











सिस्टम विश्लेषण और सॉफ्टवेयर इंजीनियरिंग के क्षेत्र में, सूचना के आंदोलन को दृश्याकृत करना अत्यंत महत्वपूर्ण है। डेटा फ्लो डायग्राम, जिसे सामान्यतः DFD के रूप में संक्षिप्त किया जाता है, एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का एक आलेखीय प्रतिनिधित्व प्रदान करता है। नियंत्रण प्रवाह को दर्शाने वाले फ्लोचार्ट्स के विपरीत, एक DFD केवल डेटा इनपुट, आउटपुट और भंडारण पर ध्यान केंद्रित करता है। यह अंतर वास्तुकारों और विश्लेषकों के लिए महत्वपूर्ण है जिन्हें यह समझने की आवश्यकता होती है कि एक प्रणाली किन डेटा को संभालती है, बिना उस डेटा के प्रोसेसिंग के प्रक्रियात्मक तर्क में फंसे रहने के बिना।
1970 के दशक में विकसित किए जाने के बाद भी, DFD आवश्यकता इंजीनियरिंग के लिए एक मूल तकनीक बनी हुई है। यह प्रणाली का उच्च स्तरीय दृश्य प्रदान करता है, जिससे स्टेकहोल्डर्स को यह सत्यापित करने में सहायता मिलती है कि सभी आवश्यक डेटा इनपुट को लिया गया है और सभी आवश्यक आउटपुट उत्पन्न किए गए हैं। जटिल प्रणालियों को प्रबंधन योग्य घटकों में तोड़कर, DFDs तकनीकी टीमों और व्यापार उपयोगकर्ताओं के बीच संचार को सुगम बनाते हैं। यह मार्गदर्शिका सटीक आरेख बनाने के लिए आवश्यक संरचनात्मक तत्वों, नोटेशन विविधताओं और विधिगत नियमों का विवरण प्रदान करती है।
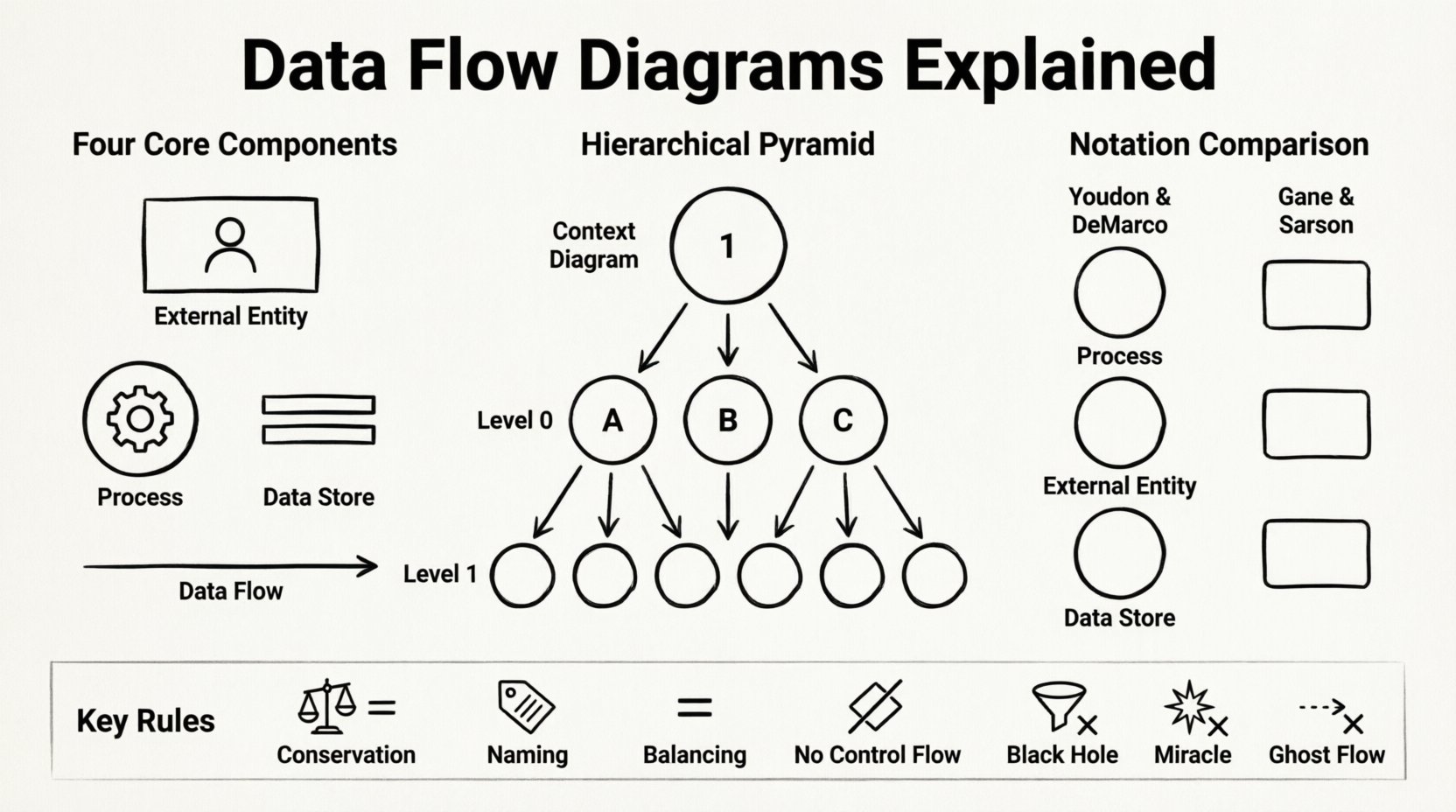
डेटा फ्लो डायग्राम के मुख्य घटक 🔍
एक वैध DFD बनाने के लिए, चार मूल निर्माण तत्वों को समझना आवश्यक है। जटिलता के बावजूद, प्रत्येक आरेख इन तत्वों पर निर्भर करता है जो प्रणाली की सीमाओं और आंतरिक संचालन को दर्शाते हैं। इन तत्वों को गलत तरीके से पहचानने से अस्पष्ट या तार्किक रूप से असंगत मॉडल बन सकते हैं।
- बाहरी एकाधिकार: इन्हें समाप्तिकारक या स्रोत के रूप में भी जाना जाता है, ये मॉडल की जा रही प्रणाली के साथ बातचीत करने वाले लोगों, संगठनों या बाहरी प्रणालियों का प्रतिनिधित्व करते हैं। ये डेटा प्रवाह के शुरुआती या अंतिम बिंदु हैं। एक एकाधिकार प्रणाली की सीमा के बाहर स्थित होता है और प्रणाली में डेटा भेजता है या उससे डेटा प्राप्त करता है। उदाहरण के लिए, एक ग्राहक आदेश देना या सरकारी कर एजेंसी रिपोर्ट प्राप्त करना।
