











डेटा फ्लो डायग्राम (DFD) प्रणाली के तर्क के लिए नक्शा के रूप में कार्य करते हैं, जो प्रक्रिया के माध्यम से जानकारी के आवागमन को दर्शाते हैं। वे प्रणाली विश्लेषण और डिजाइन में महत्वपूर्ण अभिलेख हैं, व्यापार आवश्यकताओं और तकनीकी कार्यान्वयन के बीच के अंतर को पार करते हैं। हालांकि, मान्यता प्राप्त बिना कोई आरेख सिर्फ एक खाका है। वास्तुकला की अखंडता सुनिश्चित करने के लिए, प्रत्येक DFD को कठोर जांच के माध्यम से गुजरना होगा।
यह मार्गदर्शिका डेटा फ्लो डायग्राम्स के मान्यता के लिए एक व्यापक ढांचा प्रदान करती है। इसका ध्यान संरचनात्मक सुसंगतता, तार्किक सहीता और व्यापार नियमों के साथ संरेखण पर है। इस चेकलिस्ट का पालन करके विश्लेषक विकास चक्र के बाद के चरणों में महंगी पुनर्कार्य को रोक सकते हैं।
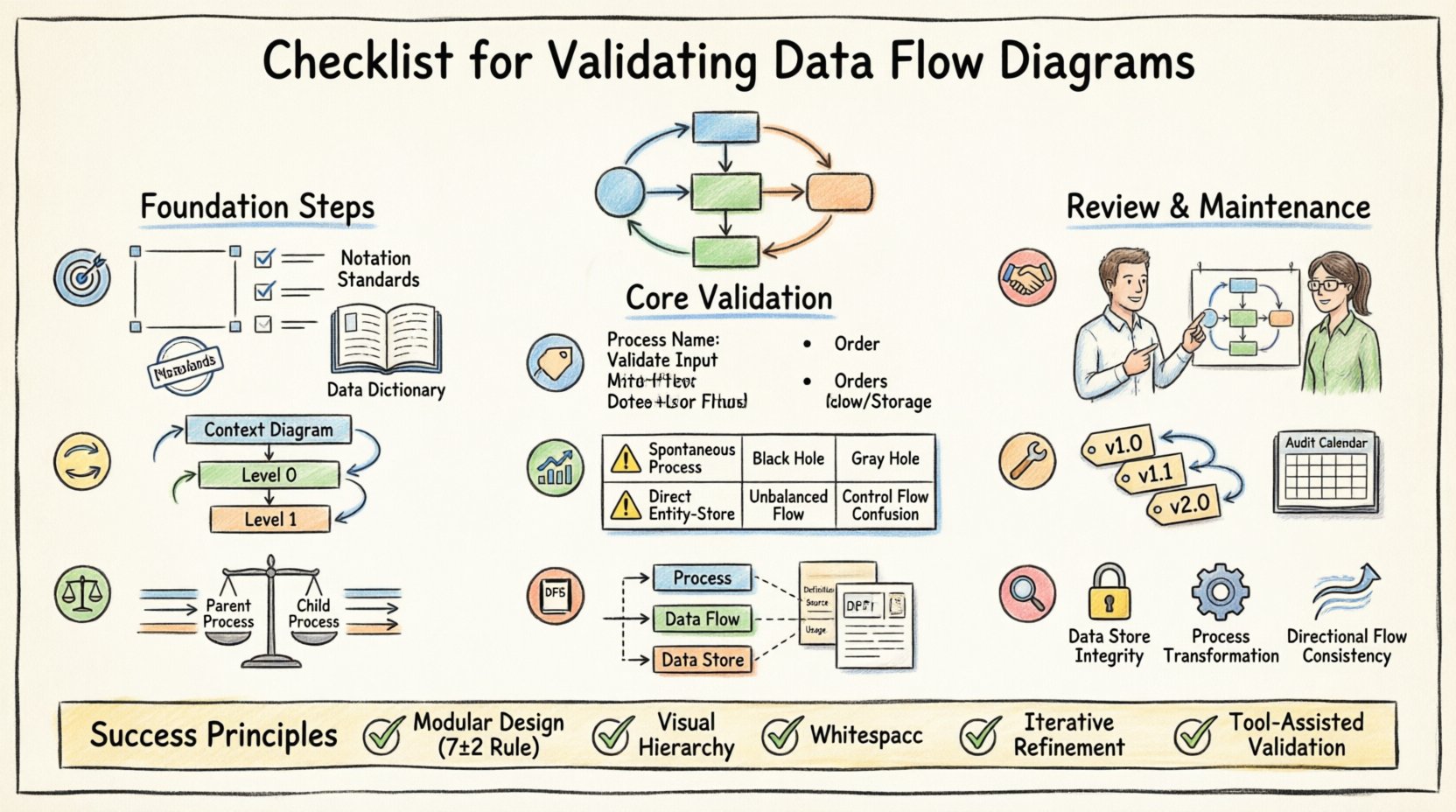
📋 मान्यता से पहले तैयारी
आरेख के दृश्य तत्वों की जांच करने से पहले, संदर्भ को स्थापित करना आवश्यक है। मान्यता एक खाली स्थान में नहीं हो सकती है। निम्नलिखित पूर्व शर्तें समीक्षा प्रक्रिया की प्रभावशीलता सुनिश्चित करती हैं।
- प्रणाली की सीमा को परिभाषित करें:स्पष्ट रूप से पहचानें कि प्रणाली के अंदर क्या है और बाहर क्या है। बाहरी एकाधिकार (स्रोत और निकास) को स्पष्ट रूप से परिभाषित किया जाना चाहिए।
- आवश्यकताओं को एकत्र करें: कार्यात्मक और गैर-कार्यात्मक आवश्यकताएं उपलब्ध हों। आरेख को इन विशिष्टताओं के सीधे मानचित्र के रूप में होना चाहिए।
- मानकों को स्थापित करें: निर्देशांक मानकों पर सहमति बनाएं (उदाहरण के लिए, गेन एंड सर्सन बनाम योर्डन एंड कोड)। निर्देशांकों को मिलाने से अस्पष्टता उत्पन्न होती है।
- डेटा शब्दकोश की समीक्षा करें: सुनिश्चित करें कि डेटा तत्वों की मास्टर सूची मौजूद है। यदि डेटा परिभाषाएं अनुपलब्ध हैं, तो DFD मान्य नहीं हो सकता है।
🔄 पदानुक्रम और विघटन
DFD पदानुक्रमित होते हैं। वे संदर्भ आरेख से शुरू होते हैं और स्तर 0, स्तर 1 और गहरे स्तरों में विघटित होते हैं। मान्यता के लिए इन परतों के बीच संबंधों की जांच करना आवश्यक है।
1. संदर्भ आरेख मान्यता
संदर्भ आरेख (स्तर -1) प्रणाली को एकल प्रक्रिया के रूप में दर्शाता है। गहरे स्तरों की समीक्षा से पहले इसकी सटीकता सुनिश्चित करना आवश्यक है।
