











La récupération après sinistre concerne rarement le cataclysme lui-même ; elle porte sur la fragilité des structures que nous construisons avant que la tempête ne frappe. Dans notre récent incident, une erreur apparemment mineure dans la conception du schéma de base de données est devenue le goulot d’étranglement de toute la procédure de restauration. Le coupable était un diagramme Entité-Relation (ERD) qui ne reflétait pas correctement les dépendances des données dans l’environnement de production. Ce qui aurait dû être une opération de quarante-cinq minutes s’est étirée sur trois heures d’interventions manuelles et de réconciliation des données. 🕰️
Cet article détaille l’analyse technique de cette erreur, les incohérences spécifiques du schéma qui ont causé le retard, et les modifications procédurales que nous avons mises en œuvre pour éviter toute récidive. Nous examinerons la manière dont l’intégrité des données dépend fortement de la précision de la documentation de conception, et non seulement du code lui-même.
Le rôle fondamental des ERD dans la résilience des données 🛡️
Les diagrammes Entité-Relation sont les plans directeurs de l’infrastructure numérique. Ils représentent les tables, les champs, les clés primaires et les clés étrangères, définissant la manière dont les données sont connectées et circulent. Lorsqu’un sinistre frappe, ces diagrammes sont le premier point de référence pour les ingénieurs chargés de restaurer l’état du système. Si la carte est fausse, le parcours est retardé.
Dans le cadre de la récupération après sinistre, un ERD remplit trois fonctions principales :
- Validation : Il confirme que le schéma restauré correspond à l’état attendu de l’application.
- Cartographie des dépendances : Il identifie les tables qui dépendent des autres, dictant ainsi l’ordre de restauration.
- Vérification des contraintes : Il garantit que les règles d’intégrité référentielle sont correctement appliquées pendant le processus d’importation.
Lorsque l’ERD ne correspond pas à la configuration réelle de la base de données, les scripts de restauration échouent au moment de la validation. Cela oblige les ingénieurs à s’arrêter, à enquêter et à corriger manuellement le schéma. C’est précisément à ce stade manuel que le temps est perdu. ⏳
