











La modélisation des données est souvent le fondement invisible de toute application logicielle. Alors que le code exécutant la logique métier est au centre de l’attention, le schéma sous-jacent détermine les performances, la scalabilité et la maintenabilité. Pour de nombreux ingénieurs juniors, le diagramme entité-association (ERD) est une tâche simple consistant à dessiner des boîtes et à relier des lignes. Cependant, cette simplicité est trompeuse. Un ERD mal conçu crée une dette technique qui s’accumule au fil du temps, entraînant des requêtes complexes, des problèmes d’intégrité des données et des migrations difficiles.
Ce guide explore la faille de complexité cachée. Il identifie où se situe le décalage entre les connaissances théoriques et leur application pratique. En comprenant ces pièges, les développeurs peuvent aller au-delà du simple dessin de diagrammes pour adopter une pensée architecturale véritable.
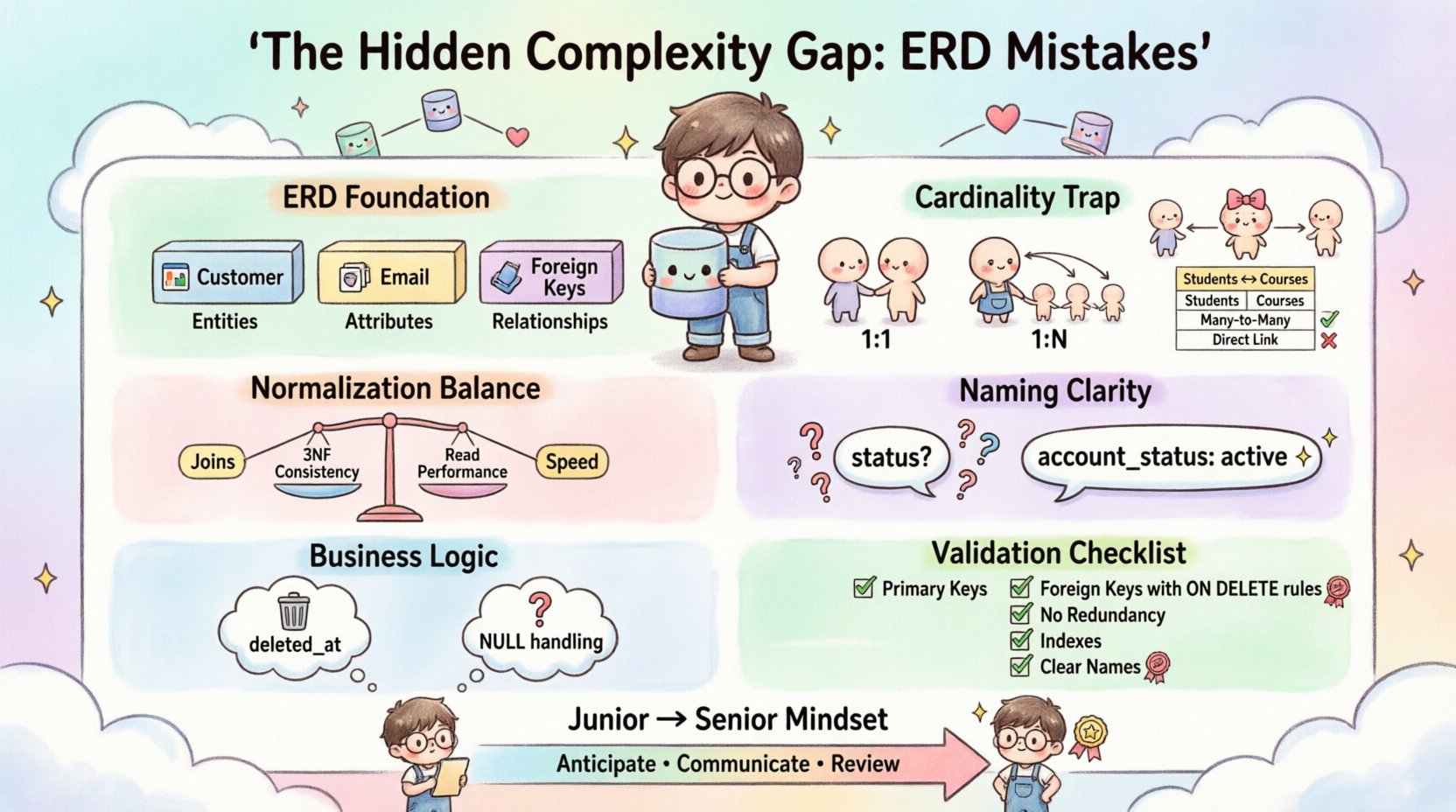
1. Comprendre les fondements de la modélisation des données 🏗️
Avant d’aborder les erreurs, il est essentiel de clarifier ce qu’un ERD représente réellement. Ce n’est pas simplement un dessin ; c’est un contrat entre l’application et la couche de stockage. Un ERD visualise les entités (tables), les attributs (colonnes) et les relations (clés étrangères).
