











Dans l’évolution de l’architecture logicielle, peu de défis sont aussi persistants que la tension entre la modélisation historique des données et les exigences modernes de scalabilité. De nombreuses organisations se retrouvent à gérer des systèmes backend fondés sur des diagrammes de relations entre entités (ERD) conçus il y a des années, souvent sous des hypothèses différentes concernant la charge, la concurrence et le matériel. Lorsqu’un schéma hérité fait face à des exigences de haut débit, la dégradation des performances n’est pas simplement un inconvénient ; c’est une failure structurelle. Ce guide explore les réalités techniques de l’optimisation de ces diagrammes sans abandonner la logique métier intégrée à ceux-ci.
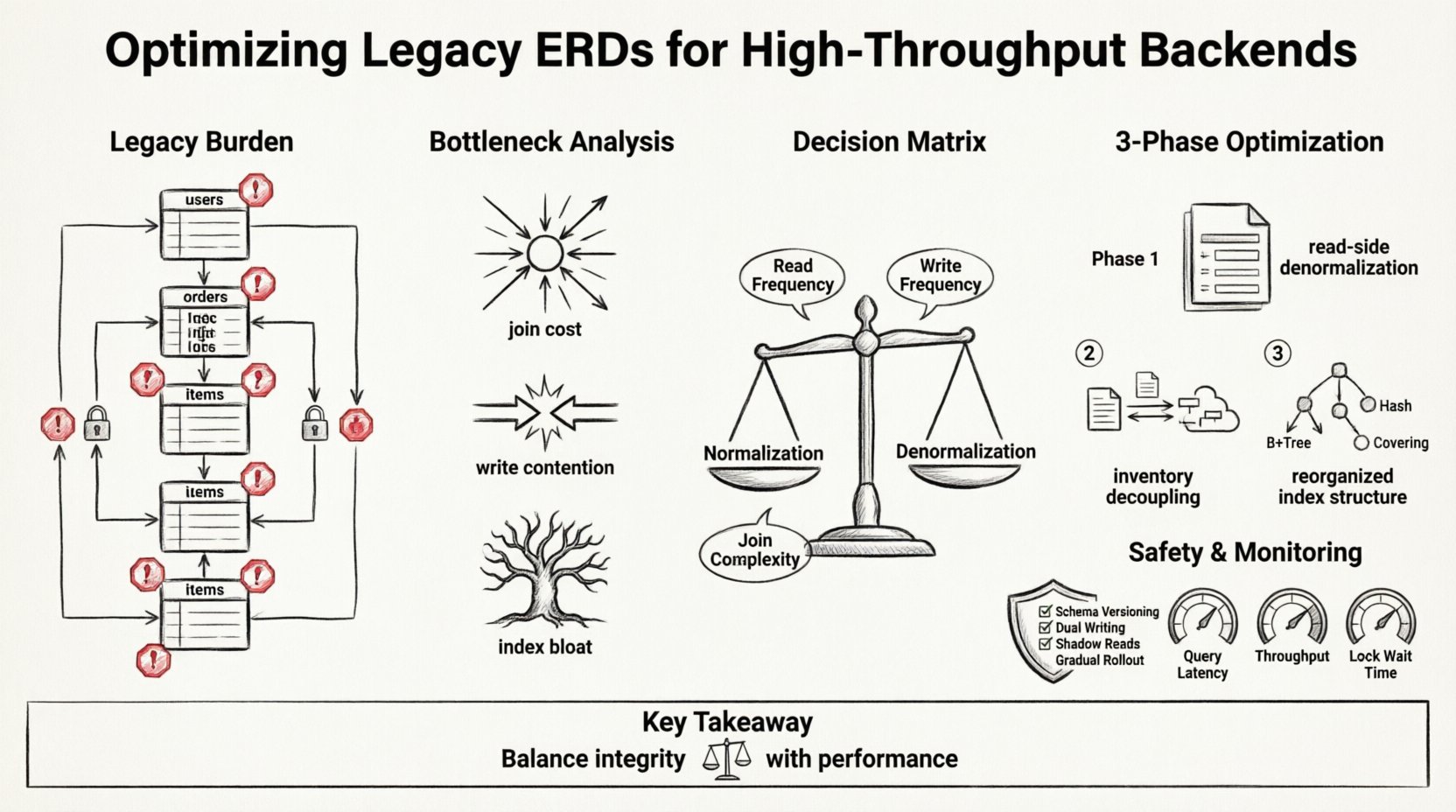
Comprendre le fardeau hérité 💾
Les ERD hérités reflètent souvent les besoins du passé. Ils privilégient la fiabilité des données et la normalisation au détriment de tout le reste. Dans un environnement à nœud unique avec un trafic modéré, cette approche fonctionne bien. L’adhésion stricte à la Troisième Forme Normale (3NF) minimise la redondance et garantit la cohérence. Toutefois, lorsque le système évolue jusqu’à des millions de transactions par seconde, le coût de ces relations devient prohibitif.