- प्रक्रियाएं: ये वे क्रियाएं या परिवर्तन हैं जो प्रणाली के भीतर होते हैं। एक प्रक्रिया एक या अधिक स्रोतों से डेटा लेती है, उसे संशोधित करती है और उसे अन्य गंतव्यों को भेजती है। यह याद रखना महत्वपूर्ण है कि एक प्रक्रिया डेटा को संग्रहीत नहीं करती है; वह केवल उसे परिवर्तित करती है। प्रक्रियाओं को आमतौर पर क्रिया वाक्यांश जैसे “कर गणना करें” या “उपयोगकर्ता प्रमाणपत्र की पुष्टि करें” के साथ चिह्नित किया जाता है।
- डेटा भंडार: ये वे भंडार हैं जहां डेटा का बाद में उपयोग करने के लिए संग्रह किया जाता है। प्रक्रियाओं के विपरीत, डेटा भंडार गणना नहीं करते हैं। वे सक्रिय नहीं होते हैं, बल्कि स्थिर डिब्बे हैं। भौतिक संदर्भ में, ये डेटाबेस तालिकाएं, फाइलें या भौतिक फाइल बॉक्स हो सकते हैं। तार्किक संदर्भ में, वे केवल यह दर्शाते हैं कि सूचना कहां स्थायी रूप से रखी जाती है। डेटा प्रवाह को डेटा भंडार में प्रवेश करना और उससे बाहर निकलना चाहिए ताकि अद्यतन या प्राप्त करने का संकेत दिया जा सके।
- डेटा प्रवाह: ये घटकों को जोड़ने वाली तीर हैं। वे डेटा के आंदोलन का प्रतिनिधित्व करते हैं। एक डेटा प्रवाह का नाम होना चाहिए जो डेटा पैकेट की सामग्री का वर्णन करे, जैसे “आदेश विवरण” या “भुगतान पुष्टि”। प्रत्येक डेटा प्रवाह को दो घटकों को जोड़ना चाहिए; इसे हवा में शुरू या समाप्त नहीं किया जा सकता।
डेटा फ्लो डायग्राम्स के प्रकार 🗺️
DFDs पदानुक्रमिक होते हैं। एक जटिल प्रणाली को एक ही दृश्य में समझना संभव नहीं है। इसलिए मानक अभ्यास यह है कि प्रणाली को अनेक स्तरों के सारांश में विभाजित किया जाए। इस दृष्टिकोण से विश्लेषकों को विशिष्ट क्षेत्रों पर ध्यान केंद्रित करने में सहायता मिलती है बिना पूरी प्रणाली के संदर्भ को खोए।
1. संदर्भ आरेख (स्तर 0)
यह उच्चतम स्तर का सारांश है। यह पूरी प्रणाली को एकल प्रक्रिया बबल के रूप में दर्शाता है। यह प्रणाली और बाहरी एकाधिकारों के बीच संबंध को दिखाता है। इस चरण में कोई आंतरिक प्रक्रियाएं या डेटा भंडार दिखाई नहीं देते हैं। उद्देश्य स्पष्ट रूप से प्रणाली की सीमा को परिभाषित करना है। यह प्रश्न का उत्तर देता है: “यह प्रणाली बाहरी दुनिया के लिए क्या करती है?”
2. स्तर 0 आरेख (आरेख 0)
इसे अवधारणात्मक मॉडल के रूप में भी जाना जाता है, यह आरेख संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विस्तारित करता है। यह प्रणाली के मुख्य कार्यों का नक्शा प्रदान करता है। यह दिखाता है कि मुख्य डेटा प्रवाह प्राथमिक प्रक्रियाओं को डेटा भंडारों और बाहरी एकाधिकारों से कैसे जोड़ते हैं। यह विस्तृत डिजाइन के पहले चरण के रूप में अक्सर उपयोग किया जाता है।
