











En la evolución de la arquitectura de software, pocas dificultades son tan persistentes como la tensión entre el modelado histórico de datos y los requisitos modernos de escalabilidad. Muchas organizaciones se encuentran gestionando sistemas de backend construidos sobre diagramas de relaciones de entidades (ERD) diseñados hace años, a menudo bajo supuestos diferentes sobre carga, concurrencia y hardware. Cuando un esquema heredado enfrenta demandas de alta capacidad, la degradación del rendimiento no es meramente una molestia; es un fallo estructural. Esta guía explora las realidades técnicas de optimizar estos diagramas sin descartar la lógica empresarial incorporada en ellos.
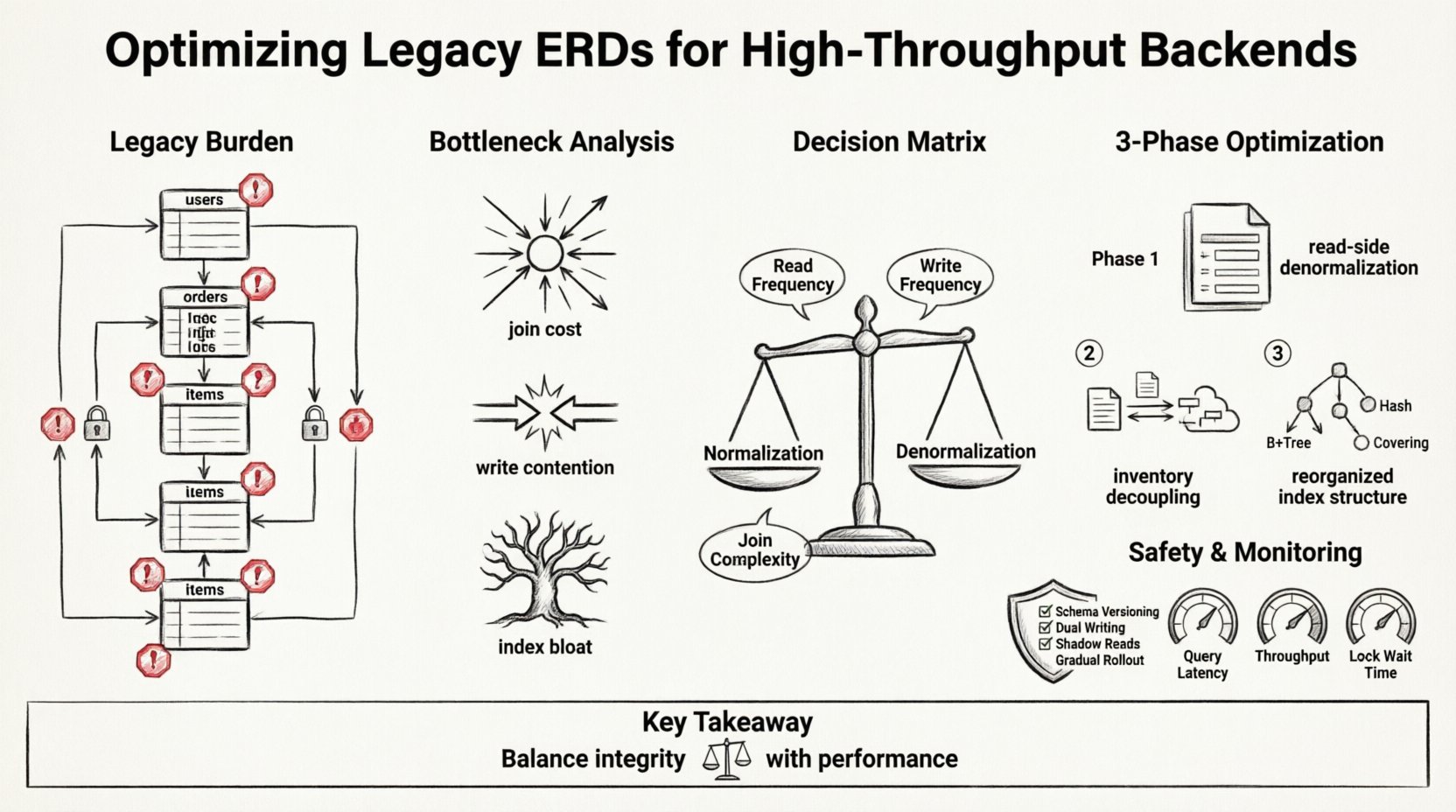
Comprendiendo la carga heredada 💾
Los ERD heredados a menudo reflejan las necesidades del pasado. Priorizan la integridad de los datos y la normalización por encima de todo. En un entorno de nodo único con tráfico moderado, este enfoque funciona bien. El cumplimiento estricto de la Tercera Forma Normal (3NF) minimiza la redundancia y garantiza la consistencia. Sin embargo, cuando el sistema escala hasta millones de transacciones por segundo, el costo de estas relaciones se vuelve prohibitivo.
