











La recuperación ante desastres rara vez trata sobre el desastre en sí; se trata de la fragilidad de las estructuras que construimos antes de que llegue la tormenta. En nuestro incidente reciente, una omisión aparentemente menor en el diseño de un esquema de base de datos se convirtió en el cuello de botella de todo el proceso de restauración. El culpable fue un Diagrama de Relaciones de Entidades (ERD) que no logró reflejar con precisión las dependencias de datos del entorno de producción. Lo que debería haber sido una operación de cuarenta y cinco minutos se extendió durante tres horas de intervención manual y reconciliación de datos. 🕰️
Este artículo detalla el análisis técnico de ese fallo, las incoherencias específicas en el esquema que causaron la demora y los cambios procedimentales que implementamos para evitar que se repita. Examinaremos cómo la integridad de los datos depende en gran medida de la precisión de la documentación de diseño, no solo del código en sí.
El papel fundamental de los ERD en la resiliencia de los datos 🛡️
Los Diagramas de Relaciones de Entidades son los planos de la infraestructura digital. Muestran tablas, campos, claves primarias y claves foráneas, definiendo cómo se conectan y fluyen los datos. Cuando ocurre un desastre, estos diagramas son el primer punto de referencia para los ingenieros que intentan restaurar el estado. Si el mapa está equivocado, el viaje se retrasa.
En el contexto de la recuperación ante desastres, un ERD cumple tres funciones principales:
- Validación: Confirma que el esquema restaurado coincide con el estado esperado de la aplicación.
- Mapa de dependencias: Identifica qué tablas dependen de otras, determinando el orden de restauración.
- Verificación de restricciones: Asegura que las reglas de integridad referencial se apliquen correctamente durante el proceso de importación.
Cuando el ERD no coincide con la configuración real de la base de datos, los scripts de restauración fallan en el momento de la validación. Esto obliga a los ingenieros a detenerse, investigar y parchear manualmente el esquema. Es en este paso manual donde se pierde el tiempo. ⏳
