











Dans le monde de l’architecture logicielle, peu de concepts ont autant d’importance qu’un diagramme d’entités et de relations (ERD). Il constitue le plan directeur de vos données, la carte qui guide les développeurs à travers le paysage complexe des tables, des clés et des relations. Lorsqu’une application ralentit, la première réaction est souvent de rejeter la faute sur le schéma. L’hypothèse est claire : si le diagramme est parfait, la performance doit l’être aussi.
Il s’agit d’une méprise courante. 🧐 Bien qu’un ERD bien conçu soit fondamental, il n’est pas une solution miracle pour la vitesse. Un modèle logique parfait ne se traduit pas automatiquement par une exécution physique rapide. Comprendre l’écart entre la théorie du design et la réalité d’exécution est crucial pour concevoir des systèmes qui restent réactifs sous pression.
Ce guide explore pourquoi un ERD parfait ne garantit pas des temps de réponse rapides et quels autres facteurs critiques influencent les performances de la base de données. Nous analyserons les couches du traitement des données, des moteurs de stockage à la latence réseau, afin de révéler les véritables moteurs de la vitesse de l’application.
📐 Comprendre le diagramme d’entités et de relations
Avant de plonger dans les métriques de performance, nous devons clarifier ce qu’un ERD représente réellement. Un ERD est un artefact logique. Il décritce quiexiste etcommentil se rapporte à d’autres données. Il définit les entités (tables), les attributs (colonnes) et les relations (clés étrangères).
- Entités :Objets du monde réel représentés sous forme de tables.
- Attributs :Caractéristiques de ces objets stockées dans des colonnes.
- Relations :Les liens entre les entités, souvent assurés par des clés primaires et étrangères.
- Cardinalité :La relation numérique entre les entités (un-à-un, un-à-plusieurs).
L’objectif principal d’un ERD est l’intégrité des données. Il garantit que les données restent cohérentes, précises et utilisables dans le temps. Il empêche les enregistrements orphelins et maintient l’intégrité référentielle. Toutefois, l’intégrité n’est pas équivalente à la vitesse. Un verrou qui tient une porte fermée protège le contenu à l’intérieur, mais il ne rend pas la porte plus rapide à ouvrir.
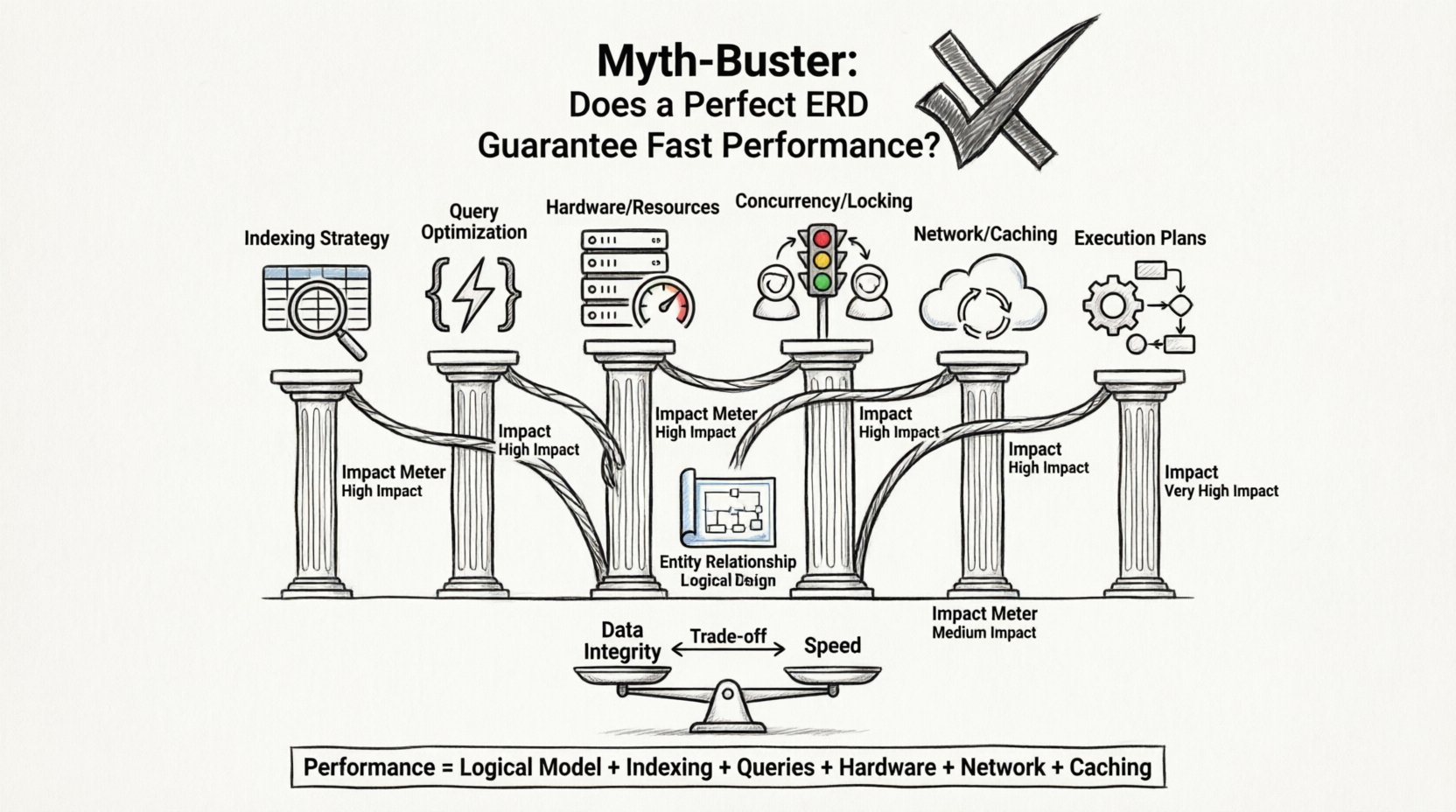
⚡ L’équation des performances : au-delà du schéma
Le temps de réponse de l’application est la somme de nombreuses composantes. La base de données n’est qu’une partie de cette équation. Même si le moteur de base de données récupère les données instantanément, l’application peut encore sembler lente en raison de goulets d’étranglement ailleurs.
Voici les facteurs clés qui influencent la vitesse, souvent en occultant la conception du schéma :
