











सिस्टम विश्लेषण और सॉफ्टवेयर विकास के जटिल माहौल में स्पष्टता अत्यंत महत्वपूर्ण है। जब स्टेकहोल्डर्स, डेवलपर्स और विश्लेषक एक सिस्टम के माध्यम से जानकारी के आवागमन को समझने की कोशिश करते हैं, तो अस्पष्टता कार्यान्वयन में महंगी त्रुटियों का कारण बन सकती है। इसी स्थिति में डेटा फ्लो डायग्राम (DFD) एक महत्वपूर्ण उपकरण के रूप में काम करता है। यह एक संरचित तरीके से सिस्टम के भीतर जानकारी के प्रवाह का प्रतिनिधित्व करता है, ताकि तार्किक प्रक्रियाओं को भौतिक कार्यान्वयन से अलग किया जा सके।
एक DFD सिर्फ एक ड्राइंग नहीं है; यह एक संचार उपकरण है। यह टीमों को कोड के विशिष्ट विवरणों में फंसे बिना डेटा इनपुट, परिवर्तन और आउटपुट को देखने की अनुमति देता है। इन प्रवाहों को मैप करके संगठन बॉटलनेक, डेटा अखंडता सुनिश्चित कर सकते हैं और व्यापार लक्ष्यों को तकनीकी क्षमताओं के साथ मिलाने में सक्षम होते हैं। यह मार्गदर्शिका आधुनिक सूचना प्रणालियों में डेटा फ्लो डायग्राम के यांत्रिकी, घटकों और रणनीतिक मूल्य का अध्ययन करती है।
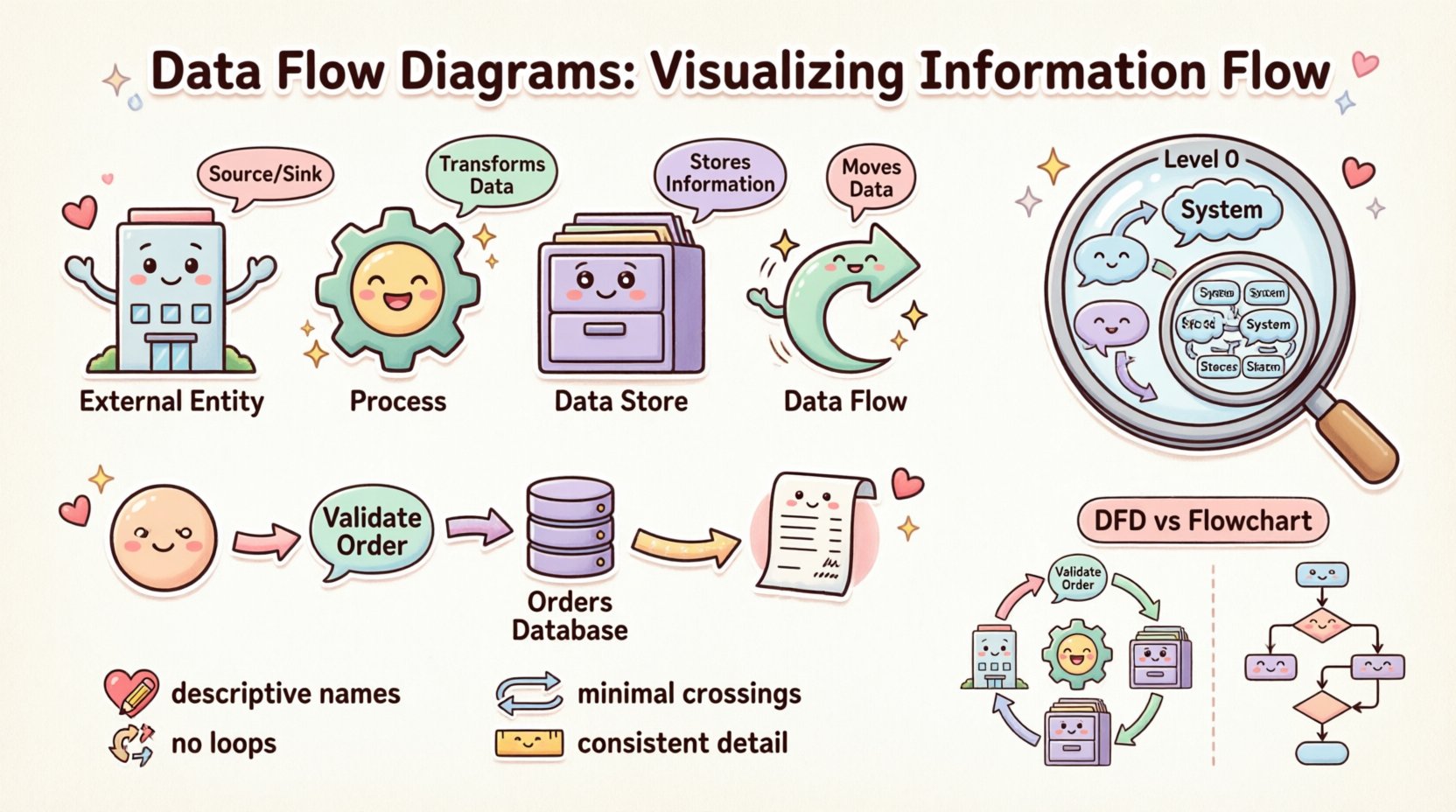
मूल उद्देश्य को समझना 🎯
डेटा फ्लो डायग्राम का प्राथमिक कार्य यह वर्णन करना है क्या एक सिस्टम करता है, बल्कि कैसेयह करता है। यह अंतर आवश्यकता संग्रह चरण के दौरान अत्यंत महत्वपूर्ण है। जबकि कोड स्निपेट या डेटाबेस स्कीमा कार्यान्वयन को दिखाता है, एक DFD व्यवहार को दिखाता है। यह सिस्टम की तर्क के लिए एक नक्शा के रूप में कार्य करता है।
एक बैंकिंग एप्लिकेशन को ध्यान में रखें। एक फ्लोचार्ट उपयोगकर्ता द्वारा क्लिक किए गए बटनों के क्रम को दिखा सकता है। हालांकि, एक DFD उपयोगकर्ता खाते से लेनदेन लेजर में जाने वाले पैसे पर ध्यान केंद्रित करता है। यह डेटा के परिवर्तन पर जोर देता है। यह अमूल्यता विश्लेषकों को तकनीकी नहीं जानने वाले स्टेकहोल्डर्स के साथ सिस्टम के तर्क के बारे में चर्चा करने में सक्षम बनाती है बिना भ्रम उत्पन्न किए।
दृश्यीकरण क्यों महत्वपूर्ण है
- संचार: यह व्यापार की आवश्यकताओं और तकनीकी कार्यान्वयन के बीच के अंतर को पार करता है।
