











Concevoir un schéma de base de données robuste exige une précision. Le diagramme d’entité-association (ERD) sert de plan directeur pour cette structure, traduisant la logique métier complexe en un format visuel que les développeurs et les parties prenantes peuvent interpréter. Cependant, malgré leur utilité, les ERD deviennent fréquemment des sources de malentendus pendant la phase de modélisation. L’ambiguïté des symboles, l’interprétation erronée de la cardinalité et la confusion concernant les types d’attributs peuvent entraîner un important travail de reprise plus tard dans le cycle de développement.
Ce guide propose une analyse détaillée des composants spécifiques d’un ERD qui causent fréquemment des difficultés parmi les architectes et ingénieurs de bases de données. En clarifiant les distinctions entre entités fortes et faibles, en examinant les notations des relations et en analysant les classifications des attributs, nous pouvons réduire les erreurs et garantir que le modèle de données résultant reflète fidèlement les exigences opérationnelles.
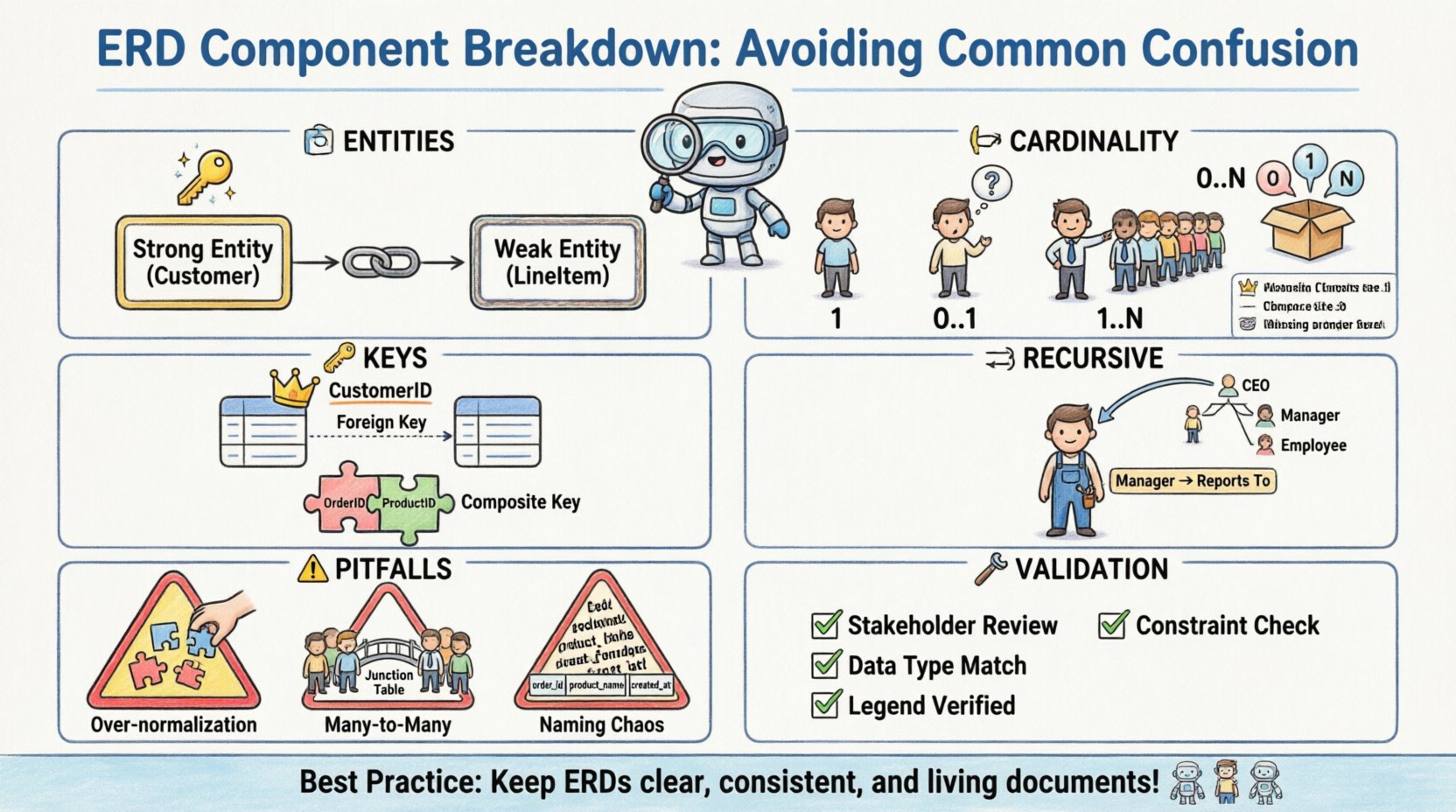
🏗️ Types d’entités : Différencier les entités fortes des entités faibles
Au cœur de tout ERD se trouvent les entités. Elles représentent les objets ou les concepts dont les données sont stockées. Bien que la plupart des praticiens comprennent le concept de table, la distinction entre entités fortes et faibles est là où surgit souvent le premier point majeur de confusion.
