











Les schémas de bases de données sont des artefacts vivants. Ils évoluent parallèlement à la logique métier qu’ils soutiennent. Au fil du temps, au fur et à mesure que les exigences changent et que de nouvelles fonctionnalités sont introduites, la structure de données sous-jacente devient souvent complexe. Cette complexité se manifeste visuellement sous la forme d’un diagramme d’entités relationnelles (ERD) surchargé. Un ERD surdimensionné peut entraîner une dégradation des performances, des cauchemars de maintenance et un risque accru de problèmes d’intégrité des données.
Le restructurage de ces diagrammes n’est pas simplement une opération esthétique. Il s’agit d’une intervention structurelle qui exige une grande précision. L’objectif principal est de simplifier le schéma, d’améliorer sa lisibilité et d’optimiser les performances des requêtes, tout en garantissant qu’aucune donnée n’est perdue ou corrompue au cours de la transition. Ce guide propose une approche structurée pour gérer ce processus.
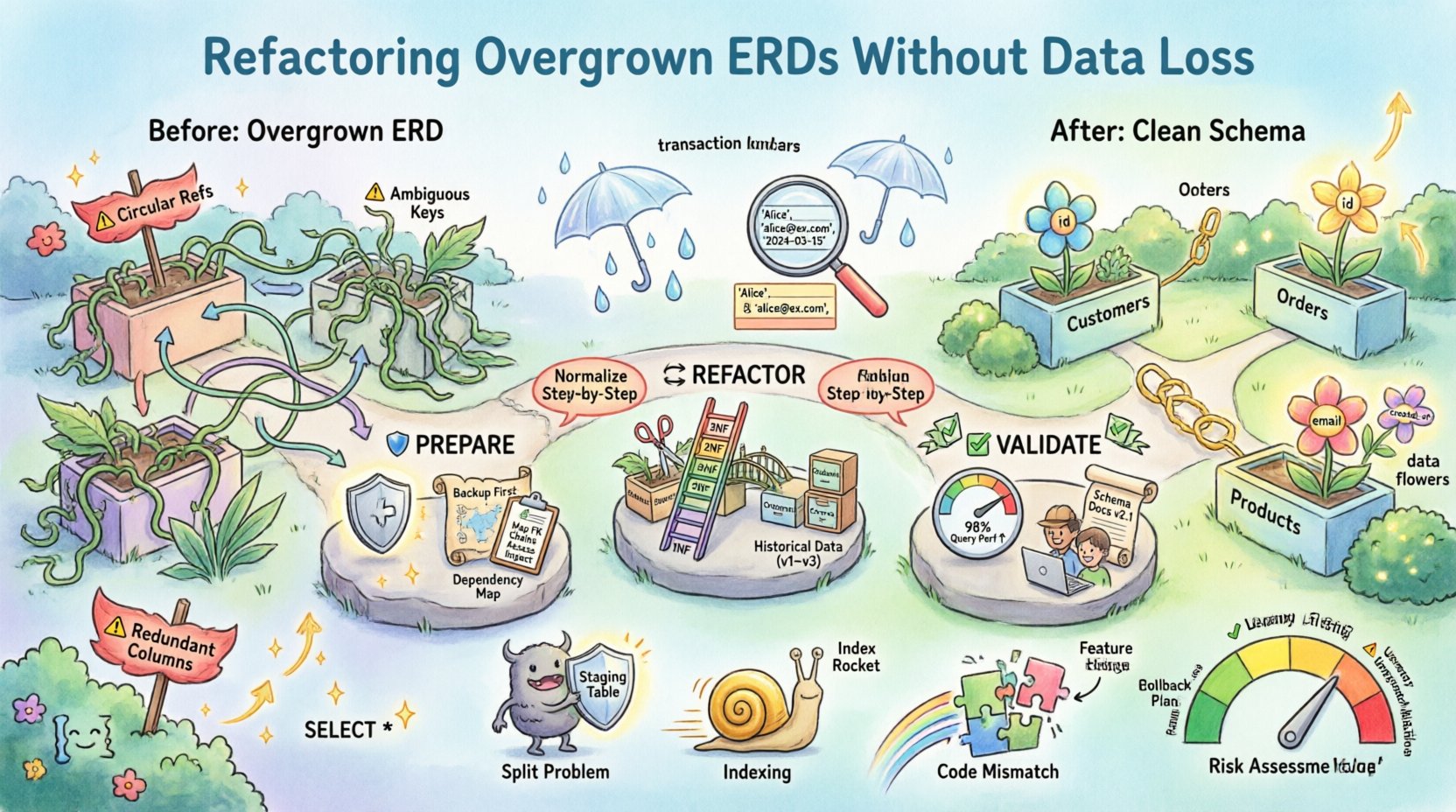
📉 Pourquoi les ERD deviennent ingérables
Comprendre les causes profondes du gonflement du schéma est la première étape vers une résolution. Un ERD qui a grandi de manière organique sans gouvernance présente souvent des symptômes spécifiques. Reconnaître ces modèles permet d’agir de manière ciblée.
