











Concevoir une architecture de données robuste exige une compréhension approfondie de la manière dont les informations sont connectées, liées et persistantes. Au cœur de ce design se trouve le diagramme Entité-Relation (ERD). Bien que traditionnellement associé aux bases de données relationnelles, les sémantiques des ERD ont évolué pour répondre aux besoins diversifiés des environnements NoSQL modernes. Ce guide explore les subtilités de la modélisation des relations entre données à travers différents paradigmes de stockage, en assurant l’intégrité structurelle sans sacrifier les performances.
Concepts fondamentaux de la modélisation des données 🏗️
Avant de plonger dans les types spécifiques de bases de données, il est essentiel d’établir un vocabulaire commun. Un diagramme Entité-Relation sert de plan visuel. Il définit les entités (tables, collections ou documents), leurs attributs (colonnes, champs ou propriétés) et les relations qui les lient.
- Entité : Un objet ou un concept distinct au sein du domaine métier. Dans un contexte de base de données, cela pourrait être un Utilisateur, un Produit ou une Commande.
- Attribut : Une propriété qui décrit l’entité. Des exemples incluent id, nom, created_at, ou statut.
- Relation : L’association entre deux entités. Cela définit la manière dont les données d’une entité sont connectées aux données d’une autre.
- Cardinalité : L’aspect numérique d’une relation. Elle précise si une relation est un-à-un, un-à-plusieurs ou plusieurs-à-plusieurs.
Lors de la création d’un ERD, l’objectif est de représenter la logique du monde réel de l’application. Un diagramme bien construit réduit l’ambiguïté pour les développeurs et garantit que les requêtes peuvent être écrites de manière efficace ultérieurement dans le cycle de développement.
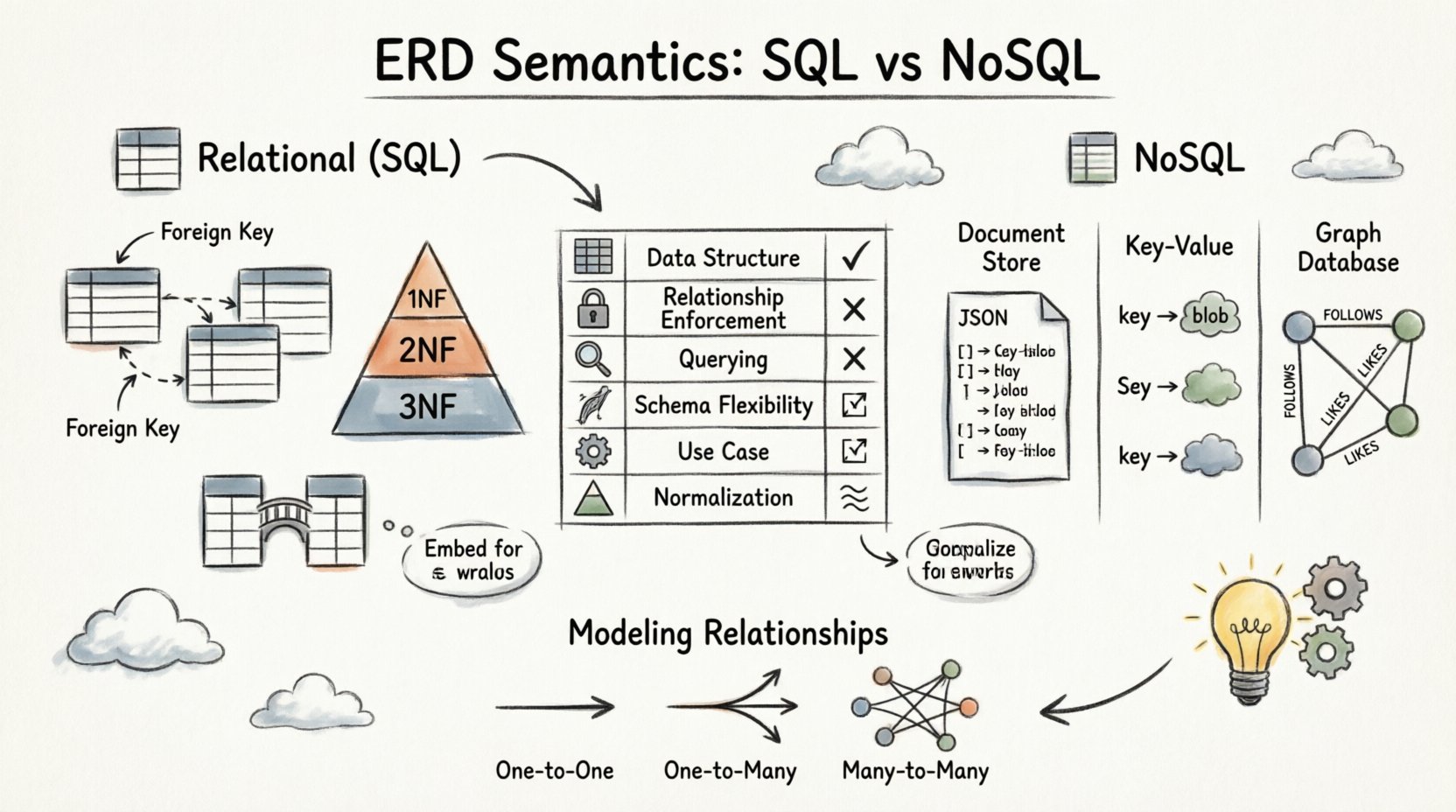
Sémantiques dans les environnements relationnels 🗃️
Dans le modèle relationnel, les données sont stockées dans des tables avec des schémas stricts. Les sémantiques de l’ERD ici sont rigides et régies par la théorie des ensembles et les principes de la première forme normale. Chaque relation est imposée par le moteur de base de données pour maintenir l’intégrité référentielle.
1. Le rôle des clés étrangères