- एकल प्रक्रिया नोड: सुनिश्चित करें कि पूरी प्रणाली का प्रतिनिधित्व करने वाली एकल प्रक्रिया है।
- बाहरी एकाधिकार: सभी बाहरी स्रोतों और गंतव्यों की उपस्थिति की पुष्टि करें। अनुपस्थित एकाधिकार अनुपस्थित डेटा प्रवाह को दर्शाते हैं।
- डेटा प्रवाह: सुनिश्चित करें कि प्रणाली के सभी इनपुट और आउटपुट को ध्यान में रखा गया है। किसी भी अचानक डेटा निर्माण या नष्ट की अनुमति नहीं है।
2. स्तर 0 और विघटन
स्तर 0 एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में बांटता है। यहां से जटिलता शुरू होती है।
- प्रक्रिया संख्या: प्रक्रियाओं की संख्या को प्रबंधन योग्य सेट तक सीमित करें (आमतौर पर 5 से 9 तक)। बहुत अधिक प्रक्रियाएं पाठक को भ्रमित करती हैं।
- प्रक्रिया नाम: नाम क्रियात्मक होने चाहिए (क्रिया + संज्ञा), उदाहरण के लिए “इन्वॉइस की गणना करें” बजाय “इन्वॉइस”।
- डेटा भंडार: इस स्तर पर डेटा कहाँ रखा जाता है, उसे पहचानें। सुनिश्चित करें कि कोई भी डेटा स्टोर बाहरी एजेंसी से सीधे जुड़ा न हो, बल्कि बीच में कोई प्रक्रिया हो।
⚖️ संतुलन नियम
DFD निर्माण में सबसे आम त्रुटियों में से एक संतुलन नियम का उल्लंघन करना है। इस नियम के अनुसार, एक मातृ प्रक्रिया के इनपुट और आउटपुट को उसके बच्चे प्रक्रियाओं के इनपुट और आउटपुट के बिल्कुल मेल बैठने चाहिए।
- इनपुट संरक्षण: यदि एक मातृ प्रक्रिया “ग्राहक आदेश” प्राप्त करती है, तो बच्चे प्रक्रियाएँ संयुक्त रूप से “ग्राहक आदेश” प्राप्त करनी चाहिए। बच्चे स्तर पर कोई नया इनपुट नहीं दिखाई दे सकता जो मातृ स्तर पर नहीं था।
- आउटपुट संरक्षण: यदि एक मातृ प्रक्रिया “बिल” भेजती है, तो बच्चे प्रक्रियाएँ संयुक्त रूप से “बिल” भेजनी चाहिए। कोई आउटपुट अप्रत्याशित रूप से गायब या दिखाई नहीं देना चाहिए।
- प्रवाह सत्यापन: मातृ प्रक्रिया में प्रवेश करने वाली प्रत्येक लाइन का अनुसरण करें। मातृ प्रक्रिया से निकलने वाली प्रत्येक लाइन का अनुसरण करें। यह सुनिश्चित करें कि वे बच्चे आरेख में मौजूद हैं।
- स्टोर संगति: यदि डेटा लेखन या पढ़ने के लिए बच्चे स्तर पर डेटा स्टोर का उपयोग किया जा रहा है, तो मातृ स्तर पर पहुँचे गए डेटा स्टोर को बच्चे स्तर पर भी पहुँचना चाहिए।
