











डेटा फ्लो डायग्राम्स (DFDs) प्रणाली विश्लेषण और डिज़ाइन के लिए एक महत्वपूर्ण नक्शा के रूप में कार्य करते हैं। वे एक प्रणाली के माध्यम से जानकारी के आवागमन का दृश्य प्रतिनिधित्व प्रदान करते हैं, नियंत्रण तर्क के बजाय डेटा के प्रवाह पर ध्यान केंद्रित करते हैं। चाहे आप एक नए एंटरप्राइज रिसोर्स प्लानिंग प्रणाली का डिज़ाइन कर रहे हों या मौजूदा लेगेसी एप्लिकेशन का विश्लेषण कर रहे हों, डेटा के आवागमन को समझना स्पष्टता और दक्षता के लिए आवश्यक है। यह मार्गदर्शिका विशिष्ट वाणिज्यिक उपकरणों पर निर्भर न करते हुए प्रभावी DFDs बनाने के यांत्रिकी, नियम और उत्तम प्रथाओं का अध्ययन करती है।
डेटा फ्लो डायग्राम क्या है? 🤔
एक डेटा फ्लो डायग्राम एक संरचित विश्लेषण तकनीक है जिसका उपयोग प्रणाली के भीतर डेटा के प्रवाह को दृश्य रूप से दिखाने के लिए किया जाता है। यह एक जटिल प्रणाली को छोटे, प्रबंधनीय भागों में बांटता है, जिसमें डेटा के इनपुट, प्रोसेसिंग, स्टोरेज और आउटपुट कैसे होता है, इसका प्रदर्शन किया जाता है। अन्य आरेखों के विपरीत जो समय क्रम या निर्णय तर्क पर ध्यान केंद्रित कर सकते हैं, DFDs केवल डेटा एकांकों और उनके रूपांतरण का सख्ती से अनुसरण करते हैं।
इन आरेखों का सॉफ्टवेयर विकास चक्र में कई महत्वपूर्ण उद्देश्य होते हैं:
- संचार:वे तकनीकी टीमों और हितधारकों के बीच के अंतर को पूरा करने में मदद करते हैं दृश्य भाषा प्रदान करके।
- अंतर विश्लेषण:वे आवश्यकता एकत्र करने के चरण के दौरान गायब प्रक्रियाओं या डेटा मार्गों की पहचान करने में मदद करते हैं।
- दस्तावेज़ीकरण:वे भविष्य के रखरखाव और समस्या निवारण के लिए एक संदर्भ के रूप में कार्य करते हैं।
- अनुकूलन:वे बॉटलनेक्स को उजागर करते हैं जहां डेटा जमा होता है या अकुशलता से आगे बढ़ता है।
DFDs पदानुक्रमिक होते हैं। एक जटिल प्रणाली को एक ही दृश्य में दिखाया जाना दुर्लभ है। इसके बजाय, इसे विभिन्न विवरण स्तरों में विभाजित किया जाता है, जिससे विश्लेषकों को आवश्यकता के अनुसार विशिष्ट क्षेत्रों पर जूम करने की अनुमति मिलती है।
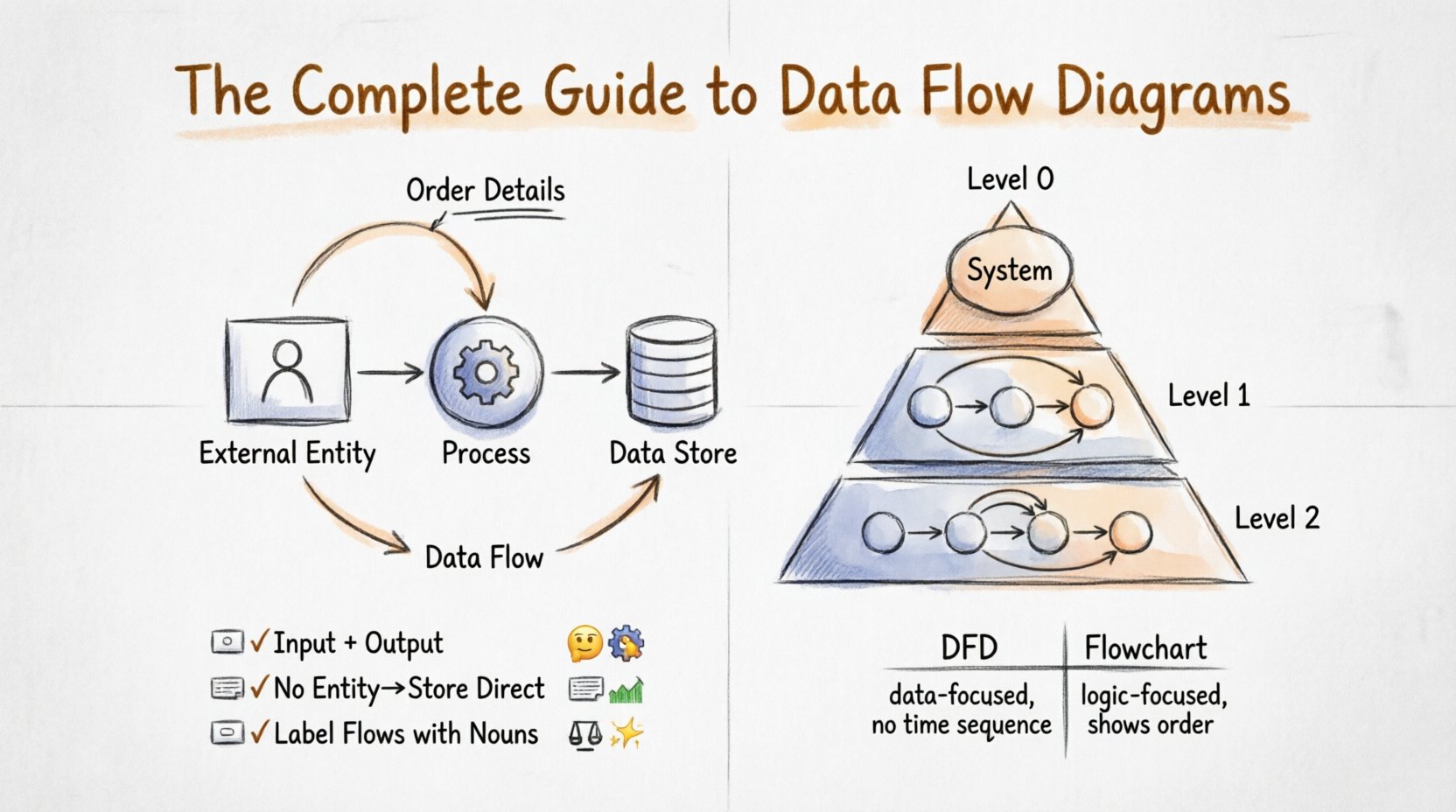
चार मूल घटक 🧩
एक वैध डेटा फ्लो डायग्राम बनाने के लिए, आपको चार मूल निर्माण ब्लॉक्स को समझना होगा। DFD में प्रत्येक तत्व इन श्रेणियों में से एक में आता है।
| घटक | प्रतीक विवरण | कार्य | उदाहरण |
|---|---|---|---|
| बाहरी एकांक | आयत या वर्ग | प्रणाली सीमा के बाहर डेटा का स्रोत या गंतव्य। | ग्राहक, प्रशासक, तीसरे पक्ष का API |
