











एक डेटा फ्लो डायग्राम (DFD) सिस्टम विश्लेषण और डिजाइन में एक मूल उपकरण के रूप में कार्य करता है। यह जानकारी के एक सिस्टम में गति का दृश्य प्रतिनिधित्व प्रदान करता है। नियंत्रण प्रवाह और तर्क पर ध्यान केंद्रित करने वाले फ्लोचार्ट्स के विपरीत, एक DFD डेटा के रूपांतरण पर जोर देता है। यह मार्गदर्शिका मुख्य घटकों, नोटेशन शैलियों और संरचनात्मक नियमों का विवरण देती है जिनकी निर्दोष आरेख बनाने के लिए आवश्यकता होती है।
DFD के उद्देश्य को समझना 🎯
प्रतीकों का चयन करने या प्रवाह बनाने से पहले, आरेख के उद्देश्य को समझना आवश्यक है। एक DFD डेटा गति से संबंधित विशिष्ट प्रश्नों के उत्तर देता है:
- डेटा का उद्गम कहाँ है?
- डेटा को कैसे रूपांतरित किया जाता है?
- डेटा कहाँ खत्म होता है?
- भविष्य के उपयोग के लिए कौन सी डेटा स्टोर की जाती है?
ये आरेख तकनीकी आवश्यकताओं और व्यापार की आवश्यकताओं के बीच एक पुल के रूप में कार्य करते हैं। ये स्टेकहोल्डर्स को यह सत्यापित करने की अनुमति देते हैं कि सिस्टम जानकारी को सही तरीके से संभालेगा, बिना नीचे के कोड को समझे। प्रक्रियाओं और प्रवाहों के श्रृंखला के रूप में सिस्टम को दृश्यमान बनाकर, विश्लेषक विकास चक्र के शुरुआती चरण में बॉटलनेक, गायब डेटा या अतिरिक्त चरणों की पहचान कर सकते हैं।
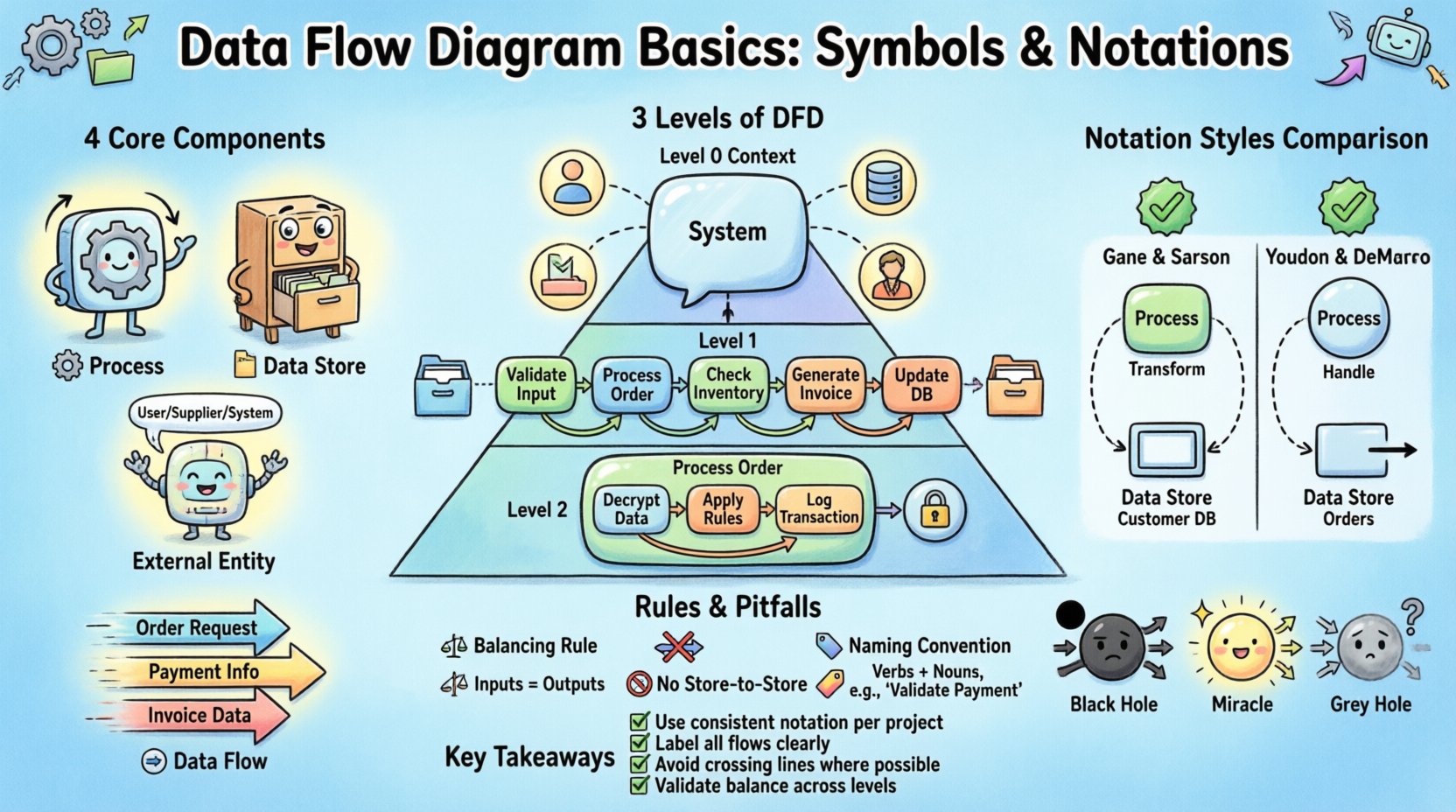
DFD के चार मूल घटक 🧩