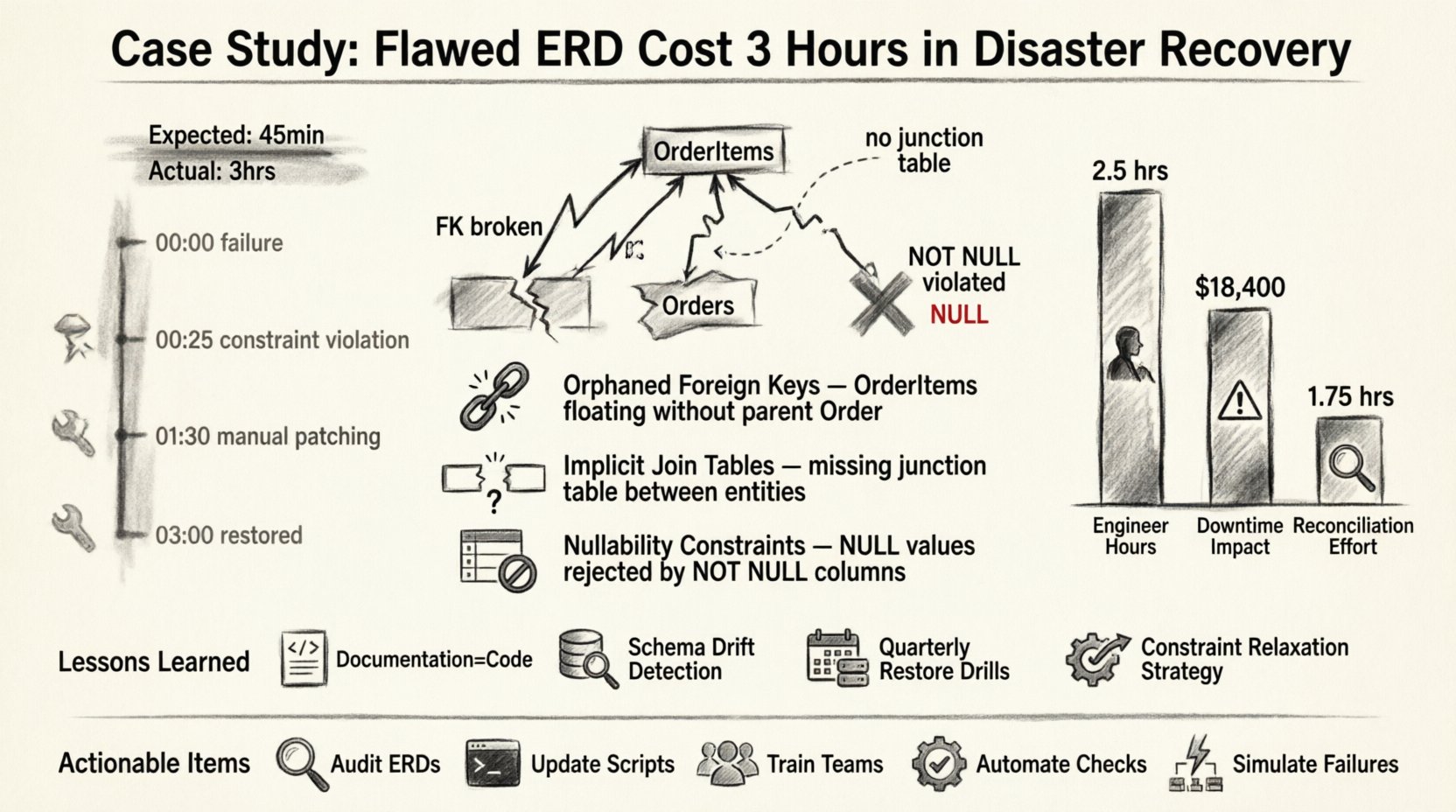
El incidente: Una cronología de errores 📉
El incidente comenzó con un fallo en el almacén de datos principal. Un error catastrófico en el hardware desencadenó el cambio de fallo hacia nuestro entorno secundario. El procedimiento estándar consistía en iniciar el script de restauración, que dependía de una versión estática del ERD almacenada en nuestro repositorio de documentación.
Aquí está la cronología del fallo:
- 00:00 – Detección de fallo en el sistema principal. La alerta desencadena la respuesta al incidente.
- 00:05 – El equipo de ingeniería se movilizó. Se otorgó acceso al entorno secundario.
- 00:15 – Se inició el script de restauración basado en el ERD de la documentación.
- 00:25 – El script se detuvo. Se detectó una violación de restricción de clave foránea.
- 00:30 – Comienza la investigación. Se encontró una discrepancia entre el ERD y el esquema en vivo.
- 01:30 – Se inició la corrección del esquema y la reconciliación manual de datos.
- 03:00 – El sistema se restauró al estado operativo.
La demora de tres horas no fue causada por la latencia de la red ni por la lentitud del hardware. Fue causada por la brecha lógica entre el documento de diseño y la realidad física. 🧩
Las fallas específicas en el esquema identificadas 🔍
Al inspeccionar la base de datos en vivo contra el ERD, identificamos tres discrepancias críticas. Estas no fueron errores de sintaxis; fueron omisiones lógicas que solo se volvieron evidentes cuando el sistema intentó imponer relaciones.
1. Claves foráneas huérfanas
El ERD mostraba una relación estricta uno-a-muchos entrePedidos y Elementos de pedido. Sin embargo, la base de datos real contenía datos heredados dondeElementos de pedido existían sin un registro correspondiente dePedido registro debido a una migración anterior que no impuso restricciones. El ERD no tuvo en cuenta este estado huérfano. Cuando la secuencia de restauración intentó reestablecer la clave foránea, la base de datos rechazó los datos porque el registro padre estaba ausente o la restricción se aplicó de forma diferente a como se documentó.