Les clés étrangères sont le pilier des ERD relationnels. Elles lient physiquement les tables entre elles. Lorsqu’un ERD montre une ligne reliant deux tables, l’implémentation repose sur une colonne clé étrangère dans la table enfant qui fait référence à la clé primaire de la table parente.
- Implémentation : Une valeur numérique ou alphanumérique stockée dans une colonne.
- Contrainte : Le moteur de base de données empêche les enregistrements orphelins. Vous ne pouvez pas insérer une valeur dans une colonne clé étrangère à moins qu’elle n’existe pas dans la clé primaire référencée.
- Enchaînement : Les actions sur l’enregistrement parent (suppression ou mise à jour) peuvent se propager automatiquement aux enregistrements enfants en fonction des règles définies.
2. Normalisation et intégrité
Les diagrammes ER relationnels privilégient la normalisation. Ce processus réduit la redondance des données en organisant les attributs en groupes logiques. Un diagramme ER bien normalisé apparaît généralement plus complexe en raison du nombre de tables impliquées.
- 1NF : Assure l’atomicité ; chaque cellule contient une seule valeur.
- 2NF : Supprime les dépendances partielles ; les attributs dépendent de la clé primaire entière.
- 3NF : Supprime les dépendances transitives ; les attributs non clés dépendent uniquement de la clé primaire.
Cette structure garantit que les données sont cohérentes. Si un utilisateur change son nom, cela se met à jour à un seul endroit, et tous les enregistrements faisant référence à cet utilisateur voient le changement immédiatement.
3. Gestion des relations plusieurs-à-plusieurs
Les relations plusieurs-à-plusieurs sont sémantiquement distinctes dans les systèmes relationnels. Vous ne pouvez pas lier directement deux tables dans ce cas. En revanche, une table d’association intermédiaire est nécessaire.
- Structure : Une table contenant les clés primaires des deux entités associées.
- Fonction : Cette table agit comme un pont, permettant à plusieurs enregistrements de l’entité A de se lier à plusieurs enregistrements de l’entité B.
- Interrogation : Récupérer ces données nécessite une
JOINTUREopération, qui peut être coûteuse en termes de calcul sur de grandes ensembles de données si elle n’est pas correctement indexée.
