











डेटा फ्लो डायग्राम (DFD) सिस्टम विश्लेषण और डिज़ाइन में एक आधारभूत उपकरण के रूप में काम करते हैं। वे डेटा के एक सिस्टम में गति के तरीके का दृश्य प्रतिनिधित्व प्रदान करते हैं, जिसमें प्रक्रियाएँ, डेटा स्टोर, बाहरी एकाधिकार और उन्हें जोड़ने वाले फ्लो को उजागर किया जाता है। हालांकि, एक वैध DFD बनाना हमेशा आसान नहीं होता है। मॉडलिंग प्रक्रिया के दौरान त्रुटियाँ छिप सकती हैं, जिससे तर्कसंगत असंगतियाँ उत्पन्न होती हैं जो पूरे सिस्टम आर्किटेक्चर को कमजोर करती हैं।
यह मार्गदर्शिका डेटा फ्लो डायग्राम में पाए जाने वाली सामान्य समस्याओं की पहचान और निवारण के लिए एक व्यापक दृष्टिकोण प्रदान करती है। संरचित समस्या निवारण विधियों का पालन करके, विश्लेषक यह सुनिश्चित कर सकते हैं कि उनके मॉडल सिस्टम की आवश्यकताओं और संचालन वास्तविकताओं का सही प्रतिनिधित्व करते हैं।
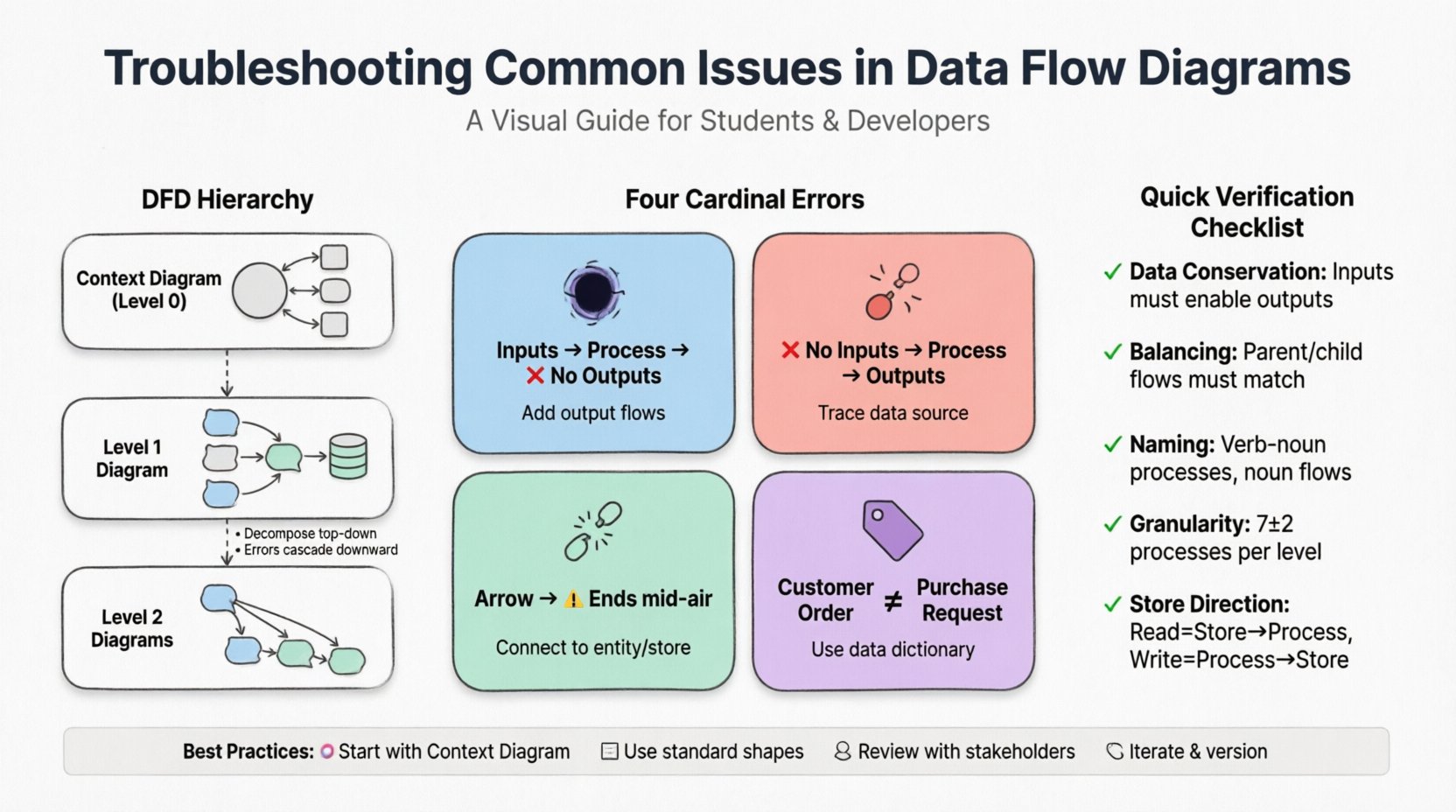
DFD के श्रेणीक्रम को समझना 🏗️
विशिष्ट त्रुटियों के निवारण से पहले, DFD की संरचना को समझना आवश्यक है। एक पूर्ण मॉडलिंग प्रयास में आमतौर पर आरेखों की श्रेणीक्रम शामिल होती है:
- संदर्भ आरेख (स्तर 0): सर्वोच्च स्तर का दृश्य। यह सिस्टम को बाहरी एकाधिकारों के साथ बातचीत करने वाली एकल प्रक्रिया के रूप में दिखाता है। यह सिस्टम की सीमाओं को परिभाषित करता है।
- स्तर 1 आरेख: संदर्भ आरेख से मुख्य प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित करता है। यह मुख्य डेटा स्टोर और मुख्य फ्लो को उजागर करता है।
- स्तर 2 आरेख: स्तर 1 से विशिष्ट प्रक्रियाओं को अधिक विस्तृत चरणों में और विभाजित करता है।
आमतौर पर संदर्भ स्तर पर समस्या निवारण शुरू होता है और नीचे की ओर बढ़ता है। शीर्ष स्तर पर असंगतियाँ सभी निचले स्तर के आरेखों में त्रुटियों को फैलाती हैं।
चार महत्वपूर्ण त्रुटियाँ 🚫
DFD में आमतौर पर दिखने वाली चार विशिष्ट प्रकार की तर्कसंगत त्रुटियाँ होती हैं। इनकी पहचान करने के लिए प्रत्येक प्रक्रिया के डेटा इनपुट और आउटपुट की ध्यान से समीक्षा करना आवश्यक होता है।
1. काला छेद
एक काला छेद तब होता है जब किसी प्रक्रिया के इनपुट होते हैं लेकिन आउटपुट नहीं होते हैं। इसका अर्थ है कि डेटा प्रक्रिया में प्रवेश करता है और किसी परिणाम या परिवर्तन के बिना गायब हो जाता है। वास्तविक दुनिया के सिस्टम में यह असंभव है। प्रत्येक इनपुट को किसी क्रिया को निष्पादित करना चाहिए, चाहे वह डेटा स्टोर करना हो, प्रतिक्रिया भेजना हो या रिकॉर्ड अपडेट करना हो।