- विश्लेषण: यह गायब डेटा बिंदु या अतिरिक्त प्रक्रियाओं को उजागर करता है।
- दस्तावेजीकरण: यह भविष्य के रखरखाव और अद्यतन के लिए एक संदर्भ के रूप में कार्य करता है।
- सत्यापन: यह सत्यापित करने में मदद करता है कि सभी डेटा इनपुट को ध्यान में रखा गया है और सही तरीके से प्रक्रिया किया गया है।
चार आवश्यक घटक 🧱
प्रत्येक डेटा फ्लो डायग्राम चार मूलभूत निर्माण ब्लॉकों से बनता है। सही डायग्राम बनाने के लिए इन तत्वों को समझना आवश्यक है। प्रत्येक घटक की जानकारी प्रवाह के पारिस्थितिकी तंत्र में एक विशिष्ट भूमिका है।
1. बाहरी एकाधिकार (स्रोत और निकास) 🏢
बाहरी एकाधिकार लोगों, संगठनों या अन्य प्रणालियों का प्रतिनिधित्व करते हैं जो विश्लेषण की जा रही प्रणाली की सीमा के बाहर स्थित हैं। वे प्रणाली में प्रवेश करने वाले डेटा के स्रोत या डेटा के बाहर निकलने वाले गंतव्य के रूप में कार्य करते हैं।
- शब्दावली: अक्सर स्रोत, निकास या अभिनेताओं के रूप में जाना जाता है।
- कार्य: वे किसी प्रक्रिया की शुरुआत करते हैं या अंतिम आउटपुट को प्राप्त करते हैं।
- उदाहरण: एक ग्राहक, एक बैंक, एक आपूर्तिकर्ता या एक बाहरी भुगतान गेटवे।
2. प्रक्रियाएँ (रूपांतरण) ⚙️
प्रक्रियाएं उन गतिविधियों का प्रतिनिधित्व करती हैं जो इनपुट डेटा को आउटपुट डेटा में बदलती हैं। वे आरेख के सक्रिय तत्व हैं। एक प्रक्रिया डेटा की स्थिति या रूप में परिवर्तन करती है।
- शब्दावली: फ़ंक्शन या रूपांतरण के रूप में भी जाना जाता है।
- कार्य: यह डेटा को लेता है, उसे संशोधित करता है और उसे बाहर भेजता है।
- उदाहरण: “कर की गणना करें,” “उपयोगकर्ता लॉगिन की पुष्टि करें,” या “बिल जनरेट करें।”
3. डेटा स्टोर (मेमोरी) 🗄️
डेटा स्टोर उन स्थानों का प्रतिनिधित्व करते हैं जहां जानकारी बाद में उपयोग के लिए संग्रहीत की जाती है। वे क्रिया शुरू नहीं करते हैं, लेकिन सिस्टम सीमा के भीतर डेटा को बनाए रखते हैं। इसमें एक भौतिक डेटाबेस, फ़ाइल या यहां तक कि पुराने संदर्भों में एक भौतिक फ़ाइलिंग कैबिनेट भी शामिल हो सकता है।