संतुलन के अभाव के कारण उच्च स्तर के दृश्य और विस्तृत कार्यान्वयन के बीच असंगति उत्पन्न होती है। इसके अक्सर विकासकर्ताओं द्वारा अनिर्धारित विशेषताएँ बनाने या महत्वपूर्ण डेटा आवश्यकताओं को नजरअंदाज करने के परिणामस्वरूप आता है।
🏷️ नामाकरण प्रथाएँ
नामाकरण में संगति पठनीयता और रखरखाव के लिए अत्यंत महत्वपूर्ण है। अस्पष्ट नाम प्रणाली के व्यवहार के गलत व्याख्या के कारण होते हैं।
- प्रक्रियाएँ: हमेशा क्रिया के बाद संज्ञा का उपयोग करें। एकल शब्दों से बचें।सही: “स्टॉक अपडेट करें।”गलत: “स्टॉक अपडेट”।
- डेटा प्रवाह: एकवचन संज्ञा का उपयोग करें।सही: “वस्तु।”गलत: “वस्तुएँ”।
- डेटा स्टोर: बहुवचन संज्ञा का उपयोग करें।सही: “आदेश।”गलत: “आदेश”।
बाहरी एकाइयाँ: संज्ञा या व्यापारिक शब्दों का उपयोग करें। सही: “ग्राहक।” गलत: “उपयोगकर्ता”।
📊 सामान्य त्रुटियाँ और सत्यापन जोखिम
यहाँ अनुभवी विश्लेषक भी त्रुटियाँ करते हैं। निम्नलिखित तालिका में अक्सर होने वाले उल्लंघन और उनके प्रणाली संरचना पर संभावित प्रभाव का वर्णन किया गया है।
| जाँच श्रेणी | सत्यापन मानदंड | अनदेखी करने पर जोखिम |
|---|---|---|
| स्वतंत्र प्रक्रियाएँ | प्रत्येक प्रक्रिया में कम से कम एक इनपुट प्रवाह होना चाहिए। | डेटा बिना किसी आधार के बनाया जाता है, जिससे प्रणाली की तर्कसंगतता खंडित होती है। |
| काले छेद | प्रत्येक प्रक्रिया में कम से कम एक आउटपुट प्रवाह होना चाहिए। | परिणाम के बिना डेटा का उपयोग किया जाता है, जिससे तर्क की कमी स्पष्ट होती है। |
| धूसर छेद | इनपुट और आउटपुट डेटा की सामग्री का मेल होना चाहिए। | परिवर्तन की स्पष्ट परिभाषा के बिना डेटा का परिवर्तन किया जाता है। |
| सीधे एंटिटी-टू-स्टोर | कोई डेटा प्रवाह एक एंटिटी को सीधे डेटा स्टोर से नहीं जोड़ता है। | व्यापारिक नियमों और सत्यापन तर्क को बायपास करता है। |
| असंतुलित प्रवाह | माता-पिता और बच्चे के प्रवाह का मेल होना चाहिए। | संरचना का विचलन; कार्यान्वयन डिज़ाइन के अनुरूप नहीं है। |
| नियंत्रण प्रवाह | DFD डेटा दिखाते हैं, नियंत्रण सिग्नल नहीं। | डेटा गतिशीलता और सिस्टम ट्रिगर्स के बीच भ्रम। |
📚 डेटा डिक्शनरी के साथ संरेखण