- Colonnes redondantes : Le même point de données est stocké dans plusieurs tables. Cela crée des difficultés de synchronisation où la mise à jour d’une instance ne met pas à jour l’autre.
- Surutilisation de la dénormalisation : Bien que la dénormalisation améliore la vitesse de lecture, son usage excessif complique les opérations d’écriture et augmente la charge de stockage.
- Relations faibles : Les relations plusieurs à plusieurs sont souvent implémentées à l’aide de tables simples avec plusieurs clés étrangères, plutôt que des tables de jonction appropriées.
- Logique métier implicite : Les types de données et les contraintes peuvent dépendre de vérifications au niveau de l’application plutôt que de l’application de règles au niveau de la base de données, ce qui rend le schéma fragile.
- Entités orphelines : Des tables existent qui ne sont plus référencées par aucun module d’application actif, mais qui restent dans le stockage physique.
Lorsque ces facteurs s’accumulent, l’ERD devient un réseau entremêlé. Visualiser les relations devient difficile, et le risque d’introduire des erreurs lors de toute modification augmente de façon exponentielle.
🛡️ Préparation des modifications de schéma
Avant de toucher la moindre ligne de DDL (langage de définition des données), une phase de préparation rigoureuse est obligatoire. Cette phase minimise les risques et garantit qu’un retour en arrière est possible en cas de problème.
1. Stratégie complète de sauvegarde
La sécurité des données est primordiale. Une sauvegarde n’est pas simplement un fichier ; c’est un point de vérification.
- Sauvegardes logiques : Exporter les définitions de schéma et les données dans un format lisible par l’humain (comme des dumps SQL).
- Instantanés physiques : Si la plateforme le permet, créez un instantané ponctuel du volume de stockage.
- Réplica en lecture seule : Si possible, mettez en place une réplique de l’environnement de production. Effectuez tous les tests et scripts de migration ici en premier.
2. Cartographie des dépendances
Les tables n’existent pas en isolation. Chaque entité est référencée par du code d’application, des procédures stockées ou des outils de reporting externes. Vous devez identifier chaque consommateur des données.
- Examinez le code d’application pour repérer les références directes aux tables.
- Vérifiez s’il existe des vues ou des vues matérialisées qui dépendent de colonnes spécifiques.
- Identifiez tous les emplois planifiés ou les processus ETL (extraction, transformation, chargement) qui ingestent ou sortent des données depuis les tables concernées.
3. Analyse d’impact
Documentez l’état actuel. Créez une base de référence des nombres de lignes, de la répartition des données et des temps d’exécution des requêtes. Cette base de référence vous permet de comparer l’état du système avant et après le restructurage afin de garantir la cohérence.
| Élément de la liste de contrôle | Priorité | Notes |
|---|---|---|
| Vérifiez l’intégralité de la sauvegarde | Élevée | Assurez-vous que les sommes de contrôle correspondent à la source |
| Cartographiez toutes les clés étrangères | Élevée | Documentez les relations parent-enfant |
| Identifiez les requêtes actives | Moyenne | Utilisez les journaux de requêtes pour identifier les requêtes les plus coûteuses |
| Revoyez les contrôles d’accès | Moyenne | Assurez-vous que les autorisations sont conservées après le transfert |
🔄 La méthodologie de restructurage
Le cœur du restructurage consiste à restructurer le modèle logique. Cela est souvent réalisé par la normalisation, bien que la dénormalisation stratégique puisse être conservée pour des raisons de performance. L’objectif est la clarté et l’intégrité.