Lorsqu’un ingénieur considère cet outil comme un artefact statique créé une fois et oublié, il néglige la nature dynamique des données. Les modèles de données évoluent au fur et à mesure que les exigences métiers changent. Un ingénieur junior pourrait se concentrer sur une fonctionnalité immédiate, comme le stockage du nom d’un utilisateur, tout en ignorant la manière dont cet utilisateur interagit avec d’autres entités telles que les commandes, les abonnements ou les journaux.
- Entités : Elles représentent des objets ou des concepts du monde réel (par exemple, Client, Produit, Facture).
- Attributs : Ce sont les propriétés qui définissent l’entité (par exemple, Email, Prix, Date).
- Relations : Elles définissent la manière dont les entités interagissent (par exemple, Un-à-Plusieurs, Plusieurs-à-Plusieurs).
Un modèle robuste prend en compte la croissance future. Il anticipe comment un « Client » pourrait devenir un « Utilisateur » ou comment un « Produit » pourrait nécessiter des variantes. Le diagramme initial doit être suffisamment souple pour intégrer ces changements sans nécessiter une reconstruction complète.
2. Le piège de la cardinalité : interpréter incorrectement les relations 🔄
La cardinalité est la source la plus fréquente d’échec structurel dans la conception des bases de données. Elle définit la relation numérique entre les instances d’entités. Une mauvaise compréhension de ce concept entraîne un stockage inefficace et une logique de jointure complexe.
Scénarios courants de cardinalité
Les ingénieurs ont souvent tendance à choisir la relation la plus évidente sans tenir compte des cas limites. Pensez aux scénarios suivants où des hypothèses conduisent à des erreurs :
- Un-à-Un (1:1) :Souvent surutilisé. Si deux entités ont une relation 1:1, elles devraient souvent être fusionnées dans une seule table afin de réduire la surcharge des jointures, sauf si une séparation de sécurité stricte est requise.
- Un-à-Plusieurs (1:N) :La relation la plus fréquente. Un enregistrement Parent est lié à plusieurs enregistrements Enfant. La clé étrangère doit se trouver du côté Enfant.
- Plusieurs-à-Plusieurs (M:N) :C’est là que s’élargit la faille de complexité. Une relation M:N directe n’est pas physiquement possible dans un modèle relationnel sans table d’intermédiaire.
Tableau : Erreurs d’implémentation de la cardinalité
| Scénario | Approche incorrecte | Approche correcte |
|---|---|---|
| Étudiants et Cours | Ajouter une colonne « CourseID » à la table « Student » | Création d’une table de jonction « Student_Course » |
| Commandes et produits | Intégrer directement les détails du produit dans la table Commande | Lier via une table OrderItems |
| Employés et départements | Permettre à un employé d’appartenir à plusieurs départements sans table de jonction | Séparer la relation de correspondance |
Lorsque les ingénieurs tentent de forcer une relation plusieurs-à-plusieurs dans une seule table en répétant les données, ils introduisent une redondance. Si le prix d’un produit change, il doit être mis à jour dans chaque enregistrement de commande où ce produit apparaît. Cela viole les principes de normalisation et crée des cauchemars de maintenance.