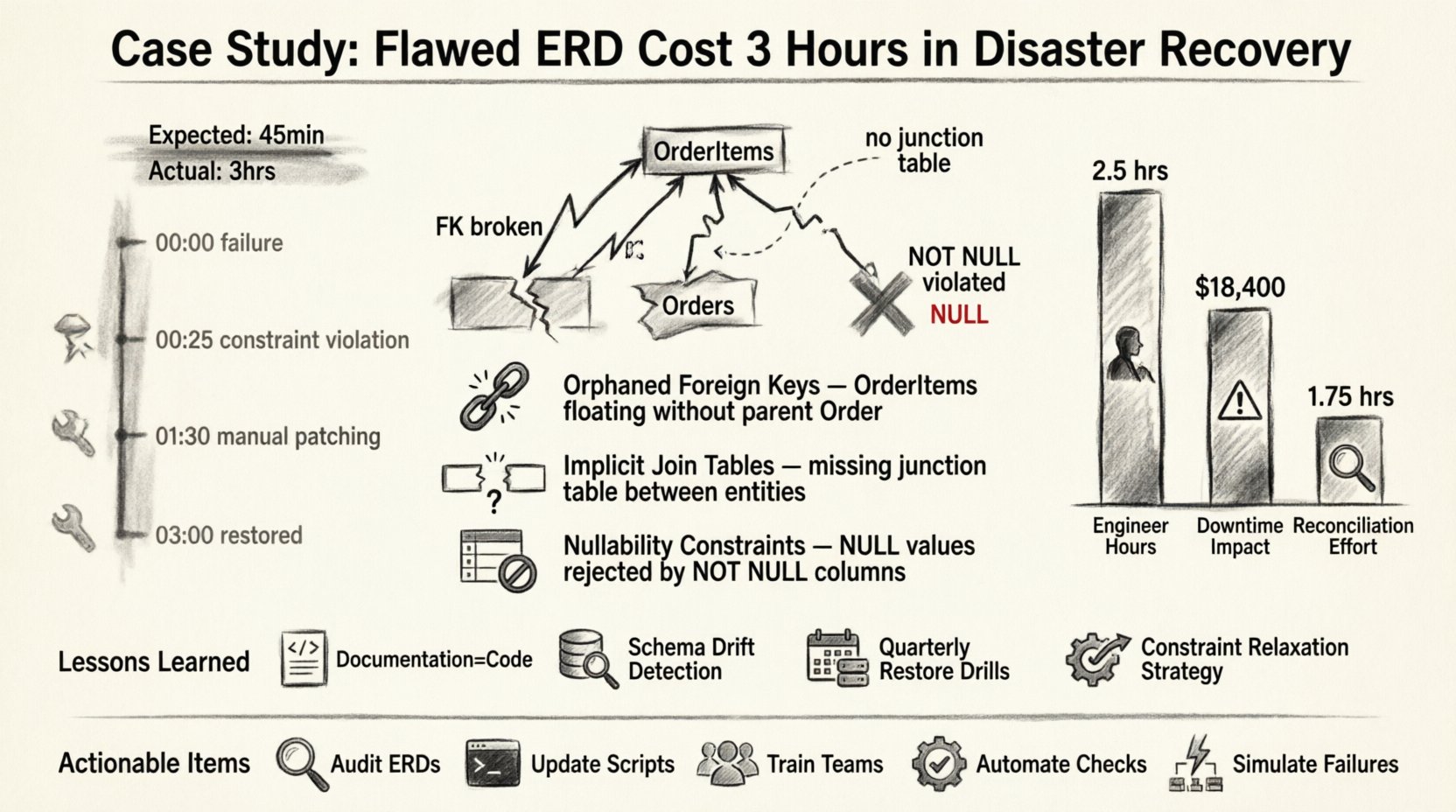
L’incident : une chronologie des erreurs 📉
L’incident a commencé par une panne du stockage de données principal. Une erreur matérielle catastrophique a déclenché le basculement vers notre environnement secondaire. La procédure opérationnelle standard consistait à lancer le script de restauration, qui reposait sur une version statique de l’ERD stockée dans notre référentiel de documentation.
Voici la chronologie de l’échec :
- 00:00 – Détection d’une panne du système principal. Une alerte déclenche la réponse à l’incident.
- 00:05 – Équipe d’ingénierie mobilisée. Accès accordé à l’environnement secondaire.
- 00:15 – Script de restauration lancé sur la base de l’ERD de documentation.
- 00:25 – Script interrompu. Violation de contrainte de clé étrangère détectée.
- 00:30 – L’enquête commence. Une incohérence est trouvée entre l’ERD et le schéma en cours d’exécution.
- 01:30 – La correction du schéma et la réconciliation manuelle des données ont commencé.
- 03:00 – Le système a été restauré en état opérationnel.
Le retard de trois heures n’était pas dû à une latence du réseau ou à une lenteur matérielle. Il était dû à l’écart logique entre le document de conception et la réalité physique. 🧩
Les défauts spécifiques du schéma identifiés 🔍
En examinant la base de données en production par rapport au MCD, nous avons identifié trois écarts critiques. Ce n’étaient pas des erreurs de syntaxe ; ce étaient des omissions logiques qui n’ont été apparentes qu’au moment où le système a tenté d’appliquer des contraintes de relation.
1. Clés étrangères orphelines
Le MCD représentait une relation stricte un-à-plusieurs entre Commandes et Articles de commande. Cependant, la base de données réelle contenait des données héritées où Articles de commande existait sans enregistrement correspondant à Commande en raison d’une migration antérieure qui n’a pas appliqué les contraintes. Le MCD n’avait pas pris en compte cet état orphelin. Lorsque le script de restauration a tenté de rétablir la clé étrangère, la base de données a rejeté les données car l’enregistrement parent était manquant ou la contrainte était appliquée différemment de ce qui était documenté.
