











Diseñar una arquitectura de datos sólida requiere una comprensión profunda de cómo se conectan, relacionan y persisten la información. En el centro de este diseño se encuentra el Diagrama de Relaciones de Entidades (ERD). Aunque tradicionalmente asociado con bases de datos relacionales, la semántica de los ERD ha evolucionado para adaptarse a las diversas necesidades de los entornos NoSQL modernos. Esta guía explora las sutilezas de modelar relaciones de datos entre diferentes paradigmas de almacenamiento, asegurando la integridad estructural sin sacrificar el rendimiento.
Conceptos fundamentales de modelado de datos 🏗️
Antes de adentrarnos en tipos específicos de bases de datos, es esencial establecer un vocabulario compartido. Un Diagrama de Relaciones de Entidades sirve como una plantilla visual. Define las entidades (tablas, colecciones o documentos), sus atributos (columnas, campos o propiedades) y las relaciones que las vinculan.
- Entidad: Un objeto o concepto distinto dentro del dominio empresarial. En un contexto de base de datos, podría ser un Usuario, un Producto o una Orden.
- Atributo: Una propiedad que describe la entidad. Ejemplos incluyen id, nombre, creado_en, o estado.
- Relación: La asociación entre dos entidades. Esto define cómo los datos en una entidad se conectan con los datos en otra.
- Cardinalidad: El aspecto numérico de una relación. Especifica si una relación es uno a uno, uno a muchos o muchos a muchos.
Al crear un ERD, el objetivo es representar la lógica del mundo real de la aplicación. Un diagrama bien construido reduce la ambigüedad para los desarrolladores y asegura que las consultas puedan escribirse de forma eficiente más adelante en el ciclo de desarrollo.
Semántica en entornos relacionales 🗃️
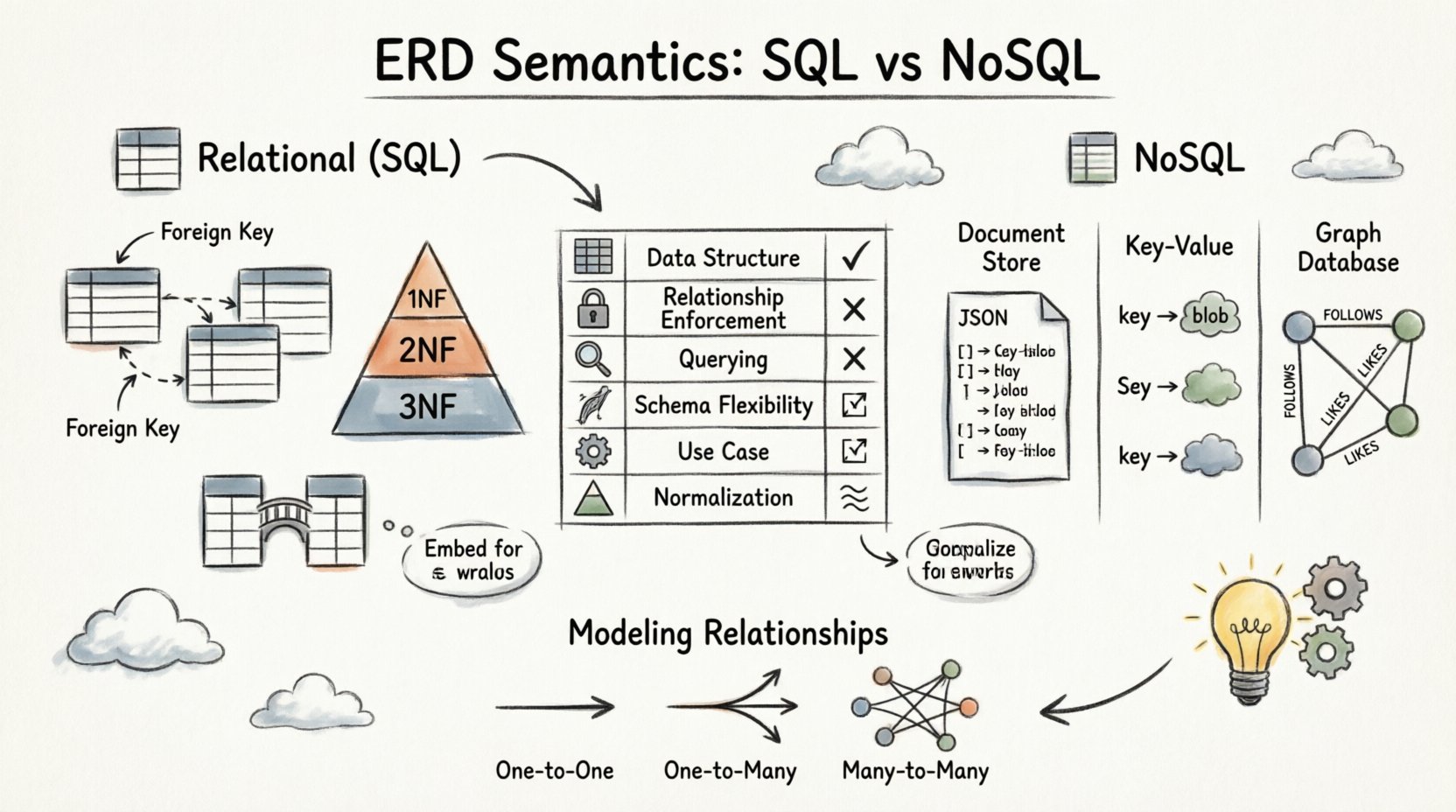
En el modelo relacional, los datos se almacenan en tablas con esquemas estrictos. La semántica del ERD aquí es rígida y gobernada por la teoría de conjuntos y los principios de la primera forma normal. Cada relación es impuesta por el motor de la base de datos para mantener la integridad referencial.