3. Mythes sur la normalisation et vérifications de la réalité 📉
La normalisation est un concept standard enseigné dans les milieux académiques. L’objectif est de réduire la redondance des données et d’améliorer l’intégrité. Cependant, les jeunes ingénieurs normalisent souvent de manière excessive (jusqu’à la 5NF) sans tenir compte des compromis liés aux performances.
Le piège de la sur-normalisation
Un schéma sur-normalisé divise les données en trop de tables. Bien que cela assure la cohérence, il oblige l’application à effectuer des jointures excessives. Chaque jointure ajoute un coût computationnel. Dans les systèmes à fort trafic, cela peut devenir un goulot d’étranglement.
- 1FN (Première Forme Normale) :Valeurs atomiques. Aucune liste dans une seule cellule.
- 2FN (Deuxième Forme Normale) :Pas de dépendances partielles. Toutes les attributs non clés doivent dépendre de toute la clé primaire.
- 3FN (Troisième Forme Normale) :Pas de dépendances transitives. Les attributs ne doivent pas dépendre d’autres attributs non clés.
Une erreur courante consiste à supposer que la 3FN est toujours l’objectif. Dans certains cas, la dénormalisation est un choix de conception délibéré. Par exemple, stocker un « Montant total de la commande » directement dans la table Commande évite de calculer la somme des articles chaque fois que la commande est affichée. Cela échange les performances d’écriture contre les performances de lecture.
Tableau : Normalisation vs. Dénormalisation
| Facteur | Normalisé (3FN) | Dénormalisé |
|---|---|---|
| Redondance des données | Faible | Élevée |
| Vitesse d’écriture | Rapide | Plus lent |
| Vitesse de lecture | Plus lent (plus de jointures) | Rapide |
| Intégrité des données | Élevé | Inférieur (nécessite une logique) |
La décision de dénormaliser doit être pilotée par les données. Elle ne doit pas se produire arbitrairement. Les ingénieurs doivent profiler les performances des requêtes avant de fusionner les tables. Suivre aveuglément les règles de normalisation sans contexte conduit à des systèmes cohérents mais lents.
4. Conventions de nommage et clarté sémantique 🏷️
Les noms de schéma sont le vocabulaire de la base de données. Si le vocabulaire est ambigu, le système devient incompréhensible pour les développeurs futurs. C’est un problème fréquent où la précision technique est sacrifiée au profit de la brièveté.
Un champ nommé statut est dangereux. Qu’est-ce que cela signifie ? Un compte actif ? Un paiement en attente ? Un enregistrement supprimé ? Sans contexte, le sens est perdu. De même, utiliser des noms pluriels pour les tables (par exemple, Utilisateurs) plutôt que singulier (par exemple, Utilisateur) crée une incohérence.
- Cohérence : Si une table utilise
snake_case, toutes doivent utilisersnake_case. - Descriptivité : Utilisez des noms qui décrivent les données, et non seulement le format. Évitez les termes génériques comme
table1oudonnées. - Contexte : Incluez le nom de l’entité dans la clé de relation si une ambiguïté existe. Utilisez
id_utilisateurplutôt que simplementidlorsque cela est possible.
Considérez le scénario d’un système avec plusieurs types d’utilisateurs : administrateurs, clients et fournisseurs. Une seule table nommée Utilisateurs pourrait contenir une colonne rôle colonne. Il s’agit d’une « table Dieu ». Une meilleure approche consiste à utiliser des tables séparées ou une stratégie d’héritage claire. Cette distinction devient cruciale lorsque les autorisations et les règles d’accès aux données divergent fortement entre les rôles.