सुधार कैसे करें:
- प्रक्रिया में प्रवेश करने वाले प्रत्येक डेटा फ्लो का अनुसरण करें।
- सत्यापित करें कि क्या प्रक्रिया को रिपोर्ट जनरेट करना, डेटाबेस अपडेट करना या सूचना उत्पन्न करना चाहिए।
- यदि कोई आउटपुट नहीं है, तो डेटा संरक्षण सुनिश्चित करने के लिए आवश्यक डेटा फ्लो को जोड़ें।
2. चमत्कार
काले छेद का विपरीत चमत्कार है। यह तब होता है जब कोई प्रक्रिया बिना किसी इनपुट के आउटपुट उत्पन्न करती है। इसका अर्थ है कि डेटा बिना किसी कारण के उत्पन्न हो रहा है। यह एक महत्वपूर्ण तर्कसंगत दोष है क्योंकि प्रत्येक डेटा के किसी सिस्टम के भीतर या बाहरी स्रोत से उत्पत्ति होनी चाहिए।
सुधार कैसे करें:
- उस डेटा तत्व की पहचान करें जो उत्पन्न किया जा रहा है।
- इस डेटा के स्रोत का निर्धारण करें (उदाहरण के लिए, उपयोगकर्ता इनपुट, सेंसर रीडिंग या पिछली प्रक्रिया)।
- प्रक्रिया के बबल में गायब इनपुट फ्लो को जोड़ें।
3. लटकता डेटा
लटकता डेटा एक ऐसे फ्लो को संदर्भित करता है जो किसी चीज़ से जुड़ा नहीं है। यह एक ऐसी रेखा हो सकती है जो आरेख के बीच में अचानक रुक जाती है या खाली स्थान से जुड़ी होती है। इसका अर्थ है डेटा पथ में तोड़ा हुआ जुड़ाव।
सुधार कैसे करें:
- सुनिश्चित करें कि प्रत्येक तीर एक स्रोत को एक गंतव्य से जोड़ता है।
- जांचें कि क्या कोई डेटा स्टोर या बाहरी एकाधिकार गायब है।
- सुनिश्चित करें कि गंतव्य प्रक्रिया वास्तव में इस विशिष्ट डेटा तत्व की आवश्यकता है।
4. असंगत नामकरण
डेटा प्रवाहों को सभी स्तरों पर एक समान रूप से लेबल किया जाना चाहिए। यदि एक प्रवाह स्तर 1 आरेख में “ग्राहक आदेश” के रूप में लेबल किया गया है, तो इसे स्तर 2 आरेख में “खरीद अनुरोध” में बदला नहीं जाना चाहिए, जब तक कि अर्थ में मूल रूप से परिवर्तन नहीं होता। असंगत नामकरण स्टेकहोल्डर्स और विकासकर्मियों को भ्रमित करता है।
सुधार कैसे करें:
- संवाद के शब्दावली को मानकीकृत करने के लिए एक डेटा शब्दकोश बनाएं।
- माता-पिता और बच्चे के आरेखों के बीच एक पारस्परिक संदर्भ जांच करें।
- सुनिश्चित करें कि प्रक्रिया में प्रवेश करने वाले प्रवाह का नाम उसी प्रक्रिया से निकलने वाले प्रवाह के नाम के साथ मेल खाता है (जब तक कि परिवर्तित नहीं होता)।
प्रक्रिया विभाजन और विभाजन 🧩