- शब्दावली: डेटाबेस, फ़ाइलें, रिपोजिटरी या कतारें।
- कार्य: डेटा का भंडारण और पुनर्प्राप्ति।
- उदाहरण: “ग्राहक डेटाबेस,” “आदेश इतिहास लॉग,” या “इन्वेंटरी फ़ाइल।”
4. डेटा प्रवाह (गति) 🔄
डेटा प्रवाह एकताओं, प्रक्रियाओं और स्टोर के बीच जानकारी के आवागमन को इंगित करते हैं। वे आरेख को एक साथ बांधने वाले कनेक्टर हैं। एक प्रवाह का नाम होना चाहिए जो स्थानांतरित हो रही जानकारी का वर्णन करे।
- शब्दावली: तीर, प्रवाह या रेखाएं।
- कार्य: बिंदु A से बिंदु B तक डेटा का परिवहन।
- दिशा: प्रवाह दिशात्मक होता है। एक प्रक्रिया से स्टोर की ओर इशारा करने वाला तीर डेटा लिखने को इंगित करता है; एक स्टोर से प्रक्रिया की ओर इशारा करने वाला तीर डेटा पढ़ने को इंगित करता है।
घटकों की तुलना
स्पष्टता सुनिश्चित करने के लिए, इन घटकों की तुलना एक साथ करना उपयोगी होता है। यह तालिका आरेख संरचना में प्रत्येक तत्व के अलग-अलग कार्यों को स्पष्ट करती है।
| घटक | भूमिका | नोटेशन आकृति | प्रश्न का उत्तर |
|---|---|---|---|
| बाहरी एकाधिकार | स्रोत/सिंक | आयत | प्रणाली के साथ कौन या क्या बातचीत करता है? |
| प्रक्रिया | रूपांतरक | वृत्त या गोल किनारे वाला आयत | डेटा पर क्या कार्य किया जा रहा है? |
| डेटा भंडार | भंडार | खुला आयत | डेटा कहाँ रखा जाता है? |
| डेटा प्रवाह | परिवहनकर्ता | तीर | डेटा कैसे आगे बढ़ता है? |
अब्स्ट्रैक्शन के स्तर 📉
एकल आरेख अक्सर पूरी प्रणाली की जटिलता को नहीं दर्शा पाता है। इस जटिलता को प्रबंधित करने के लिए DFD को विभिन्न विवरण स्तरों पर बनाया जाता है। इस तकनीक को विघटन के रूप में जाना जाता है। इससे विश्लेषकों को प्रणाली संरचना में जूम इन और जूम आउट करने की अनुमति मिलती है।
संदर्भ आरेख (स्तर 0) 🌍
संदर्भ आरेख सर्वोच्च स्तर का दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है। यह प्रणाली की सीमाओं को परिभाषित करता है और उन सभी बाहरी एकाधिकारों को पहचानता है जो इसके साथ बातचीत करते हैं। यह आरेख प्रश्न का उत्तर देता है: “प्रणाली का समग्र उद्देश्य क्या है?”
