia/wyjścia i niższe opóźnienie.
- Koszt: Zwiększone zużycie pamięci i skomplikowana logika aktualizacji.
2. Obciążenia zdominowane zapisami
Jeśli aplikacja często aktualizuje dane, preferowane jest normalizowanie lub oddzielne przechowywanie danych.
- Strategia: Przechowuj dane w najbardziej atomowej formie i łączy bądź odwołuj się do nich w czasie zapytania.
- Zaleta: Jedno źródło prawdy; aktualizacje odbywają się w jednym miejscu.
- Koszt: Wyższe opóźnienie odczytu spowodowane łączeniem lub wielokrotnymi wyszukiwaniami.
3. Strategie indeksowania
Niezależnie od typu bazy danych, ERD wskazuje, gdzie są potrzebne indeksy.
- Relacyjne:Indeksy są umieszczane na kluczach obcych i kolumnach używanych w
WHEREklauzulach. - Dokument:Indeksy są umieszczane w polach, które są często zapytane. Pola zagnieżdżone mogą wymagać specyficznej składni indeksowania.
- Graf:Indeksy są umieszczane na etykietach węzłów i właściwościach krawędzi w celu przyspieszenia punktów początkowych przeszukiwania.
Hybrydowe środowiska i wielojęzyczna persistencja 🧩
Nowoczesne architektury często używają jednocześnie wielu technologii baz danych. Nazywa się to wielojęzyczna persistencja. Semantyka ERD musi zamykać te luki.
1. Wzorce spójności danych
Gdy dane rozciągają się na wiele systemów, spójność staje się złożona.
- ACID:Bazy danych relacyjnych zapewniają silną spójność. Transakcje obejmują wiele tabel w tej samej bazie danych.
- BASE:Bazy danych NoSQL często preferują dostępność i spójność ostateczną. Transakcje mogą być ograniczone do jednego dokumentu.
- Wzorzec Saga: W przypadku transakcji rozproszonych między systemami, wzorzec Saga zarządza długotrwałymi operacjami poprzez koordynację lokalnych transakcji.
2. Rola ERD w systemach hybrydowych
ERD działa jak mapa koncepcyjna. Definiuje relacje logiczne, nawet jeśli fizyczne przechowywanie danych się różni.
- Mapowanie:Deweloperzy używają ERD, aby określić, do którego magazynu trafiają dane.
- Integracja:Diagram pomaga wizualizować, gdzie wymagana jest synchronizacja danych między systemami.
- Dokumentacja: Zapewnia jednolity widok dla stakeholderów, którzy mogą nie rozumieć różnic technicznych między silnikami przechowywania danych.
Najlepsze praktyki dla solidnego modelowania danych 🛡️
Aby zapewnić długoterminową utrzymywalność i wydajność, przestrzegaj tych zasad podczas projektowania ERD.
- Zrozumienie domeny:Zacznij od wymagań biznesowych. Nie modeluj danych, które nie wspierają konkretnego przypadku użycia.
- Wybierz odpowiednie narzędzie: Wybieraj typ bazy danych na podstawie relacji danych, a nie tylko trendów. Używaj grafów dla złożonych sieci, dokumentów dla treści i SQL dla transakcji.
- Jasno dokumentuj relacje: Jasną etykietą oznacz liczność na diagramie. Niejasność prowadzi do błędów implementacji.
- Planuj rozwój: Rozważ, jak będzie skalować się objętość danych. Czy osadzona tablica stanie się zbyt duża? Czy tabela pośrednicząca stanie się węzłem zatkania?
- Iteruj projekt: Diagramy ER nie są statyczne. Doskonal je wraz z rozwojem aplikacji i odkrywaniem nowych ograniczeń.
- Weryfikuj na warstwie aplikacji: W szczególności w NoSQL zaimplementuj logikę weryfikacji, aby zapewnić integralność danych, ponieważ baza danych może jej nie wymuszać.
Wnioski dotyczące semantyki modelowania 📝
Semantyka diagramu relacji encji nie jest uniwersalna; dostosowuje się do podstawowej technologii przechowywania danych. W systemach relacyjnych diagram ERD jest umową wymuszana przez silnik bazy danych. W systemach NoSQL jest to przewodnik wzorców dla warstwy aplikacji. Zrozumienie tych różnic pozwala architektom projektować systemy, które są zarówno skalowalne, jak i spójne.
Czyniąc dokładny analizę liczności, wybierając odpowiedni model przechowywania danych i przewidując przyszłe zmiany, zespoły mogą tworzyć warstwy danych wspierające złożoną logikę biznesową bez kompromisu pod względem wydajności. Kluczem jest dopasowanie modelu logicznego do możliwości fizycznych wybranego środowiska.
Niezależnie od tego, czy pracuje się z tabelami, dokumentami czy grafami, podstawowe zasady identyfikowania encji i definiowania ich połączeń pozostają niezmienne. Jasny diagram ERD stanowi fundament niezawodnej architektury oprogramowania, łącząc wymagania biznesowe z realizacją techniczną.