Sémantique dans les environnements NoSQL 📦
Les bases de données NoSQL offrent de la flexibilité. La sémantique du diagramme ER passe du contrôle structurel à une représentation logique. Le diagramme devient davantage un guide de modèle de conception qu’une définition stricte de schéma. Les différents modèles NoSQL traitent les relations de manière différente.
1. Magasins de documents et intégration
Dans les bases de données orientées documents, les données sont stockées sous forme de documents similaires à JSON. Le diagramme ER suggère souvent d’intégrer les données associées directement dans un seul document afin d’optimiser les performances de lecture.
- Un-à-plusieurs : Un document parent peut contenir un tableau d’objets enfants. Cela évite la nécessité de jointures lors de la récupération.
- Implication : Les mises à jour des données enfants nécessitent la réécriture de l’ensemble du document parent. Cela peut entraîner une contention si le document parent devient très volumineux.
- Lecture vs. écriture : Cette approche optimise les lectures. Elle échange les performances d’écriture et la redondance des données contre la vitesse.
2. Magasins clé-valeur
Les magasins clé-valeur traitent les données comme des blocs opaques. Les sémantiques du MCD ici sont minimales. Les relations sont souvent déduites par la couche d’application plutôt que par le moteur de base de données.
- Référencement :Les documents contiennent souvent un identifiant de référence vers un autre document, similaire à une clé étrangère, mais sans contrainte d’application.
- Responsabilité :La logique de l’application doit garantir que l’identifiant référencé existe et est valide. Il n’existe aucune contrainte au niveau de la base de données.
- Cas d’utilisation :Idéal pour le cache, la gestion des sessions ou des structures de données très flexibles où les relations ne sont pas la préoccupation principale.
3. Bases de données orientées graphe
Les bases de données orientées graphe sont conçues spécifiquement pour les relations. Le MCD dans ce contexte se traduit directement par des nœuds et des arêtes. C’est peut-être l’interprétation la plus littérale d’un diagramme Entité-Relation.
- Nœuds :Représentent des entités (par exemple, Personne, Lieu).
- Arêtes :Représentent des relations (par exemple, HABITE_DANS, CONNAÎT).
- Propriétés :Les nœuds et les arêtes peuvent avoir des attributs associés.
- Parcours :Les requêtes suivent les arêtes. Une relation n’est pas une recherche ; c’est un parcours de chemin.
Analyse comparative des approches de modélisation 📊
Comprendre les différences entre ces environnements aide à choisir l’outil adapté. Le tableau suivant décrit comment les sémantiques du MCD se traduisent dans ces systèmes.
| Fonctionnalité | Relationnel (SQL) | Magasin de documents | Base de données orientée graphe |
|---|---|---|---|
| Structure de données | Tables avec lignes et colonnes | Documents JSON | Nœuds et arêtes |
| Application des relations | Clés étrangères (strictes) | Manuel / Niveau d’application | Références d’arêtes natives |
| Interrogation des relations | Opérations JOIN | Recherche ou intégration | Parcours de chemin |
| Flexibilité du schéma | Schéma fixe | Schéma dynamique | Semi-structuré |
| Cas d’utilisation principal | Intégrité des transactions | Gestion de contenu / Hiérarchies | Réseaux / Graphes sociaux |
| Normalisation | Élevée (3NF / FNBC) | Faible (dénormalisée) | Non applicable |
Modélisation des relations : une exploration approfondie 🔗
La manière dont les relations sont représentées dans un MCD détermine les modèles de requêtes et les caractéristiques de performance de l’application. Examinons en détail des cardinalités spécifiques.
Relations un-à-un
Il s’agit de la relation la plus simple. Un enregistrement dans la table A correspond exactement à un enregistrement dans la table B.
- Implémentation SQL : Une clé étrangère dans l’une des deux tables avec une contrainte d’unicité.
- Implémentation NoSQL : Souvent fusionnés dans un seul document pour éviter les recherches, ou stockés séparément avec une référence unique.