3. स्तर 1 और विघटन
जैसे विश्लेषण गहरा होता है, स्तर 0 प्रक्रियाओं को और अधिक स्तर 1 आरेखों में विभाजित किया जाता है। यह तब तक जारी रहता है जब तक कि प्रक्रियाएं इतनी सरल नहीं हो जाती हैं कि उन्हें सीधे लागू किया जा सके। प्रत्येक बच्चे के आरेख को अपने माता-पिता के साथ संतुलित होना चाहिए। इसका मतलब है कि माता-पिता आरेख में एक प्रक्रिया के इनपुट और आउटपुट को उस बच्चे के आरेख में विस्तारित प्रक्रिया के इनपुट और आउटपुट के साथ मेल खाना चाहिए।
नोटेशन मानकों की तुलना 📐
DFD बनाने के लिए कोई एकल सार्वभौमिक मानक नहीं है। उद्योग में दो प्रमुख विचारधाराएं प्रमुख हैं। दोनों एक ही तार्किक सूचना को स्थानांतरित करती हैं लेकिन घटकों का प्रतिनिधित्व करने के लिए अलग-अलग आकृतियों का उपयोग करती हैं। एक मानक का चयन करना और उस पर अटूट रहना प्रोजेक्ट के भीतर संगतता के लिए आवश्यक है।
| घटक | यौरडॉन और डीमार्को नोटेशन | गेन और सर्सन नोटेशन |
|---|---|---|
| प्रक्रिया | वृत्त या गोल कोने वाला आयत | गोल कोने वाला आयत |
| डेटा भंडार | दो समानांतर क्षैतिज रेखाएँ | खुला आयत |
| बाहरी एकाई | आयत | आयत |
| डेटा प्रवाह | वक्र या सीधी तीर | सीधी तीर |
| अनुमान | प्रवाह के पास पाठ | प्रवाह के पास पाठ |
जबकि आकृतियाँ भिन्न हैं, संबंधों को नियंत्रित करने वाले नियम समान रहते हैं। यौरडॉन और डेमार्को शैली को पुराने लेगेसी दस्तावेज़ों में अक्सर प्राथमिकता दी जाती है, जबकि गेन और सर्सन शैली आधुनिक प्रणालियों में अक्सर अपनाई जाती है क्योंकि इसकी साफ आयताकार भाषा होती है।
तार्किक बनाम भौतिक अंतर 🔄
DFD मॉडलिंग में एक महत्वपूर्ण अवधारणा है तार्किक डिज़ाइन और भौतिक डिज़ाइन के बीच अंतर करना। इस अंतर के कारण सुनिश्चित होता है कि मॉडल तकनीक में बदलाव आने पर भी वैध रहता है।
- तार्किक DFD: व्यापार आवश्यकताओं पर ध्यान केंद्रित करता है। यह यह बताता है कि प्रणाली क्या करती है, न कि यह कैसे करती है। एक तार्किक आरेख में, एक “डेटाबेस” को सामान्य रूप से डेटा भंडार के रूप में दर्शाया जा सकता है, बिना बताए कि यह SQL, NoSQL या समतल फ़ाइल है। एक “प्रक्रिया” को “लोन की मंजूरी” के रूप में दर्शाया जा सकता है, चाहे मंजूरी मानव द्वारा, स्क्रिप्ट द्वारा या AI एल्गोरिदम द्वारा की गई हो।