DFD में सबसे आम समस्याओं में से एक अनुचित विभाजन है। एक प्रक्रिया बबल को बहुत बड़ा (बहुत अधिक तर्क) या बहुत छोटा (साधारण चरण) नहीं होना चाहिए।
बहुत अधिक प्रक्रियाएं
यदि स्तर 1 आरेख में सात से नौ प्रक्रियाओं से अधिक हैं, तो इसे पढ़ना और प्रबंधित करना मुश्किल हो जाता है। इसका अक्सर यह अर्थ होता है कि विश्लेषक ने संबंधित कार्यों को एक साथ नहीं जोड़ा है।
- समाधान: कार्यात्मक क्षेत्र या व्यापार क्षमता के आधार पर प्रक्रियाओं का समूहन करें।
- समाधान: विचार करें कि क्या एक प्रक्रिया को दो अलग-अलग प्रक्रियाओं में विभाजित किया जाना चाहिए यदि यह दो अलग-अलग तार्किक कार्यों को संभालती है।
बहुत कम प्रक्रियाएं
विपरीत रूप से, यदि एक प्रक्रिया उपयोगकर्ता लॉगिन से लेकर डेटाबेस बैकअप तक सभी कार्यों को संभालती है, तो यह बहुत जटिल है। इससे उस बबल के लिए विशिष्ट एल्गोरिदम या इंटरफेस डिज़ाइन करना असंभव हो जाता है।
- समाधान: जटिल प्रक्रियाओं को स्तर 2 आरेखों के लिए उप-प्रक्रियाओं में विभाजित करें।
- समाधान: सुनिश्चित करें कि प्रत्येक प्रक्रिया का एक एकल क्रिया-संज्ञा नाम हो (उदाहरण के लिए, “लॉगिन की पुष्टि करें” के बजाय “लॉगिन करें और पुष्टि करें और सहेजें”)।
डेटा स्टोर अखंडता 🗄️
डेटा स्टोर उन भंडारों का प्रतिनिधित्व करते हैं जहां डेटा भविष्य के उपयोग के लिए सहेजा जाता है। यहां त्रुटियां डेटा के नुकसान या विकृति का कारण बन सकती हैं।
गायब डेटा स्टोर
जब किसी प्रक्रिया को बाद में पुनर्प्राप्त करने के लिए जानकारी सहेजने की आवश्यकता होती है, तो डेटा स्टोर जोड़ना भूल जाना आम बात है। उदाहरण के लिए, “आदेश प्रक्रिया” कार्य को लेनदेन पूरा होने से पहले कहीं आदेश विवरण सहेजना चाहिए।
- जांचें: उन प्रक्रियाओं को खोजें जो संबंधित डेटा स्टोर कनेक्शन के बिना राज्य को बदलती हैं।
गलत डेटा प्रवाह दिशा
डेटा स्टोर को जोड़ने वाले तीरों को डेटा गति की सही दिशा को दर्शाना चाहिए। डेटा स्टोर से प्रक्रिया तक प्रवाह का अर्थ है डेटा पढ़ना। प्रक्रिया से डेटा स्टोर तक प्रवाह का अर्थ है डेटा लिखना। इन्हें गलत करने से डेटाबेस डिज़ाइन में तार्किक त्रुटियां हो सकती हैं।
- जांचें:सुनिश्चित करें कि पढ़ने के संचालन स्टोर से प्रक्रिया की ओर जाते हैं।
- जांचें:सुनिश्चित करें कि लेखन संचालन प्रक्रिया से स्टोर की ओर जाते हैं।
सत्यापन और मान्यता प्रक्रिया तकनीकें 🧐
चित्र बनाने के बाद, इसकी वास्तविक व्यापार आवश्यकताओं के अनुसार पुष्टि करनी होगी। कई तकनीकें सटीकता सुनिश्चित करने में मदद करती हैं।