प्रत्येक डेटा फ्लो डायग्राम चार अलग-अलग तत्वों पर निर्भर करता है। इन प्रतीकों ने सिस्टम के भीतर व्यवहार और संबंधों को परिभाषित किया है। इन घटकों के मास्टरी के कारण आरेख सभी टीम सदस्यों द्वारा संगत और व्याख्यायोग्य बना रहता है।
1. प्रक्रिया (रूपांतरण) ⚙️
एक प्रक्रिया डेटा के बदलाव के लिए एक क्रिया या कार्य का प्रतिनिधित्व करती है। यह इनपुट डेटा लेती है, गणना या रूपांतरण करती है और आउटपुट डेटा उत्पन्न करती है। DFD में, प्रक्रियाएँ वास्तविक कोड नहीं होती हैं, बल्कि किए जा रहे तार्किक कार्य का प्रतिनिधित्व करती हैं।
- कार्य:इनपुट को आउटपुट में बदलता है।
- पहचानकर्ता:प्रत्येक प्रक्रिया का एक अद्वितीय नाम और संख्या होना चाहिए।
- क्रिया-संज्ञा:नाम आमतौर पर क्रिया-संज्ञा संरचना का पालन करते हैं (उदाहरण के लिए, कर की गणना करें, उपयोगकर्ता की पुष्टि करें).
- विघटन:जटिल प्रक्रियाओं को निचले स्तर के आरेखों में उप-प्रक्रियाओं में विभाजित किया जा सकता है।
2. डेटा स्टोर (गोदाम) 📂
एक डेटा स्टोर एक स्थान का प्रतिनिधित्व करता है जहाँ डेटा विश्राम में रहता है। यह उस जानकारी को रखता है जो वर्तमान में प्रक्रिया में नहीं है लेकिन बाद में आवश्यक होगी। यह एक डेटाबेस तालिका, एक फ़ाइल या एक भौतिक फ़ाइल बॉक्स हो सकता है।
- स्थायित्व:डेटा सिस्टम सत्रों के बीच स्टोर में रहता है।
- पहुँच: प्रक्रियाओं को एक भंडार से पढ़ना या लिखना आवश्यक है।
- दिशा: डेटा भंडार डेटा नहीं बनाते हैं; वे केवल इसे रखते हैं।
- नामकरण: नाम बहुवचन संज्ञा होने चाहिए (उदाहरण के लिए, आदेश, ग्राहक).