- परिधि: एक केंद्रीय प्रक्रिया।
- विवरण: न्यूनतम। केवल मुख्य इनपुट और आउटपुट दिखाए गए हैं।
- लक्ष्य: हितधारकों के लिए प्रणाली की सीमाओं को परिभाषित करना।
स्तर 1 आरेख (मुख्य प्रक्रियाएँ) 🔍
जब संदर्भ स्थापित हो जाता है, तो केंद्रीय प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित किया जाता है। इस स्तर 1 आरेख में प्रणाली को उसके प्राथमिक कार्यात्मक क्षेत्रों में विभाजित किया जाता है। यह दिखाता है कि डेटा इन मुख्य घटकों और बाहरी एकाधिकारों के बीच कैसे आगे बढ़ता है।
- परिधि: 3 से 7 तक मुख्य प्रक्रियाएँ।
- विवरण: उच्च स्तरीय आंतरिक बातचीत।
- लक्ष्य: प्रमुख कार्यात्मक मॉड्यूल्स को समझें।
स्तर 2 आरेख (विस्तृत प्रक्रियाएँ) 🔬
स्तर 2 पर आगे का विभाजन होता है। स्तर 1 से विशिष्ट प्रक्रियाओं को अधिक विस्तृत चरणों में बाँटा जाता है। यहीं तर्क विशिष्ट होता है। यह आमतौर पर विकास टीमों के लिए कोडिंग के लिए सटीक आवश्यकताओं को समझने के लिए उपयोग किया जाता है।
- परिसर: विस्तृत उप-प्रक्रियाएँ।
- विवरण: विशिष्ट डेटा परिवर्तन।
- लक्ष्य: कार्यान्वयन और तर्क डिजाइन का मार्गदर्शन करें।
संतुलन की अवधारणा ⚖️
DFD निर्माण में एक महत्वपूर्ण नियम संतुलन है। एक माता-पिता प्रक्रिया के इनपुट और आउटपुट को उसके बच्चे आरेख (अगला स्तर नीचे) के इनपुट और आउटपुट के मेल बनाना चाहिए। यदि स्तर 1 की प्रक्रिया “ऑर्डर डेटा” प्राप्त करती है, तो उस प्रक्रिया के स्तर 2 विभाजन में उस डेटा को सरलता से गायब नहीं किया जा सकता; इसे अभी भी इनपुट के रूप में “ऑर्डर डेटा” स्वीकार करना चाहिए।
संतुलन नियमों के उल्लंघन से सिस्टम मॉडल में असंगतता उत्पन्न होती है। यह इंगित करता है कि डेटा वायु में बनाया जा रहा है या बिना किसी निशान के गायब हो रहा है। संतुलन बनाए रखने से यह सुनिश्चित होता है कि सिस्टम की तार्किक अखंडता सभी स्तरों के अबस्ट्रैक्शन में संरक्षित रहती है।
डेटा फ्लो आरेख बनाम फ्लोचार्ट 🆚
डेटा फ्लो आरेखों को फ्लोचार्ट्स से भ्रमित करना एक सामान्य गलती है। जबकि इनकी दृश्य समानता है, उनका उद्देश्य और संरचना में महत्वपूर्ण अंतर है।
- फ्लोचार्ट्स: ध्यान केंद्रित करें नियंत्रण प्रवाह। वे चरणों, निर्णयों और लूप्स के क्रम को दिखाते हैं। वे “अगला क्या होता है?” का उत्तर देते हैं। वे आमतौर पर किसी विशिष्ट एल्गोरिदम या उपयोगकर्ता इंटरफेस इंटरैक्शन के तर्क का वर्णन करने के लिए उपयोग किए जाते हैं।