| प्रक्रिया | वृत्त या गोल कोने वाला आयत | इनपुट डेटा को आउटपुट डेटा में बदलता है। | कर गणना, उपयोगकर्ता की पुष्टि, रिपोर्ट उत्पन्न करना |
| डेटा भंडार | खुला आयत या समानांतर रेखाएं | जहां डेटा बाद में पुनर्प्राप्ति के लिए सहेजा जाता है। | डेटाबेस, फाइल सिस्टम, ईमेल इनबॉक्स |
| डेटा प्रवाह | तीर | वह मार्ग जिसके द्वारा डेटा घटकों के बीच आता-जाता है। | आदेश विवरण, लॉगिन क्रेडेंशियल, इन्वॉइस |
1. बाहरी एकाधिकार 🧑💼
समाप्तिकारक के रूप में भी जाने जाते हैं, ये लोगों, संगठनों या अन्य प्रणालियों का प्रतिनिधित्व करते हैं जो आपकी प्रणाली के साथ बातचीत करते हैं लेकिन इसके नियंत्रण के बाहर होते हैं। वे डेटा प्रवाह के प्रारंभिक या अंतिम बिंदु हैं। यह निर्धारित करने के लिए महत्वपूर्ण है कि बाहरी एकाधिकार और आंतरिक प्रक्रिया के बीच क्या अंतर है, इसलिए प्रणाली की सीमा को स्पष्ट रूप से परिभाषित करना आवश्यक है।
2. प्रक्रियाएं ⚙️
प्रक्रियाएं वे सक्रिय तत्व हैं जहां काम होता है। वे डेटा लेती हैं, उसे बदलती हैं और उसे बाहर भेजती हैं। एक प्रक्रिया के हमेशा कम से कम एक इनपुट और एक आउटपुट होना चाहिए। यदि कोई प्रक्रिया इनपुट है लेकिन आउटपुट नहीं है, तो यह एक “काला छेद” है। यदि इनपुट नहीं है लेकिन आउटपुट है, तो यह एक “चमत्कार” है। दोनों तर्क की त्रुटियां हैं।
3. डेटा स्टोर 🗃️
डेटा स्टोर प्रतिक्रियाशील भंडार हैं जहां जानकारी रुकती है। वे डेटा को प्रक्रिया नहीं करते; वे उसे रखते हैं। यह एक भौतिक डेटाबेस, एक कागज का फाइल बॉक्स या क्लाउड बैग हो सकता है। DFD में, डेटा एक स्टोर में प्रवेश करता है ताकि सहेजा जा सके और पुनर्प्राप्ति के लिए बाहर निकलता है।
4. डेटा प्रवाह ➡️
डेटा प्रवाह संयोजक हैं। वे जानकारी के आवागमन का प्रतिनिधित्व करते हैं। प्रत्येक प्रवाह को एक संज्ञा वाक्यांश से लेबल किया जाना चाहिए जो बताता है कि क्या गतिशील है (उदाहरण के लिए, “भुगतान जानकारी”), क्रिया शब्द (उदाहरण के लिए, “भुगतान भेजें”) के बजाय। प्रवाह को प्रणाली की सीमा को पार करने के लिए प्रक्रिया या स्टोर के बीच होना चाहिए।
DFD स्तरों की व्याख्या 📈
DFD को वर्गीकृत ढंग से बनाया जाता है। इससे आप प्रणाली को संकल्पनात्मक स्तरों में विभाजित करके जटिलता को प्रबंधित कर सकते हैं।
स्तर 0: संदर्भ आरेख
संदर्भ आरेख सबसे ऊंचे स्तर का दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया बबल के रूप में दिखाता है। यह सभी बाहरी एकाधिकारों और प्रणाली में प्रवेश और निकास होने वाले प्रमुख डेटा प्रवाहों को पहचानता है। यह आरेख प्रश्न का उत्तर देता है: “प्रणाली क्या करती है?” यह प्रणाली की सीमा को स्पष्ट रूप से स्थापित करता है।
