











Dans le paysage de l’analyse système et de la modélisation des processus métiers, la clarté est primordiale. Un diagramme de flux de données (DFD) sert de plan visuel indiquant comment les informations circulent dans un système. Contrairement aux organigrammes qui représentent le flux de contrôle, les DFD se concentrent spécifiquement sur la transformation des données, leur stockage et leurs interactions externes. Ce guide explore l’application pratique des DFD dans divers secteurs, offrant une compréhension approfondie de leur construction et de leur utilité sans dépendre d’outils logiciels spécifiques.
Comprendre les mécanismes du déplacement des données permet aux architectes d’identifier les goulets d’étranglement, de garantir la conformité en matière de sécurité et d’optimiser les opérations. En examinant des scénarios du monde réel, nous pouvons voir comment des symboles abstraits se traduisent en conceptions fonctionnelles de systèmes. Cette ressource couvre les concepts fondamentaux, des études de cas détaillées et des bonnes pratiques essentielles pour créer des diagrammes efficaces.
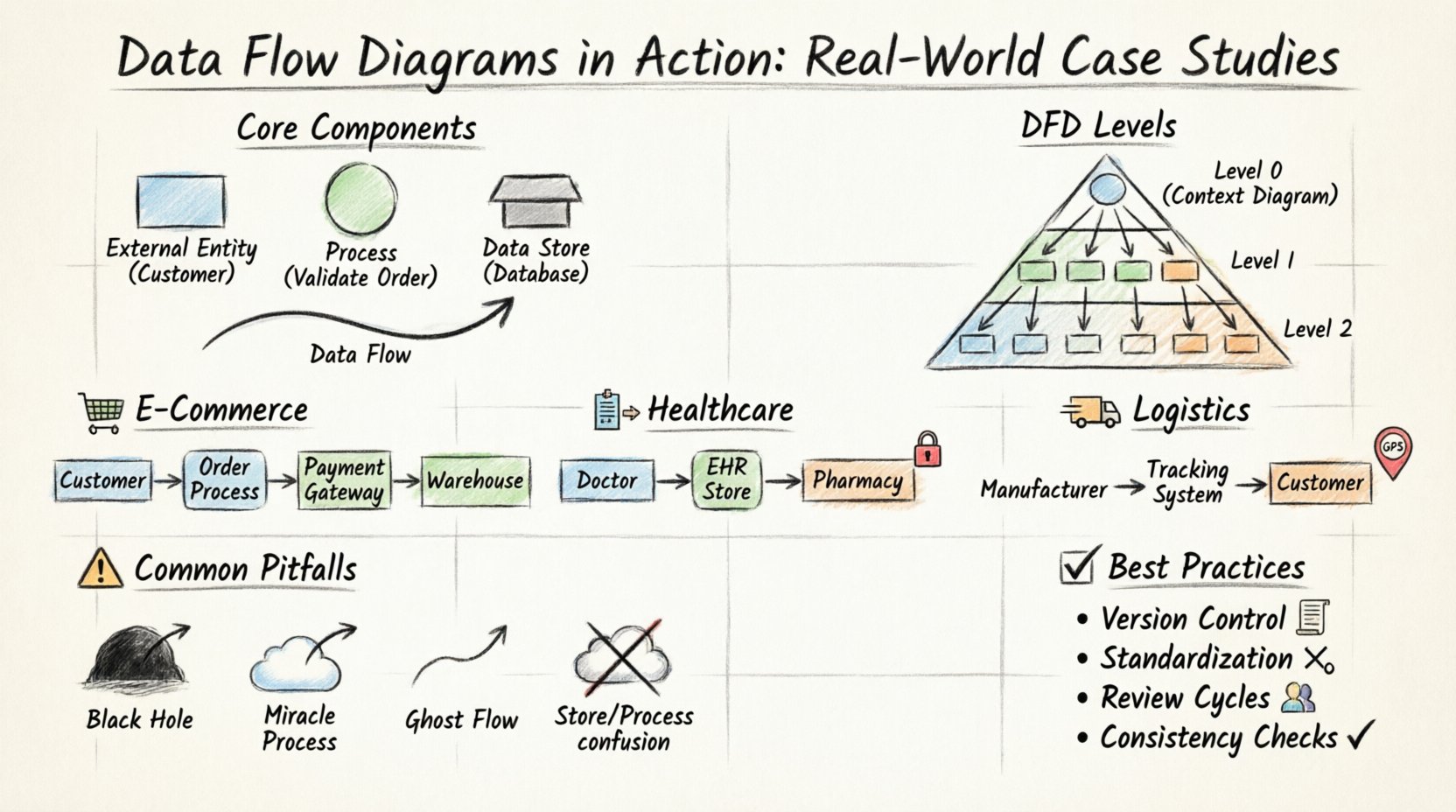
Composants fondamentaux d’un diagramme de flux de données 🧩
Avant de plonger dans des scénarios complexes, il est essentiel d’établir un vocabulaire commun. Un DFD est composé de quatre éléments principaux. Chaque élément représente une fonction spécifique au sein de l’écosystème des données. La confusion entre ces symboles peut entraîner une mauvaise interprétation de la logique du système.