- Quand l’utiliser : Profils d’utilisateurs séparés des détails d’authentification, ou paramètres de configuration liés à des environnements spécifiques.
Relations un-à-plusieurs
Il s’agit du type de relation le plus courant. Un enregistrement dans la table A est lié à de nombreux enregistrements dans la table B.
- Implémentation SQL : Une clé étrangère dans la table B faisant référence à la table A.
- Magasin de documents : Intégrez le côté « Many » à l’intérieur du document du côté « One » sous forme de tableau. Cela est efficace pour lire toute la hiérarchie d’un coup.
- Base de données orientée graphe : Créez une arête depuis le nœud « One » vers plusieurs nœuds « Many ».
- Considération : Si le côté « Many » croît considérablement, l’intégration dans un magasin de documents peut atteindre les limites de stockage. Une approche hybride (références au lieu d’intégration) pourrait être nécessaire.
Relations plusieurs-à-plusieurs
Cette relation nécessite un pont en SQL, mais se comporte différemment dans d’autres systèmes.
- Implémentation SQL : Une table de jonction contenant les identifiants des deux tables parentes.
- Magasin de documents : Souvent dénormalisé. Chaque document contient une liste d’identifiants ou d’objets complets provenant de l’entité associée. Cela duplique les données mais accélère la récupération.
- Base de données orientée graphe : C’est la force naturelle du modèle. Les nœuds sont directement connectés sans table intermédiaire.
- Défi de cohérence : Dans les magasins de documents, maintenir les listes synchronisées sur plusieurs documents est difficile. Les mises à jour d’une entité partagée doivent être propagées manuellement à tous les documents qui y font référence.
Évolution du schéma et flexibilité 🔄
Les exigences logicielles évoluent. Les modèles de données doivent évoluer sans casser les applications existantes. Les sémantiques du MCD dictent à quel point cette évolution peut être facile.
1. Migration de schéma en SQL
Modifier un schéma relationnel est une opération importante. Elle implique souvent le verrouillage des tables ou l’exécution de migrations pendant une période d’indisponibilité.
- Ajout de colonnes : Généralement sûr et rapide.
- Renommage de colonnes : Exige de réécrire la structure de la table et de mettre à jour toutes les requêtes dépendantes.
- Changement de type de données : Peut être risqué si la conversion des données échoue ou si la logique de l’application dépend du type ancien.
2. Flexibilité du schéma en NoSQL
Les systèmes NoSQL permettent généralement des approches sans schéma ou avec schéma à la lecture. Le MCD est une orientation plutôt qu’une loi.
- Ajout de champs : Vous pouvez ajouter de nouveaux champs à des documents spécifiques sans affecter les autres.
- Gestion des versions : Il est courant d’ajouter des numéros de version aux documents pour gérer différentes structures au fil du temps.
- Compromis : Le manque de contrôle signifie que des problèmes de qualité des données peuvent survenir. L’application doit valider les données avant d’écrire.
Implications sur les performances des choix de modélisation ⚡
La structure de votre schéma ER a une influence directe sur la vitesse des requêtes. Il n’existe pas de solution universelle ; la conception doit correspondre aux schémas d’accès de l’application.
1. Charges de lecture importantes
Si l’application lit souvent les données mais met à jour rarement, la dénormalisation est avantageuse.
- Stratégie :Intégrer les données associées pour réduire le nombre de requêtes nécessaires.
- Avantage :Moins d’opérations d’E/S et latence réduite.
- Coût :Utilisation accrue du stockage et logique de mise à jour complexe.
2. Charges d’écriture importantes
Si l’application met fréquemment à jour les données, la normalisation ou un stockage séparé est préférée.
- Stratégie :Stockez les données sous leur forme la plus atomique et effectuez les jointures ou références au moment de la requête.
- Avantage :Source unique de vérité ; les mises à jour ont lieu à un seul endroit.
- Coût :Latence de lecture plus élevée en raison des jointures ou des recherches multiples.
3. Stratégies d’indexation
Quel que soit le type de base de données, le schéma ER indique où les index sont nécessaires.