3. बाहरी एकाधिकारी (स्रोत/स्थान) 🌐
एक बाहरी एकाधिकारी वर्तमान प्रणाली की सीमा के बाहर कोई व्यक्ति, संगठन या प्रणाली है। यह डेटा के स्रोत (इनपुट) या डेटा के गंतव्य (आउटपुट) के रूप में कार्य करता है।
- सीमा: आरेख के दायरे से बाहर कुछ भी एक बाहरी एकाधिकारी है।
- भूमिका: इंसानी उपयोगकर्ता, तीसरे पक्ष का API, सरकारी एजेंसी या हार्डवेयर उपकरण हो सकता है।
- बातचीत: डेटा प्रणाली और एकाधिकारी के बीच प्रवाहित होता है।
4. डेटा प्रवाह (गति) ➡️
डेटा प्रवाह घटकों के बीच जानकारी के आवागमन का प्रतिनिधित्व करता है। यह आरेख को एक साथ बांधने वाला संबंध है। तीर डेटा की दिशा को दर्शाते हैं।
- लेबलिंग: प्रत्येक तीर को डेटा पैकेट के नाम से लेबल किया जाना चाहिए।
- परमाणुता: एक डेटा प्रवाह केवल एक तार्किक जानकारी के टुकड़े को ले जाना चाहिए।
- दिशा: मानक DFD में प्रवाह एकदिशीय होता है।
- तर्क: डेटा किसी प्रक्रिया के माध्यम से प्रवाहित होना चाहिए; यह डेटा भंडारों के बीच सीधे प्रवाहित नहीं हो सकता है।
डेटा प्रवाह आरेखों के स्तर 📉
DFD हीरार्किक होते हैं। एकल प्रणाली को एक दृश्य में दिखाना बहुत जटिल है। इसलिए, आरेखों को विवरण के स्तरों में बांटा जाता है। इस दृष्टिकोण से विश्लेषक जटिलता को प्रबंधित कर सकते हैं जबकि समग्र प्रणाली की अखंडता बनाए रखते हैं।
स्तर 0: संदर्भ आरेख 🌍
संदर्भ आरेख प्रणाली का सर्वोच्च स्तर का दृश्य प्रदान करता है। यह प्रणाली की सीमा को परिभाषित करता है और दिखाता है कि प्रणाली बाहरी एजेंसियों के साथ कैसे बातचीत करती है।
- एकल प्रक्रिया: पूरी प्रणाली को एकल प्रक्रिया के रूप में दर्शाया गया है।
- इनपुट/आउटपुट: प्रणाली में प्रवेश करने और बाहर निकलने वाले प्रमुख डेटा को दिखाता है।
- परिसर: परियोजना के लिए सीमाओं को स्थापित करता है।
स्तर 1: प्रमुख प्रक्रियाएँ 🔍
स्तर 1 संदर्भ आरेख से एकल प्रक्रिया को प्रमुख उप-प्रक्रियाओं में विभाजित करता है। यह प्रणाली के निर्माण में शामिल प्राथमिक कार्यों को दिखाता है।
- विस्तार: मुख्य प्रक्रिया को 3 से 7 तक प्रमुख प्रक्रियाओं में विभाजित किया जाता है।
- स्टोर का परिचय: जानकारी कहाँ संग्रहीत की जाती है, इसका प्रदर्शन करने के लिए डेटा स्टोर का परिचय दिया जाता है।
- विवरण स्तर: प्रमुख तर्क को समझने के लिए पर्याप्त विवरण, बिना विस्तार में फंसे रहे।
स्तर 2: विस्तृत प्रक्रियाएँ 🛠️
स्तर 2 स्तर 1 से विशिष्ट प्रक्रियाओं को और विभाजित करता है। इसका उपयोग जटिल क्षेत्रों के लिए किया जाता है जिनमें सटीक तर्क परिभाषा की आवश्यकता होती है।
- विस्तृतता: विशिष्ट वर्कफ्लो या मॉड्यूल पर ध्यान केंद्रित करता है।
- सत्यापन: सुनिश्चित करता है कि सभी डेटा प्रवाह मुख्य प्रक्रिया के साथ संतुलित रहें।
- कार्यान्वयन: आमतौर पर विकासकर्मियों के लिए सीधे संदर्भ के रूप में उपयोग किया जाता है।