- Entités fortes : Ces entités possèdent leur propre clé primaire. Elles sont indépendantes et ne dépendent pas d’autres entités pour être identifiées. Par exemple, une entité
Clientpossède généralement un identifiant Client unique, ce qui en fait une entité forte. - Entités faibles : Ces entités ne peuvent pas être identifiées de manière unique par leurs propres attributs seuls. Elles dépendent d’une relation avec une autre entité, appelée parent identifiant, pour exister. Un
Articledans un système de commande pourrait exister uniquement dans le contexte d’unCommande.
La confusion provient souvent de la manière dont elles sont représentées visuellement. Une entité forte est généralement dessinée sous la forme d’un rectangle standard. Une entité faible est souvent représentée par un rectangle double. Le fait de ne pas distinguer visuellement ces deux types peut entraîner des erreurs d’implémentation de base de données où la table de l’entité faible est créée sans les contraintes de clé étrangère nécessaires pour imposer sa dépendance.
Implications de la mauvaise classification
Lorsqu’une entité faible est modélisée comme forte, la base de données peut autoriser l’existence de records sans parent. Cela crée des données orphelines. À l’inverse, modéliser une entité forte comme faible impose une dépendance inutile, pouvant limiter la faisabilité de l’entité en dehors de son contexte principal. Il est essentiel de déterminer si un objet peut exister de manière indépendante avant de lui attribuer un statut d’entité forte.
- Vérification d’indépendance : Ce record peut-il exister sans lien vers un autre record ?
- Source de l’identifiant : L’identifiant unique provient-il de l’entité elle-même ou de la relation ?
- Dépendance d’existence : La suppression du parent entraîne-t-elle automatiquement la suppression de l’enfant ?
🔗 Cardinalité et facultativité des relations
Les relations définissent la manière dont les entités interagissent. La cardinalité précise le nombre d’instances d’une entité qui peuvent ou doivent s’associer à chaque instance d’une autre entité. C’est peut-être la zone la plus courante de confusion en raison des styles de notation variés.
Notations de cardinalité
Il existe plusieurs façons de noter la cardinalité sur un diagramme. Certains utilisent des étiquettes textuelles comme « 1 » ou « N », tandis que d’autres utilisent la notation en pied de corbeau. Mélanger ces styles ou mal interpréter les symboles entraîne des lacunes logiques dans le schéma physique.
| Symbole / Étiquette | Signification | Scénario d’exemple |
|---|---|---|
| 1 | Exactement un | Une personne possède exactement un numéro de sécurité sociale. |
| 0..1 | Zéro ou un | Une personne peut avoir zéro ou un prénom intermédiaire. |
| 1..1 | Un et un seul | Un projet doit avoir un responsable de projet attribué. |
| 0..N | Zéro à plusieurs | Une commande peut avoir zéro ou plusieurs lignes de commande. |
| 1..N | Un à plusieurs | Un département doit avoir un ou plusieurs employés. |
Optionnalité et nullabilité
L’optionnalité fait référence au fait qu’une relation soit obligatoire ou facultative. Cela a directement un impact sur la définition de la clé étrangère dans la table de base de données. Si une relation est obligatoire, la colonne de clé étrangère ne peut pas être nulle. Si elle est facultative, elle peut être nulle.
La confusion survient souvent lorsque le diagramme montre une ligne pleine par rapport à une ligne pointillée. Sans légende claire, les développeurs peuvent supposer des relations obligatoires là où aucune n’existe, ce qui entraîne des violations de contraintes lors de l’entrée de données. Il est essentiel de documenter explicitement le sens des styles de ligne dans la documentation du modèle.
- Relation obligatoire : L’enregistrement enfant doit exister pour que l’enregistrement parent soit valide.
- Relation facultative : L’enregistrement enfant peut être créé sans parent, ou le parent peut exister sans enfant.
- Contrainte de clé étrangère : Doit être défini sur
NON NULLpour les relations obligatoires,NULLautorisé pour les relations facultatives.
🔑 Attributs et identification des clés
Les attributs sont les propriétés d’une entité. Bien qu’ils semblent simples, la classification des attributs en clés, clés étrangères et attributs simples entraîne fréquemment des erreurs lors de la normalisation et des performances des requêtes.
Clé primaire vs. Clé étrangère
La clé primaire (PK) identifie de manière unique une ligne. La clé étrangère (FK) lie une ligne à une table parente. La confusion survient lorsque des clés naturelles sont utilisées au lieu de clés surrogées, ou lorsque la PK n’est pas définie de manière cohérente sur l’ensemble du schéma.
