











Concevoir l’architecture des données pour un système backend à grande échelle est une tâche fondamentale qui détermine la durabilité et la stabilité de toute l’application. Un diagramme de relation entre entités, souvent abrégé en ERD, sert de plan directeur pour cette architecture. Il représente visuellement la structure des données, en définissant comment les différentes pièces d’information se connectent, se rapportent et interagissent au sein du système. Dans un contexte d’entreprise, où la cohérence des données, l’intégrité et la scalabilité sont primordiales, respecter les normes établies des ERD n’est pas simplement une bonne pratique ; c’est une nécessité.
Sans une approche standardisée de la modélisation des données, les systèmes backend risquent de devenir fragiles. Des conventions de nommage incohérentes, des relations ambigües et une mauvaise normalisation peuvent entraîner des goulets d’étranglement de performance, des cycles de maintenance difficiles et des corruption des données. Ce guide explore les normes et méthodologies essentielles nécessaires pour concevoir des schémas de bases de données robustes adaptés aux environnements d’entreprise complexes. Nous examinerons les composants fondamentaux, les systèmes de notation, les règles de normalisation et les stratégies de gouvernance que les équipes professionnelles mettent en œuvre pour garantir que leurs couches de données restent fiables au fil du temps.
Composants fondamentaux d’un ERD d’entreprise 🧩
Avant de plonger dans les normes spécifiques, il est essentiel de comprendre les éléments fondamentaux qui constituent un ERD. Chaque diagramme dans un contexte professionnel repose sur trois éléments principaux. Ces éléments agissent ensemble pour décrire la structure logique des données.
- Entités : Elles représentent les objets ou concepts du monde réel dont les données sont stockées. Dans un contexte backend, une entité correspond souvent directement à une table de base de données. Des exemples incluent Client, Commande, ou Produit. Les entités doivent être clairement définies afin de garantir que chaque enregistrement dispose d’une identité unique.
- Attributs : Les attributs décrivent les propriétés ou caractéristiques spécifiques d’une entité. Ils correspondent aux colonnes au sein d’une table. Pour une entité Client , les attributs pourraient inclure IDClient, NomComplet, et AdresseEmail. Définir correctement les types de données pour les attributs est crucial pour l’intégrité des données.
- Relations : Les relations définissent comment les entités interagissent entre elles. Elles établissent les contraintes et les associations entre les tables. Par exemple, un seul Client peut passer plusieurs Commandes. Cette relation détermine les contraintes de clés étrangères et la logique de jointure nécessaires dans le backend.
Dans le développement de niveau entreprise, ces composants ne sont pas seulement des concepts abstraits ; ils constituent la base de l’optimisation des requêtes, du contrôle d’accès et des stratégies de migration des données. Un ERD bien documenté permet aux développeurs de comprendre le flux des données sans avoir à inspecter chaque ligne de code.