2. Tablas de unión implícitas
Una relación muchos-a-muchos se representó en el ERD como un enlace directo entre dos tablas. En la implementación física, esto se manejó mediante una tabla de unión. La lógica de restauración esperaba el enlace directo y trató de insertar datos en las columnas incorrectas. Esto provocó una cascada de errores de tipo incompatible que requirieron una alteración manual del esquema.
3. Restricciones de nulidad
El ERD indicaba que varios campos eran opcionales (nulos). Sin embargo, el esquema de producción se había actualizado con el tiempo para exigir valores no nulos con fines de calidad de datos. El ERD no se actualizó para reflejar este cambio. Durante la restauración, la secuencia intentó insertar valores NULL en columnas no nulas, lo que provocó un rechazo inmediato de la transacción.
Estas discrepancias destacan un problema común en la documentación técnica:desviación de la documentación. El documento se vuelve obsoleto a medida que el sistema evoluciona, creando una falsa sensación de seguridad.
Análisis de costos: Tiempo frente a precisión 💰
El impacto financiero de la interrupción de tres horas es significativo, pero el costo reputacional es mayor. A continuación se muestra un desglose de los recursos consumidos durante la demora.
| Recurso | Tiempo consumido | Impacto |
|---|---|---|
| Ingenieros senior | 3 horas | Alta prioridad desviada del desarrollo |
| Tiempo de inactividad del sistema | 3 horas | La disponibilidad del servicio se redujo en un 15% |
| Reconciliación de datos | 1.5 Horas | Se requiere verificación manual |
| Actualización de documentación | 0.5 Horas | Reunión posterior al incidente |
La tabla ilustra que la mayor parte del costo no fue la restauración en sí, sino la corrección de la restauración. Si el ERD hubiera sido preciso, la restauración habría avanzado sin interrupciones.
Análisis técnico: ¿Por qué falló la secuencia de comandos 🛠️
Para comprender la gravedad del error, debemos analizar cómo interactuó la secuencia de comandos de restauración con el motor de base de datos. La secuencia siguió una secuencia estándar:
- Crear tablas basadas en las definiciones del ERD.
- Aplicar restricciones (claves primarias, claves foráneas).
- Verificar integridad.
3. Insertar datos.
Cuando la secuencia alcanzó el paso 2, intentó crear una restricción de clave foránea que vinculara Tabla A con Tabla B. El motor de base de datos escaneó Tabla B en busca de datos existentes. Encontró registros que violaban la restricción porque faltaba la clave principal. Debido a que la secuencia estaba diseñada para ser idempotente y segura, se detuvo en lugar de corromper los datos. Esta característica de seguridad, aunque beneficiosa para la integridad de los datos, se convirtió en un obstáculo para el cronograma de recuperación.
La secuencia no pudo continuar hasta que se limpiaron los datos en Tabla B fueron limpiados. Limpiar los datos requiere:
- Identificar los registros huérfanos.
- Decidir si eliminarlos o crear registros padres ficticios.
- Ejecutar la limpieza manualmente.
- Volver a ejecutar la creación de la restricción.
Cada paso en esta cadena añade tiempo. El diagrama ERD debería haber señalado el potencial de datos huérfanos durante la fase de diseño, lo que habría impulsado una estrategia de migración de datos en lugar de una simple replicación del esquema.
Lecciones aprendidas: Fortalecimiento del ciclo de vida del esquema 🔄
Tras el incidente, iniciamos una revisión rigurosa de nuestras prácticas de gestión de esquemas. Nos dimos cuenta de que depender de un documento estático para la recuperación ante desastres era insuficiente. Necesitábamos un enfoque dinámico y controlado por versiones para el diseño de esquemas.
Estas son las principales lecciones aprendidas del incidente:
- La documentación es código: El diagrama ERD no es un artefacto independiente; forma parte de la base de código. Debe someterse a los mismos procesos de control de versiones y revisiones que la lógica de la aplicación.
- Detección de desviación del esquema: Implementamos herramientas automatizadas para comparar el esquema de la base de datos en vivo con el diagrama ERD versionado. Cualquier desviación desencadena una alerta de inmediato.
