











En el mundo de la arquitectura de software, pocas conceptos tienen tanta importancia como el Diagrama de Relaciones de Entidades (ERD). Es el plano de tu datos, el mapa que guía a los desarrolladores a través del complejo terreno de tablas, claves y relaciones. Cuando una aplicación se ralentiza, la primera reacción suele ser culpar al esquema. La suposición es clara: si el diagrama es perfecto, el rendimiento debe ser perfecto.
Esta es una creencia común. 🧐 Aunque un ERD bien diseñado es fundamental, no es una solución mágica para la velocidad. Un modelo lógico perfecto no se traduce automáticamente en una ejecución física de alta velocidad. Comprender la brecha entre la teoría del diseño y la realidad en tiempo de ejecución es crucial para construir sistemas que permanezcan responsivos bajo presión.
Esta guía explora por qué un ERD perfecto no garantiza tiempos de respuesta rápidos y qué otros factores críticos influyen en el rendimiento de la base de datos. Analizaremos las capas del manejo de datos, desde motores de almacenamiento hasta la latencia de red, para revelar los verdaderos impulsores de la velocidad de la aplicación.
📐 Comprendiendo el Diagrama de Relaciones de Entidades
Antes de adentrarnos en métricas de rendimiento, debemos aclarar qué representa realmente un ERD. Un ERD es un artefacto lógico. Describequé datos existen y cómo se relacionan con otros datos. Define entidades (tablas), atributos (columnas) y relaciones (claves foráneas).
- Entidades:Objetos del mundo real representados como tablas.
- Atributos:Características de esos objetos almacenados en columnas.
- Relaciones:Los enlaces entre entidades, a menudo garantizados mediante claves primarias y foráneas.
- Cardinalidad:La relación numérica entre entidades (uno a uno, uno a muchos).
El objetivo principal de un ERD es la integridad de los datos. Asegura que los datos permanezcan consistentes, precisos y útiles con el tiempo. Evita registros huérfanos y mantiene la integridad referencial. Sin embargo, la integridad no es lo mismo que velocidad. Una cerradura que mantiene una puerta cerrada protege el contenido interior, pero no hace que la puerta se abra más rápido.
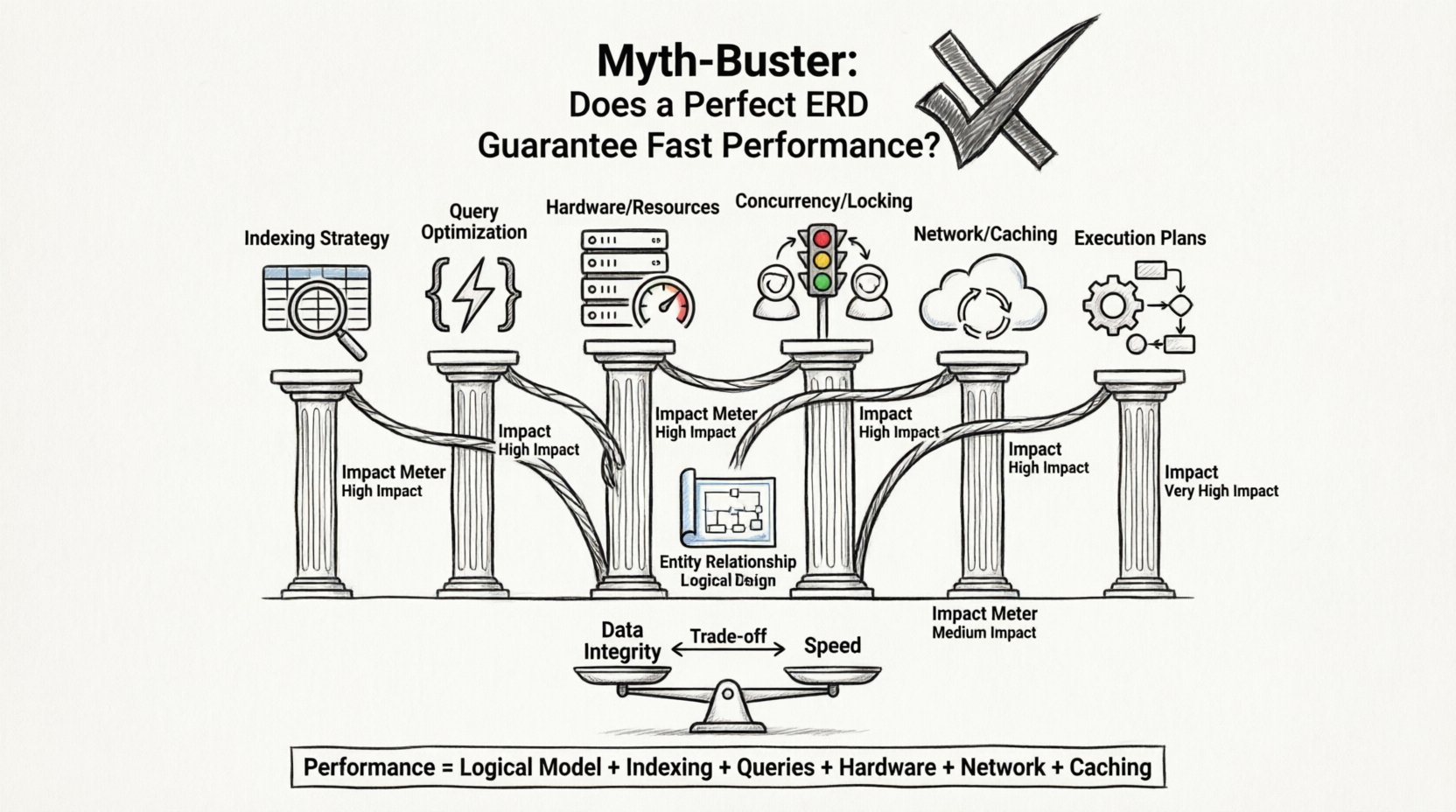
⚡ La ecuación de rendimiento: más allá del esquema
El tiempo de respuesta de la aplicación es la suma de muchos componentes. La base de datos es solo una parte de esta ecuación. Incluso si el motor de la base de datos recupera los datos instantáneamente, la aplicación puede seguir sintiéndose lenta debido a cuellos de botella en otras partes.