- भौतिक DFD: कार्यान्वयन विवरण पर ध्यान केंद्रित करता है। यह बताता है कि प्रणाली कैसे बनाई जाती है। यहाँ, डेटा भंडार को “सर्वर A में ओरेकल टेबल्स” के रूप में निर्दिष्ट किया जा सकता है। प्रक्रिया को “जावा सीलेट रिक्वेस्ट प्रोसेसिंग” के रूप में दर्शाया जा सकता है। भौतिक आरेख डेवलपर्स द्वारा कोडिंग चरण के दौरान उपयोग किए जाते हैं।
एक ही आरेख में इन स्तरों को मिलाने से भ्रम पैदा होता है। स्टेकहोल्डर समीक्षा के लिए तार्किक दृष्टिकोण बनाए रखना और तकनीकी कार्यान्वयन के लिए भौतिक दृष्टिकोण बनाए रखना सर्वोत्तम प्रथा है।
DFD बनाने के नियम ⚙️
आरेख बनाना केवल आकृतियाँ बनाने के बारे में नहीं है; यह सख्त तार्किक नियमों का पालन करने के बारे में है। इन नियमों के उल्लंघन से आरेख तकनीकी रूप से अमान्य हो जाता है और विश्लेषण के लिए बेकार हो जाता है।
1. डेटा का संरक्षण
किसी प्रक्रिया के भीतर डेटा का निर्माण या नष्ट नहीं किया जा सकता। यदि डेटा किसी प्रक्रिया में प्रवेश करता है, तो उसे या तो प्रक्रिया से बाहर निकलना चाहिए या संग्रहीत करना चाहिए। कोई प्रक्रिया ऐसा डेटा आउटपुट नहीं कर सकती जो इनपुट नहीं था, बशर्ते कि वह डेटा अन्य इनपुट से निकला हो। इससे प्रणाली डिज़ाइन में “चमत्कार” की रोकथाम होती है।
2. नामकरण प्रथाएँ
प्रत्येक तत्व का एक अद्वितीय नाम होना चाहिए। डेटा प्रवाह को संज्ञा (उदाहरण के लिए, “इन्वॉइस”) होना चाहिए। प्रक्रियाओं को क्रिया-संज्ञा वाक्यांश (उदाहरण के लिए, “इन्वॉइस प्रोसेस”) होना चाहिए। डेटा भंडार को समुच्चय संज्ञा (उदाहरण के लिए, “इन्वॉइस”) होना चाहिए। नामकरण में स्थिरता तंत्र के नेविगेशन और समझ में आसानी प्रदान करती है।
3. संतुलन
यह नियम हीरार्किक विभाजन पर लागू होता है। यदि किसी प्रक्रिया को उप-प्रक्रियाओं में विभाजित किया जाता है, तो मूल प्रक्रिया के इनपुट और आउटपुट का योग उप-प्रक्रियाओं के इनपुट और आउटपुट के योग के बराबर होना चाहिए। विभाजन के दौरान कोई डेटा गायब या जादुई तरीके से दिखाई नहीं देना चाहिए।
4. नियंत्रण प्रवाह से बचना
DFD नियंत्रण प्रवाह आरेख नहीं हैं। वे “यदि X, तो Y” जैसे निर्णय बिंदु नहीं दिखाते हैं। वे डेटा के आंदोलन को दिखाते हैं। निर्णय तर्क को प्रक्रिया विवरण में ही संभाला जाता है, न कि आरेख के अंदर। इससे दृश्य प्रतिनिधित्व साफ रहता है और डेटा पर ध्यान केंद्रित रहता है।