1. El papel de las claves foráneas
Las claves foráneas son la columna vertebral de los ERD relacionales. Enlazan físicamente las tablas entre sí. Cuando un ERD muestra una línea que conecta dos tablas, la implementación depende de una columna clave foránea en la tabla hija que hace referencia a la clave primaria de la tabla padre.
- Implementación: Un valor numérico o alfanumérico almacenado en una columna.
- Restricción: El motor de la base de datos evita registros huérfanos. No puedes insertar un valor en una columna de clave foránea a menos que exista en la clave primaria referenciada.
- En cascada: Las acciones en el registro padre (eliminar o actualizar) pueden propagarse automáticamente a los registros hijos según las reglas definidas.
2. Normalización e integridad
Los ERD relacionales priorizan la normalización. Este proceso reduce la redundancia de datos organizando los atributos en grupos lógicos. Un ERD bien normalizado suele parecer más complejo debido al número de tablas involucradas.
- 1FN: Garantiza la atomicidad; cada celda contiene un solo valor.
- 2FN: Elimina dependencias parciales; los atributos dependen de toda la clave primaria.
- 3FN: Elimina dependencias transitivas; los atributos no clave dependen únicamente de la clave primaria.
Esta estructura garantiza que los datos sean consistentes. Si un usuario cambia su nombre, se actualiza en un solo lugar, y todos los registros que hacen referencia a ese usuario ven el cambio inmediatamente.
3. Manejo de relaciones muchos a muchos
Las relaciones muchos a muchos son semanticamente distintas en los sistemas relacionales. No puedes enlazar directamente dos tablas en este caso. En su lugar, se requiere una tabla intermedia de unión.
- Estructura: Una tabla que contiene las claves primarias de ambas entidades relacionadas.
- Función: Esta tabla actúa como un puente, permitiendo que múltiples registros en la Entidad A se vinculen a múltiples registros en la Entidad B.
- Consulta: Recuperar estos datos requiere una
UNIÓNoperación, que puede ser computacionalmente costosa en conjuntos de datos grandes si no se indexa correctamente.