2. Tables de jointure implicites
Une relation plusieurs-à-plusieurs était représentée dans le MCD par un lien direct entre deux tables. Dans la mise en œuvre physique, cela était géré via une table de jonction. La logique de restauration s’attendait au lien direct et a tenté d’insérer des données dans les colonnes incorrectes. Cela a entraîné une cascade d’erreurs de type incompatibles nécessitant une modification manuelle du schéma.
3. Contraintes de nullité
Le MCD indiquait que plusieurs champs étaient facultatifs (pouvant être nuls). Le schéma de production, en revanche, avait été mis à jour au fil du temps pour imposer des valeurs non nulles dans le cadre de la qualité des données. Le MCD n’avait pas été mis à jour pour refléter ce changement. Pendant la restauration, le script a tenté d’insérer des valeurs NULL dans des colonnes non nulles, provoquant un rollback immédiat de la transaction.
Ces écarts mettent en évidence un problème courant dans la documentation technique : dérive de documentation. Le document devient obsolète au fur et à mesure que le système évolue, créant un faux sentiment de sécurité.
Analyse des coûts : Temps vs. Précision 💰
L’impact financier de l’indisponibilité de trois heures est important, mais le coût réputationnel est encore plus élevé. Ci-dessous se trouve le détail des ressources consommées pendant le délai.
| Ressource | Temps consommé | Impact |
|---|---|---|
| Ingénieurs seniors | 3 heures | Priorité élevée détournée du développement |
| Indisponibilité du système | 3 heures | La disponibilité du service a été réduite de 15 % |
| Reconnaissance des données | 1,5 heure | Vérification manuelle requise |
| Mise à jour de la documentation | 0,5 heure | Réunion de suivi après incident |
Le tableau illustre que la majorité des coûts ne provenait pas de la restauration elle-même, mais du correctif de la restauration. Si le MCD avait été exact, la restauration se serait déroulée sans interruption.
Analyse technique : Pourquoi le script a échoué 🛠️
Pour comprendre la gravité de l’erreur, nous devons examiner comment le script de restauration a interagi avec le moteur de base de données. Le script a suivi une séquence standard :
- Créer les tables selon les définitions du MCD.
- Appliquer les contraintes (clés primaires, clés étrangères).
- Vérifier l’intégrité.
3. Insérer les données.
Lorsque le script a atteint l’étape 2, il a tenté de créer une contrainte de clé étrangère reliant Table A à Table B. Le moteur de base de données a analysé Table B pour les données existantes. Il a trouvé des enregistrements qui violaient la contrainte car la clé parente était absente. Comme le script était conçu pour être idempotent et sûr, il s’est arrêté plutôt que de corrompre les données. Cette fonctionnalité de sécurité, bien qu’utile pour l’intégrité des données, a agi comme un obstacle pour le calendrier de récupération.
Le script ne pouvait pas continuer tant que les données dans Table B n’avaient pas été nettoyées. Le nettoyage des données nécessite :
- Identifier les enregistrements orphelins.
- Déterminer s’il faut les supprimer ou créer des enregistrements parent fictifs.
- Exécuter le nettoyage manuellement.
- Relancer la création de la contrainte.
Chaque étape dans cette chaîne ajoute du temps. Le schéma ER aurait dû signaler le risque de données orphelines pendant la phase de conception, ce qui aurait conduit à une stratégie de migration des données plutôt qu’à une simple réplication du schéma.
Leçons apprises : renforcer le cycle de vie du schéma 🔄
Suite à l’incident, nous avons lancé un examen rigoureux de nos pratiques de gestion des schémas. Nous avons compris qu’une dépendance à un document statique pour la récupération après sinistre était insuffisante. Nous avions besoin d’une approche dynamique et contrôlée par version pour la conception des schémas.
Voici les enseignements clés tirés de l’incident :
- La documentation est du code : Le schéma ER n’est pas un artefact indépendant ; il fait partie du code source. Il doit subir les mêmes processus de contrôle de version et de revue que la logique de l’application.
- Détection des écarts de schéma : Nous avons mis en place des outils automatisés pour comparer le schéma de la base de données en production avec le schéma ER versionné. Toute divergence déclenche une alerte immédiatement.