Estos son los factores clave que influyen en la velocidad, a menudo eclipsando el diseño del esquema:
1. Estrategia de índices
Un ERD define claves primarias y claves foráneas, que a menudo generan índices automáticamente. Sin embargo, estos índices predeterminados rara vez son suficientes para consultas complejas. El rendimiento depende en gran medida de índices secundarios adaptados a patrones de consulta específicos.
- Índices faltantes:Sin un índice en una columna frecuentemente filtrada, la base de datos debe realizar una escaneo completo de la tabla. Esto lee cada fila, lo que es exponencialmente más lento en conjuntos de datos grandes.
- Sobrecarga de índices:Demasiados índices ralentizan las operaciones de escritura. Cada inserción o actualización requiere actualizar cada índice asociado con esa tabla.
- Selectividad:Un índice en una columna con baja selectividad (por ejemplo, género o estado) puede ser ignorado por el optimizador de consultas.
2. Optimización de consultas
La forma en que se solicita la data es más importante que cómo se almacena. Una consulta mal escrita puede paralizar un esquema perfecto. Los problemas comunes incluyen:
- Problemas N+1:Recuperar un registro padre y luego recorrerlo para obtener individualmente los registros hijos. Esto genera múltiples idas y vueltas a la base de datos en lugar de una sola operación JOIN.
- Uso de SELECT *:Recuperar todas las columnas aumenta el tráfico de red y el uso de memoria, incluso si solo se necesita una.
- Conversiones implícitas:Comparar una cadena con un número o una fecha con una marca de tiempo puede impedir el uso de índices.
- JOINs complejos:Unir múltiples tablas grandes sin un filtrado adecuado aumenta significativamente la carga computacional.
3. Hardware e infraestructura
La eficiencia del software no puede superar las limitaciones físicas. El hardware subyacente determina el límite para el rendimiento.
- Tipo de almacenamiento:Las unidades de estado sólido (SSD) son significativamente más rápidas que las unidades de disco duro (HDD) para operaciones de E/S aleatorias.
- Memoria (RAM):Si el conjunto de datos que se está utilizando cabe en la RAM, las consultas son casi instantáneas. Si los datos deben recuperarse del disco, la latencia aumenta.
- Potencia de la CPU:Cálculos complejos, ordenamiento y agregación requieren potencia de procesamiento.
- Latencia de red:La distancia entre el servidor de aplicaciones y el servidor de base de datos añade milisegundos a cada solicitud.