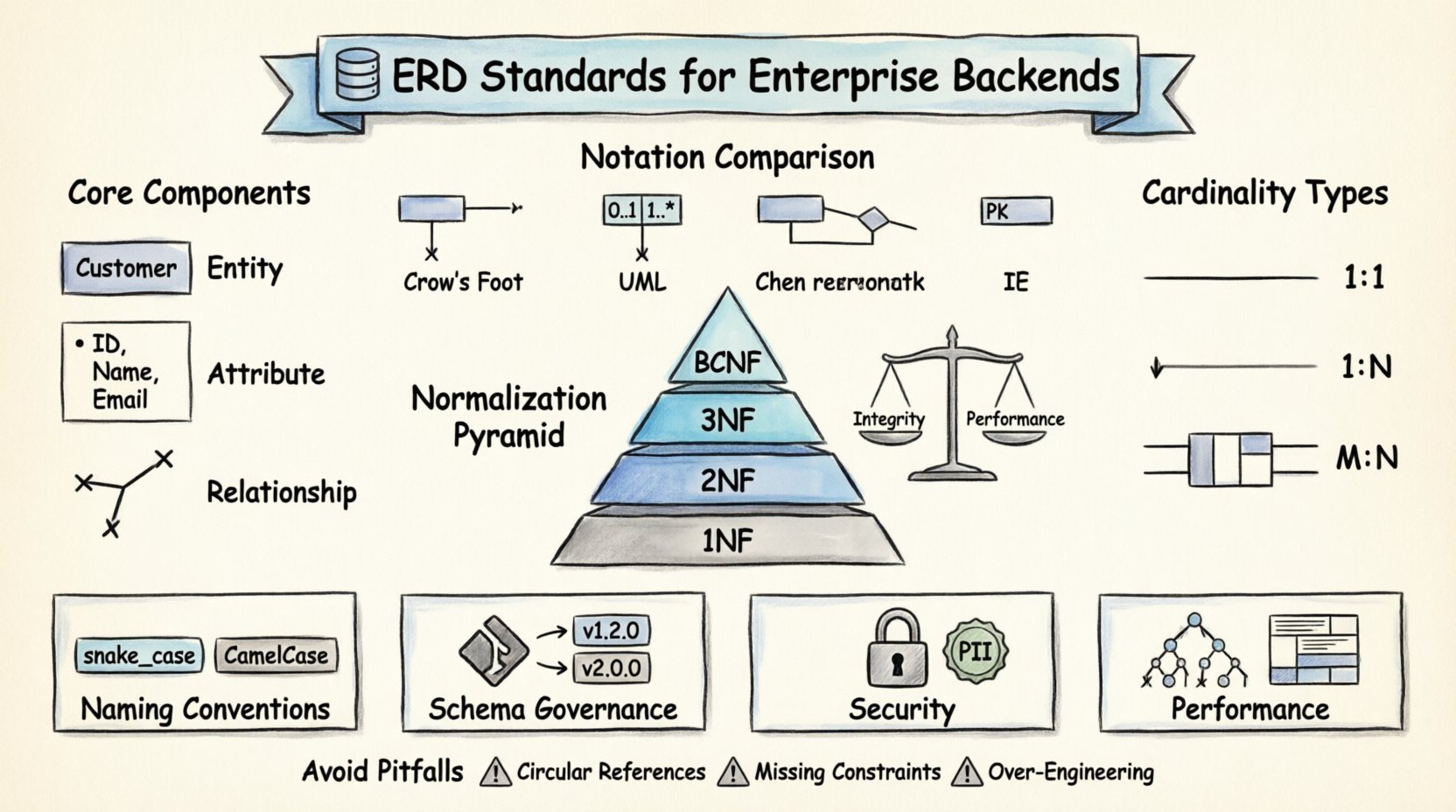
Normes de notation et conventions visuelles 📐
Il n’existe pas de syntaxe universelle unique pour dessiner les modèles entité-association, mais il existe des normes largement acceptées qui garantissent clarté et cohérence entre différentes équipes. Choisir une notation et s’y tenir est une décision stratégique essentielle.
Notation Chen versus Notation à pieds de corbeau
Historiquement, la notation Chen était la norme, utilisant des rectangles pour les entités et des losanges pour les relations. Bien qu’elle soit claire, elle est moins courante dans les outils modernes de développement logiciel. La notation à pieds de corbeau est devenue la préférence de l’industrie pour plusieurs raisons :
- Clarté dans la cardinalité : Elle utilise des symboles spécifiques (lignes, cercles et « pieds ») pour représenter visuellement les relations un-à-un, un-à-plusieurs et plusieurs-à-plusieurs.
- Prise en charge par les outils : La plupart des outils modernes de conception de bases de données et des utilitaires de reverse-ingénierie prennent en charge nativement les symboles à pieds de corbeau ou dérivés du UML.
- Lisibilité : Elle est généralement plus compacte et plus facile à lire lorsqu’on traite des schémas complexes et interconnectés.