नोटेशन शैलियाँ: तुलना गाइड 🔄
DFD के लिए दो मुख्य नोटेशन उपयोग किए जाते हैं। यद्यपि वे समान तार्किक जानकारी प्रसारित करते हैं, प्रतीकों का दृश्य प्रतिनिधित्व भिन्न होता है। ऐसे टीमों के साथ सहयोग करते समय इन अंतरों को समझना आवश्यक है जिनके पास विशिष्ट संस्कृतियाँ हों।
| घटक | गेन और सर्सन | यौरडॉन और डीमार्को |
|---|---|---|
| प्रक्रिया | गोल आयत | वृत्त या गोल किनारे वाला आयत |
| डेटा भंडार | खुला आयत (2 समानांतर रेखाएं) | दाहिनी ओर खुले आयत |
| बाहरी एकाई | आयत | आयत |
| डेटा प्रवाह | तीर | तीर |
| कनेक्टर | तीर | तीर |
गेन और सर्सन: यह नोटेशन अमेरिका और यूरोप में व्यापक रूप से उपयोग किया जाता है। इसमें प्रक्रियाओं के लिए गोल किनारे वाला आयत और डेटा भंडार के लिए एक विशिष्ट डबल लाइन आकृति का उपयोग किया जाता है। इसका बल प्रक्रिया के तर्क के लिए एक डिब्बे के रूप में बल देने पर है।
यौरडॉन और डीमार्को: यह नोटेशन पहले उत्पन्न हुआ था और शैक्षणिक और पुराने प्रणालियों में आम है। इसमें प्रक्रियाओं के लिए वृत्त का उपयोग किया जाता है। डेटा भंडार को एक आयत द्वारा दर्शाया जाता है जिसकी एक भुजा गायब है। दोनों नोटेशन मान्य हैं, लेकिन परियोजना के भीतर सुसंगतता अनिवार्य है।
डेटा प्रवाह अखंडता के नियम ⚖️
एक DFD को तार्किक रूप से स्थिर बनाने के लिए, विशिष्ट नियमों का पालन करना आवश्यक है। इन नियमों के उल्लंघन से अस्पष्टता उत्पन्न होती है और सिस्टम डिजाइन के असफल होने की संभावना होती है। इन नियमों का नियंत्रण डेटा के गति और परिवर्तन के तरीके पर होता है।
1. संतुलन नियम ⚖️
जब किसी आरेख को एक स्तर से अगले स्तर पर विभाजित किया जाता है, तो इनपुट और आउटपुट को संगत रहना चाहिए। इसे डेटा प्रवाह संतुलन के रूप में जाना जाता है।
- यदि मातृ प्रक्रिया का इनपुट है आदेश डेटा, तो बच्चे के आरेख में प्राप्त करने के लिए ध्यान देना चाहिए आदेश डेटा.
- बच्चे के आरेख में नए इनपुट नहीं दिख सकते जो मातृ आरेख में नहीं थे।
- मौजूदा आउटपुट को विभाजन में बनाए रखना चाहिए।
2. कोई सीधा भंडार से भंडार प्रवाह नहीं 🚫
डेटा एक डेटा भंडार से दूसरे डेटा भंडार में सीधे नहीं जा सकता है। डेटा के परिवर्तन या ले जाने के लिए एक प्रक्रिया का अस्तित्व होना चाहिए।
- कारण: डेटा स्थानांतरण को आमतौर पर तर्क की आवश्यकता होती है (उदाहरण के लिए, रिकॉर्ड अपडेट करना, फ़ाइल कॉपी करना)।
- प्रभाव: प्रत्येक सूचना स्थानांतरण में प्रसंस्करण चरण शामिल होना चाहिए।
3. डेटा प्रवाह नामकरण प्रथाएँ 🏷️
डेटा प्रवाहों पर लेबल वर्णनात्मक और एकवचन होने चाहिए।
- एकल अवधारणा: एक तीर जिस पर लेबल है ग्राहक जानकारी एक विशिष्ट डेटा पैकेट को संदर्भित करता है, सभी ग्राहक डेटा के प्रवाह को नहीं।
- सांस्कृतिकता: एक ही डेटा पैकेट का सभी आरेखों में एक ही नाम होना चाहिए।