Semántica en entornos NoSQL 📦
Las bases de datos NoSQL ofrecen flexibilidad. La semántica del ERD cambia de un cumplimiento estructural a una representación lógica. El diagrama se convierte más en una guía de patrón de diseño que en una definición estricta de esquema. Diferentes modelos NoSQL manejan las relaciones de manera distinta.
1. Almacenes de documentos y anidamiento
En bases de datos orientadas a documentos, los datos se almacenan como documentos similares a JSON. El ERD suele sugerir anidar datos relacionados directamente dentro de un solo documento para optimizar el rendimiento de lectura.
- Uno a muchos: Un documento padre puede contener una matriz de objetos hijos. Esto evita la necesidad de uniones durante la recuperación.
- Implicación: Las actualizaciones de los datos hijos requieren volver a escribir todo el documento padre. Esto puede provocar contención si el documento padre se vuelve muy grande.
- Lectura frente a escritura: Este enfoque optimiza para lecturas. Intercambia el rendimiento de escritura y la redundancia de datos por velocidad.
2. Almacenes de clave-valor
Los almacenes de clave-valor tratan los datos como bloques opacos. Las semánticas del ERD aquí son mínimas. Las relaciones a menudo se infieren a nivel de la capa de aplicación en lugar de que lo haga el motor de la base de datos.
- Referencia:Los documentos a menudo contienen un ID de referencia a otro documento, similar a una clave foránea, pero sin aplicación de restricciones.
- Responsabilidad:La lógica de la aplicación debe asegurar que el ID referenciado exista y sea válido. No hay ninguna restricción a nivel de base de datos.
- Casos de uso:Ideal para caché, gestión de sesiones o estructuras de datos altamente flexibles donde las relaciones no son la principal preocupación.
3. Bases de datos de grafos
Las bases de datos de grafos están diseñadas específicamente para las relaciones. El ERD en este contexto se mapea directamente a nodos y aristas. Quizás esta sea la interpretación más literal de un Diagrama de Entidad-Relación.
- Nodos:Representan entidades (por ejemplo, Persona, Ubicación).
- Aristas:Representan relaciones (por ejemplo, VIVE_EN, CONOCE).
- Propiedades:Tanto los nodos como las aristas pueden tener atributos asociados.
- Recorrido:Las consultas siguen las aristas. Una relación no es una búsqueda; es un recorrido de camino.
Análisis comparativo de enfoques de modelado 📊
Comprender las diferencias entre estos entornos ayuda a elegir la herramienta adecuada para la tarea. La siguiente tabla describe cómo se traducen las semánticas del ERD en estos sistemas.
| Característica | Relacional (SQL) | Almacén de documentos | Base de datos de grafos |
|---|---|---|---|
| Estructura de datos | Tablas con filas y columnas | Documentos JSON | Nodos y aristas |
| Aplicación de relaciones | Claves foráneas (estrictas) | Manual / Nivel de Aplicación | Referencias de Arista Nativas |
| Consulta de Relaciones | Operaciones JOIN | Búsqueda o Incorporación | Recorrido de Camino |
| Flexibilidad de Esquema | Esquema Fijo | Esquema Dinámico | Semi-Estructurado |
| Casos de Uso Principales | Integridad de Transacciones | Gestión de Contenido / Jerarquías | Redes / Grafos Sociales |
| Normalización | Alta (3FN / BCNF) | Baja (Denormalizada) | No Aplicable |
Modelado de Relaciones: Una Profunda Exploración 🔗
La forma en que se representan las relaciones en un diagrama ER determina los patrones de consulta y las características de rendimiento de la aplicación. Examinemos ahora con detalle cardinalidades específicas.
Relaciones Uno a Uno
Esta es la relación más simple. Un registro en la tabla A corresponde exactamente a un registro en la tabla B.
- Implementación en SQL: Una clave foránea en cualquiera de las tablas con una restricción única.
- Implementación en NoSQL: A menudo combinado en un solo documento para evitar búsquedas, o almacenado por separado con una referencia única.