Comparaison des systèmes de notation
| Style de notation | Représentation des entités | Représentation des relations | Meilleur cas d’utilisation |
|---|---|---|---|
| Pieds de corbeau | Rectangle | Lignes avec des symboles (pieds de corbeau, cercle, ligne) | Conception de bases de données relationnelles |
| Diagramme de classes UML | Boîte de classe avec compartiments | Flèches avec multiplicités (0..1, 1..*) | Modélisation orientée objet |
| Chen | Rectangle | Forme de losange reliant les entités | Modèles académiques/ théoriques |
| IE (Ingénierie des informations) | Rectangle avec attributs | Lignes avec indicateurs de clés primaires | Documentation du système hérité |
Pour les backends d’entreprise, la notation Crow’s Foot est généralement recommandée en raison de son mappage direct aux contraintes relationnelles. Elle minimise les ambiguïtés lorsqu’un développeur interprète le schéma pendant l’implémentation.
Normalisation : garantir l’intégrité des données 🔄
La normalisation est le processus d’organisation des données dans une base de données afin de réduire la redondance et d’améliorer l’intégrité des données. Bien que les systèmes modernes dénormalisent parfois pour des raisons de performance, comprendre les règles de normalisation est essentiel pour concevoir un schéma initial solide.
Les formes normales
- Première forme normale (1NF) : Chaque colonne doit contenir des valeurs atomiques. Les listes de valeurs dans une seule cellule sont interdites. Cela garantit que chaque intersection entre une ligne et une colonne contient une seule pièce de données indivisible.
- Deuxième forme normale (2NF) : La table doit être en 1NF, et toutes les attributs non clés doivent dépendre entièrement de la clé primaire. Cela empêche les dépendances partielles où une colonne dépend uniquement d’une partie d’une clé composite.
- Troisième forme normale (3NF) : La table doit être en 2NF, et il ne doit pas y avoir de dépendances transitives. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés. Par exemple, si Ville dépend de Code postal, et Code postal dépend de ID, Ville doit être déplacée dans une table séparée.
- Forme normale de Boyce-Codd (BCNF) : Une version plus stricte de la 3NF. Elle exige que pour toute dépendance fonctionnelle X → Y, X soit une superclé. Cela traite certains cas limites de la 3NF où un déterminant est une clé candidate mais pas la clé primaire.
Compromis de normalisation
| Niveau | Avantage | Coût |
|---|---|---|
| Haute normalisation (3NF/BCNF) | Redondance minimale, intégrité élevée | Plus de jointures nécessaires pour les requêtes |
| Faible normalisation (dénormalisée) | Performances de lecture plus rapides | Risque accru d’incohérence des données |
Les systèmes d’entreprise visent généralement la 3NF dans leurs schémas transactionnels. Lorsque les performances de lecture deviennent un goulot d’étranglement, la dénormalisation est appliquée de manière sélective à des vues spécifiques ou des tables de reporting, plutôt que sur le schéma transactionnel central.
Conventions de nommage et hygiène du schéma 🏷️
Une convention de nommage cohérente est essentielle pour la maintenabilité. Lorsque plusieurs équipes travaillent sur le même backend, l’ambiguïté dans le nommage entraîne des erreurs. Une norme doit être documentée et appliquée via des outils de vérification ou des scripts de validation du schéma.
Règles de nommage des tables
- Pluriel vs. Singulier : Il y a un débat, mais la cohérence est essentielle. Les noms au pluriel (par exemple, Utilisateurs, Commandes) se lisent souvent mieux dans des phrases anglaises. Les noms au singulier (par exemple, Utilisateur, Ordre) sont souvent préférés dans les contextes orientés objet. Choisissez-en un et appliquez-le globalement.
- Soulignés vs. CamelCase : Soulignés (snake_case) sont la norme pour les identifiants SQL. CamelCase (camelCase) est courant dans le code d’application. Assurez-vous que la couche base de données et la couche application s’accordent sur la stratégie de traduction.
- Évitez les mots réservés : Ne nommez jamais une table ou une colonne avec des mots réservés de base de données (par exemple, Groupe, Sélectionner, Ordre). Cela empêche les erreurs de syntaxe lors de la génération de requêtes.
- Préfixes pour les métadonnées : Utilisez des préfixes tels que _audit, _log, ou _temp pour distinguer les tables auxiliaires des entités métiers principales.