स्तर 1: प्रमुख प्रक्रियाएं
स्तर 1 संदर्भ आरेख में एकल प्रक्रिया को उसके प्रमुख उप-प्रक्रियाओं में विस्तारित करता है। यह स्तर प्रणाली के मुख्य कार्यात्मक क्षेत्रों को उजागर करता है। उदाहरण के लिए, एक “बिक्री प्रणाली” को “आदेश प्रसंस्करण”, “इन्वेंट्री प्रबंधन” और “बिलिंग” में विभाजित किया जा सकता है। डेटा स्टोर को यहां भी पेश किया जाता है।
स्तर 2: विस्तृत प्रक्रियाएं
स्तर 2 स्तर 1 से विशिष्ट प्रक्रियाओं में गहराई से नजर डालता है। यहीं आप बारीक चरणों को नक्शा बनाते हैं। उदाहरण के लिए, स्तर 1 की “बिलिंग” प्रक्रिया को “शुल्क की गणना”, “छूट लागू करें” और “इन्वॉइस जनरेट करें” में विभाजित किया जा सकता है। यह स्तर अक्सर सबसे विस्तृत होता है और कार्यान्वयन निर्देशों के लिए उपयोग किया जाता है।
नोटेशन शैलियां 📐
DFD बनाने के लिए दो मुख्य नोटेशन उपयोग किए जाते हैं। दोनों एक ही तार्किक जानकारी को संदर्भित करते हैं लेकिन अलग-अलग आकृतियों का उपयोग करते हैं।
- योरडॉन और डीमार्को नोटेशन: प्रक्रियाओं के लिए वृत्त और डेटा स्टोर के लिए खुले छोर वाले आयत का उपयोग करता है। इस शैली को आमतौर पर पुरानी विधियों से जोड़ा जाता है लेकिन यह अभी भी व्यापक रूप से मान्य है।
- गेन और सर्सन नोटेशन: प्रक्रियाओं के लिए गोल किनारे वाले आयत और डेटा स्टोर के लिए समानांतर क्षैतिज रेखाओं का उपयोग करता है। इस शैली को आधुनिक प्रणाली डिजाइन में उसकी स्पष्टता के कारण अक्सर पसंद किया जाता है।
आरेख बनाते समय सुसंगतता महत्वपूर्ण है। एक नोटेशन चुनें और पूरे दस्तावेजीकरण सेट में उसी का पालन करें ताकि हितधारकों में भ्रम न हो।
आवश्यक नियम और सीमाएं ⚖️
अपने डेटा फ्लो डायग्राम की अखंडता सुनिश्चित करने के लिए, आपको विशिष्ट नियमों का पालन करना होगा। इन नियमों के उल्लंघन से डायग्राम तार्किक रूप से अमान्य हो जाता है।
- डेटा संतुलन: प्रत्येक प्रक्रिया में कम से कम एक इनपुट फ्लो और एक आउटपुट फ्लो होना चाहिए। डेटा को किसी भी चीज से बनाया या बिना निशान के नष्ट नहीं किया जा सकता है।
- कोई सीधा एंटिटी-से-स्टोर फ्लो नहीं: डेटा किसी बाहरी एंटिटी से सीधे डेटा स्टोर में नहीं बह सकता है। इसे पहले किसी प्रक्रिया से गुजरना होगा। इससे यह सुनिश्चित होता है कि सभी डेटा को सही या परिवर्तित करने के बाद ही सहेजा जाए।
- कोई सीधा स्टोर-से-स्टोर फ्लो नहीं: डेटा एक स्टोर से दूसरे स्टोर में सीधे नहीं जा सकता है। डेटा की अखंडता सुनिश्चित करने के लिए एक प्रक्रिया को इस स्थानांतरण के माध्यम के रूप में काम करना चाहिए।