Considérez les caractéristiques courantes suivantes présentes dans les anciens schémas :
- Chaînes de jointures profondes :Requêtes nécessitant cinq jointures ou plus pour récupérer un seul enregistrement.
- Contraintes de clés étrangères lourdes :Vérifications rigides d’intégrité qui bloquent les écritures concurrentes.
- Verrouillage centralisé :Points chauds sur des tables spécifiques qui deviennent des goulets d’étranglement pendant les pics de charge.
- Écarts de dénormalisation :L’absence de magasins de données redondants pour les opérations de lecture intensives.
Ces modèles ne sont pas intrinsèquement « erronés ». Ils étaient corrects à leur époque. Le défi réside dans leur adaptation à un environnement distribué et à haute concurrence où la latence est la principale monnaie.
Analyse des goulets d’étranglement 🔍
Avant de modifier le diagramme, il faut comprendre où le système perd en performance. Les backends à haut débit sont souvent limités par les opérations d’E/S, la latence réseau entre les services et la contention de verrous. L’ERD détermine la manière dont les données sont accessibles, ce qui influence directement ces métriques.
1. Coûts des jointures
Chaque jointure correspond à une lecture sur disque et à un cycle de processeur. Dans un système hérité, une requête simple sur un profil utilisateur peut déclencher une cascade de recherches à travers cinq tables. À mesure que le trafic augmente, la base de données passe plus de temps à naviguer dans les relations qu’à exécuter la logique. Cela est particulièrement vrai lorsque les index ne couvrent pas toute la chaîne de jointure.
2. Contention d’écriture
La normalisation exige d’écrire des données à plusieurs endroits pour préserver l’intégrité. Si une transaction met à jour un profil utilisateur et enregistre un événement d’activité, deux tables doivent être modifiées. Si ces tables se trouvent sur le même shard, la durée du verrouillage augmente. Si elles sont réparties, la transaction devient un commit en deux phases, ajoutant un surcroît de charge significatif.
3. Gonflement des index
Pour soutenir des jointures complexes, les systèmes hérités accumulent des index. Au fil du temps, ces index ralentissent les opérations d’écriture. La base de données doit mettre à jour chaque index à chaque insertion ou mise à jour. Dans les scénarios à haut débit, cette amplification des écritures peut saturer le sous-système de stockage.
Stratégie de refactoring : Normalisation vs. Dénormalisation ⚖️
Le cœur de l’optimisation réside dans la réévaluation du compromis entre l’intégrité des données et la vitesse des requêtes. Bien que la normalisation stricte assure la cohérence, les systèmes à haute performance exigent souvent une dénormalisation pragmatique. Cela ne signifie pas abandonner la structure ; cela signifie accepter la redondance afin de réduire la latence.
Le tableau suivant décrit la matrice décisionnelle pour les changements de schéma :
| Critères | Conserver normalisé | Appliquer la dénormalisation |
|---|---|---|
| Fréquence de lecture | Faible (traitement par lots) | Élevé (tableaux de bord en temps réel) |
| Fréquence d’écriture | Élevé (transactions principales) | Faible (journaux d’audit) |
| Exigence de cohérence | ACID fort | Cohérence éventuelle acceptable |
| Complexité des jointures | Simple (1-2 jointures) | Complexe (3+ jointures) |
| Volatilité des données | Statique (données de référence) | Dynamique (état de l’utilisateur) |
Mettre en œuvre cette stratégie nécessite une planification soigneuse. Vous ne changez pas seulement des tables ; vous changez la manière dont l’application perçoit les données.