1. डेटा संरक्षण नियम
इस नियम के अनुसार, एक प्रक्रिया के इनपुट और आउटपुट को वर्णित कार्य को करने के लिए पर्याप्त होना चाहिए। यदि किसी प्रक्रिया को ‘कर की गणना’ लेबल किया गया है, तो इनपुट में कर योग्य राशि और कर की दर शामिल होनी चाहिए, और आउटपुट में गणना की गई कर की राशि होनी चाहिए।
2. प्रक्रिया विघटन नियम
स्तर 1 पर इनपुट और आउटपुट को स्तर 2 पर बच्चे प्रक्रियाओं के संग्रहित इनपुट और आउटपुट के साथ मेल बैठाना चाहिए। यदि स्तर 1 का चित्र ‘ग्राहक आईडी’ इनपुट को ‘आदेश प्रक्रिया’ बबल में प्रवेश करते हुए दिखाता है, तो स्तर 2 के बच्चे चित्र में ‘ग्राहक आईडी’ को कम से कम एक बच्चे प्रक्रिया में प्रवेश करते हुए दिखाना चाहिए।
3. संतुलन जांच
सुनिश्चित करें कि माता-पिता प्रक्रिया में प्रवेश करने वाले डेटा प्रवाह, बच्चे प्रक्रियाओं के संग्रह में प्रवेश करने वाले डेटा प्रवाह के समान हैं। इससे पदानुक्रम की अखंडता बनी रहती है।
सामान्य समस्या निवारण चेकलिस्ट 📋
अपने चित्रों की व्यवस्थित रूप से समीक्षा करने के लिए निम्नलिखित तालिका का उपयोग करें।
| समस्या प्रकार | विवरण | प्रभाव | सुधार कदम |
|---|---|---|---|
| काला छेद | प्रक्रिया के इनपुट हैं लेकिन कोई आउटपुट नहीं है | डेटा हानि; टूटा हुआ कार्य प्रवाह | आउटपुट प्रवाह जोड़ें या प्रक्रिया के कार्य को पुनर्परिभाषित करें |
| चमत्कार | प्रक्रिया के आउटपुट हैं लेकिन कोई इनपुट नहीं है | अमान्य डेटा उत्पादन | डेटा स्रोत का पता लगाएं और इनपुट प्रवाह जोड़ें |
| लटकता हुआ प्रवाह | तीर किसी चीज से नहीं जुड़ता है | टूटा हुआ डेटा मार्ग | उचित एंटिटी, प्रक्रिया या स्टोर से जोड़ें |
| नामकरण असंगति | एक ही डेटा के अलग-अलग नाम | डेवलपर्स के लिए भ्रम | डेटा डिक्शनरी में शब्दावली को मानकीकृत करें |
| असंतुलित विभाजन | बच्चे के इनपुट/आउटपुट माता-पिता से भिन्न हैं | हायरार्की में तार्किक अंतराल | प्रवाह को माता-पिता प्रक्रिया के अनुरूप समायोजित करें |
नामकरण प्रथाएं और स्पष्टता 🏷️
स्टेकहोल्डर संचार के लिए स्पष्ट नामकरण निर्णायक है। प्रक्रिया के नाम क्रिया के बाद संज्ञा होने चाहिए (उदाहरण के लिए, “इन्वेंटरी को अपडेट करें”)। डेटा प्रवाह के नाम संज्ञा होने चाहिए (उदाहरण के लिए, “इन्वेंटरी रिपोर्ट”)।
जब नामकरण की समस्याओं का समाधान कर रहे हों:
- एक्रोनिम्स से बचें: एक्रोनिम के संगठन में व्यापक रूप से समझे जाने के अलावा पूरे शब्दों का उपयोग करें।