एक डेटा फ्लो डायग्राम केवल उन डेटा परिभाषाओं के बराबर ही अच्छा होता है जो इसका समर्थन करती हैं। डेटा डिक्शनरी प्रत्येक डेटा फ्लो और स्टोर की संरचना को परिभाषित करने वाले मेटाडेटा का भंडार है।
- डेटा तत्व सुसंगतता: जांचें कि DFD में नामित डेटा तत्व डेटा डिक्शनरी में मौजूद हैं या नहीं।
- डेटा संरचना: डेटा फ्लो की संरचना की पुष्टि करें। क्या “ग्राहक आदेश” में परिभाषित अनुसार “ग्राहक आईडी” और “आदेश तिथि” शामिल हैं?
- एकल पहचानकर्ता: सुनिश्चित करें कि डेटा स्टोर में प्राथमिक कुंजियों की पहचान की गई है ताकि डेटा अखंडता का समर्थन किया जा सके।
- एलियास: यदि किसी डेटा तत्व के दस्तावेज़ में कई नाम हैं, तो उन्हें समान रूप से निर्धारित करें ताकि भ्रम न हो।
- डेटा प्रकार: सुनिश्चित करें कि डायग्राम और डेटाबेस स्कीमा के बीच डेटा प्रकार (संख्यात्मक, स्ट्रिंग, तिथि) सुसंगत हैं।
🤝 स्टेकहोल्डर समीक्षा और स्वीकृति
तकनीकी सटीकता पर्याप्त नहीं है। आवश्यकताओं के लिए योगदान देने वाले व्यावसायिक स्टेकहोल्डरों को आरेख को समझना चाहिए।
- व्यावसायिक शब्दावली: लेबल में तकनीकी जर्गन का उपयोग न करें। व्यावसायिक भाषा का उपयोग करें।
- वॉकथ्रू: एक वॉकथ्रू सत्र आयोजित करें जहां स्टेकहोल्डर एक विशिष्ट लेनदेन के लिए डेटा के प्रवाह का अनुसरण करें।
- अंतर विश्लेषण: स्टेकहोल्डरों से पूछें कि क्या कोई महत्वपूर्ण व्यावसायिक गतिविधि आरेख में अनुपस्थित है।
- सत्यापन स्वीकृति: औपचारिक स्वीकृति प्राप्त करें। इससे यह सुनिश्चित होता है कि आरेख सहमत व्यावसायिक तर्क को सही तरीके से प्रतिबिंबित करता है।
🛠️ रखरखाव और संस्करण नियंत्रण
प्रणालियाँ विकसित होती हैं। आवश्यकताएं बदलती हैं। आज वैध एक DFD कल अवैध हो सकता है। रखरखाव सत्यापन चक्र का हिस्सा है।
- परिवर्तन प्रबंधन: प्रक्रिया तर्क में किसी भी परिवर्तन के लिए DFD के अपडेट की आवश्यकता होती है। आरेख के बिना कोड को अपडेट मत करें।
- संस्करण निर्धारण: आरेखों को संस्करण संख्या और तिथि के साथ लेबल करें। परिवर्तनों के इतिहास को बनाए रखें ताकि प्रणाली के विकास को समझा जा सके।
- लिंकेज DFD को आवश्यकता दस्तावेज से जोड़ें। यदि कोई आवश्यकता बदलती है, तो संबंधित आरेख नोड को चिह्नित करना आवश्यक है।
- आवधिक ऑडिट: वास्तविक प्रणाली व्यवहार के विरुद्ध DFD की नियमित समीक्षा की योजना बनाएं। समय के साथ विचलन होता है।