4. Concurrencia y bloqueos
Cuando múltiples usuarios acceden al sistema simultáneamente, la base de datos debe gestionar los conflictos. Es aquí donde el rendimiento a menudo se degrada.
- Contención de bloqueos:Si una transacción mantiene un bloqueo sobre una fila, las demás deben esperar. Una alta contención lleva a tiempos de espera y tiempos de respuesta lentos.
- Muertes de espera (deadlocks):Dos transacciones esperando mutuamente pueden causar una paralización general del sistema.
- Niveles de aislamiento:Los niveles de aislamiento más altos (por ejemplo, Serializable) ofrecen garantías más fuertes, pero reducen la concurrencia y la velocidad.
📊 Impacto del ERD frente a otros factores de rendimiento
Para visualizar la influencia del ERD en comparación con otras variables, considere la siguiente descomposición. Esta tabla destaca dónde el ERD aporta valor y dónde falla.
| Factor | Impacto en la velocidad de lectura | Impacto en la velocidad de escritura | Rol del ERD |
|---|---|---|---|
| Estructura del esquema de tabla | Medio | Medio | Define relaciones y normalización. |
| Indización | Alto | Bajo | El ERD define claves, pero no todos los índices. |
| Lógica de consulta | Muy alto | Medio | El ERD no dicta la sintaxis de consulta. |
| Recursos de hardware | Alto | Alto | Ninguno. Independiente del esquema. |
| Latencia de red | Alto | Medio | Ninguno. Independiente del esquema. |
| Aprovechamiento de conexiones | Medio | Medio | Ninguno. Configuración de la aplicación. |
🧱 El compromiso de la normalización
Uno de los temas más debatidos en el diseño de bases de datos es la normalización. El ERD generalmente busca la Tercera Forma Normal (3FN) para reducir la redundancia. Aunque esto ahorra espacio y garantiza la consistencia, puede afectar el rendimiento.
Cuando los datos están altamente normalizados, una sola pieza de información se almacena en un solo lugar. Para recuperarla, el sistema debe atravesar múltiples JOINs. Cada JOIN añade sobrecarga computacional.
Considere un escenario en el que necesita mostrar el perfil de un usuario junto con su último pedido y los detalles del producto. En un ERD normalizado, esto podría requerir unir cuatro tablas. Si estas tablas son grandes, la CPU dedica mucho tiempo a ordenar y emparejar filas.
Denormalización es una técnica utilizada para contrarrestar esto. Implica duplicar datos para reducir la necesidad de JOINs. Esto mejora la velocidad de lectura, pero complica las operaciones de escritura y conlleva el riesgo de inconsistencia de datos. Un ERD perfecto no decide automáticamente dónde trazar esta línea. Es una decisión estratégica basada en la relación de lectura/escritura.
🔍 Análisis profundo: Planes de ejecución de consultas
El motor de base de datos no ejecuta las consultas exactamente como se escriben. Analiza la solicitud y genera un Plan de ejecución. Este plan determina el orden de las operaciones, qué índices utilizar y si realizar una búsqueda completa o un acceso directo.
Un ERD proporciona metadatos sobre los tipos de datos y las restricciones. Sin embargo, el optimizador utiliza estadísticas sobre la distribución de los datos para tomar decisiones. Si las estadísticas están desactualizadas, el optimizador podría elegir un plan subóptimo, ignorando los mejores índices disponibles.
Por ejemplo, si una tabla tiene 10 millones de filas pero las estadísticas piensan que tiene 100, el optimizador podría decidir que una búsqueda completa es más barata que un acceso indexado. Esto conduce a un rendimiento lento a pesar de un ERD bien estructurado.
🛡️ Integridad de datos frente a velocidad
Existe una tensión inherente entre garantizar la integridad de los datos y maximizar la velocidad. Un ERD impone reglas de integridad como restricciones y desencadenadores.
- Restricciones de clave foránea: Garantizan la integridad referencial. Al eliminar o actualizar, el sistema debe verificar las tablas relacionadas. Esto añade latencia a las operaciones de escritura.
- Desencadenadores:Scripts automatizados que se ejecutan ante cambios de datos. Aunque son útiles para la lógica, añaden tiempo de procesamiento a cada transacción.
- Restricciones únicas: Requieren que el sistema verifique los valores existentes antes de insertar nuevos.
En sistemas de alto rendimiento, estas comprobaciones a veces se deshabilitan o se posponen para mejorar la velocidad. Un ERD perfecto incluye todas estas reglas, pero un sistema de alto rendimiento podría requerir un enfoque modificado.