Considere las siguientes características comunes encontradas en esquemas antiguos:
- Cadenas profundas de unión:Consultas que requieren cinco o más uniones para recuperar un solo registro.
- Restricciones de clave foránea pesadas:Verificaciones rígidas de integridad que bloquean escrituras concurrentes.
- Bloqueo centralizado:Puntos calientes en tablas específicas que se convierten en cuellos de botella durante cargas máximas.
- Brechas de denormalización:La falta de almacenes de datos redundantes para operaciones de lectura intensiva.
Estos patrones no son inherentemente «incorrectos». Fueron correctos para su época. El desafío radica en adaptarlos a un entorno distribuido y de alta concurrencia donde la latencia es la principal moneda.
Análisis de los cuellos de botella 🔍
Antes de alterar el diagrama, uno debe entender dónde el sistema pierde rendimiento. Los backends de alta capacidad suelen verse limitados por operaciones de E/S, latencia de red entre servicios y contención de bloqueos. El ERD determina cómo se accede a los datos, lo que influye directamente en estas métricas.
1. Costos de unión
Cada unión es una lectura en disco y un ciclo de CPU. En un sistema heredado, una sola solicitud de perfil de usuario podría desencadenar una cascada de búsquedas a través de cinco tablas. A medida que aumenta el tráfico, la base de datos pasa más tiempo navegando por relaciones que ejecutando lógica. Esto es especialmente cierto cuando los índices no pueden cubrir todo el camino de unión.
2. Contención de escritura
La normalización requiere escribir datos en múltiples ubicaciones para mantener la integridad. Si una transacción actualiza un perfil de usuario y registra un evento de actividad, dos tablas deben modificarse. Si estas tablas residen en el mismo shard, la duración del bloqueo aumenta. Si están distribuidas, la transacción se convierte en un compromiso de dos fases, añadiendo una sobrecarga significativa.
3. Hinchazón de índices
Para soportar uniones complejas, los sistemas heredados acumulan índices. Con el tiempo, estos índices ralentizan las operaciones de escritura. La base de datos debe actualizar cada índice en cada inserción o actualización. En escenarios de alta capacidad, esta amplificación de escritura puede saturar el subsistema de almacenamiento.
Estrategia de refactorización: Normalización frente a denormalización ⚖️
El núcleo de la optimización radica en replantear el equilibrio entre la integridad de los datos y la velocidad de consulta. Mientras que la normalización estricta garantiza la consistencia, los sistemas de alto rendimiento a menudo requieren una denormalización pragmática. Esto no significa abandonar la estructura; significa aceptar la redundancia para reducir la latencia.
La siguiente tabla describe la matriz de decisiones para cambios en el esquema:
| Criterios | Mantener normalizado | Aplicar denormalización |
|---|---|---|
| Frecuencia de lectura | Baja (procesamiento por lotes) | Alta (tableros en tiempo real) |
| Frecuencia de escritura | Alta (transacciones principales) | Baja (registros de auditoría) |
| Requisito de consistencia | ACID fuerte | Consistencia eventual aceptable |
| Complejidad de unión | Simple (1-2 uniones) | Compleja (3+ uniones) |
| Volatilidad de los datos | Estática (datos de referencia) | Dinámica (estado del usuario) |
Implementar esta estrategia requiere una planificación cuidadosa. No solo está cambiando tablas; está cambiando la forma en que la aplicación percibe los datos.