- संगत नामकरण: डेटा फ्लो के अद्वितीय, वर्णनात्मक नाम होने चाहिए। यदि एक ही डेटा कई स्थानों पर जाता है, तो उसे एक ही नाम लेना चाहिए ताकि ट्रेसेबिलिटी बनी रहे।
- विघटन: जब किसी प्रक्रिया को निचले स्तरों में तोड़ा जाता है, तो इनपुट और आउटपुट को मूल प्रक्रिया के साथ मेल खाना चाहिए। इसे ‘संतुलन’ कहा जाता है।
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी विश्लेषक भी डेटा फ्लो के मॉडलिंग में गलतियां कर सकते हैं। सामान्य त्रुटियों के बारे में जागरूक रहने से डायग्राम की गुणवत्ता बनी रहती है।
1. काले छेद
एक काला छेद वह प्रक्रिया है जो डेटा प्राप्त करती है लेकिन कोई आउटपुट नहीं उत्पन्न करती है। इसका अर्थ है कि डेटा बिना किसी परिणाम के सिस्टम में गायब हो रहा है। एक वैध DFD में ऐसा असंभव है। प्रक्रिया में प्रवेश करने वाले प्रत्येक डेटा के किसी परिवर्तन या आउटपुट के रूप में परिणाम होना चाहिए।
2. ग्रे होल्स
एक ग्रे होल वह प्रक्रिया है जहां इनपुट डेटा आउटपुट डेटा के साथ तार्किक रूप से मेल नहीं खाता है। उदाहरण के लिए, यदि इनपुट ‘ग्राहक का नाम’ है लेकिन आउटपुट ‘शिपिंग पता’ है, तो एक अनुपस्थित रूपांतरण प्रक्रिया है। आउटपुट को बनाने के लिए आवश्यक डेटा को ध्यान में रखना चाहिए।
3. बहुत अधिक फ्लो
एक प्रक्रिया को बहुत अधिक डेटा फ्लो के साथ ओवरलोड करने से डायग्राम पढ़ने योग्य नहीं रहता है। यदि किसी प्रक्रिया में सात से अधिक इनपुट या आउटपुट हैं, तो यह संभवतः बहुत काम कर रही है और इसे छोटी उप-प्रक्रियाओं में विभाजित करना चाहिए।
4. नियंत्रण प्रवाह की भ्रम
DFD में नियंत्रण प्रवाह, समय क्रम या लूप नहीं दिखाए जाते हैं। ‘यहां से शुरू करें’ या ‘फिर इसे करें’ का संकेत देने के लिए तीर का उपयोग न करें। सभी तीर डेटा गति का प्रतिनिधित्व करते हैं। यदि आप तर्क या समय को दिखाना चाहते हैं, तो बजाय इसके एक फ्लोचार्ट का उपयोग करें।
DFD बनाम फ्लोचार्ट 🔄
डेटा फ्लो डायग्राम और फ्लोचार्ट को गलती से एक दूसरे से भ्रमित करना आम बात है। यद्यपि दोनों तीर और आकृतियों का उपयोग करते हैं, लेकिन उनके उद्देश्य अलग-अलग होते हैं।
| विशेषता | डेटा फ्लो डायग्राम (DFD) | फ्लोचार्ट |
|---|---|---|
| फोकस | डेटा गति और संग्रहण। | नियंत्रण प्रवाह और निर्णय तर्क। |
| प्रक्रियाएं | डेटा को परिवर्तित करें। | चरणों या निर्णयों को क्रियान्वित करें। |
| समय | क्रम को नहीं दिखाता है। | संचालन के क्रम को दिखाता है। |