Règles de nommage des colonnes
- Clés étrangères : Indiquez clairement la relation. Si une colonne fait référence à la table Utilisateurs table, nommez-la id_utilisateur plutôt que id_util ou clef_etrangere_utilisateur.
- Drapeaux booléens : Utilisez des préfixes tels que est_ ou a_. Par exemple, est_actif ou a_abonnement.
- Champs de date-heure : Spécifiez la portée. Utilisez created_at ou updated_at au lieu de date ou heure.
Relations et cardinalité 🔄
Comprendre la cardinalité fait la différence entre une base de données fonctionnelle et une base cassée. La cardinalité définit le nombre exact d’instances d’une entité qui peuvent ou doivent être associées à chaque instance d’une autre entité.
Types de relations
- Un à un (1:1) : Une instance de l’entité A est associée à exactement une instance de l’entité B. Cela est rare dans la logique métier principale, mais courant pour les données de sécurité ou de configuration. Exemple : Un Utilisateur a un Profil.
- Un à plusieurs (1:N) : Une instance de l’entité A est associée à de nombreuses instances de l’entité B. C’est la relation la plus courante. Exemple : Une Département a de nombreux Employés.
- Plusieurs à plusieurs (M:N) : De nombreuses instances de l’entité A sont associées à de nombreuses instances de l’entité B. Cela nécessite une table de jonction (entité d’association). Exemple : Étudiants et Cours.
Optionnalité et contraintes
La cardinalité ne raconte pas toute l’histoire ; c’est l’optionnalité qui le fait. Cela fait référence au fait que la relation est obligatoire ou facultative.
- Obligatoire (participation obligatoire) : Une instance d’entité doit être associée à une autre. Par exemple, une Commande doit avoir une Client.
- Facultatif (participation facultative) : Une instance d’entité peut exister sans relation. Par exemple, un Produit peut exister sans une Commande enregistrement pour le moment.
Imposer ces règles au niveau de la base de données à l’aide de contraintes (NOT NULL, clés étrangères) est bien plus fiable que de les imposer dans le code applicatif. Cela protège contre le décalage des données et garantit que le schéma reste la source de vérité.
Gouvernance du schéma et contrôle de version 📜
Dans les environnements d’entreprise, le schéma de base de données est du code. Il doit être versionné, revu et géré avec la même rigueur que le code source applicatif. Un schéma ERN n’est pas un document statique ; il évolue au fur et à mesure que les exigences métiers changent.
Stratégies de migration
- Compatibilité ascendante : Les modifications doivent être conçues pour prendre en charge les anciennes données. Évitez de supprimer immédiatement les colonnes ; marquez-les plutôt comme obsolètes.
- Compatibilité descendante : Les nouvelles versions du schéma ne doivent pas rompre les requêtes existantes. Utilisez des vues pour masquer les modifications au niveau de la couche applicative.
- Modifications atomiques : Chaque script de migration doit représenter un seul changement logique. Cela facilite le retour en arrière en cas d’erreur.
Maintenance de la documentation
Un ERD non mis à jour est une charge. Assurez-vous que le processus de génération du diagramme est automatisé. Idéalement, l’ERD doit être généré directement à partir des fichiers de définition du schéma (DML) afin d’éviter tout écart entre la documentation et l’état réel de la base de données.
- Automatisez la génération de l’ERD à chaque validation.
- Exigez une revue du schéma dans le processus de demande de fusion.
- Marquez les versions majeures du schéma pour les corrélater avec les versions de l’application.
Considérations en matière de sécurité et de confidentialité 🔒
Les backends d’entreprise traitent des informations sensibles. La phase de conception de l’ERD doit tenir compte des exigences de sécurité et de confidentialité, en particulier en ce qui concerne les informations personnelles identifiables (PII).
Classification des données
- Données publiques :Informations pouvant être partagées librement. Aucune manipulation spéciale requise.
- Données internes :Informations destinées uniquement aux employés. Les listes de contrôle d’accès (ACL) doivent être prises en compte.