1. Stratégie d’indexation
Un ERD définit les clés primaires et les clés étrangères, qui génèrent souvent des index automatiquement. Toutefois, ces index par défaut sont rarement suffisants pour les requêtes complexes. Les performances dépendent fortement des index secondaires adaptés à des modèles de requêtes spécifiques.
- Index manquants :Sans index sur une colonne fréquemment filtrée, la base de données doit effectuer un balayage complet de la table. Cela lit chaque ligne, ce qui est exponentiellement plus lent sur de grandes quantités de données.
- Surcharge des index :Trop d’index ralentissent les opérations d’écriture. Chaque insertion ou mise à jour nécessite la mise à jour de chaque index associé à cette table.
- Sélectivité :Un index sur une colonne à faible sélectivité (par exemple, sexe ou statut) peut être ignoré par l’optimiseur de requêtes.
2. Optimisation des requêtes
La manière dont les données sont demandées est plus importante que la manière dont elles sont stockées. Une requête mal rédigée peut paralyser un schéma parfait. Les problèmes courants incluent :
- Problèmes N+1 :Récupérer un enregistrement parent, puis parcourir celui-ci en boucle pour récupérer individuellement les enfants. Cela génère plusieurs allers-retours vers la base de données au lieu d’une seule jointure.
- Utilisation de SELECT * :Récupérer toutes les colonnes augmente le trafic réseau et l’utilisation de la mémoire, même si une seule colonne est nécessaire.
- Conversions implicites :Comparer une chaîne à un nombre ou une date à une horodatage peut empêcher l’utilisation des index.
- Jointures complexes :Faire des jointures sur plusieurs grandes tables sans filtrage approprié augmente considérablement la charge de calcul.
3. Matériel et infrastructure
L’efficacité logicielle ne peut pas surmonter les limitations physiques. Le matériel sous-jacent fixe le plafond de performance.
- Type de stockage :Les disques SSD sont nettement plus rapides que les disques HDD pour les opérations d’E/S aléatoires.
- Mémoire (RAM) :Si l’ensemble de données en cours d’utilisation tient en mémoire vive, les requêtes sont presque instantanées. Si les données doivent être récupérées depuis le disque, la latence augmente.
- Puissance du processeur :Les calculs complexes, le tri et l’agrégation nécessitent une puissance de traitement.
- Latence du réseau :La distance entre le serveur d’application et le serveur de base de données ajoute des millisecondes à chaque requête.
4. Concurrence et verrouillage
Lorsque plusieurs utilisateurs accèdent au système simultanément, la base de données doit gérer les conflits. C’est là que les performances dégradent souvent.