- Test de la récupération : Nous effectuons désormais des exercices de récupération dans un environnement de sandbox tous les trois mois. Cela garantit que le schéma ER reflète fidèlement le chemin de récupération.
- Relâchement des contraintes : Nous avons ajusté les scripts de récupération pour désactiver temporairement les contraintes de clés étrangères pendant le chargement initial des données, en les réactivant uniquement après vérification de toutes les données.
Meilleures pratiques pour la maintenance des schémas ER 📝
Pour éviter les retards futurs, nous avons adopté un ensemble de bonnes pratiques pour la maintenance des diagrammes de relations entre entités. Ces étapes garantissent que le plan directeur reste valide tout au long du cycle de vie du système.
1. Contrôle de version pour les diagrammes
Stockez les fichiers de schéma ER dans le même dépôt que le code source. Marquez chaque version avec une version correspondante du schéma. Cela permet aux ingénieurs de récupérer l’état exact du schéma à tout moment.
2. Génération automatisée
Lorsque c’est possible, générez les schémas ER directement à partir du schéma de la base de données plutôt que de les dessiner manuellement. Cela réduit les risques d’erreur humaine et garantit que le schéma correspond toujours à la réalité.
3. Audits réguliers
Programmez un audit trimestriel du schéma ER. Comparez le diagramme avec l’environnement de production. Documentez tous les changements effectués en dehors du pipeline de déploiement standard.
4. Inclure des notes de migration des données
Le schéma ER ne doit pas montrer uniquement les tables ; il doit montrer l’historique des données. Annotez le diagramme avec des notes concernant les données qui pourraient être orphelines ou obsolètes. Cela informe l’équipe de récupération qu’elle doit s’attendre à des anomalies.
5. Revue lors de la planification des sprints
Lorsqu’une nouvelle fonctionnalité nécessite un changement de base de données, le schéma ER doit être mis à jour dans le même ticket. Ne permettez pas le déploiement de changements de schéma sans mise à jour correspondante du diagramme.
L’élément humain dans les erreurs techniques 🧑💻
Il est facile de blâmer le schéma ou le script, mais la cause racine était souvent un manque de communication. Le développeur qui a ajouté le nouveau champ n’a pas mis à jour le schéma. L’ingénieur qui a revu le code n’a pas vérifié la documentation du schéma.
Les processus techniques ne sont aussi solides que les personnes qui les suivent. Nous avons introduit une liste de vérification pour le déploiement incluant une étape de vérification du schéma. Chaque déploiement doit inclure un rapport de différences montrant les modifications apportées à la structure de la base de données. Cela impose une visibilité sur les modifications du schéma.
Pensées finales sur la résilience 🏗️
La récupération après sinistre est une mesure de notre préparation, et non seulement de notre réaction. Le retard de trois heures était un symptôme d’un problème plus large : le décalage entre la conception et la mise en œuvre. En traitant le schéma de relations entre entités comme un composant vivant et actif de notre infrastructure, nous pouvons réduire considérablement les temps de récupération.
L’intégrité des données n’est pas une fonctionnalité ; c’est une fondation. Quand cette fondation se fissure, toute la structure est en danger. Assurer que nos plans sont précis est la première étape vers une architecture résiliente. Nous devons consacrer autant de temps à la documentation qu’à l’écriture du code.
Résumé des éléments actionnables ✅
- Audit des ERD actuels : Comparez toutes les documentation aux schémas en cours d’exécution immédiatement.
- Mise à jour des scripts : Modifiez les scripts de récupération après sinistre pour gérer les violations de contraintes de manière fluide.
- Former les équipes : Assurez-vous que tous les ingénieurs comprennent l’importance de la documentation des schémas.
- Automatiser les vérifications : Mettez en place des outils qui alertent en cas de dérive du schéma.
- Simuler les défaillances : Effectuez régulièrement des exercices de récupération après sinistre pour tester l’exactitude de la documentation.
En suivant ces pratiques, nous pouvons garantir que les incidents futurs seront résolus en minutes, et non en heures. Le coût de la précision est bien inférieur à celui de la correction.