- Entité externe : Une source ou une destination externe de données. Cela peut être une personne, une organisation ou un autre système.
- Processus : Une transformation ou un calcul effectué sur les données. Il transforme les entrées en sorties.
- Stockage de données : Un répertoire où les données sont conservées pour une récupération ultérieure. Cela représente des bases de données, des fichiers ou des journaux.
- Flux de données : Le déplacement des données entre les entités, les processus et les stockages. Les flèches indiquent la direction.
Tableau de référence des symboles 📋
| Élément | Forme | Fonction | Exemple |
|---|---|---|---|
| Entité externe | Rectangle | Source/Puisard | Client, Fournisseur |
| Processus | Cercle/Rectangle arrondi | Transformation | Calculer la taxe, Valider la connexion |
| Stockage de données | Rectangle ouvert | Stockage | Base de données des commandes, Profil utilisateur |
| Flux de données | Flèche | Déplacement | Informations de paiement, demande d’expédition |
Comprendre les niveaux des diagrammes de flux de données 📉
Les systèmes complexes ne peuvent pas être représentés dans une seule vue. Pour maintenir la clarté, les diagrammes de flux de données sont décomposés en niveaux. Cette hiérarchie permet aux parties prenantes de voir le tableau global avant d’examiner les détails précis.
- Diagramme de contexte (Niveau 0) : La vue au plus haut niveau. Il montre le système comme un seul processus et son interaction avec les entités externes. Aucun stockage interne de données n’est visible.
- Diagramme de niveau 1 : Découpe le processus principal en sous-processus majeurs. Les stockages de données sont introduits.
- Diagramme de niveau 2 : Découpage supplémentaire des processus du niveau 1. Utilisé pour les spécifications détaillées de conception.
La cohérence est essentielle. Chaque flux de données entrant dans un processus de niveau 1 doit apparaître dans le diagramme de contexte. De même, les entrées et sorties doivent correspondre entre les diagrammes parent et enfant. Cela garantit l’intégrité du modèle tout au long du processus de décomposition.
Étude de cas 1 : Traitement des commandes e-commerce 🛒
L’une des applications les plus courantes des diagrammes de flux de données est sur les plateformes e-commerce. Le flux de traitement des commandes implique plusieurs points d’interaction, de la navigation à la livraison. Un diagramme solide garantit que les données clients sont traitées en toute sécurité et que le stock est mis à jour avec précision.
Contexte du système (Niveau 0)
La frontière du système englobe l’ensemble de la plateforme de gestion des commandes. Les entités externes incluent le Client, la passerelle de paiement et le système de stockage. Le flux principal de données commence lorsque le client passe une commande.
- Client : Envoie les détails de la commande et les informations de paiement.
- Système : Traite le paiement et demande l’expédition.
- Entrepôt : Reçoit les instructions d’expédition et confirme l’envoi.
Décomposition au niveau 1
À ce niveau, le processus unique est divisé en quatre fonctions distinctes. Cela révèle où les données sont stockées et comment elles changent d’état.
- Valider la commande : Vérifie la disponibilité du stock et les détails du client.
- Traiter le paiement : Communique avec la passerelle de paiement.
- Créer une facture : Génère un enregistrement pour la transaction.
- Mise à jour du stock :Réduit le comptage des stocks en fonction de l’état de la commande.
Analyse des flux de données
Pensez au flux des données sensibles. Les informations de paiement entrent dans le Traitement du paiementbulle mais n’interagit jamais avec le Création de la factureprocessus directement. Il va vers un stockage sécurisé Journal des transactionsstock. Cette séparation des préoccupations est essentielle pour le respect des réglementations.