- नियंत्रण प्रवाह नहीं: तर्क (उदाहरण के लिए, हाँ/नहीं) के साथ प्रवाह को लेबल न करें। DFDs डेटा पर ध्यान केंद्रित करते हैं, नियंत्रण पर नहीं।
4. डेटा स्टोर तर्क 🗄️
डेटा स्टोर को तार्किक रूप से पहुँचा जाना चाहिए।
- पढ़ना/लिखना: एक प्रक्रिया को यह बताना चाहिए कि वह स्टोर से पढ़ रही है या उसमें लिख रही है।
- अस्तित्व: एक डेटा स्टोर को कम से कम एक प्रक्रिया द्वारा पहुँचा जाना चाहिए।
- अलगाव: एक स्टोर का अस्तित्व उसके डेटा को प्रबंधित करने वाली प्रक्रिया के बिना नहीं हो सकता।
आम DFD त्रुटियाँ और बाधाएँ 🚨
यहाँ तक कि अनुभवी विश्लेषक भी आरेख बनाते समय गलतियाँ कर सकते हैं। इन आम त्रुटियों को पहचानने से सिस्टम डिज़ाइन के डिबगिंग और मान्यता प्राप्त करने में मदद मिलती है।
1. काला छेद प्रक्रिया ⚫
एक काला छेद एक प्रक्रिया है जिसके इनपुट हैं लेकिन आउटपुट नहीं है। यह कोई परिणाम नहीं उत्पन्न किए बिना डेटा का उपभोग करती है।
- प्रभाव: सिस्टम संसाधनों का उपभोग कर रहा है बिना किसी मूल्य के प्रदान किए।
- सुधार:प्रक्रिया के उत्पादन के रूप में क्या होना चाहिए उसे पहचानें और आवश्यक डेटा प्रवाह जोड़ें।
2. चमत्कारिक प्रक्रिया ✨
एक चमत्कारिक प्रक्रिया काले छेद के विपरीत है। इसके आउटपुट है लेकिन कोई इनपुट नहीं है। यह किसी भी चीज के बिना डेटा बनाती है।
- प्रभाव: प्रणाली किसी स्रोत के बिना डेटा उत्पन्न कर रही है।
- सुधार: डेटा के स्रोत को बाहरी एकाइटी या डेटा स्टोर तक ट्रेस करें।
3. ग्रे होल प्रक्रिया 🌫️
एक ग्रे होल तब होता है जब एक प्रक्रिया के इनपुट और आउटपुट का आकार या प्रकार विघटन के दौरान मेल नहीं खाता है।
- प्रभाव: डेटा स्तरों के बीच गायब हो रहा है या अस्थिर रूप से दिखाई दे रहा है।
- सुधार: सुनिश्चित करें कि विघटन मूल स्तर से सभी डेटा प्रवाहों को बरकरार रखे।
4. डेटा प्रवाहों का प्रतिच्छेदन ⤵️
हालांकि हमेशा निषेध नहीं है, लेकिन डेटा प्रवाहों का प्रतिच्छेदन आरेख को पढ़ने में कठिन बना सकता है।
- स्पष्टता: यदि संभव हो, तो जोड़कर लाइनों को प्रतिच्छेदन के चारों ओर ले जाएं।
- लेआउट: प्रक्रियाओं और स्टोर्स को लाइन प्रतिच्छेदन को न्यूनतम करने के लिए व्यवस्थित करें।
डेटा प्रवाह आरेख और डेटा शब्दकोश 📚
एक डीएफडी अकेले नहीं खड़ा हो सकता है। इसे डेटा प्रवाह आरेख में बहने वाले डेटा की सटीक संरचना को परिभाषित करने के लिए डेटा शब्दकोश की आवश्यकता होती है। डेटा शब्दकोश प्रणाली में उपयोग किए जाने वाले डेटा तत्वों के बारे में जानकारी का भंडार है।
- परिभाषा: प्रत्येक डेटा तत्व के डेटा प्रकार, लंबाई और प्रारूप को निर्दिष्ट करता है।
- संबंध: डीएफडी प्रतीकों को विशिष्ट डेटाबेस क्षेत्रों से जोड़ता है।
- संगतता: सुनिश्चित करता है कि डीएफडी तीर पर लेबल शब्दकोश में परिभाषा के साथ मेल खाता है।