5. Ignorer la logique métier dans la conception technique 🧠
La plus grande différence entre les ingénieurs juniors et les ingénieurs seniors réside dans la compréhension de la logique métier. Un ingénieur junior pourrait concevoir un schéma qui correspond parfaitement aux exigences actuelles du code, mais échouerait lorsque les règles métiers changent.
Le malentendu sur la suppression douce
Beaucoup de développeurs ajoutent simplement une colonne supprimé_le à une table. Cela fonctionne dans les cas simples. Toutefois, si un utilisateur est supprimé, ses journaux associés doivent-ils être supprimés ? Les enregistrements financiers doivent-ils être conservés pour respecter les exigences d’audit ? Le schéma conceptuel des données doit refléter ces contraintes à travers des contraintes et des déclencheurs, et non seulement du code d’application.
Le problème des valeurs NULL
Permettre les valeurs NULL est souvent à l’origine d’une complexité cachée. Dans certains cas, NULL a une signification différente d’une chaîne vide ou d’un zéro. Si un champ est facultatif, le schéma conceptuel des données doit le préciser clairement. Toutefois, il est déconseillé de s’appuyer sur les NULLs pour contrôler la logique.
- Intégrité référentielle : Les clés étrangères ne devraient idéalement pas être NULL sauf si la relation est véritablement facultative.
- Calculs : Les NULL se propagent dans les calculs, entraînant des résultats NULL. Cela peut rompre les requêtes d’agrégation.
- Index : Le traitement des NULL dans les index varie selon le moteur de base de données, pouvant affecter les performances des requêtes.
6. La charge de maintenance d’une mauvaise conception 🔧
La dette technique ne concerne pas seulement le code lent ; elle concerne la rigidité structurelle. Un schéma conceptuel des données mal conçu rend les modifications douloureuses. Lorsqu’une nouvelle exigence arrive, comme l’ajout d’une « adresse de facturation » distincte de l’« adresse de livraison », l’ingénieur doit évaluer si le schéma actuel le permet.
Cauchemars de migration
Modifier le schéma d’une base de données de production contenant des millions d’enregistrements exige une planification soigneuse. Si le schéma conceptuel des données n’a pas été conçu en tenant compte des migrations, modifier le type d’une colonne ou diviser une table peut bloquer le système pendant des heures. Ce temps d’indisponibilité affecte les revenus et la confiance des utilisateurs.
Des stratégies pour atténuer cela incluent :
- Contrôle de version pour le schéma : Traitez la structure de la base de données comme du code d’application.
- Compatibilité descendante : Ajoutez les colonnes avant de les supprimer. Gardez les anciennes colonnes jusqu’à la fin de la migration.
- Documentation : Le modèle MER devrait être la source de vérité. Si celui-ci ne correspond pas à la base de données, c’est la base de données qui est fausse.
7. Liste de contrôle pratique pour la validation du modèle MER ✅
Pour garantir une conception robuste, les ingénieurs doivent passer en revue une liste de contrôle de validation avant de finaliser le schéma. Ce processus permet de détecter les erreurs logiques avant le début de l’implémentation.
Validation préalable à l’implémentation
| Vérification | Question | Critères de validation |
|---|---|---|
| Clés primaires | Chaque table possède-t-elle un identifiant unique ? | Oui, auto-incrément ou UUID |
| Clés étrangères | Les relations sont-elles explicitement définies ? | Oui, avec des règles ON DELETE/UPDATE |
| Redondance | Des données sont-elles stockées à plusieurs endroits ? | Non, sauf si la dénormalisation est intentionnelle |
| Évolutivité | Peut-il gérer 10 fois le volume de données actuel ? | Des index existent sur les clés étrangères |
| Lisibilité | Un nouveau recruté peut-il comprendre le flux en 5 minutes ? | Conventions de nommage claires |
8. Outils vs. Concepts 🛠️
Il est facile de s’appuyer sur les fonctionnalités d’un outil spécifique pour résoudre des problèmes de conception. Toutefois, l’outil est secondaire par rapport au concept. Que l’on utilise un outil de modélisation visuelle ou qu’on écrive directement des scripts SQL, la logique sous-jacente reste la même.