- Entrée :Numéro de carte de crédit, identifiant de commande.
- Sortie :Statut de la transaction, reçu.
- Stockage :Journal des transactions chiffré, base de données client.
Les erreurs dans ce diagramme se manifestent souvent par des flux de données orphelins. Par exemple, si une commande est annulée, les données doivent revenir au stock de gestion des stocks pour restaurer les niveaux de stock. Si ce flux est manquant, des incohérences dans le stock apparaissent.
Étude de cas 2 : Gestion des patients dans le secteur de la santé 🏥
Les systèmes de santé exigent une sécurité et une précision accrues. La confidentialité des données n’est pas facultative ; elle est une exigence réglementaire. Un diagramme de flux de données ici doit clairement délimiter qui peut accéder à quelles données.
Défis clés
Dans cet environnement, la distinction entre un Processuset un Stockage de donnéesest vitale. Les dossiers médicaux sensibles doivent rester stockés jusqu’à ce qu’un processus d’autorisation spécifique les récupère.
- Entités :Médecin, Patient, Assurance, Laboratoire.
- Processus :Diagnostic, Prescription, Facturation, Demande de laboratoire.
- Magasins : Dossier de santé électronique (DSE), Livre de facturation, Résultats d’analyses.
Logique du flux
Le flux de données pour une ordonnance implique plusieurs étapes. Le médecin saisit une demande, qui est transmise à un Processus de vérification. Ce processus vérifie les interactions médicamenteuses par rapport à l’historique du patient dans le magasin DSE. Seulement après validation, les données sont transmises au Pharmacie.
Voici une analyse des chemins critiques :
- Flux d’admission : Informations du patient → Processus d’enregistrement → Magasin du profil du patient.
- Flux de consultation : Symptômes → Processus de diagnostic → Magasin des antécédents médicaux.
- Flux d’ordonnance : Médicament → Interface pharmacie → Magasin des stocks.
Un piège courant dans les schémas DFD de santé est l’absence de traces d’audit. Chaque modification apportée à un magasin de données doit être accompagnée d’un flux de données correspondant indiquant la source du changement. Cela permet de garantir la responsabilité en cas de modification d’un enregistrement.
Considérations de sécurité
Tous les flux de données ne sont pas équivalents. Certains sont marqués comme Public, tandis que d’autres sont Confidentiel. Le schéma doit représenter visuellement ces distinctions. Par exemple, l’assureur reçoit les données de facturation mais pas les notes cliniques. Cette séparation logique empêche tout accès non autorisé.
Étude de cas 3 : Logistique de la chaîne d’approvisionnement 🚚
La logistique consiste à suivre les marchandises physiques à travers des systèmes numériques. Le schéma DFD ici se concentre sur les mises à jour d’état et les données de localisation. La complexité réside dans la nature en temps réel des données.
Portée du système
Le système suit les marchandises du fabricant jusqu’au point de livraison final. Les entités clés incluent le Fabricant, le Transporteur, le Centre de distribution et le Client.
Découpage des processus
- Expédier la commande : Déclenche le déplacement des marchandises.
- Suivre la localisation : Met à jour la position actuelle du colis.
- Confirmer la livraison :Finalise la transaction.
Dynamique des flux de données
Dans la logistique, les flux de données sont souvent asynchrones. Un camion peut envoyer une mise à jour de localisation qui est stockée temporairement jusqu’à ce que le système la traite. Cela nécessite un mécanisme de tamponnage dans la conception du magasin de données.
| Étape | Données d’entrée | Traitement | Données de sortie |
|---|---|---|---|
| Expédition | ID de commande, Adresse | Calcul de trajet | Numéro de suivi |
| En transit | Coordonnées GPS | Mise à jour de position | Journal d’état |
| Livraison | Numérisation de signature | Vérification de complétion | Confirmation de livraison |
Un aspect critique de ce diagramme est la gestion des erreurs. Si un colis est perdu, le flux de données doit déclencher une Alerte de divergence. Cette alerte est un flux de données qui passe de la Boutique de suivi au Équipe d’assistance entité.
Péchés courants dans la conception des diagrammes de flux de données ⚠️
Même les analystes expérimentés commettent des erreurs. Identifier ces erreurs courantes tôt permet d’économiser un temps considérable pendant la phase de développement.