🔍 विस्तृत तकनीकी संगतता जांच
सामान्य नियमों के अतिरिक्त, आरेख को कार्यान्वयन के लिए तैयार बनाने के लिए विशिष्ट तकनीकी सीमाओं का पालन करना आवश्यक है।
1. डेटा स्टोर अखंडता
डेटा स्टोर स्थायी भंडारण का प्रतिनिधित्व करते हैं। उन्हें अस्थायी नहीं होना चाहिए।
- पढ़ने/लिखने की अनुमति: सत्यापित करें कि प्रत्येक प्रक्रिया जो किसी स्टोर में लिखती है, आवश्यकता पड़ने पर उससे पढ़ती है। सुनिश्चित करें कि डेटा संशोधन शामिल होने पर कोई प्रक्रिया स्टोर में लिखने के बिना पढ़ने की आवश्यकता के बिना लिखे।
- खुली/बंद सीमाएं: डेटा स्टोर के खुली सीमाएं नहीं होनी चाहिए। प्रत्येक डेटा स्टोर को कम से कम एक प्रक्रिया से जुड़ा होना चाहिए।
- स्टोर नामकरण: नाम सामग्री का प्रतिनिधित्व करना चाहिए, उदाहरण के लिए, “कर्मचारी फाइलें” के बजाय “फाइल 1”।
2. प्रक्रिया तर्क पूर्णता
प्रक्रियाएं परिवर्तन तर्क का प्रतिनिधित्व करती हैं।
- परिवर्तन: सुनिश्चित करें कि प्रक्रिया वास्तव में डेटा को बदलती है। जो प्रक्रिया बस डेटा को पार करती है, वह एक प्रवाह है, प्रक्रिया नहीं।
- निर्णय बिंदु: जबकि DFDs निर्णय तर्क को स्पष्ट रूप से नहीं दिखाते (जैसे फ्लोचार्ट करते हैं), तो प्रवाह लेबल को आवश्यकता पड़ने पर शर्तों को इंगित करना चाहिए (उदाहरण के लिए, “वैध आदेश” बनाम “अवैध आदेश”)।
- बाहरी निर्भरता: यदि कोई प्रक्रिया बाहरी प्रणाली पर निर्भर है, तो इसे बाहरी एकाधिकार या उपप्रक्रिया के रूप में दर्शाया जाना चाहिए, जादू के डिब्बे के रूप में नहीं।
3. प्रवाह दिशात्मकता
तीर डेटा गति की दिशा को दर्शाते हैं।
- एकल दिशा: तीर स्रोत से गंतव्य की ओर इशारा करना चाहिए। डेटा प्रवाह वास्तव में एक ही चरण में द्विदिशात्मक होने के अलावा डबल हेडेड तीर का उपयोग न करें।
- लेबल स्पष्टता: प्रत्येक तीर को लेबल होना चाहिए। बिना लेबल वाले प्रवाह अस्पष्ट होते हैं।
- क्रॉसिंग नहीं: क्रॉसिंग लाइनों को कम करें। यदि लाइनें क्रॉस करती हैं, तो क्रॉसओवर सिंबल का उपयोग करें या लेआउट को पुनर्गठित करें ताकि पठनीयता में सुधार हो।
🧠 संज्ञानात्मक भार कम करना
एक मान्य DFD केवल तकनीकी रूप से सही होने के अलावा; इसे मानसिक रूप से उपलब्ध होना चाहिए। यदि आरेख बहुत जटिल है, तो इसका मुख्य उद्देश्य: संचार विफल हो जाता है।