- डेटा फ्लो आरेख: ध्यान केंद्रित करें डेटा प्रवाह। वे सूचना के आंदोलन को दिखाते हैं। वे “डेटा कहाँ जाता है?” का उत्तर देते हैं। वे आमतौर पर लूप्स या निर्णय बिंदुओं को स्पष्ट रूप से नहीं दिखाते; वे परिवर्तनों को दिखाते हैं।
गलत आरेख प्रकार का उपयोग विकास टीम को भ्रमित कर सकता है। यदि आपको त्रुटि संभाल के साथ उपयोगकर्ता लॉगिन अनुक्रम का दस्तावेजीकरण करना है, तो फ्लोचार्ट बेहतर है। यदि आपको उपयोगकर्ता डेटा के फॉर्म से डेटाबेस तक जाने के तरीके का दस्तावेजीकरण करना है, तो DFD उपयुक्त है।
स्पष्टता के लिए सर्वोत्तम प्रथाएँ ✨
DFD बनाना अनुशासन का एक अभ्यास है। स्थापित प्रथाओं का पालन करने से यह सुनिश्चित होता है कि आरेख समय के साथ पठनीय और उपयोगी बना रहे।
1. नामकरण प्रथाएँ 📝
लेबल वर्णनात्मक होने चाहिए। “प्रक्रिया 1” या “डेटा A” जैसे अस्पष्ट शब्दों से बचें। बजाय इसके, प्रक्रियाओं के लिए क्रिया-संज्ञा संयोजन का उपयोग करें, जैसे “पासवर्ड की पुष्टि करें।” डेटा प्रवाह के लिए, सामग्री का वर्णन करने वाली संज्ञाओं का उपयोग करें, जैसे “शिपिंग पता” या “भुगतान रसीद।” संगत नामकरण उपयोगकर्ताओं को अनुमान लगाए बिना आरेख में नेविगेट करने में मदद करता है।
2. डेटा प्रवाह लूप्स से बचें 🚫
एक डेटा प्रवाह को तुरंत समान प्रक्रिया में वापस लौटने की अनुमति नहीं होनी चाहिए। जब डेटा अन्य घटकों से गुजरने के बाद प्रक्रिया में वापस आ सकता है, लेकिन सीधे स्वयं के लूप के लिए अक्सर तर्कसंगत त्रुटि या प्रक्रिया सीमा की गलत समझ का संकेत होता है। एक प्रक्रिया को इनपुट लेना, उसे परिवर्तित करना और आउटपुट देना चाहिए। यदि यह सीधे अपने आप में आउटपुट देता है, तो इसका अर्थ है अनंत प्रोसेसिंग।
3. प्रतिच्छेदनों को कम करना 🧵
एक भारी डायग्राम बेकार का डायग्राम है। घटकों को इस तरह व्यवस्थित करें कि डेटा प्रवाह प्राकृतिक रूप से हो, आमतौर पर बाएं से दाएं या ऊपर से नीचे की ओर। तीर के प्रतिच्छेदनों की संख्या को कम करें। यदि रेखाएं प्रतिच्छेदन करती हैं, तो विशिष्ट डेटा के मार्ग को ट्रैक करना मुश्किल हो जाता है। दृश्य प्रवाह बनाए रखने के लिए वक्र या तोड़ का उपयोग करें।
4. सुसंगत विविधता 📏
एक ही डायग्राम में विवरण का स्तर सुसंगत होना चाहिए। उच्च स्तर की प्रक्रियाओं को निम्न स्तर की उप-प्रक्रियाओं के साथ मिलाएं नहीं। यदि एक प्रक्रिया तीन चरणों में विभाजित है, तो उसी दृश्य में अन्य सभी प्रमुख प्रक्रियाओं को भी समान विभाजन स्तर पर होना चाहिए।
आम त्रुटियां और समाधान ⚠️