- Pruebas de restauración: Ahora realizamos pruebas de restauración en un entorno de pruebas trimestralmente. Esto garantiza que el diagrama ERD refleje con precisión el camino de restauración.
- Relajación de restricciones: Ajustamos los scripts de restauración para deshabilitar temporalmente las restricciones de clave externa durante la carga inicial de datos, aplicándolas únicamente después de que se verifique toda la información.
Mejores prácticas para el mantenimiento del diagrama ERD 📝
Para evitar retrasos futuros, hemos adoptado un conjunto de mejores prácticas para mantener los diagramas de relaciones de entidades. Estos pasos garantizan que el plano permanezca válido durante todo el ciclo de vida del sistema.
1. Control de versiones para diagramas
Almacene los archivos del diagrama ERD en el mismo repositorio que el código fuente. Etiquete cada versión con una versión correspondiente del diagrama. Esto permite a los ingenieros recuperar el estado exacto del esquema en cualquier momento.
2. Generación automatizada
Donde sea posible, genere diagramas ERD directamente desde el esquema de la base de datos en lugar de dibujarlos manualmente. Esto reduce la posibilidad de errores humanos y garantiza que el diagrama siempre coincida con la realidad.
3. Auditorías regulares
Programa una auditoría trimestral del diagrama ERD. Compara el diagrama con el entorno de producción. Documenta cualquier cambio realizado fuera de la canalización estándar de despliegue.
4. Incluir notas sobre migración de datos
El diagrama ERD no debe mostrar solo tablas; debe mostrar la historia de los datos. Añada anotaciones al diagrama sobre datos que podrían quedar huérfanos o ser obsoletos. Esto informa al equipo de recuperación que debe esperar anomalías.
5. Revisión durante la planificación de sprints
Cuando una nueva funcionalidad requiere un cambio en la base de datos, el diagrama ERD debe actualizarse en el mismo ticket. No permita que se despliegue ningún cambio en el esquema sin una actualización correspondiente del diagrama.
El factor humano en los errores técnicos 🧑💻
Es fácil culpar al diagrama o al script, pero la causa raíz a menudo fue una brecha de comunicación. El desarrollador que añadió el nuevo campo no actualizó el diagrama. El ingeniero que revisó el código no verificó la documentación del esquema.
Los procesos técnicos solo son tan fuertes como las personas que los siguen. Introdujimos una lista de verificación para el despliegue que incluye una etapa de verificación del esquema. Cada despliegue debe incluir un informe de diferencias que muestre los cambios en la estructura de la base de datos. Esto obliga a que las modificaciones del esquema sean visibles.
Reflexiones finales sobre la resiliencia 🏗️
La recuperación ante desastres es una medida de nuestra preparación, no solo de nuestra reacción. El retraso de tres horas fue un síntoma de un problema mayor: la desconexión entre el diseño y la implementación. Al tratar el diagrama de relaciones de entidades como un componente vivo y activo de nuestra infraestructura, podemos reducir significativamente los tiempos de recuperación.
La integridad de los datos no es una característica; es una base. Cuando esa base se rompe, toda la estructura está en riesgo. Asegurar que nuestros planos sean precisos es el primer paso hacia una arquitectura resiliente. Debemos invertir tiempo en la documentación tanto como invertimos en el código.
Resumen de los elementos accionables ✅
- Auditar los ERD actuales:Compare toda la documentación con los esquemas en vivo de inmediato.
- Actualizar los scripts:Modifique los scripts de recuperación ante desastres para que manejen las violaciones de restricciones de forma adecuada.
- Capacitar a los equipos:Asegúrese de que todos los ingenieros entiendan la importancia de la documentación del esquema.
- Automatizar las verificaciones:Implemente herramientas que alerten sobre desviaciones en el esquema.
- Simular fallas:Realice pruebas regulares de recuperación ante desastres para verificar la precisión de la documentación.
Al adherirse a estas prácticas, podemos asegurarnos de que los incidentes futuros se resuelvan en minutos, no en horas. El costo de la precisión es mucho menor que el costo de corrección.