











W procesie ewolucji architektury oprogramowania nieliczne wyzwania są tak trwałe jak napięcie między historycznym modelowaniem danych a współczesnymi wymogami skalowalności. Wiele organizacji napotyka się na zarządzanie systemami backendowymi opartymi na diagramach relacji encji (ERD), projektowanych wiele lat temu, często przy innych założeniach dotyczących obciążenia, współbieżności i sprzętu. Gdy dziedziczny schemat napotyka wymagania dotyczące wysokiej przepustowości, spowolnienie wydajności nie jest po prostu irytującym niedociągnięciem – jest to błąd strukturalny. Niniejszy przewodnik bada rzeczywistości techniczne optymalizacji tych diagramów bez rezygnacji z zaimplementowanej w nich logiki biznesowej.
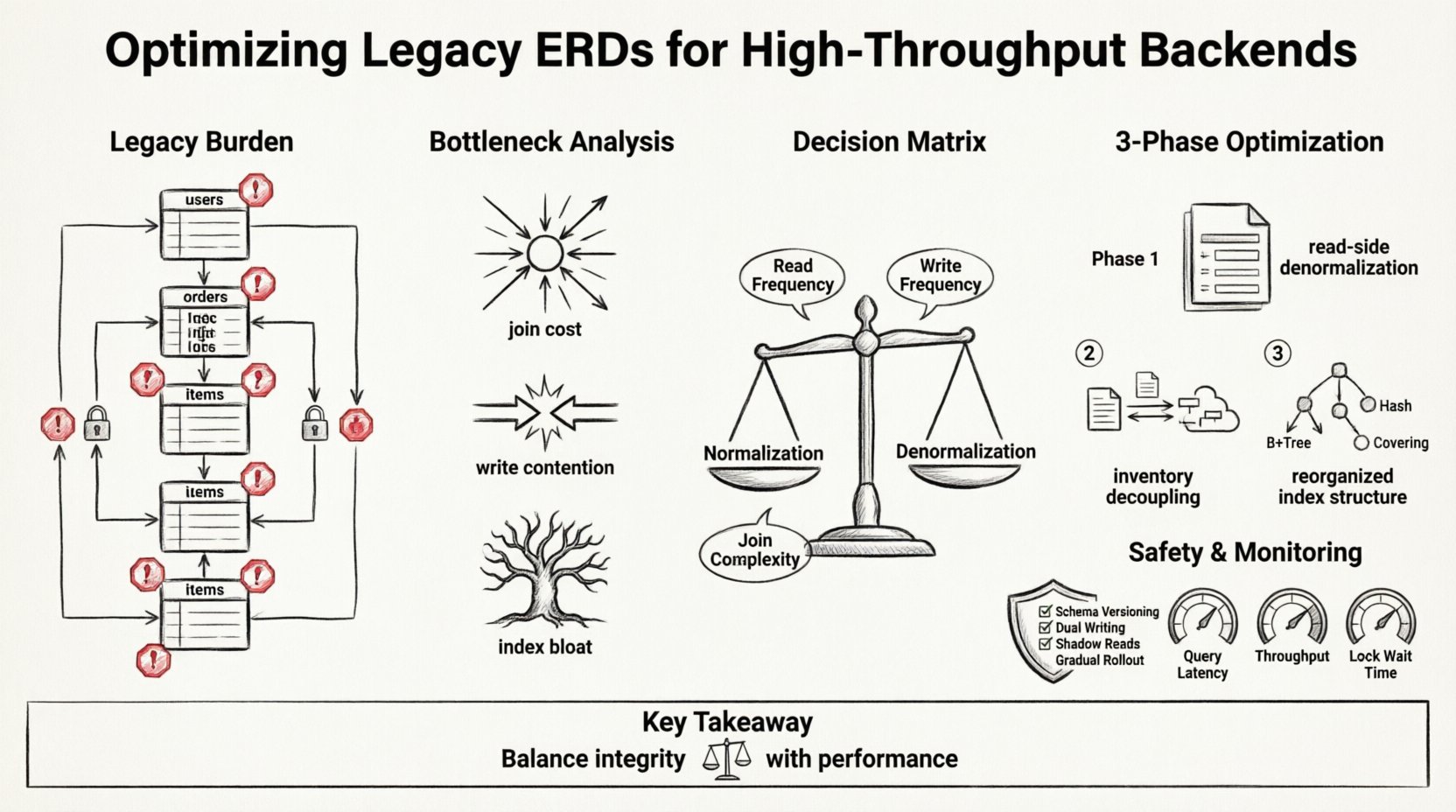
Zrozumienie obciążenia dziedziczonego 💾
Dziedziczne diagramy relacji encji często odzwierciedlają potrzeby przeszłości. Najpierw zwracają uwagę na integralność danych i normalizację. W środowisku jednowęzłowym z umiarkowanym ruchem ten podejście działa dobrze. Ścisłe przestrzeganie Trzeciej Postaci Normalnej (3NF) minimalizuje nadmiarowość i zapewnia spójność. Jednak gdy system skaluje się do milionów transakcji na sekundę, koszt tych relacji staje się nie do zaakceptowania.