- विशिष्ट बनें: “डेटा” बहुत व्यापक है। “ग्राहक पता” या “भुगतान रिकॉर्ड” का उपयोग करें।
- स्थिर काल: प्रक्रिया के नाम को वर्तमान काल में रखें (“रिपोर्ट जनरेट करें” नहीं “जनरेट की गई रिपोर्ट”)।
अन्य मॉडल्स के साथ एकीकरण 🔄
डेटा प्रवाह आरेख अकेले नहीं मौजूद होते हैं। उन्हें अक्सर अन्य मॉडलिंग तकनीकों के साथ समायोजित करने की आवश्यकता होती है।
एंटिटी संबंध आरेख (ERD)
DFD डेटा स्टोर को ERD में परिभाषित तालिकाओं के साथ समायोजित करना चाहिए। यदि DFD में “ग्राहक जानकारी” डेटा स्टोर दिखाता है, लेकिन ERD में “उपयोगकर्ता” और “संपर्क_विवरण” हैं, तो DFD को भौतिक डेटाबेस संरचना को दर्शाने के लिए समायोजित करने की आवश्यकता है।
राज्य संक्रमण आरेख
DFD डेटा गति पर ध्यान केंद्रित करते हैं, जबकि राज्य आरेख प्रणाली की स्थितियों पर ध्यान केंद्रित करते हैं। सुनिश्चित करें कि DFD में प्रक्रियाएं राज्य आरेख में पहचानी गई राज्य परिवर्तनों को सही तरीके से ट्रिगर करती हैं।
समय के साथ आरेख को बनाए रखना 📅
प्रणालियां विकसित होती हैं। आवश्यकता चरण के दौरान बनाए गए DFD को कार्यान्वयन चरण के बाद अप्रचलित हो सकता है। रखरखाव के लिए संस्करण नियंत्रण रणनीति की आवश्यकता होती है।
- संस्करण निर्धारण: प्रत्येक आरेख को संस्करण संख्या और तारीख के साथ लेबल करें।
- परिवर्तन लॉग: दर्ज करें कि परिवर्तन क्यों किया गया (उदाहरण के लिए, “नए भुगतान गेटवे को दर्शाने के लिए अपडेट किया गया”)।
- समीक्षा चक्र: व्यापार स्टेकहोल्डर्स के साथ नियमित समीक्षा की योजना बनाएं ताकि आरेख व्यापार की वास्तविकता के साथ अभी भी मेल खाता रहे।
उपकरण बनाम हाथ से समीक्षा 🖥️
जबकि मॉडलिंग उपकरण डीएफडी निर्माण में सहायता करने के लिए मौजूद हैं, वे अपरावत नहीं हैं। स्वचालित उपकरण वाक्य रचना त्रुटियों (जैसे लटकती रेखाएं) की जांच कर सकते हैं, लेकिन वे व्यापार तर्क की पुष्टि नहीं कर सकते। एक मानव विश्लेषक को आरेख की समीक्षा करनी होगी ताकि यह यह सुनिश्चित किया जा सके कि व्यापार संचालन के संदर्भ में यह समझ में आता है।
जब सामान्य मॉडलिंग सॉफ्टवेयर का उपयोग कर रहे हों:
- मूल रूप से जांच के लिए निर्मित वैधता विशेषताओं का उपयोग करें।
- सॉफ्टवेयर पर अपनी प्रक्रियाओं के नामकरण के लिए भरोसा न करें; मानव निर्णय का उपयोग करें।
- स्टेकहोल्डर समीक्षा के लिए आरेखों को पीडीएफ में निर्यात करें जहां संपादन अक्षम हो ताकि अनजाने बदलाव से बचा जा सके।