- Relationnel :Les index sont placés sur les clés étrangères et les colonnes utilisées dans
WHEREclauses. - Document : Les index sont placés sur les champs qui sont fréquemment interrogés. Les champs imbriqués peuvent nécessiter une syntaxe d’indexation spécifique.
- Graphique : Les index sont placés sur les étiquettes des nœuds et les propriétés des arêtes pour accélérer les points de départ des parcours.
Environnements hybrides et persistance polyglotte 🧩
Les architectures modernes utilisent souvent plusieurs technologies de bases de données simultanément. Cela s’appelle la persistance polyglotte. Les sémantiques du MCD doivent combler ces écarts.
1. Modèles de cohérence des données
Lorsque les données s’étendent sur plusieurs systèmes, la cohérence devient complexe.
- ACID : Les bases de données relationnelles offrent une cohérence forte. Les transactions s’étendent sur plusieurs tables au sein de la même base de données.
- BASE : Les bases de données NoSQL privilégient souvent la disponibilité et la cohérence éventuelle. Les transactions peuvent être limitées à un seul document.
- Modèle Saga : Pour les transactions distribuées à travers les systèmes, un modèle saga gère les opérations longues en coordonnant des transactions locales.
2. Le rôle du MCD dans les systèmes hybrides
Le MCD agit comme une carte conceptuelle. Il définit les relations logiques, même si le stockage physique diffère.
- Mappage :Les développeurs utilisent le MCD pour décider quelles données vont dans quel magasin.
- Intégration : Le schéma aide à visualiser où la synchronisation des données est nécessaire entre les systèmes.
- Documentation : Il fournit une vue unifiée pour les parties prenantes qui pourraient ne pas comprendre les différences techniques entre les moteurs de stockage.
Meilleures pratiques pour un modèle de données robuste 🛡️
Pour garantir la maintenabilité et les performances à long terme, respectez ces principes lors de la conception de vos MCD.
- Comprenez le domaine :Commencez par les exigences métiers. Ne modélisez pas les données qui ne soutiennent pas un cas d’utilisation spécifique.
- Choisissez l’outil adapté :Choisissez le type de base de données en fonction des relations entre les données, et non seulement en fonction des tendances. Utilisez les graphes pour les réseaux complexes, les documents pour le contenu, et SQL pour les transactions.
- Documentez les relations explicitement :Marquez clairement la cardinalité sur le schéma. L’ambiguïté conduit à des erreurs d’implémentation.
- Prévoir la croissance : Pensez à la manière dont le volume de données évoluera. Un tableau intégré deviendra-t-il trop volumineux ? Une table de jonction deviendra-t-elle un goulot d’étranglement ?
- Itérer sur la conception :Les diagrammes ER ne sont pas statiques. Affinez-les au fur et à mesure que l’application évolue et que de nouvelles contraintes sont découvertes.
- Valider au niveau de la couche application : En particulier dans les systèmes NoSQL, mettez en œuvre une logique de validation pour garantir l’intégrité des données, car la base de données peut ne pas l’assurer.
Conclusion sur les sémantiques de modélisation 📝
Les sémantiques d’un diagramme Entité-Relation ne sont pas universelles ; elles s’adaptent à la technologie de stockage sous-jacente. Dans les systèmes relationnels, le diagramme ER est un contrat imposé par le moteur de base de données. Dans les systèmes NoSQL, il s’agit d’une référence de conception pour la couche application. Comprendre ces différences permet aux architectes de concevoir des systèmes à la fois évolutifs et cohérents.
En analysant soigneusement la cardinalité, en choisissant le modèle de stockage approprié et en anticipant les évolutions futures, les équipes peuvent construire des couches de données capables de soutenir des logiques métier complexes sans compromettre les performances. L’essentiel réside dans l’alignement du modèle logique sur les capacités physiques de l’environnement choisi.
Qu’il s’agisse de tables, de documents ou de graphes, les principes fondamentaux de l’identification des entités et de la définition de leurs connexions restent constants. Un diagramme ER clair sert de fondement à une architecture logicielle fiable, comblant le fossé entre les exigences métiers et la mise en œuvre technique.