यहां तक कि अनुभवी विश्लेषक भी डायग्राम बनाते समय त्रुटियों का सामना करते हैं। इन आम त्रुटियों को पहचानने से समीक्षा प्रक्रिया में समय बचता है।
काला छेद
एक काला छेद तब होता है जब एक प्रक्रिया के इनपुट होते हैं लेकिन आउटपुट नहीं होते हैं। डेटा प्रक्रिया में प्रवेश करता है और गायब हो जाता है। यह आमतौर पर एक गायब डेटा स्टोर या बाहरी एजेंसी के लिए गायब प्रवाह का संकेत होता है। जो प्रक्रिया डेटा स्वीकार करती है, उसे कोई परिणाम उत्पन्न करना चाहिए।
चमत्कारी प्रक्रिया
यह काले छेद के विपरीत है। एक चमत्कारी प्रक्रिया के आउटपुट होते हैं लेकिन इनपुट नहीं होते हैं। यह कोई भी जानकारी नहीं खपते हुए डेटा उत्पन्न करती है। यह भौतिक रूप से असंभव है। प्रत्येक आउटपुट किसी इनपुट डेटा से उत्पन्न होना चाहिए।
भूत डेटा
भूत डेटा का तात्पर्य उन डेटा प्रवाहों से होता है जो अनुमानित होते हैं लेकिन नहीं बनाए जाते हैं। यदि एक प्रक्रिया को कार्य करने के लिए ग्राहक आईडी की आवश्यकता होती है, लेकिन कोई तीर प्रक्रिया में आईडी नहीं लाता है, तो तर्क अपूर्ण है। प्रत्येक डेटा आवश्यकता को स्पष्ट रूप से जोड़ा जाना चाहिए।
बाहरी एजेंसी की भ्रम
विश्लेषक कभी-कभी आंतरिक घटकों को बाहरी एजेंसियों के रूप में गलत समझते हैं। यदि एक घटक प्रणाली सीमा का हिस्सा है, तो वह एक प्रक्रिया या स्टोर है। यदि यह प्रणाली के बाहर है, तो वह एक एजेंसी है। सीमा रेखा खींचने से इस अंतर को स्पष्ट करने में मदद मिलती है।
विकास चक्र में एकीकरण 🛠️
डेटा प्रवाह आरेख स्थिर वस्तुएं नहीं हैं; वे परियोजना के साथ विकसित होने वाले जीवित दस्तावेज हैं। वे सॉफ्टवेयर विकास चक्र के विभिन्न चरणों में भूमिका निभाते हैं।
- आवश्यकताओं का एकत्रीकरण:DFD डेटा के व्यवसाय में प्रवेश और बाहर जाने के तरीके को दृश्याकरण करके उपयोगकर्ता की आवश्यकताओं को ध्यान में रखने में मदद करते हैं। वे यह सत्यापित करते हैं कि सभी आवश्यक डेटा बिंदु पहचाने गए हैं।
- प्रणाली डिजाइन: वे डेटाबेस डिजाइन के लिए मार्गदर्शन करते हैं। DFD में डेटा स्टोर डेटाबेस स्कीमा में तालिकाओं या संग्रहों में सीधे बदल जाते हैं।
- परीक्षण: परीक्षण केस डेटा प्रवाहों से निकाले जा सकते हैं। यदि डायग्राम में कोई प्रवाह मौजूद है, तो डेटा अखंडता सुनिश्चित करने के लिए उसका परीक्षण किया जाना चाहिए।
- रखरखाव: जब परिवर्तन होते हैं, तो DFD को अद्यतन किया जाता है। यह एक उच्च स्तर का अवलोकन प्रदान करता है जो नए टीम सदस्यों को प्रणाली को तेजी से समझने में मदद करता है।