Zastanów się nad poniższymi typowymi cechami występującymi w starszych schematach:
- Głębokie łańcuchy połączeń:Zapytania wymagające pięciu lub więcej połączeń w celu pobrania pojedynczego rekordu.
- Zaawansowane ograniczenia kluczy obcych:Sztywne sprawdzanie integralności, które blokują jednoczesne zapisy.
- Centralizowane blokowanie:Obszary nadmiernego obciążenia na określonych tabelach, które stają się wąskimi gardłami podczas szczytowego obciążenia.
- Luki w denormalizacji:Brak zduplikowanych magazynów danych dla operacji o wysokim obciążeniu odczytu.
Te wzorce nie są wewnętrznie „źle”. Były poprawne w swoim czasie. Wyzwanie polega na dopasowaniu ich do rozproszonego środowiska o wysokiej współbieżności, gdzie opóźnienie jest główną wartością.
Analiza wąskich gardeł 🔍
Zanim zmieni się diagram, należy zrozumieć, gdzie system traci wydajność. Systemy backendowe o wysokiej przepustowości często są ograniczane operacjami wejścia/wyjścia, opóźnieniem sieciowym między usługami oraz zawieszeniem blokad. Diagram relacji encji określa sposób dostępu do danych, co bezpośrednio wpływa na te metryki.
1. Koszty połączeń
Każde połączenie to odczyt z dysku i cykl procesora. W systemie dziedzicznym żądanie profilu użytkownika może wywołać szereg wyszukiwań w pięciu tabelach. Wraz ze wzrostem ruchu baza danych spędza więcej czasu na przemieszczaniu się po relacjach niż na wykonywaniu logiki. Jest to szczególnie prawdziwe, gdy indeksy nie mogą obejmować całego ścieżki połączeń.
2. Konflikty zapisu
Normalizacja wymaga zapisu danych w wielu lokalizacjach w celu zachowania integralności. Jeśli transakcja aktualizuje profil użytkownika i zapisuje zdarzenie aktywności, muszą zostać zmodyfikowane dwie tabele. Jeśli te tabele znajdują się na tym samym shardzie, czas blokady wzrasta. Jeśli są rozproszone, transakcja staje się transakcją dwufazową, co dodatkowo zwiększa obciążenie.
3. Nadmiar indeksów
Aby wspierać złożone połączenia, systemy dziedziczne gromadzą indeksy. Z czasem te indeksy spowalniają operacje zapisu. Baza danych musi aktualizować każdy indeks przy każdym wstawieniu lub aktualizacji. W scenariuszach o wysokiej przepustowości ta zwiększona ilość zapisów może przeprowadzić podsystem przechowywania danych.
Strategia refaktoryzacji: normalizacja wobec denormalizacji ⚖️
Serce optymalizacji polega na ponownym rozważeniu kompromisu między integralnością danych a szybkością zapytań. Choć ścisła normalizacja zapewnia spójność, systemy o wysokiej wydajności często wymagają praktycznej denormalizacji. Oznacza to nie porzucenie struktury, ale zaakceptowanie nadmiarowości w celu zmniejszenia opóźnień.
Poniższa tabela przedstawia macierz decyzyjną zmian schematu:
| Kryteria | Zachowaj normalizację | Zastosuj denormalizację |
|---|---|---|
| Częstotliwość odczytu | Niska (przetwarzanie partii) | Wysoka (pulpity czasu rzeczywistego) |
| Częstotliwość zapisu | Wysoka (główne transakcje) | Niska (rejestracje audytu) |
| Wymóg spójności | Silne ACID | Dopuszczalna spójność ostateczna |
| Złożoność łączenia | Prosta (1-2 łączenia) | Złożona (3+ łączeń) |
| Wahania danych | Statyczne (dane referencyjne) | Dynamiczne (stan użytkownika) |
Wdrożenie tej strategii wymaga dokładnego planowania. Nie zmieniasz tylko tabel; zmieniasz sposób, w jaki aplikacja postrzega dane.