बचने के लिए सामान्य त्रुटियाँ ❌
अनुभवी विश्लेषक भी एक DFD में त्रुटियाँ डाल सकते हैं। सामान्य गलतियों के बारे में जागरूक रहने से मॉडल की अखंडता बनाए रखने में मदद मिलती है।
- काले छेद:एक प्रक्रिया जिसमें इनपुट हैं लेकिन आउटपुट नहीं हैं। इसका तात्पर्य है कि डेटा का उपयोग किया जा रहा है और कभी उपयोग नहीं किया जाता है, जो एक तार्किक त्रुटि है।
- चमत्कार:एक प्रक्रिया जिसमें आउटपुट हैं लेकिन इनपुट नहीं हैं। इसका तात्पर्य है कि डेटा बिना किसी कारण के उत्पन्न किया जा रहा है।
- भूत के प्रवाह:वे डेटा प्रवाह जो किसी भी घटक से जुड़े नहीं हैं। प्रत्येक तीर का स्पष्ट स्रोत और गंतव्य होना चाहिए।
- ओवरलैपिंग कार्य:जब एक ही प्रक्रिया बॉक्स बहुत कुछ करने की कोशिश करता है। यदि एक प्रक्रिया बॉक्स में सात से अधिक इनपुट या आउटपुट हैं, तो यह संभवतः बहुत सारी चीजें करने की कोशिश कर रहा है और इसे विभाजित करना चाहिए।
- बाहरी घटक चक्र:बाहरी घटकों को दूसरे बाहरी घटकों से सीधे जोड़ना चाहिए। सभी बातचीत को सिस्टम सीमा के माध्यम से जाना चाहिए।
प्रणाली विश्लेषण में लाभ 🛠️
इन आरेखों को बनाने में समय निवेश करने का क्या कारण है? इसका मूल्य सरल दस्तावेजीकरण से आगे तक जाता है।
- संचार:यह तकनीकी और गैर-तकनीकी हितधारकों के बीच के अंतर को पार करता है। दृश्य मॉडल टेक्स्ट आवश्यकताओं की तुलना में बातचीत करने में आसान होते हैं।
- अंतर विश्लेषण: प्रवाह के नक्शे बनाकर विश्लेषक अनुपस्थित डेटा आवश्यकताओं की पहचान कर सकते हैं। यदि उपयोगकर्ता को एक रिपोर्ट की आवश्यकता है, लेकिन उस रिपोर्ट के समर्थन करने वाले डेटा स्टोर तक जाने वाला कोई डेटा प्रवाह नहीं है, तो एक अंतर जल्दी ही पहचान लिया जाता है।
- परीक्षण आधार: डेटा प्रवाह परीक्षण मामलों को परिभाषित करते हैं। यदि कोई विशिष्ट डेटा प्रवाह परिभाषित किया गया है, तो एक परीक्षण को यह सत्यापित करना चाहिए कि डेटा उस प्रवाह के माध्यम से सही तरीके से आगे बढ़ रहा है।
- प्रणाली दस्तावेजीकरण: जैसे-जैसे प्रणालियाँ विकसित होती हैं, DFDs एक जीवंत नक्शे के रूप में कार्य करते हैं। जब नए फीचर जोड़े जाते हैं, तो आरेख को अद्यतन किया जाता है, जिससे दस्तावेजीकरण को कोड के साथ समन्वय में रखा जाता है।
अक्सर पूछे जाने वाले प्रश्न ❓
DFD और फ्लोचार्ट में क्या अंतर है?