Certains ingénieurs créent des schémas qui semblent parfaits visuellement mais sont syntaxiquement impossibles dans la base de données cible. Par exemple, certains outils permettent des dépendances circulaires au niveau visuel, alors que le moteur de base de données les rejette. L’attention doit rester centrée sur les règles d’intégrité relationnelle plutôt que sur l’interface de dessin.
- Consistance visuelle : Utilisez des symboles standards pour les relations (notation en pied de corbeau).
- Validation : Exécutez le schéma sur une base de données de test pour vérifier les contraintes.
- Collaboration : Revue du diagramme avec les parties prenantes qui comprennent le domaine métier, et non seulement les pairs techniques.
9. Scénarios du monde réel d’échec ⚠️
Comprendre des concepts abstraits est une chose ; les voir échouer en pratique en est une autre. Ci-dessous figurent des scénarios courants où une mauvaise conception d’un modèle entité-association entraîne des problèmes concrets.
Scénario A : La boucle infinie
Un développeur crée une relation entre Utilisateurs et Équipesoù un utilisateur appartient à une équipe, et une équipe est dirigée par un utilisateur. Si la clé étrangère pointe vers la même table sans racine claire, des erreurs de référence circulaire surviennent lors de l’insertion. Le modèle entité-association doit clairement distinguer les relations « Membre » et « Responsable ».
Scénario B : La perte silencieuse de données
Une Commandetable fait référence à une Produittable. La ON DELETEcontrainte est définie sur CASCADE. Lorsqu’un produit est supprimé du catalogue, toutes les commandes associées sont supprimées. Cela détruit les données historiques de ventes. Le modèle entité-association doit définir explicitement l’action référentielle sur RESTREINDRE ou SET NULL selon les besoins métiers.
Scénario C : La recherche lente
Une table est créée avec une colonne nomcolonne. Les ingénieurs interrogent fréquemment cette table pour trouver des utilisateurs par nom. Sans index défini dès la phase de conception, la base de données effectue un balayage complet de la table. Le modèle entité-association doit indiquer quelles colonnes sont intensivement recherchées et nécessitent un index.
10. Évolution du mindset junior vers senior 🚀
La transition consiste à déplacer l’attention de « Est-ce que ça fonctionne ? » vers « Est-ce que ça évolue ? » et « Est-ce que c’est maintenable ? ».
- Anticipation : Prédire les besoins futurs en fonction des tendances du secteur.
- Communication : Traduire les contraintes techniques en risques métiers.
- Revue : Ne suppose jamais qu’un schéma est correct sans revue par un pair.
Les ingénieurs juniors travaillent souvent de manière isolée. Les ingénieurs seniors collaborent. Le schéma ERD est un outil de communication. Il comble le fossé entre les développeurs, les gestionnaires de produit et les parties prenantes. Si le schéma est confus, les attentes seront mal alignées.
Pensées finales sur l’intégrité des données 🎯
Construire un schéma de base de données n’est pas une tâche ponctuelle ; c’est une discipline continue. L’écart de complexité existe parce que les enjeux sont élevés. Une erreur dans le code de l’application peut être corrigée rapidement. Une erreur dans le modèle de données nécessite souvent une migration, un nettoyage des données et une interruption de service.
En respectant des principes de modélisation stricts, en comprenant profondément la cardinalité et en privilégiant la logique métier plutôt que la commodité, les ingénieurs peuvent combler cet écart. L’objectif n’est pas de créer un schéma parfait, mais de créer une base solide qui soutient l’évolution du logiciel. Les données sont l’actif le plus précieux qu’une application puisse posséder. Protéger leur structure est la responsabilité de chaque ingénieur impliqué dans le processus de construction.
Prenez le temps de revoir vos schémas. Mettez en doute chaque relation. Vérifiez chaque contrainte. Le temps investi dans la phase de conception permet d’économiser des mois d’efforts lors de la phase de maintenance.