डेटा शब्दकोश के बिना, डीएफडी एक उच्च स्तर के अमूर्तीकरण रहता है। इसके साथ, आरेख डेटाबेस डिजाइन और एप्लिकेशन तर्क के लिए एक नींव के रूप में बन जाता है। इस एकीकरण से यह सुनिश्चित होता है कि दृश्य मॉडल तकनीकी कार्यान्वयन में सटीक रूप से बदल जाता है।
रखरखाव के लिए सर्वोत्तम प्रथाएं 🛡️
प्रणालियाँ समय के साथ विकसित होती हैं। आवश्यकताओं या वास्तुकला में होने वाले परिवर्तनों को दर्शाने के लिए DFD को बनाए रखना आवश्यक है।
- संस्करण नियंत्रण: परिवर्तनों को प्रबंधित करने के लिए आरेख के संस्करणों का अनुसरण करें।
- परिवर्तन का प्रभाव: जब कोई प्रक्रिया बदलती है, तो सभी संबंधित प्रवाहों और भंडारों की जांच करें।
- समीक्षा चक्र: स्टेकहोल्डर्स के साथ नियमित समीक्षा करें ताकि आरेख वास्तविकता के अनुरूप हो।
- दस्तावेज़ीकरण: जटिल तर्क को समझाने वाले नोट्स के साथ आरेखों को टिप्पणी करें।
प्रणाली मॉडलिंग पर निष्कर्ष 🏁
डेटा प्रवाह आरेख बनाना एक अनुशासित गतिविधि है जिसमें विस्तार से ध्यान देने और संरचनात्मक नियमों का पालन करने की आवश्यकता होती है। सही प्रतीकों का उपयोग करने और संतुलन नियमों का पालन करने से विश्लेषक प्रणाली के व्यवहार का स्पष्ट नक्शा बना सकते हैं। गेन एंड सर्सन और यूरडॉन एंड डेमार्को नोटेशन के बीच अंतर के कारण लचीलापन होता है, लेकिन स्थिरता ही प्राथमिकता बनी रहती है। काले छेद और चमत्कार जैसी सामान्य त्रुटियों से बचने से तार्किक अखंडता सुनिश्चित होती है। डेटा शब्दकोश के साथ जोड़े जाने पर DFD प्रणाली की आवश्यकताओं को परिभाषित करने और विकास को मार्गदर्शन करने का एक शक्तिशाली उपकरण बन जाता है।
DFD का मूल्य उसकी कठिन डेटा गतिशीलता को तकनीकी रूप से अपरिचित स्टेकहोल्डर्स तक संचारित करने की क्षमता में निहित है। यह प्रणाली को समझने योग्य घटकों में सरल बनाता है, जिससे प्रोजेक्ट जीवनचक्र के दौरान बेहतर निर्णय लेने में सहायता मिलती है। नई एप्लिकेशन के डिज़ाइन करने या मौजूदा एप्लिकेशन के विश्लेषण करने के लिए भी, DFD के सिद्धांत प्रणाली विश्लेषण के लिए एक स्थिर आधार प्रदान करते हैं।
मुख्य बातों का सारांश ✅
- मूल तत्व: प्रक्रियाएँ, डेटा भंडार, बाहरी एजेंसियाँ और डेटा प्रवाह प्रत्येक आरेख का आधार बनाते हैं।
- पदानुक्रम: जटिलता और विवरण को प्रबंधित करने के लिए स्तर 0, 1 और 2 का उपयोग करें।
- नोटेशन: एक मानक (गेन एंड सर्सन या यूरडॉन एंड डेमार्को) चुनें और उसी पर टिके रहें।
- अखंडता: सुनिश्चित करें कि सभी प्रवाह माता-पिता और बच्चे के आरेखों के बीच संतुलित हों।
- तर्क: चमत्कार और काले छेद जैसी डेटा प्रवाह त्रुटियों से बचें।
- दस्तावेज़ीकरण: हमेशा DFD तत्वों को डेटा शब्दकोश से जोड़ें।
इन सिद्धांतों के अनुप्रयोग से यह सुनिश्चित होता है कि प्राप्त दस्तावेज़ीकरण सटीक, रखरखाव योग्य और पूरी विकास टीम के लिए उपयोगी हो। अच्छी तरह से निर्मित DFD अस्पष्टता को कम करता है और तकनीकी कार्यान्वयन को व्यावसायिक लक्ष्यों के साथ मिलाता है।