- Clé naturelle :Une clé qui existe naturellement dans les données, comme un numéro de sécurité sociale ou une adresse e-mail. Elles peuvent changer, ce qui entraîne des problèmes d’intégrité.
- Clé surrogée :Une clé artificielle générée par le système, comme un entier auto-incrémenté. Elles sont généralement préférées pour leur stabilité.
Clés composées
Une clé composée est constituée de deux ou plusieurs colonnes qui, prises ensemble, identifient de manière unique un enregistrement. Cela est courant dans les tables d’association utilisées pour résoudre les relations many-to-many. La confusion provient ici de l’ordre des colonnes et de la table qui contient la clé.
Si l’ordre des colonnes dans une clé composée n’est pas maintenu de manière cohérente entre les tables liées, les jointures échoueront ou nécessiteront un casting complexe. Il est essentiel de documenter l’ordre exact des colonnes dans la définition de la clé primaire.
🔁 Relations récursives
Une relation récursive se produit lorsque une entité est liée à elle-même. Cela est fréquemment utilisé pour des structures hiérarchiques telles que les organigrammes ou les listes de matériaux. La confusion provient de la représentation visuelle, car la ligne relie l’entité à elle-même.
Sans étiquetage clair, il est souvent difficile de déterminer quel côté de la relation représente le parent et quel côté représente l’enfant. Par exemple, dans une table Employé, un employé gère un autre employé. La relation doit explicitement indiquer qu’un Employé peut être responsable d’autres Employés.
- Référence à soi-même : La clé étrangère dans la table fait référence à la clé primaire de la même table.
- Gestion des valeurs nulles : La racine de la hiérarchie a généralement une valeur nulle dans la colonne ID du gestionnaire.
- Limites de profondeur : Les requêtes récursives peuvent devenir des goulets d’étranglement de performance si la hiérarchie est très profonde.
⚠️ Pièges courants dans la modélisation
Au-delà des éléments spécifiques, certains schémas structurels entraînent souvent de la confusion lors de l’implémentation. Reconnaître ces pièges tôt permet d’éviter des migrations de schéma coûteuses.
1. Sur-normalisation
Bien que la normalisation réduise la redondance, une sur-normalisation peut rendre les requêtes difficiles à lire et à exécuter. Créer une table distincte pour chaque attribut peut fragmenter inutilement les données. Il est important de trouver un équilibre entre la troisième forme normale (3NF) et les performances pratiques des requêtes.
2. Many-to-Many sans tables d’association
Dans une base de données physique, une relation many-to-many ne peut pas exister directement. Elle doit être résolue en deux relations one-to-many à l’aide d’une table d’association (entité associative). Oublier cette étape conduit à un modèle qui ne peut pas être implémenté en SQL standard.
- Modèle logique vs. Modèle physique : Le modèle logique peut montrer une ligne directe entre deux entités avec une cardinalité N:N.
- Implémentation physique : Cette ligne doit être divisée par une nouvelle table contenant les clés étrangères des deux côtés.
3. Conventions de nommage incohérentes
Utiliser des styles de nommage mixtes (par exemple, customer_id vs CustomerID vs customerId) crée de la confusion pour les développeurs rédigeant des requêtes. Une convention de nommage standardisée doit être établie dès le début du projet.
- Minuscules avec des traits de soulignement :
order_line_items - PascalCase :
OrderLineItems - CamelCase :
orderLineItems
🛠️ Stratégies de validation
Pour garantir que le MCD reste précis et utilisable, des étapes de validation spécifiques doivent être effectuées pendant le processus de revue. Ces étapes aident à détecter les points de confusion avant que le schéma ne soit verrouillé.
- Passage en revue avec les parties prenantes : Revue du diagramme avec les utilisateurs métiers pour s’assurer que les relations correspondent à leur modèle mental du flux de travail.
- Vérification des contraintes : Vérifiez que chaque clé étrangère a une référence correspondante vers une clé primaire.
- Consistance des types de données : Assurez-vous que les attributs définis comme entiers dans une table ne sont pas définis comme chaînes dans une autre.
- Conformité à la légende : Vérifiez que tous les symboles utilisés dans le diagramme correspondent à la légende fournie ou à la norme.
📝 Résumé des meilleures pratiques
Maintenir la clarté dans un diagramme d’entités-relationships exige de la discipline. En respectant la notation standard, en définissant clairement la cardinalité et en distinguant les types d’entités, le risque d’interprétation erronée est considérablement réduit. L’objectif n’est pas seulement de dessiner une image, mais de créer une spécification qui se traduit directement en un système de base de données stable et fiable.
Souvenez-vous que le diagramme est un document vivant. À mesure que les exigences évoluent, le MCD doit être mis à jour pour refléter ces changements. Cela garantit que le modèle de données continue de servir de manière précise les besoins métiers au fil du temps. Les revues régulières et le respect des directives structurelles décrites dans cet article aideront les équipes à éviter les pièges courants qui compromettent les projets de bases de données.