केस स्टडी: रिटेल सिस्टम में समस्या निवारण 🛒
एक ऐसे परिदृश्य पर विचार करें जहां एक रिटेल सिस्टम डीएफडी उपयोगकर्ता स्वीकृति परीक्षण के दौरान विफल हो रहा था।
समस्या
उपयोगकर्ताओं ने रिपोर्ट की कि जब बिक्री की जाती है तो स्टॉक स्तर अपडेट नहीं हो रहे थे। लेवल 1 आरेख में एक प्रक्रिया “बिक्री प्रक्रिया” को “बिक्री विवरण” के रूप में इनपुट लेते हुए दिखाया गया था।
निदान
लेवल 2 विघटन की निकट जांच के बाद पाया गया कि “बिक्री प्रक्रिया” के बबल को “कुल गणना” और “लेनदेन रिकॉर्ड” में विभाजित कर दिया गया था। हालांकि, “लेनदेन रिकॉर्ड” को “स्टॉक भंडार” से जोड़ने वाला डेटा प्रवाह अनुपस्थित था। यह स्टॉक तरफ एक प्राचीन काल का ब्लैक होल था, भले ही प्रक्रिया के अपने आउटपुट था।
समाधान
विश्लेषकों ने “लेनदेन रिकॉर्ड” प्रक्रिया से “स्टॉक भंडार” तक “स्टॉक अपडेट” डेटा प्रवाह जोड़ा। सिस्टम को फिर से परीक्षण किया गया और स्टॉक स्तर सही तरीके से अपडेट हुए।
विश्लेषकों के लिए सर्वोत्तम प्रथाएं 👨💻
भविष्य में समस्या निवारण के प्रयासों को कम करने के लिए, शुरुआत से ही इन प्रथाओं को अपनाएं:
- छोटे से शुरू करें:विघटन से पहले स्पष्ट एक संदर्भ आरेख से शुरू करें।
- टेम्पलेट का उपयोग करें:प्रक्रियाओं (गोल कोने वाले आयत) और डेटा भंडार (खुले आयत) के लिए मानक आकृतियों को अपनाएं ताकि भ्रम न हो।
- स्टेकहोल्डर्स को शामिल करें:व्यापार उपयोगकर्ताओं के साथ आरेख के माध्यम से चलें। यदि वे प्रवाह को समझते हैं, तो यह संभवतः सही है।
- पुनरावृत्ति करें:आरेखों को बार-बार फिर से बनाने की उम्मीद करें। पहला ड्राफ्ट अक्सर अंतिम संस्करण नहीं होता है।
सिस्टम अखंडता पर निष्कर्ष ✅
डेटा प्रवाह आरेखों का निराकरण एक महत्वपूर्ण कौशल है जो सिस्टम विश्वसनीयता सुनिश्चित करने के लिए आवश्यक है। चार मुख्य त्रुटियों को समझने, नामकरण सुसंगतता बनाए रखने और व्यापार नियमों के अनुसार प्रमाणीकरण करने से विश्लेषक मजबूत मॉडल बना सकते हैं। ये मॉडल डेवलपर्स के लिए नींव के रूप में काम करते हैं, जिससे यह सुनिश्चित होता है कि अंतिम सॉफ्टवेयर इच्छित तरीके से व्यवहार करता है।
नियमित समीक्षा और डेटा संरक्षण नियमों का पालन करने से तार्किक अंतराल रोके जा सकते हैं। याद रखें कि डीएफडी एक तकनीकी दस्तावेज के बराबर एक संचार उपकरण भी है। पाठक के लिए स्पष्टता मशीन के लिए सटीकता के बराबर महत्वपूर्ण है।