दृश्याकरण की मनोविज्ञान 🧠
हम टेक्स्ट के बजाय आरेखों पर क्यों भरोसा करते हैं? मानव मस्तिष्क टेक्स्ट की तुलना में दृश्य सूचना को काफी तेजी से प्रक्रिया करता है। DFD जटिल तर्क को व्यवस्थित करने के लिए स्थानिक तर्क का उपयोग करता है। यह दर्शक को वे संबंध देखने में सक्षम बनाता है जो एक पैराग्राफ टेक्स्ट में खो सकते हैं।
जब स्टेकहोल्डर आरेख देखते हैं, तो वे तुरंत गायब संबंधों को पहचान सकते हैं। तीरों में एक अंतर एक आवश्यकता दस्तावेज में अंतर की तुलना में अधिक दिखाई देता है। इस दृश्य त्वरितता से गलत व्याख्या के जोखिम को कम किया जाता है। यह टीम के बीच एक साझा मानसिक मॉडल बनाता है।
डेटा दृश्याकरण का भविष्य 🔮
जैसे-जैसे प्रणालियां अधिक वितरित और क्लाउड-मूल बनती हैं, DFD की भूमिका संबंधित बनी रहती है। आधुनिक प्रणालियां माइक्रोसर्विसेज, APIs और तीसरे पक्ष के एकीकरण को शामिल करती हैं। ये मूल रूप से बाहरी एजेंसियां और डेटा प्रवाह हैं।
स्वचालित दस्तावेज़ीकरण उपकरण कोड भंडारों से DFDs उत्पन्न करने लगे हैं। यद्यपि इन उपकरणों का सुसंगतता बनाए रखने में उपयोगी होना है, फिर भी प्रवाह की तार्किक सहीता सुनिश्चित करने के लिए मैन्युअल समीक्षा आवश्यक है। विभाजन और संतुलन के मूल सिद्धांत तकनीकी स्टैक के बावजूद स्थिर रहते हैं।
रणनीतिक मूल्य का सारांश 💡
डेटा प्रवाह आरेख सूचना प्रणालियों को समझने के लिए एक संरचित दृष्टिकोण प्रदान करते हैं। वे जटिलता को प्रबंधन योग्य घटकों में तोड़ते हैं। वे तकनीकी और गैर-तकनीकी टीमों के बीच संचार को सुगम बनाते हैं। वे डेटाबेस डिज़ाइन और प्रक्रिया अनुकूलन के लिए आधार के रूप में कार्य करते हैं।
संतुलन, स्पष्ट नामकरण और उचित अमूर्तता के सिद्धांतों का पालन करके विश्लेषक ऐसे आरेख बना सकते हैं जो समय की परीक्षा में खड़े रहें। नए एप्लिकेशन के निर्माण या मौजूदा एप्लिकेशन के ऑडिट के दौरान भी, DFD जानकारी के प्रवाह को दृश्यीकृत करने के लिए एक मूल उपकरण बना रहता है। यह अमूर्त तर्क को एक भौतिक मानचित्र में बदल देता है जो विकास को मार्गदर्शन करता है और व्यापार लक्ष्यों के साथ संरेखण सुनिश्चित करता है।
जब आप अगली बार किसी प्रणाली विश्लेषण कार्य को अपनाएंगे, तो याद रखें कि स्पष्टता लक्ष्य है। अपने डेटा के यात्रा को मानचित्रित करने के लिए DFD का उपयोग करें। सुनिश्चित करें कि प्रत्येक जानकारी का स्रोत, गंतव्य और मार्ग हो। इस अनुशासन के परिणामस्वरूप अधिक विश्वसनीय प्रणालियाँ और कम गलतफहमियाँ होंगी।