1. Analysez la normalisation actuelle
La plupart des schémas hérités ne respectent pas la Troisième Forme Normale (3NF). Passer à une normalisation plus élevée réduit la redondance.
- Première Forme Normale (1NF) :Assurez l’atomicité. Aucun groupe répétitif ou attribut multivalué dans une seule cellule.
- Deuxième Forme Normale (2NF) :Supprimez les dépendances partielles. Assurez-vous que chaque attribut non clé dépend entièrement de la clé primaire.
- Troisième Forme Normale (3NF) :Supprimez les dépendances transitives. Les attributs non clés doivent dépendre uniquement de la clé, et non d’autres attributs non clés.
| Niveau de normalisation | Règle clé | Avantage |
|---|---|---|
| 1NF | Valeurs atomiques uniquement | Élimine la logique de parsing complexe |
| 2NF | Dépendance complète sur la clé primaire | Réduit les anomalies de mise à jour |
| 3NF | Pas de dépendances transitives | Améliore la cohérence des données |
2. Découper les entités volumineuses
Lorsqu’une seule table contient trop de colonnes, cela indique souvent que des concepts commerciaux distincts sont confondus. Séparez-les en tables distinctes.
- Identifiez les groupes de colonnes qui décrivent des entités différentes (par exemple, Profil utilisateur vs. Préférences utilisateur).
- Créez une nouvelle table pour le concept distinct.
- Déplacez les colonnes pertinentes vers la nouvelle table.
- Établissez une relation un à un à l’aide d’une clé étrangère.
3. Résoudre les relations plusieurs à plusieurs
Lier directement deux tables par une colonne dans chacune est un anti-patrimoine courant. Cela doit être remplacé par une table de jonction.
- Créez une nouvelle table pour servir de pont.
- Incluez les clés primaires des deux tables parentes comme clés étrangères dans la table de jonction.
- Ajoutez tout attribut spécifique qui appartient à la relation elle-même (par exemple, la date à laquelle une relation a été établie).
4. Gérer les données historiques
Le restructurage modifie souvent la manière dont les données sont stockées. Les enregistrements historiques doivent être conservés avec précision.
- Ne supprimez pas simplement les anciennes données. Elles peuvent être nécessaires pour des traçages d’audit ou des exigences légales.
- Utilisez des scripts de migration pour transformer les données existantes au format nouveau avant de basculer la connexion de l’application.
- Archivez les anciennes tables si elles ne sont plus nécessaires mais doivent être conservées pour des raisons d’archivage.
✅ Assurer l’intégrité des données
Pendant la transformation, le risque de corruption des données est le plus élevé. Les contraintes d’intégrité sont votre filet de sécurité.
1. Contraintes de clé étrangère
Assurez l’intégrité référentielle au niveau de la base de données. Cela empêche les enregistrements orphelins où un enregistrement enfant fait référence à un parent qui n’existe plus.
- Activer
CASCADEles mises à jour ou les suppressions uniquement là où cela est logiquement nécessaire. - Utiliser
RESTRICTouAUCUNE ACTIONpour bloquer les modifications qui rompraient les relations.
2. Gestion des transactions
Enveloppez toutes les étapes de migration dans des transactions. Cela garantit que toutes les modifications sont appliquées ou aucune ne l’est. Les mises à jour partielles entraînent des états incohérents.
- Démarrez une transaction avant la première commande DDL.
- Validez uniquement après que toutes les vérifications de validation aient réussi.
- Annulez immédiatement si une erreur survient.
3. Scripts de validation des données
Après la migration, exécutez des scripts pour vérifier les données.
- Comparez les nombres de lignes entre les anciennes et les nouvelles tables.
- Calculez les sommes de contrôle sur les colonnes critiques pour garantir des correspondances exactes.