| निर्णय बिंदु | उपयोग नहीं किया जाता है। | भारी मात्रा में उपयोग किया जाता है (हीरे के आकार के)। |
| सर्वोत्तम उपयोग | प्रणाली विश्लेषण और आवश्यकताएँ। | एल्गोरिदम डिज़ाइन और प्रोग्रामिंग तर्क। |
चरण-दर-चरण निर्माण प्रक्रिया 🛠️
DFD बनाने के लिए एक संरचित दृष्टिकोण की आवश्यकता होती है। एक बलवान मॉडल बनाने के लिए इन चरणों का पालन करें।
- प्रणाली सीमा की पहचान करें: यह परिभाषित करें कि प्रणाली के अंदर क्या है और बाहर क्या है। इससे आपके बाहरी एकाधिकार निर्धारित होते हैं।
- संदर्भ आरेख बनाएं: प्रणाली को केंद्र में एक प्रक्रिया के रूप में रखें। सभी बाहरी एकाधिकारों की ओर तीर खींचें जो उच्च स्तर की डेटा गतिशीलता दिखाते हैं।
- मुख्य प्रक्रियाओं की पहचान करें: केंद्रीय प्रक्रिया को लेवल 1 प्रक्रियाओं में विभाजित करें। ये प्रणाली के मुख्य कार्य हैं।
- डेटा स्टोर जोड़ें: यह निर्धारित करें कि प्रक्रियाओं के बीच डेटा कहाँ संग्रहीत करने की आवश्यकता है। उन्हें संबंधित प्रक्रियाओं से जोड़ें।
- डेटा प्रवाह को बेहतर बनाएं: प्रक्रियाओं, स्टोर और एकाधिकारों के बीच तीर खींचें। सुनिश्चित करें कि सभी लेबल स्पष्ट संज्ञाएँ हैं।
- संतुलन की जाँच करें: सुनिश्चित करें कि लेवल 1 प्रक्रियाओं के इनपुट और आउटपुट संदर्भ आरेख के अनुरूप हैं।
- आगे विभाजित करें: यदि लेवल 1 प्रक्रिया बहुत जटिल है, तो उसके आंतरिक कार्यों को विस्तार से दिखाने के लिए लेवल 2 आरेख बनाएं।
प्रणाली संरचना के लिए लाभ 🏗️
DFD के कार्यान्वयन से प्रणाली संरचना और विकास टीमों को भावी लाभ मिलते हैं।
- स्पष्टता: दृश्य मॉडल आवश्यकताओं में अस्पष्टता को कम करते हैं। हितधारक देख सकते हैं कि वे कौन से डेटा को भेज रहे हैं और कौन से डेटा को प्राप्त कर रहे हैं।
- स्केलेबिलिटी: हायरार्किकल आरेख वास्तुकारों को विस्तार के बिना टीम को विवरण से भारी नहीं करने देते हैं।
- एकीकरण: DFDs को अलग-अलग उपप्रणालियों के बीच बातचीत को पहचानने में आसानी होती है, जो माइक्रोसर्विसेज या वितरित प्रणालियों के लिए जरूरी है।
- सुरक्षा: डेटा प्रवाह के नक्शे बनाकर सुरक्षा टीमें यह पहचान सकती हैं कि संवेदनशील डेटा कहाँ जाता है और सही बिंदुओं पर एन्क्रिप्शन या पहुँच नियंत्रण लागू कर सकती हैं।
रखरखाव और अनुकूलन 🔁
एक DFD एकमात्र उत्पाद नहीं है। प्रणालियाँ विकसित होती हैं, और डेटा की आवश्यकताएँ बदलती हैं। आरेख को अद्यतन रखना निर्णायक है।
- संस्करण नियंत्रण: आरेखों को कोड की तरह लें। समय के साथ बदलावों को ट्रैक करने के लिए संस्करण प्रबंधन का उपयोग करें।