Przegląd przypadku studium: silnik transakcji e-commerce 🛒
Aby ilustrować ten proces, rozważ fikcyjną platformę e-commerce. Stary system obsługuje przetwarzanie zamówień, zarządzanie zapasami i profile klientów. Diagram ERD został zaprojektowany dla jednej instancji bazy danych z naciskiem na zapobieganie nadmiernemu sprzedawaniu towarów.
Stan dziedziczony
W oryginalnym projekcie tabela orders odnosiła się do order_items, która odnosiła się do products. Tabela products odnosiła się do inventory. Aby wyświetlić stronę szczegółów zamówienia, backend wykonał zapytanie łączące wszystkie cztery tabele. Dodatkowo, każde aktualizowanie zamówienia wymagało blokady tabeli zapasów w celu zapewnienia dokładności.
Zidentyfikowane kluczowe problemy:
- Opóźnienie: Czas ładowania strony wzrósł do 800 ms podczas wydarzeń promocyjnych.
- Zamknięcia:Wysoka współbieżność aktualizacji zapasów spowodowała cofnięcie transakcji.
- Skalowalność: Baza danych nie mogła podzielić na shardy tabelę
zapasówz powodu częstych połączeń między shardami.
Proces optymalizacji
Zespół zdecydował się przebudować ERD w trzech fazach. Celem było rozdzielenie ścieżek odczytu od ścieżek zapisu.
Faza 1: Denormalizacja strony odczytu
Pierwszym krokiem było utworzenie kopii zapasowej danych produktu w rekordach zamówień. Zamiast łączyć się z tabelą produktów w czasie zapytania, system skopiował nazwę produktu, cenę i kod SKU do tabeli order_items w momencie zakupu.
- Zaleta: Historia zamówień pozostaje dokładna, nawet jeśli dane produktu zostaną później zmienione.
- Zaleta: Zapytanie nie wymaga już połączenia z tabelą produktów.
- Ryzyko: Różnice w cenach, jeśli produkt zostanie zaktualizowany po złożeniu zamówienia.
- Zmniejszenie ryzyka: Interfejs użytkownika wyświetla cenę w momencie zakupu jako „Cena historyczna”.
Faza 2: Odłączenie zapasów
Tabela zapasów była źródłem konfliktów. Zespół przeniósł śledzenie zapasów do osobistego magazynu zapisu o wysokiej częstotliwości. System zamówień wysyła asynchroniczne komunikaty do zarezerwowania towaru zamiast wykonywać synchroniczny blokadę SQL.
- Zaleta: Przepustowość zapisu wzrosła o 400%.
- Zaleta: Nie ma już blokowania głównej transakcji zamówienia.
- Zalety i wady: Zamówienia mogą być umawiane nawet wtedy, gdy stan magazynowy jest tymczasowo niezgodny.
- Zmniejszenie ryzyka:Proces działający w tle wygładza rozbieżności między systemem zamówień a stanem magazynowym.
Faza 3: Przebudowa indeksów
Przy danych znormalizowanych stare indeksy na kluczach obcych stały się zbędne. Zespół je usunął i dodał złożone indeksy zoptymalizowane pod nowe wzorce zapytań. Na przykład indeks na(customer_id, created_at) zastąpił potrzebę przeszukiwania całej tabeli zamówień.
Fazy wdrożenia i bezpieczeństwo 🛡️
Zmiana schematu w działającym systemie to operacja o wysokim ryzyku. Poniższe fazy zapewniają stabilność podczas przejścia.
1. Wersjonowanie schematu
Nie usuwaj starych kolumn od razu. Zachowaj je, ale oznacz jako przestarzałe. Pozwala to aplikacji cofnąć się, jeśli nowa logika nie zadziała. Używaj skryptów migracji, które dodają kolumny przed ich usunięciem.
2. Zapis dwukrotny
W trakcie przejścia dane zapisujesz zarówno w starej strukturze, jak i w nowej. Logika aplikacji kieruje odczyty do nowej struktury, ale zapisy idą do obu. Zapewnia to alternatywę, jeśli nowy schemat jest niekompletny.
3. Czytanie cieniowe
Zanim przekierujesz ruch produkcyjny, uruchom nowe zapytania na kopii danych produkcyjnych. Porównaj wyniki zapytań starszych z zoptymalizowanymi, aby upewnić się w poprawności danych.
4. Stopniowe wdrażanie
Użyj flag funkcji, aby włączyć nowy schemat dla małej grupy użytkowników (np. 1%). Monitoruj wskaźniki błędów i opóźnienia. Jeśli metryki pozostaną stabilne, stopniowo zwiększ procent użytkowników.