Recorrido del estudio de caso: Motor de transacciones de comercio electrónico 🛒
Para ilustrar este proceso, considere una plataforma de comercio electrónico ficticia. El sistema heredado maneja el procesamiento de pedidos, la gestión de inventario y los perfiles de clientes. El diagrama ERD fue diseñado para una única instancia de base de datos con enfoque en prevenir la venta excesiva de stock.
El estado heredado
En el diseño original, la pedidos tabla referenciaba items_de_pedidos, que referenciaba productos. La productos tabla referenciaba inventario. Para mostrar una página de detalles de pedido, el backend ejecutó una consulta que unía las cuatro tablas. Además, cada actualización de pedido requería un bloqueo en la tabla de inventario para garantizar precisión.
Problemas clave identificados:
- Latencia: Los tiempos de carga de la página aumentaron hasta 800 ms durante los eventos de venta.
- Fugas de bloqueo:Alta concurrencia en las actualizaciones de inventario provocó deshacer transacciones.
- Escalabilidad: La base de datos no pudo dividir el
inventariotabla debido a las frecuentes uniones entre particiones.
El proceso de optimización
El equipo decidió refactorizar el ERD en tres fases. El objetivo era desacoplar las rutas de lectura de las rutas de escritura.
Fase 1: Denormalización del lado de lectura
El primer paso consistió en crear una instantánea de los datos del producto dentro de los registros de pedidos. En lugar de unirse a la productos tabla en el momento de la consulta, el sistema copió el nombre del producto, el precio y el SKU en la order_items tabla en el momento de la compra.
- Beneficio: El historial de pedidos permanece preciso incluso si los datos del producto cambian más adelante.
- Beneficio: La consulta ya no requiere una unión con la tabla de productos.
- Riesgo: Diferencias de precio si un producto se actualiza después de que se coloca un pedido.
- Mitigación: La interfaz de usuario muestra el precio en el momento de la compra como «Precio histórico».
Fase 2: Desacoplamiento del inventario
La tabla de inventario era la fuente de conflicto. El equipo trasladó el seguimiento de inventario a una tienda de escritura separada y de alta frecuencia. El sistema de pedidos envía un mensaje asíncrono para reservar stock en lugar de ejecutar un bloqueo SQL síncrono.
- Beneficio: El rendimiento de escritura aumentó en un 400%.
- Beneficio: Ya no hay bloqueos en la transacción principal de pedidos.
- Compromiso: Se pueden realizar pedidos incluso si el inventario está momentáneamente desincronizado.
- Mitigación:Un proceso en segundo plano reconcilia las discrepancias entre el sistema de pedidos y el inventario.
Fase 3: Reestructuración de índices
Con datos denormalizados, los índices antiguos en claves foráneas se volvieron redundantes. El equipo los eliminó y agregó índices compuestos optimizados para los nuevos patrones de consulta. Por ejemplo, un índice en (customer_id, created_at) reemplazó la necesidad de escanear toda la tabla de pedidos.
Fases de implementación y seguridad 🛡️
Cambiar un esquema en producción es una operación de alto riesgo. Las siguientes fases aseguran la estabilidad durante la transición.
1. Versionado de esquema
No elimine las columnas antiguas de inmediato. Manténgalas en su lugar, pero márquelas como obsoletas. Esto permite que la aplicación se revierta si la nueva lógica falla. Use scripts de migración que agreguen columnas antes de eliminarlas.
2. Escritura dual
Durante la transición, escriba datos en ambas estructuras, la antigua y la nueva. La lógica de la aplicación redirige las lecturas a la nueva estructura, pero las escrituras van a ambas. Esto proporciona una alternativa si el nuevo esquema está incompleto.
3. Lecturas en sombra
Antes de redirigir el tráfico en vivo, ejecute las nuevas consultas en una copia de los datos de producción. Compare los resultados de las consultas heredadas con las consultas optimizadas para asegurar la precisión de los datos.