🚦 Pasos prácticos para la optimización
Si su aplicación es lenta, no redibuje inmediatamente su ERD. Siga un enfoque sistemático para identificar el cuello de botella.
1. Analice las consultas lentas
Habilite el registro de consultas para capturar las declaraciones de larga duración. Use herramientas de perfilado para ver dónde se gasta el tiempo. ¿Está esperando bloques? ¿Está escaneando filas? ¿Está procesando lógica?
2. Revise el uso de índices
Verifique qué índices se están utilizando realmente. Los índices no utilizados consumen almacenamiento y ralentizan las escrituras. Cree índices que coincidan con las cláusulas WHERE y JOIN de sus consultas frecuentes.
3. Optimize la asignación de hardware
Asegúrese de que el servidor de base de datos tenga suficiente RAM para cachear el conjunto de trabajo. Si la base de datos está limitada por la memoria, añadir más RAM dará resultados inmediatos. Si está limitada por la CPU, es posible que deba actualizar el procesador o optimizar el código.
4. Implemente el almacenamiento en caché
No todas las solicitudes necesitan acceder a la base de datos. Use una caché en memoria (como Redis o Memcached) para datos frecuentemente accedidos. Esto evita por completo la base de datos en operaciones de lectura.
5. Monitoree la concurrencia
Vigile los tiempos de espera de bloqueos. Si los usuarios experimentan tiempos de espera, revise las duraciones de las transacciones. Mantenga las transacciones cortas para liberar los bloqueos rápidamente.
🔄 El papel de la evolución del esquema
Las aplicaciones cambian. Los requisitos varían. El ERD debe evolucionar con el negocio. Un esquema que era perfecto hace seis meses puede ser obsoleto hoy debido a nuevas funciones o un aumento en el volumen de datos.
Las estrategias de migración importan. Mover datos de una tabla pequeña a una tabla grande particionada puede mejorar el rendimiento. Cambiar los tipos de datos de VARCHAR a INT puede reducir el almacenamiento y mejorar las velocidades de escaneo. Estas decisiones se toman después de crear el ERD inicial.
Los ERD estáticos no tienen en cuenta el crecimiento de los datos. A medida que los datos crecen, cambian las características de rendimiento. Un diseño que funcionaba con 10.000 registros podría fallar con 10 millones. Por eso, el ajuste de rendimiento es un proceso continuo, no una tarea única.
🧩 Consideraciones sobre NoSQL
El concepto de un ERD se aplica más estrictamente a las bases de datos relacionales. En entornos NoSQL, el modelo de datos es diferente. Las bases de datos de documentos, almacenes de claves-valor y bases de datos de grafos manejan las relaciones de forma distinta.
En una base de datos de documentos, los datos podrían incluirse para evitar uniones. Esto simula la desnormalización por diseño. En una base de datos de grafos, las relaciones son ciudadanos de primera clase, almacenadas explícitamente para optimizar el recorrido.
El mito de la garantía del ERD es aún más evidente aquí. En NoSQL, el esquema suele ser flexible o dinámico. El rendimiento depende en gran medida de los patrones de acceso definidos en el código de la aplicación, más que de un diagrama rígido.
🏁 Reflexiones finales sobre la arquitectura de datos
Construir una aplicación rápida requiere una visión integral. El ERD es un punto de partida crítico, que asegura que los datos estén organizados lógicamente. Evita el caos y mantiene la integridad. Sin embargo, no es el motor que impulsa la velocidad.
El rendimiento es el resultado de una sinergia entre:
- Un modelo lógico sólido.
- Indexación estratégica.
- Escritura eficiente de consultas.
- Recursos de hardware adecuados.
- Configuración de red adecuada.
- Estrategias efectivas de caché.
Responsabilizar al esquema por tiempos de respuesta lentos es un atajo que conduce a soluciones incorrectas. Un diagrama perfecto en papel no puede compensar un disco lento, un tiempo de espera de red o una consulta mal escrita. La ingeniería de rendimiento verdadera implica mirar más allá del plano para el flujo real de datos.
Cuando audites tu sistema, comienza con el ERD para asegurar la corrección. Luego, pasa al plan de ejecución para asegurar la eficiencia. Finalmente, evalúa la infraestructura para asegurar la capacidad. Solo abordando todas las capas puedes lograr la respuesta que los usuarios esperan.