- Contestation de verrous :Si une transaction détient un verrou sur une ligne, les autres doivent attendre. Une forte contention entraîne des délais d’attente et des temps de réponse lents.
- Interblocages :Deux transactions en attente l’une de l’autre peuvent provoquer une paralysie du système.
- Niveaux d’isolement :Les niveaux d’isolement plus élevés (par exemple, Sérieable) offrent des garanties plus fortes mais réduisent la concurrence et la vitesse.
📊 Impact du MCD par rapport aux autres facteurs de performance
Pour visualiser l’influence du MCD par rapport aux autres variables, considérez le découpage suivant. Ce tableau met en évidence où le MCD apporte de la valeur et où il est insuffisant.
| Facteur | Impact sur la vitesse de lecture | Impact sur la vitesse d’écriture | Rôle du schéma ER |
|---|---|---|---|
| Structure du schéma de table | Moyen | Moyen | Définit les relations et la normalisation. |
| Indexation | Élevé | Faible | Le schéma ER définit les clés, mais pas tous les index. |
| Logique des requêtes | Très élevé | Moyen | Le schéma ER ne dicte pas la syntaxe des requêtes. |
| Ressources matérielles | Élevé | Élevé | Aucun. Indépendant du schéma. |
| Latence du réseau | Élevé | Moyen | Aucun. Indépendant du schéma. |
| Pool de connexions | Moyen | Moyen | Aucun. Configuration de l’application. |
🧱 Le compromis de normalisation
L’un des sujets les plus controversés dans la conception de bases de données est la normalisation. Le schéma ER vise généralement la Troisième Forme Normale (3FN) afin de réduire la redondance. Bien que cela économise de l’espace et assure la cohérence, cela peut nuire aux performances.
Lorsque les données sont fortement normalisées, une seule pièce d’information est stockée à un endroit. Pour la récupérer, le système doit parcourir plusieurs JOIN. Chaque JOIN ajoute une surcharge computationnelle.
Pensez à un scénario où vous devez afficher le profil d’un utilisateur accompagné de sa dernière commande et des détails du produit. Dans un ERD normalisé, cela pourrait nécessiter la jointure de quatre tables. Si ces tables sont grandes, le CPU passe un temps considérable à trier et à correspondre les lignes.
Dénormalisation est une technique utilisée pour contrer ce problème. Elle consiste à dupliquer des données afin de réduire le besoin de JOIN. Cela améliore la vitesse de lecture, mais complique les opérations d’écriture et expose à des risques d’incohérence des données. Un ERD parfait ne décide pas automatiquement où tracer cette ligne. Il s’agit d’une décision stratégique basée sur les rapports lecture/écriture.
🔍 Approfondissement : Plans d’exécution des requêtes
Le moteur de base de données n’exécute pas les requêtes exactement comme elles sont écrites. Il analyse la requête et génère un Plan d’exécution. Ce plan détermine l’ordre des opérations, les index à utiliser, et si effectuer un balayage ou une recherche.
Un ERD fournit des métadonnées sur les types de données et les contraintes. Toutefois, l’optimiseur utilise des statistiques sur la distribution des données pour prendre des décisions. Si les statistiques sont obsolètes, l’optimiseur pourrait choisir un plan sous-optimal, en ignorant les meilleurs index disponibles.
Par exemple, si une table contient 10 millions de lignes mais que les statistiques pensent qu’elle en contient 100, l’optimiseur pourrait décider qu’un balayage complet est moins coûteux qu’une recherche d’index. Cela entraîne des performances lentes malgré un ERD bien structuré.
🛡️ Intégrité des données vs. Vitesse
Il existe une tension inhérente entre garantir l’intégrité des données et maximiser la vitesse. Un ERD impose des règles d’intégrité telles que les contraintes et les déclencheurs.
- Contraintes de clé étrangère :Assurent l’intégrité référentielle. En cas de suppression ou de mise à jour, le système doit vérifier les tables associées. Cela ajoute une latence aux opérations d’écriture.
- Déclencheurs :Scripts automatisés qui s’exécutent lors des modifications de données. Bien qu’utilisés pour la logique, ils ajoutent du temps de traitement à chaque transaction.
- Contraintes uniques :Exigent que le système vérifie les valeurs existantes avant d’insérer de nouvelles données.
Dans les systèmes à haut débit, ces vérifications sont parfois désactivées ou reportées afin d’améliorer la vitesse. Un ERD parfait inclut toutes ces règles, mais un système à haute performance pourrait nécessiter une approche modifiée.