- Cuándo usarlo: Perfiles de usuario separados de los detalles de autenticación, o configuraciones vinculadas a entornos específicos.
Relaciones Uno a Muchos
Este es el tipo de relación más común. Un registro en la tabla A se relaciona con muchos registros en la tabla B.
- Implementación en SQL: Una clave foránea en la tabla B que hace referencia a la tabla A.
- Almacén de documentos: Incrusta el lado «Muchos» dentro del documento del lado «Uno» como una matriz. Esto es eficiente para leer toda la jerarquía de una vez.
- Base de datos de grafos: Crea una arista desde el nodo «Uno» hacia múltiples nodos «Muchos».
- Consideración: Si el lado «Muchos» crece significativamente, incrustar en un almacén de documentos podría alcanzar los límites de almacenamiento. Podría ser necesario un enfoque híbrido (referencias en lugar de incrustación).
Relaciones muchos a muchos
Esta relación requiere un puente en SQL, pero se comporta de manera diferente en otros sistemas.
- Implementación en SQL: Una tabla de unión que contiene identificadores de ambas tablas padres.
- Almacén de documentos: A menudo no normalizado. Cada documento contiene una lista de identificadores o objetos completos de la entidad relacionada. Esto duplica los datos pero acelera la recuperación.
- Base de datos de grafos: Esta es la fortaleza nativa del modelo. Los nodos están conectados directamente sin una tabla intermedia.
- Desafío de consistencia: En los almacenes de documentos, mantener las listas sincronizadas entre múltiples documentos es difícil. Las actualizaciones a una entidad compartida deben propagarse manualmente a todos los documentos que la referencian.
Evolución de esquemas y flexibilidad 🔄
Los requisitos de software cambian. Los modelos de datos deben evolucionar sin romper las aplicaciones existentes. Las semánticas del diagrama ERD determinan cuán fácilmente puede ocurrir esta evolución.
1. Migración de esquemas en SQL
Cambiar un esquema relacional es una operación importante. A menudo implica bloquear tablas o ejecutar migraciones durante tiempos de inactividad.
- Agregar columnas: Generalmente seguro y rápido.
- Renombrar columnas: Requiere reescribir la estructura de la tabla y actualizar todas las consultas dependientes.
- Cambiar tipos de datos: Puede ser riesgoso si la conversión de datos falla o si la lógica de la aplicación depende del tipo anterior.
2. Flexibilidad de esquemas en NoSQL
Los sistemas NoSQL generalmente permiten enfoques sin esquema o con esquema en la lectura. El diagrama ERD es una guía más que una ley.
- Añadiendo Campos:Puedes agregar nuevos campos a documentos específicos sin afectar a los demás.
- Versionado:Es común agregar números de versión a los documentos para gestionar diferentes estructuras con el paso del tiempo.
- Compromiso:La falta de cumplimiento significa que pueden surgir problemas de calidad de datos. La aplicación debe validar los datos antes de escribirlos.
Implicaciones de rendimiento de las decisiones de modelado ⚡
La estructura de tu ERD afecta directamente la velocidad de las consultas. No existe una solución única para todos los casos; el diseño debe alinearse con los patrones de acceso de la aplicación.
1. Cargas de trabajo con muchas lecturas
Si la aplicación lee datos con frecuencia pero actualiza con poca frecuencia, la desnormalización es beneficiosa.
- Estrategia:Incrusta datos relacionados para reducir el número de consultas necesarias.
- Beneficio:Menos operaciones de E/S y menor latencia.
- Costo:Uso aumentado de almacenamiento y lógica de actualización compleja.
2. Cargas de trabajo con muchas escrituras
Si la aplicación actualiza datos con frecuencia, se prefiere la normalización o el almacenamiento separado.
- Estrategia:Almacena los datos en su forma más atómica y realiza uniones o referencias en el momento de la consulta.
- Beneficio:Única fuente de verdad; las actualizaciones ocurren en un solo lugar.
- Costo:Latencia de lectura más alta debido a uniones o múltiples búsquedas.