4. Implementación gradual
Use banderas de características para habilitar el nuevo esquema para un pequeño porcentaje de usuarios (por ejemplo, 1 %). Monitoree las tasas de error y la latencia. Si las métricas permanecen estables, aumente el porcentaje de forma incremental.
Monitoreo y validación 📊
La optimización no es un evento único. Requiere un monitoreo continuo para asegurar que los cambios resisten la carga. Deben establecerse indicadores clave de rendimiento (KPI) antes de comenzar la refactorización.
Métricas principales a monitorear:
- Latencia de consulta: Tiempos de respuesta del percentil 95 y 99.
- Rendimiento: Transacciones por segundo (TPS) sin errores.
- Tiempo de espera de bloqueo: Tiempo promedio que una transacción espera un bloqueo.
- Retardo de replicación: Retardo entre los nodos primarios y réplicas (si es aplicable).
- Ratio de aciertos en caché: Efectividad de las estrategias de caché de lectura.
Los umbrales de alerta deben establecerse basándose en las métricas de referencia recopiladas antes de los cambios. Si hay picos de latencia, el sistema debe revertir automáticamente al esquema heredado o redirigir el tráfico a un servicio de respaldo.
Errores comunes que debes evitar ⚠️
Aunque se cuente con un plan sólido, la deuda técnica a menudo resurge de formas inesperadas. Ten en cuenta estos errores comunes.
- Ignorar los costos de migración de datos:Mover terabytes de datos a nuevas estructuras lleva tiempo. Planifica ventanas de mantenimiento o herramientas de migración en segundo plano.
- Sobroptimizar las lecturas:Si normalizas demasiado, el rendimiento de escritura sufrirá. Equilibra la relación de lectura/escritura de tu carga de trabajo específica.
- Olvidar la lógica de la aplicación:El cambio de esquema es solo la mitad de la batalla. El código de la aplicación debe actualizarse para manejar la nueva estructura de datos.
- Descuidar las pruebas:Las pruebas unitarias cubren con frecuencia los caminos exitosos. Se requieren pruebas de estrés para detectar condiciones de carrera en el nuevo esquema.
Estrategias de mantenimiento a largo plazo 🔧
Una vez completada la optimización, el equipo debe mantener la nueva arquitectura. La documentación es crítica. Cada tabla, columna y relación debe etiquetarse con su propósito y responsabilidad.
Revisiones regulares:
Programa revisiones trimestrales del diagrama ERD. Identifica tablas que crecen de forma desproporcionada o consultas que se vuelven más lentas. El crecimiento de la base de datos revela a menudo nuevos cuellos de botella que no estaban presentes durante la refactorización inicial.
Verificaciones automáticas de esquema:
Integra la validación de esquema en la canalización CI/CD. Evita que los desarrolladores agreguen nuevas uniones o eliminen restricciones críticas sin aprobación. Esto garantiza que el sistema permanezca optimizado con el tiempo.
Capacitación del equipo:
Asegúrate de que todos los ingenieros de backend comprendan el nuevo modelo de datos. Una comprensión compartida del esquema reduce la probabilidad de introducir nueva deuda técnica mediante consultas ad hoc.
Reflexiones finales sobre el modelado de datos 🔗
Optimizar un diagrama de relaciones de entidades heredado es un equilibrio entre precisión histórica y escalabilidad futura. No existe un único esquema “correcto”. El modelo adecuado es aquel que apoya tus objetivos comerciales actuales y permite espacio para el crecimiento.
Al centrarte en los cuellos de botella específicos de tu sistema—ya sean costos de unión, contención de bloqueos o inflación de índices—puedes realizar mejoras dirigidas. El estudio de caso demuestra que incluso estructuras profundamente arraigadas pueden modernizarse sin una reescritura completa. La clave está en proceder de forma metódica, validar rigurosamente y mantener una visión clara de las compensaciones involucradas.
El modelado de datos no es estático. Evoluciona junto al tráfico que atiende. Trata tu ERD como un documento vivo que requiere el mismo cuidado y atención que el código que lo consulta. Con el enfoque adecuado, puedes transformar un sistema heredado en un motor de alto rendimiento capaz de manejar las demandas de la web moderna.