1. Trou noirs
Un trou noir est un processus qui a des entrées mais aucune sortie. Les données entrent, mais rien ne se produit. Dans un diagramme de flux de données (DFD), cela indique une erreur logique. Chaque processus doit produire un résultat, même s’il s’agit d’un message d’erreur.
2. Processus miracles
L’inverse d’un trou noir est un processus miracle. Il a des sorties mais aucune entrée. Cela implique que des données sont générées à partir de rien. Chaque sortie doit être retracée jusqu’à une source d’entrée spécifique.
3. Flux fantômes
Cela se produit lorsque des flux de données sont dessinés mais jamais réellement utilisés ou stockés. Cela encombre le diagramme et confond les parties prenantes. Revoyez chaque flèche pour vous assurer qu’elle a une fonction.
4. Confusion autour des magasins de données
Ne confondez pas un processus avec un magasin de données. Un processus modifie les données ; un magasin les conserve. Une erreur courante consiste à dessiner un processus à l’intérieur d’un magasin de données ou inversement. Cela floute la distinction entre transformation et conservation.
Meilleures pratiques pour la maintenance 🛠️
Un DFD n’est pas un artefact ponctuel. Il doit évoluer avec le système. À mesure que les exigences changent, le diagramme doit être mis à jour pour refléter la nouvelle réalité.
- Contrôle de version : Gardez une trace des versions du diagramme. Les modifications doivent être documentées avec des dates et des raisons.
- Standardisation : Utilisez des conventions de nommage cohérentes pour les processus et les magasins.Obtenir les informations utilisateur et Récupérer les données utilisateurdoivent être le même processus.
- Cycles de revue : Effectuez des revues régulières avec les parties prenantes. Les règles métier changent souvent plus vite que le code.
- Vérifications de cohérence : Assurez-vous que les diagrammes enfants correspondent aux diagrammes parents en termes d’entrées et de sorties. Cela s’appelle l’équilibrage.
Intégration des DFD avec d’autres modèles 🔗
Les DFD n’existent pas en isolation. Ils fonctionnent le mieux lorsqu’ils sont intégrés à d’autres techniques de modélisation. Cela fournit une vue d’ensemble du système.
DFD par rapport au diagramme entité-association (ERD)
Alors que les DFD montrent le déplacement des données, les ERD montrent leur structure. Utiliser les deux garantit que le flux logique correspond à la conception physique de la base de données. Par exemple, une entité Client dans un ERD doit correspondre à un magasin de données Client dans le DFD.
Diagrammes DFD vs. diagrammes de cas d’utilisation
Les diagrammes de cas d’utilisation se concentrent sur les interactions utilisateur. Les DFD se concentrent sur le déplacement des données. Ensemble, ils expliquentquifait quoiet commentles données soutiennent cette action.
Considérations finales pour les architectes de systèmes 🏛️
La création d’un diagramme de flux de données est un exercice de communication. Il traduit la logique complexe en une langue visuelle que les équipes techniques et non techniques peuvent comprendre. La valeur réside dans l’analyse, et non seulement dans le dessin.
Lors de la revue d’un DFD, posez-vous ces questions :
- Tous les points de données sont-ils pris en compte ?
- Y a-t-il des flux de données non autorisés ?
- Le diagramme reflète-t-il les règles métier réelles ?
- Le niveau de détail est-il adapté au public cible ?
En suivant ces principes, vous assurez que la conception du système est robuste, sécurisée et efficace. Le diagramme devient un document vivant qui guide le développement et la maintenance bien au-delà de la phase initiale de conception.
Résumé des points clés à retenir 📝
- Structure : Utilisez les diagrammes de contexte, de niveau 1 et de niveau 2 pour établir une hiérarchie.
- Précision : Assurez-vous que toutes les entrées ont des sorties et réciproquement.
- Sécurité : Représentez explicitement la sensibilité des données et les contrôles d’accès.
- Conformité : Maintenez une cohérence entre les diagrammes et le comportement réel du système.
Le parcours du concept à la mise en œuvre est pavé de documentation claire. Les diagrammes de flux de données fournissent la carte routière nécessaire pour naviguer dans des architectures système complexes. En appliquant ces études de cas du monde réel et en respectant les bonnes pratiques, vous pouvez construire des systèmes qui sont non seulement fonctionnels, mais aussi maintenables et sécurisés.