- Données restreintes :Données sensibles telles que les mots de passe, les dossiers médicaux ou les détails financiers. Ces champs nécessitent un chiffrement au repos et en transit.
Masquage et anonymisation
Dans l’ERD, indiquez les champs qui doivent être masqués dans les environnements non productifs. Cela aide les développeurs à comprendre quels colonnes nécessitent un traitement particulier lors des tests. Bien que le diagramme lui-même n’impose pas de sécurité, il guide la mise en œuvre des politiques de sécurité.
- Identifiez explicitement les colonnes contenant des PII.
- Définissez des champs d’audit (par exemple, dernier_modifié_par) pour suivre qui a accédé ou modifié les données.
- Assurez-vous que les clés étrangères ne révèlent pas d’identifiants internes pouvant être énumérés.
Planification des performances et de la scalabilité 🚀
Bien que l’ERD se concentre sur la structure, il doit également tenir compte des performances. Un schéma logiquement correct mais physiquement lent échouera sous charge.
Stratégie d’indexation
Les relations définies dans l’ERD déterminent où les index sont nécessaires. Les clés étrangères doivent être indexées pour accélérer les jointures et les vérifications de contraintes. Toutefois, un sur-indexage peut ralentir les opérations d’écriture.
- Clés primaires : Toujours indexées.
- Clés étrangères : Toujours indexées pour améliorer les performances des jointures.
- Colonnes de recherche : Les colonnes fréquemment utilisées dans les clauses WHERE doivent avoir des index.
Partitionnement et fractionnement
Pour les jeux de données massifs, le MCD pourrait suggérer des stratégies de partitionnement. Si les données sont naturellement regroupées (par exemple, par Région ou Date), cela doit être reflété dans la conception du schéma. Cela permet à la base de données de répartir la charge sur plusieurs nœuds physiques.
Péchés courants à éviter ⚠️
Même les équipes expérimentées commettent des erreurs. Reconnaître les schémas courants d’échec aide à construire un système résilient.
- Références circulaires : Évitez les relations où l’entité A dépend de B, et B dépend de A, créant ainsi une boucle qui complique la suppression ou la mise à jour des données.
- Contraintes manquantes : Compter sur le code de l’application pour appliquer des règles (par exemple, garantir qu’un Prix est positif) est risqué. Utilisez des contraintes CHECK dans la base de données.
- Surconception : Ne concevez pas chaque scénario futur possible. Concevez pour les besoins actuels avec une flexibilité suffisante pour s’adapter, mais évitez de créer des tables pour des cas d’utilisation hypothétiques.
- Valeurs codées en dur : Évitez de stocker les codes d’état sous forme d’entiers sans table de référence. Utilisez une table de référence pour les états tels que StatutCommande afin de maintenir la clarté.
Mettre en œuvre des normes dans votre flux de travail 🛠️
Adopter ces normes nécessite un changement de culture. Il ne suffit pas de dessiner simplement un schéma ; ce schéma doit piloter le processus de développement.
- Conception en premier : Exigez l’approbation du MCD avant d’écrire tout script de migration.
- Revue de code : Incluez les modifications de schéma dans la liste de contrôle standard de la revue de code.
- Formation : Assurez-vous que tous les ingénieurs backend comprennent les concepts de normalisation et de cardinalité.
- Outils : Investissez dans des outils de conception de schémas qui soutiennent la collaboration et la gestion de versions.
En traitant le diagramme d’entités et de relations comme un composant vivant et dynamique de l’architecture du système, les équipes d’entreprise peuvent garantir que leurs couches de données restent solides. L’effort investi dans la standardisation de la phase de conception porte ses fruits sous forme de dette technique réduite et d’une fiabilité du système améliorée. Une base de données bien structurée est le fondement sur lequel sont construites des applications évolutives.
Lorsque vous privilégiez la clarté, la cohérence et l’intégrité dans votre modélisation des données, vous créez une fondation qui soutient la croissance. Les normes décrites ici fournissent un cadre pour cette fondation. Leur application garantit que votre backend reste maintenable, sécurisé et efficace à mesure que votre organisation grandit.