Monitorowanie i weryfikacja 📊
Optymalizacja to nie jednorazowa czynność. Wymaga ciągłego monitorowania, aby upewnić się, że zmiany wytrzymają obciążenie. Przed rozpoczęciem refaktoryzacji należy ustalić kluczowe wskaźniki wydajności (KPI).
Kluczowe metryki do śledzenia:
- Opóźnienie zapytania:Czas odpowiedzi na percentylach 95. i 99.
- Przepustowość:Transakcje na sekundę (TPS) bez błędów.
- Czas oczekiwania na blokadę:Średni czas, przez który transakcja oczekuje na blokadę.
- Opóźnienie replikacji:Opóźnienie między węzłami głównymi a replikami (jeśli dotyczy).
- Wskaźnik trafień w pamięci podręcznej:Skuteczność strategii buforowania odczytów.
Progięcia progów ostrzegawczych powinny być ustawiane na podstawie metryk bazowych zebranych przed zmianami. Jeśli nastąpi wzrost opóźnień, system powinien automatycznie wrócić do starszego schematu lub przekierować ruch do usługi zapasowej.
Typowe pułapki do unikania ⚠️
Nawet przy solidnym planie dług techniczny często powraca nieoczekiwanymi sposobami. Bądź na baczności przed tymi częstymi błędami.
- Ignorowanie kosztów migracji danych:Przenoszenie terabajtów danych do nowych struktur zajmuje czas. Zaprojektuj okna konserwacji lub narzędzia migracji w tle.
- Zbyt duża optymalizacja odczytów:Jeśli zbyt dużo znormalizujesz, wydajność zapisu będzie się pogarszać. Zrównowaguj stosunek odczytu do zapisu dla Twojego konkretnego obciążenia.
- Zapominanie o logice aplikacji:Zmiana schematu to tylko połowa walki. Kod aplikacji musi zostać zaktualizowany, aby obsługiwał nową strukturę danych.
- Ignorowanie testowania:Testy jednostkowe często obejmują ścieżki pozytywne. Testy obciążeniowe są wymagane do znalezienia warunków wyścigu w nowym schemacie.
Strategie długoterminowej utrzymaności 🔧
Po zakończeniu optymalizacji zespół musi utrzymywać nową architekturę. Dokumentacja jest kluczowa. Każda tabela, kolumna i relacja powinna być oznaczona jej celem i właścicielem.
Regularne audyty:
Zaplanuj przegląd ERD co kwartał. Zidentyfikuj tabele, które rosną nieproporcjonalnie, lub zapytania, które stają się wolniejsze. Rosnąca baza danych często ujawnia nowe przewężenia, które nie były obecne podczas początkowej refaktoryzacji.
Automatyczne sprawdzanie schematu:
Zintegruj weryfikację schematu z potokiem CI/CD. Zapobiegaj deweloperom dodawanie nowych połączeń lub usuwanie kluczowych ograniczeń bez zatwierdzenia. Zapewnia to, że system pozostanie zoptymalizowany w długiej perspektywie.
Szkolenia zespołu:
Upewnij się, że wszyscy inżynierowie backendu rozumieją nowy model danych. Wspólne zrozumienie schematu zmniejsza ryzyko wprowadzenia nowego długu technicznego poprzez zapytania ad-hoc.
Ostateczne rozważania nad modelowaniem danych 🔗
Optymalizacja starszego diagramu relacji encji to balans między dokładnością historyczną a przyszłą skalowalnością. Nie ma jednego „poprawnego” schematu. Prawidłowy model to ten, który wspiera obecne cele biznesowe, pozwalając na rozwój.
Skupiając się na konkretnych przewężeniach systemu – czy to koszty połączeń, zawieszenia blokad czy nadmiar indeksów – możesz dokonywać celowych ulepszeń. Przykład pokazuje, że nawet głęboko zakorzenione struktury mogą zostać zmodernizowane bez całkowitej przebudowy. Kluczem jest systematyczny postęp, surowa weryfikacja oraz jasne rozumienie zalet i wad podejmowanych decyzji.
Modelowanie danych nie jest statyczne. Rozwija się wraz z ruchem, który obsługuje. Traktuj swój ERD jak żywy dokument, który wymaga takiej samej staranności i uwagi jak kod, który go wykorzystuje. Poprawnie podejście pozwala przekształcić system dziedziczony w wydajny silnik, zdolny do obsługi wymagań współczesnej sieci.