- Vérifiez la présence de valeurs nulles dans les colonnes qui n’étaient auparavant pas nulles.
- Vérifiez que toutes les contraintes uniques sont respectées.
⚠️ Pièges courants et solutions
Même avec une planification soigneuse, des problèmes peuvent survenir. Anticiper ces problèmes réduit les temps d’indisponibilité.
1. Le problème de « séparation »
Lors de la séparation d’une table, vous pouvez rencontrer des clés en double. Si une clé composite est divisée, assurez-vous que les nouvelles clés conservent leur unicité dans la nouvelle structure.
- Solution : Utilisez des tables temporaires de staging pour réorganiser les données avant d’appliquer le nouveau schéma.
2. Performances des index
De nouvelles relations nécessitent de nouveaux index. Sans eux, les requêtes sur les nouvelles tables de jonction seront lentes.
- Solution : Créez des index sur les colonnes de clés étrangères immédiatement après leur création. Ne comptez pas uniquement sur l’index de clé primaire.
3. Mauvaise correspondance du code d’application
Les modifications de la base de données sont effectuées, mais le code de l’application ne se met pas à jour immédiatement. Cela entraîne des erreurs d’exécution.
- Solution :Mettez en place un indicateur de fonctionnalité ou une stratégie d’écriture double pendant la période de transition. Permettez aux anciennes et nouvelles structures de schémas de coexister brièvement.
4. Incompatibilités de type de données
Le restructurage implique souvent le changement de types de données (par exemple, VARCHAR en INT). Si les données contiennent des caractères non numériques dans un champ à convertir, la migration échouera.
- Solution :Nettoyez les données lors d’une étape préalable à la migration. Générez un rapport des données non valides pour un examen manuel.
🚀 Validation post-restructurage
Le travail n’est pas terminé lorsque le script de migration est terminé. Le système doit être validé dans un environnement similaire à la production.
- Benchmarking des performances :Exécutez le même ensemble de requêtes utilisé lors du contrôle de base. Comparez les temps d’exécution et l’utilisation des ressources.
- Tests d’acceptation par l’utilisateur :Faites effectuer aux utilisateurs de l’application des workflows standards afin de garantir que les données s’affichent correctement dans l’interface utilisateur.
- Configuration de la surveillance :Activez la journalisation améliorée et la surveillance pour les tables spécifiques concernées. Surveillez les pics d’erreurs ou les augmentations de latence.
- Mise à jour de la documentation :Mettez à jour les diagrammes ERD, les dictionnaires de données et la documentation de l’API pour refléter la nouvelle structure.
📝 Matrice d’évaluation des risques
| Facteur de risque | Impact | Stratégie d’atténuation |
|---|---|---|
| Perte de données inattendue | Critique | Vérifiez les sauvegardes avant de commencer ; utilisez des transactions |
| Interruption de service | Élevé | Planifiez pendant les fenêtres de maintenance ; utilisez un déploiement bleu-vert |
| Dégradation des performances | Moyen | Testez avec des données de taille similaire à la production ; optimisez les index |
| Panne d’application | Élevé | Drapeaux de fonctionnalité ; déploiement progressif |
Le refactoring d’un diagramme d’entité-relation est une tâche d’ingénierie rigoureuse. Elle exige un équilibre entre les principes théoriques de modélisation des données et les contraintes opérationnelles pratiques. En suivant une approche structurée, en maintenant des contrôles stricts de l’intégrité des données et en vous préparant soigneusement à la transition, vous pouvez moderniser votre architecture des données sans compromettre la fiabilité de vos actifs informationnels.
La complexité des systèmes modernes exige que nous restions vigilants. Les revues régulières du diagramme ERD doivent faire partie du cycle de développement afin d’éviter que la croissance excessive ne devienne à nouveau un problème critique. Traitez le schéma comme un composant essentiel de l’infrastructure de l’application, digne du même soin et de la même attention que le code lui-même.
Le succès de cette entreprise se mesure à la stabilité du système après le transfert et à la précision continue des données qu’il contient. Avec de la patience et de la précision, le chemin vers une structure de base de données plus propre et plus efficace est réalisable.