एक फ्लोचार्ट एल्गोरिदम के नियंत्रण तर्क और निर्णय बिंदुओं को नक्शा बनाता है। यह चरणों के क्रम को दिखाता है। एक DFD डेटा को नक्शा बनाता है। यह बताता है कि डेटा कहाँ से आता है और कहाँ जाता है, चाहे ऑपरेशन का क्रम कुछ भी हो। फ्लोचार्ट कोड तर्क के लिए होते हैं; DFD प्रणाली संरचना के लिए होते हैं।
क्या DFD सुरक्षा नियंत्रण दिखा सकता है?
मानक DFD सीधे सुरक्षा प्रोटोकॉल जैसे एन्क्रिप्शन या प्रमाणीकरण को नहीं दिखाते हैं। हालांकि, एक सुरक्षा विश्लेषक डेटा प्रवाह को टिप्पणी कर सकता है ताकि यह दिखाया जा सके कि संवेदनशील डेटा का उपयोग कहाँ किया जाता है या जहाँ पहुँच नियंत्रण लागू किया जाता है। इसे आमतौर पर विशिष्ट डेटा प्रवाह से जुड़े नोट के रूप में दर्शाया जाता है।
DFD बनाने के लिए कोई विशिष्ट उपकरण आवश्यक है?
नहीं। बहुत सारे सॉफ्टवेयर उपकरण मौजूद हैं, लेकिन आरेख एक अवधारणात्मक वस्तु है। इसे कागज, व्हाइटबोर्ड या किसी भी वेक्टर ग्राफिक्स उपकरण के उपयोग से बनाया जा सकता है। माध्यम मॉडल की तर्क को नहीं बदलता है।
DFD वास्तविक समय के डेटा का निपटान कैसे करते हैं?
DFD आम तौर पर स्थिर प्रतिनिधित्व होते हैं। इनमें समय या लेटेंसी को आंतरिक रूप से नहीं दिखाया जाता है। वास्तविक समय की प्रणालियों के लिए, DFD को अक्सर स्थिति संक्रमण आरेख या समय आरेख के साथ जोड़ा जाता है ताकि डेटा गतिशीलता के समयानुकूल पहलुओं को पकड़ा जा सके।
पद्धति पर निष्कर्ष
एक डेटा प्रवाह आरेख बनाना अमूर्ति का एक व्यवस्थित अभ्यास है। इसमें विश्लेषक को कार्यान्वयन विवरणों को हटाकर डेटा के गति के मूल स्वरूप पर ध्यान केंद्रित करने की आवश्यकता होती है। संरचनात्मक नियमों और निरूपण मानकों का पालन करके टीमें अपनी सूचना प्रणालियों का स्पष्ट नक्शा बना सकती हैं। इस स्पष्टता से जोखिम कम होता है, संचार सुधारता है, और यह सुनिश्चित करता है कि अंतिम प्रणाली डेटा की वास्तविक आवश्यकताओं को पूरा करती है जिसे वह प्रसंस्कृत करती है।
DFD अब भी संबंधित रहता है क्योंकि यह एक मूलभूत प्रश्न का समाधान करता है: “डेटा कहाँ जाता है?” जटिल, वितरित प्रणालियों के युग में, सूचना के मार्ग का पता लगाना कभी नहीं इतना महत्वपूर्ण रहा है। एक सरल वेब एप्लिकेशन या बड़े पैमाने पर उद्यम प्रणाली के लिए भी, DFD मॉडलिंग के सिद्धांत डिज़ाइन और विश्लेषण के लिए एक स्थिर आधार प्रदान करते हैं।