Parcours du cas d’étude : moteur de transaction e-commerce 🛒
Pour illustrer ce processus, envisagez une plateforme e-commerce fictive. Le système hérité gère le traitement des commandes, la gestion des stocks et les profils clients. Le schéma entité-association a été conçu pour une seule instance de base de données, avec pour objectif principal d’éviter la vente en excès des stocks.
L’état hérité
Dans la conception initiale, la table orders fait référence à order_items, qui fait référence à products. La table products fait référence à inventory. Pour afficher une page de détail de commande, le backend exécutait une requête joignant les quatre tables. En outre, chaque mise à jour de commande nécessitait un verrouillage de la table des stocks pour garantir l’exactitude.
Problèmes clés identifiés :
- Latence : Les temps de chargement de la page ont grimpé jusqu’à 800 ms pendant les événements de vente.
- Interblocages : Un haut niveau de concurrence sur les mises à jour d’inventaire a provoqué des annulations de transactions.
- Évolutivité : La base de données n’a pas pu fractionner la
inventairetable en raison des jointures fréquentes entre les partitions.
Le processus d’optimisation
L’équipe a décidé de restructurer l’ERD en trois phases. L’objectif était de déconnecter les chemins de lecture des chemins d’écriture.
Phase 1 : Dénormalisation du côté lecture
La première étape consistait à créer un instantané des données produit au sein des enregistrements de commande. Au lieu de joindre la table produits à l’heure de la requête, le système a copié le nom du produit, le prix et le SKU dans la table order_items à l’instant de l’achat.
- Avantage : L’historique des commandes reste précis même si les données du produit changent ultérieurement.
- Avantage : La requête n’a plus besoin de joindre la table des produits.
- Risque : Des écarts de prix si un produit est mis à jour après la passation d’une commande.
- Atténuation : L’interface utilisateur affiche le prix au moment de l’achat sous le nom de « Prix historique ».
Phase 2 : Découplage de l’inventaire
La table d’inventaire était la source de contention. L’équipe a déplacé le suivi d’inventaire vers un magasin d’écriture séparé et à haute fréquence. Le système de commandes envoie un message asynchrone pour réserver les stocks au lieu d’exécuter un verrou SQL synchrone.
- Avantage : Le débit d’écriture a augmenté de 400 %.
- Avantage : Plus de blocage sur la transaction principale de commande.
- Compromis : Les commandes peuvent être passées même si l’inventaire est temporairement désynchronisé.
- Atténuation :Un processus en arrière-plan réconcilie les différences entre le système de commande et l’inventaire.
Phase 3 : Restructuration des index
Avec des données dénormalisées, les anciens index sur les clés étrangères sont devenus redondants. L’équipe les a supprimés et ajouté des index composés optimisés pour les nouveaux modèles de requêtes. Par exemple, un index sur (customer_id, created_at) a remplacé la nécessité de scanner l’intégralité de la table des commandes.
Phases de mise en œuvre et sécurité 🛡️
Modifier un schéma en production est une opération à haut risque. Les phases suivantes garantissent la stabilité pendant la transition.
1. Versioning du schéma
Ne supprimez pas les anciennes colonnes immédiatement. Gardez-les en place, mais marquez-les comme obsolètes. Cela permet à l’application de revenir en arrière si la nouvelle logique échoue. Utilisez des scripts de migration qui ajoutent les colonnes avant de les supprimer.
2. Écriture double
Pendant la transition, écrivez les données dans la structure ancienne et la nouvelle. La logique de l’application redirige les lectures vers la nouvelle structure, mais les écritures vont dans les deux. Cela fournit une solution de secours si le nouveau schéma est incomplet.
3. Lecture en ombre
Avant de rediriger le trafic en direct, exécutez les nouvelles requêtes sur une copie des données de production. Comparez les résultats des requêtes héritées à ceux des requêtes optimisées pour garantir l’exactitude des données.