- बहुलता:जटिल प्रक्रियाओं को उपप्रक्रियाओं में बांटें। यदि किसी प्रक्रिया में 7 से अधिक इनपुट या आउटपुट हैं, तो उसे विघटित करें।
- दृश्य स्तर:प्रक्रियाओं के लिए स्थिर आकृतियों का उपयोग करें, डेटा स्टोर के लिए हीरे के आकार (नोटेशन के आधार पर), और एकाधिकार के लिए आयताकार आकृतियों का उपयोग करें। स्थिरता मानसिक भार को कम करती है।
- खाली स्थान:तत्वों के बीच स्थान दें। भारी आरेख त्रुटियों को छिपा देते हैं।
- रंग कोडिंग:यदि उपकरण अनुमति देता है, तो विभिन्न प्रकार के प्रवाहों (उदाहरण के लिए, इनपुट बनाम आउटपुट) को अलग करने के लिए रंग का उपयोग करें, लेकिन यह सुनिश्चित करें कि काले और सफेद प्रिंटिंग में पढ़ने योग्य रहे।
📝 अंतिम विचार
सत्यापन एक आवर्ती प्रक्रिया है। यह पहली बार में दुर्लभ रूप से सफल होता है। लक्ष्य एक मजबूत, स्पष्ट और वास्तविकता के अनुरूप मॉडल बनाना है।
- आवर्ती सुधार:आरेख को कई बार संशोधित करने की अपेक्षा करें। प्रत्येक संशोधन स्पष्टता बढ़ाना चाहिए।
- दस्तावेज़ीकरण स्वच्छता:आरेख को दस्तावेज़ीकरण के साथ समन्वय में रखें। यदि पाठ एक बात कहता है और आरेख दूसरी बात कहता है, तो प्रणाली विफल हो जाएगी।
- प्रशिक्षण:सुनिश्चित करें कि टीम नोटेशन को समझती है। यदि समीक्षक प्रतीकों को नहीं समझते हैं, तो चेकलिस्ट बेकार है।
- उपकरण:विन्यास नियमों को बल देने वाले मॉडलिंग उपकरणों का उपयोग करें। जब तक चेकलिस्ट मैन्युअल है, उपकरण बैलेंसिंग जैसी मूल जांच को स्वचालित कर सकते हैं।
इस व्यापक चेकलिस्ट का पालन करके, आप सुनिश्चित करते हैं कि डेटा प्रवाह आरेख प्रणाली के लिए विश्वसनीय आधार के रूप में कार्य करें। वे विकास को मार्गदर्शन करने वाला एक जीवंत दस्तावेज़ बन जाते हैं और व्यापार तर्क की पुष्टि करते हैं। इस अनुशासन से जोखिम कम होता है, संचार में सुधार होता है, और यह सुनिश्चित करता है कि अंतिम उत्पाद इच्छित आवश्यकताओं को पूरा करता है।
याद रखें कि आरेख सोचने का एक उपकरण है, केवल एक डिलीवरेबल नहीं। आरेख के सत्यापन की क्रिया विश्लेषक को तार्किक अंतरालों का सामना करने के लिए मजबूर करती है, जो अन्यथा परीक्षण शुरू होने तक छिपे रह सकते हैं। विस्तार से सत्यापन करने के लिए समय लें।