3. Estrategias de indexación
Independientemente del tipo de base de datos, el ERD indica dónde se necesitan índices.
- Relacional:Los índices se colocan en claves foráneas y columnas utilizadas en
WHEREcláusulas. - Documento:Los índices se colocan en campos que se consultan con frecuencia. Los campos anidados pueden requerir una sintaxis de indexación específica.
- Gráfico:Los índices se colocan en las etiquetas de nodos y en las propiedades de aristas para acelerar los puntos de inicio de la navegación.
Entornos híbridos y persistencia políglota 🧩
Las arquitecturas modernas a menudo utilizan múltiples tecnologías de bases de datos simultáneamente. Esto se conoce como persistencia políglota. La semántica del ERD debe cerrar estas brechas.
1. Patrones de consistencia de datos
Cuando los datos abarcan múltiples sistemas, la consistencia se vuelve compleja.
- ACID:Las bases de datos relacionales ofrecen consistencia fuerte. Las transacciones abarcan múltiples tablas dentro de la misma base de datos.
- BASE:Las bases de datos NoSQL suelen favorecer la disponibilidad y la consistencia eventual. Las transacciones pueden estar limitadas a un solo documento.
- Patrón Saga:Para transacciones distribuidas entre sistemas, un patrón saga gestiona operaciones de larga duración coordinando transacciones locales.
2. El papel del ERD en sistemas híbridos
El ERD actúa como un mapa conceptual. Define las relaciones lógicas, incluso si el almacenamiento físico difiere.
- Mapeo:Los desarrolladores utilizan el ERD para decidir qué datos van a cada almacén.
- Integración:El diagrama ayuda a visualizar dónde es necesaria la sincronización de datos entre sistemas.
- Documentación:Proporciona una vista unificada para los interesados que podrían no entender las diferencias técnicas entre los motores de almacenamiento.
Mejores prácticas para un modelado de datos robusto 🛡️
Para garantizar la mantenibilidad y el rendimiento a largo plazo, adhiera a estos principios al diseñar sus ERD.
- Entienda el dominio:Comience con los requisitos del negocio. No modele datos que no apoyen un caso de uso específico.
- Elija la herramienta adecuada:Elija el tipo de base de datos según las relaciones de los datos, no solo por tendencias. Use grafos para redes complejas, documentos para contenido y SQL para transacciones.
- Documente las relaciones explícitamente:Etiquete claramente la cardinalidad en el diagrama. La ambigüedad conduce a errores de implementación.
- Planificación para el crecimiento:Considere cómo escalará el volumen de datos. ¿Se volverá demasiado grande una matriz incrustada? ¿Será una tabla de unión un cuello de botella?
- Iterar el diseño:Los ERD no son estáticos. Perfecciónelos a medida que evoluciona la aplicación y se descubren nuevas restricciones.
- Validar a nivel de la capa de aplicación:Especialmente en NoSQL, implemente lógica de validación para garantizar la integridad de los datos, ya que la base de datos podría no imponerla.
Conclusión sobre la semántica de modelado 📝
La semántica de un Diagrama de Entidad-Relación no es universal; se adapta a la tecnología de almacenamiento subyacente. En los sistemas relacionales, el ERD es un contrato impuesto por el motor de la base de datos. En los sistemas NoSQL, es una guía de patrones para la capa de aplicación. Comprender estas diferencias permite a los arquitectos diseñar sistemas que sean tanto escalables como consistentes.
Al analizar cuidadosamente la cardinalidad, elegir el modelo de almacenamiento adecuado y anticipar cambios futuros, los equipos pueden construir capas de datos que respalden lógicas de negocio complejas sin comprometer el rendimiento. La clave está en alinear el modelo lógico con las capacidades físicas del entorno elegido.
Ya sea que trabaje con tablas, documentos o grafos, los principios fundamentales para identificar entidades y definir sus conexiones permanecen constantes. Un ERD claro sirve como fundamento para una arquitectura de software confiable, cerrando la brecha entre los requisitos del negocio y la implementación técnica.