4. Déploiement progressif
Utilisez des indicateurs fonctionnels pour activer le nouveau schéma pour une petite proportion d’utilisateurs (par exemple, 1 %). Surveillez les taux d’erreurs et la latence. Si les métriques restent stables, augmentez progressivement le pourcentage.
Surveillance et validation 📊
L’optimisation n’est pas un événement ponctuel. Elle nécessite une surveillance continue pour s’assurer que les modifications résistent à la charge. Des indicateurs clés de performance (KPI) doivent être établis avant de commencer la refonte.
Indicateurs clés à surveiller :
- Latence des requêtes : Temps de réponse aux percentiles 95e et 99e.
- Débit : Transactions par seconde (TPS) sans erreurs.
- Temps d’attente des verrous : Temps moyen qu’une transaction attend un verrou.
- Délai de réplication : Délai entre les nœuds principaux et répliqués (le cas échéant).
- Taux de réussite du cache : Efficacité des stratégies de mise en cache des lectures.
Les seuils d’alerte doivent être définis en fonction des métriques de référence collectées avant les modifications. Si la latence augmente brusquement, le système doit revenir automatiquement au schéma hérité ou rediriger le trafic vers un service de secours.
Péchés courants à éviter ⚠️
Même avec un plan solide, la dette technique resurgit souvent de manière inattendue. Soyez attentif à ces erreurs courantes.
- Ignorer les coûts de migration des données :Le déplacement de téraoctets de données vers de nouvelles structures prend du temps. Prévoyez des fenêtres de maintenance ou des outils de migration en arrière-plan.
- Sur-optimisation des lectures :Si vous dénormalisez trop, les performances des écritures seront compromises. Équilibrez le ratio lecture/écriture de votre charge de travail spécifique.
- Oublier la logique d’application :Le changement de schéma n’est que la moitié de la bataille. Le code de l’application doit être mis à jour pour gérer la nouvelle structure des données.
- Négliger les tests :Les tests unitaires couvrent souvent les cas idéaux. Des tests de charge sont nécessaires pour détecter les conditions de concurrence dans le nouveau schéma.
Stratégies de maintenance à long terme 🔧
Une fois l’optimisation terminée, l’équipe doit maintenir la nouvelle architecture. La documentation est essentielle. Chaque table, colonne et relation doit être étiquetée avec son objectif et son responsable.
Audits réguliers :
Programmez des revues trimestrielles du schéma ERD. Identifiez les tables qui croissent de manière disproportionnée ou les requêtes qui ralentissent. La croissance de la base de données révèle souvent de nouveaux goulets d’étranglement qui n’étaient pas présents lors du refactorisation initiale.
Vérifications automatiques du schéma :
Intégrez la validation du schéma dans le pipeline CI/CD. Empêchez les développeurs d’ajouter de nouveaux joints ou de supprimer des contraintes critiques sans approbation. Cela garantit que le système reste optimisé au fil du temps.
Formation de l’équipe :
Assurez-vous que tous les ingénieurs backend comprennent le nouveau modèle de données. Une compréhension partagée du schéma réduit la probabilité d’introduire une nouvelle dette technique à travers des requêtes ad hoc.
Réflexions finales sur la modélisation des données 🔗
Optimiser un diagramme relationnel hérité est un équilibre entre la précision historique et la scalabilité future. Il n’existe pas de schéma unique « correct ». Le bon modèle est celui qui soutient vos objectifs commerciaux actuels tout en laissant de la place à la croissance.
En vous concentrant sur les goulets d’étranglement spécifiques de votre système—qu’il s’agisse des coûts de jointure, de la contention de verrous ou du gonflement des index—vous pouvez apporter des améliorations ciblées. L’étude de cas montre qu’il est possible de moderniser même des structures profondément ancrées sans refonte complète. La clé réside dans une approche méthodique, une validation rigoureuse et une vision claire des compromis impliqués.
La modélisation des données n’est pas statique. Elle évolue avec le trafic qu’elle dessert. Traitez votre ERD comme un document vivant qui exige le même soin et la même attention que le code qui le requête. Avec la bonne approche, vous pouvez transformer un système hérité en un moteur à haute performance capable de répondre aux exigences du web moderne.