- परिवर्तन प्रबंधन: जब कोई नया आवश्यकता जोड़ी जाती है, तो तुरंत DFD को अपडेट करें ताकि नए डेटा पथ दिखाई दें।
- समीक्षा चक्र: हितधारकों के साथ नियमित समीक्षा योजना बनाएं ताकि आरेख अभी भी व्यापार की वास्तविकता के अनुरूप हो।
- सेवानिवृत्ति: जब कोई प्रक्रिया हटाई जाती है, तो सुनिश्चित करें कि सभी संबंधित डेटा प्रवाह भी हटा दिए जाएँ ताकि अनाथ डेटा संदर्भों को रोका जा सके।
स्पष्टता के लिए सर्वोत्तम प्रथाएँ ✨
अपने डेटा प्रवाह आरेखों की प्रभावशीलता सुनिश्चित करने के लिए, इन दिशानिर्देशों का पालन करें।
- वर्णनात्मक लेबल का उपयोग करें: प्रक्रियाओं के नाम एक क्रिया और एक संज्ञा के साथ रखें (उदाहरण के लिए, “ऑर्डर प्रोसेस करें”)। डेटा प्रवाहों के नाम संज्ञा के साथ रखें (उदाहरण के लिए, “ऑर्डर विवरण”)।
- लाइनों के प्रतिच्छेदन से बचें: तीर के प्रतिच्छेदन को कम करने के लिए तत्वों को व्यवस्थित करें। यदि वे प्रतिच्छेदन करते हैं, तो “जंप” प्रतीक का उपयोग करें या लेआउट को फिर से व्यवस्थित करें।
- सरल रखें: प्रति प्रक्रिया अधिकतम सात आइटम का लक्ष्य रखें। यदि आप इससे अधिक हैं, तो प्रक्रिया को विभाजित करें।
- संगत अभिमुखीकरण: बाहरी तत्वों को बाएं और दाएं रखें, और डेटा भंडार को नीचे या ऊपर रखें ताकि संगतता बनी रहे।
- उपयोगकर्ताओं के साथ समीक्षा करें: आरेख को प्रणाली के वास्तविक उपयोगकर्ताओं को दिखाएं। वे अक्सर तकनीकी विश्लेषकों द्वारा नजरअंदाज किए गए गायब डेटा प्रवाहों को पहचान सकते हैं।
अंतिम विचार 🔍
डेटा फ्लो डायग्राम संरचित विश्लेषण का एक मूल बिंदु बना हुआ है। वे तकनीकी कार्यान्वयन विवरणों में फंसे बिना सिस्टम की आवश्यकताओं के बारे में चर्चा करने का एक तटस्थ तरीका प्रदान करते हैं। डेटा के आवागमन पर ध्यान केंद्रित करके टीमें डिजाइन चरण के शुरुआती बिंदु पर अक्षमताओं और तार्किक अंतरालों की पहचान कर सकती हैं।
याद रखें कि एक डायग्राम सोचने का एक उपकरण है, केवल दस्तावेजीकरण के लिए नहीं। प्रवाहों को बनाने की क्रिया अक्सर ऐसी समस्याओं को उजागर करती है जो पहले टेक्स्ट विवरणों में छिपी रहती थीं। चाहे आप एजाइल परिदृश्य में काम कर रहे हों या पारंपरिक वॉटरफॉल मॉडल में, डेटा प्रवाहों के नक्शा बनाने की अनुशासन एक बलवान और बनाए रखने योग्य सिस्टम वास्तुकला सुनिश्चित करता है।
नियमों का पालन करने, सामान्य त्रुटियों से बचने और सिस्टम के विकास के साथ डायग्रामों को बनाए रखने से आप सुनिश्चित करते हैं कि आपका दस्तावेजीकरण सॉफ्टवेयर के जीवनचक्र के दौरान एक विश्वसनीय सत्य स्रोत बना रहे।