🚦 Étapes pratiques pour l’optimisation
Si votre application est lente, ne redessinez pas immédiatement votre ERD. Suivez une approche systématique pour identifier le goulot d’étranglement.
1. Analyser les requêtes lentes
Activez la journalisation des requêtes pour capturer les instructions longues. Utilisez des outils de profilage pour voir où le temps est consacré. Attend-il des verrous ? Scanne-t-il des lignes ? Traite-t-il de la logique ?
2. Examiner l’utilisation des index
Vérifiez quels index sont réellement utilisés. Les index inutilisés consomment de l’espace de stockage et ralentissent les écritures. Créez des index correspondant aux clauses WHERE et JOIN de vos requêtes fréquentes.
3. Optimiser l’allocation des ressources matérielles
Assurez-vous que le serveur de base de données dispose de suffisamment de RAM pour mettre en cache l’ensemble de travail. Si la base de données est limitée par la mémoire, ajouter plus de RAM produira des résultats immédiats. Si elle est limitée par le CPU, vous devrez peut-être mettre à niveau le processeur ou optimiser le code.
4. Mettre en œuvre le cache
Toute requête n’a pas besoin d’accéder à la base de données. Utilisez un cache en mémoire (comme Redis ou Memcached) pour les données fréquemment consultées. Cela évite complètement la base de données pour les opérations de lecture.
5. Surveiller la concurrence
Surveillez les attentes de verrous. Si les utilisateurs rencontrent des délais d’attente, examinez la durée des transactions. Gardez les transactions courtes pour libérer les verrous rapidement.
🔄 Le rôle de l’évolution du schéma
Les applications évoluent. Les exigences changent. Le schéma doit évoluer avec l’entreprise. Un schéma qui était parfait il y a six mois peut être obsolète aujourd’hui en raison de nouvelles fonctionnalités ou d’une augmentation du volume de données.
Les stratégies de migration sont importantes. Déplacer les données d’une petite table vers une grande table partitionnée peut améliorer les performances. Changer les types de données de VARCHAR à INT peut réduire l’espace de stockage et améliorer les vitesses de balayage. Ces décisions sont prises après la création du schéma ERD initial.
Les schémas ERD statiques ne tiennent pas compte de la croissance des données. À mesure que les données s’agrandissent, les caractéristiques de performance évoluent. Un design qui fonctionnait avec 10 000 enregistrements peut échouer avec 10 millions. C’est pourquoi l’optimisation des performances est un processus continu, et non une tâche ponctuelle.
🧩 Considérations relatives aux bases de données NoSQL
Le concept de schéma ERD s’applique le plus strictement aux bases de données relationnelles. Dans les environnements NoSQL, le modèle de données est différent. Les magasins de documents, les magasins clé-valeur et les bases de données graphes traitent les relations différemment.
Dans un magasin de documents, les données peuvent être intégrées pour éviter les jointures. Cela reproduit intentionnellement la dénormalisation. Dans une base de données graphes, les relations sont des entités de premier plan, stockées explicitement pour optimiser le parcours.
Le mythe de la garantie apportée par le schéma ERD est encore plus marqué ici. En NoSQL, le schéma est souvent souple ou dynamique. Les performances dépendent fortement des modèles d’accès définis dans le code de l’application plutôt que d’un schéma rigide.
🏁 Réflexions finales sur l’architecture des données
Construire une application rapide exige une vision globale. Le schéma ERD est un point de départ critique, garantissant que les données sont organisées logiquement. Il évite le chaos et préserve l’intégrité. Toutefois, il n’est pas le moteur qui assure la vitesse.
Les performances résultent d’une synergie entre :
- Un modèle logique solide.
- Un indexage stratégique.
- Une écriture efficace des requêtes.
- Des ressources matérielles adéquates.
- Une configuration réseau appropriée.
- Des stratégies de mise en cache efficaces.
Blâmer le schéma pour des temps de réponse lents est une solution de facilité qui conduit à des corrections erronées. Un schéma parfait sur papier ne peut compenser un disque lent, un délai réseau ou une requête mal écrite. L’ingénierie des performances réelles consiste à aller au-delà du plan pour observer le flux réel des données.
Lorsque vous effectuez une vérification de votre système, commencez par le schéma ERD pour garantir la correction. Ensuite, passez au plan d’exécution pour garantir l’efficacité. Enfin, évaluez l’infrastructure pour garantir la capacité. Seule une attention portée à toutes les couches permet d’atteindre la réactivité attendue par les utilisateurs.