











Wydajność bazy danych często pozostaje niewidoczna, dopóki nie staje się krytycznym węzłem zatkania. Gdy użytkownicy doświadczają opóźnień, przekroczeń czasu lub niereagujących interfejsów, przyczyna problemu często kryje się pod powierzchnią warstwy aplikacji. Ona tkwi w architekturze samej danych. Projekt, który określa sposób strukturyzowania, powiązywania i przechowywania danych, to diagram relacji encji (ERD). Dobrze zaprojektowany ERD zapewnia integralność danych i skuteczne pobieranie. Z kolei błędny diagram wprowadza opóźnienia, które nie da się całkowicie rozwiązać nawet przy użyciu pamięci podręcznej na poziomie aplikacji.
Ten przewodnik zapewnia szczegółowe omówienie rozwiązywania problemów z powolnymi zapytaniami poprzez analizę podstawowego projektu schematu. Przeanalizujemy, jak decyzje strukturalne w ERD bezpośrednio wpływają na plany wykonania zapytań, operacje wejścia/wyjścia oraz ogólną reaktywność systemu. Zrozumienie mechanizmów projektowania relacyjnego pozwala diagnozować problemy wydajności w ich źródle, a nie tylko leczyć objawy.
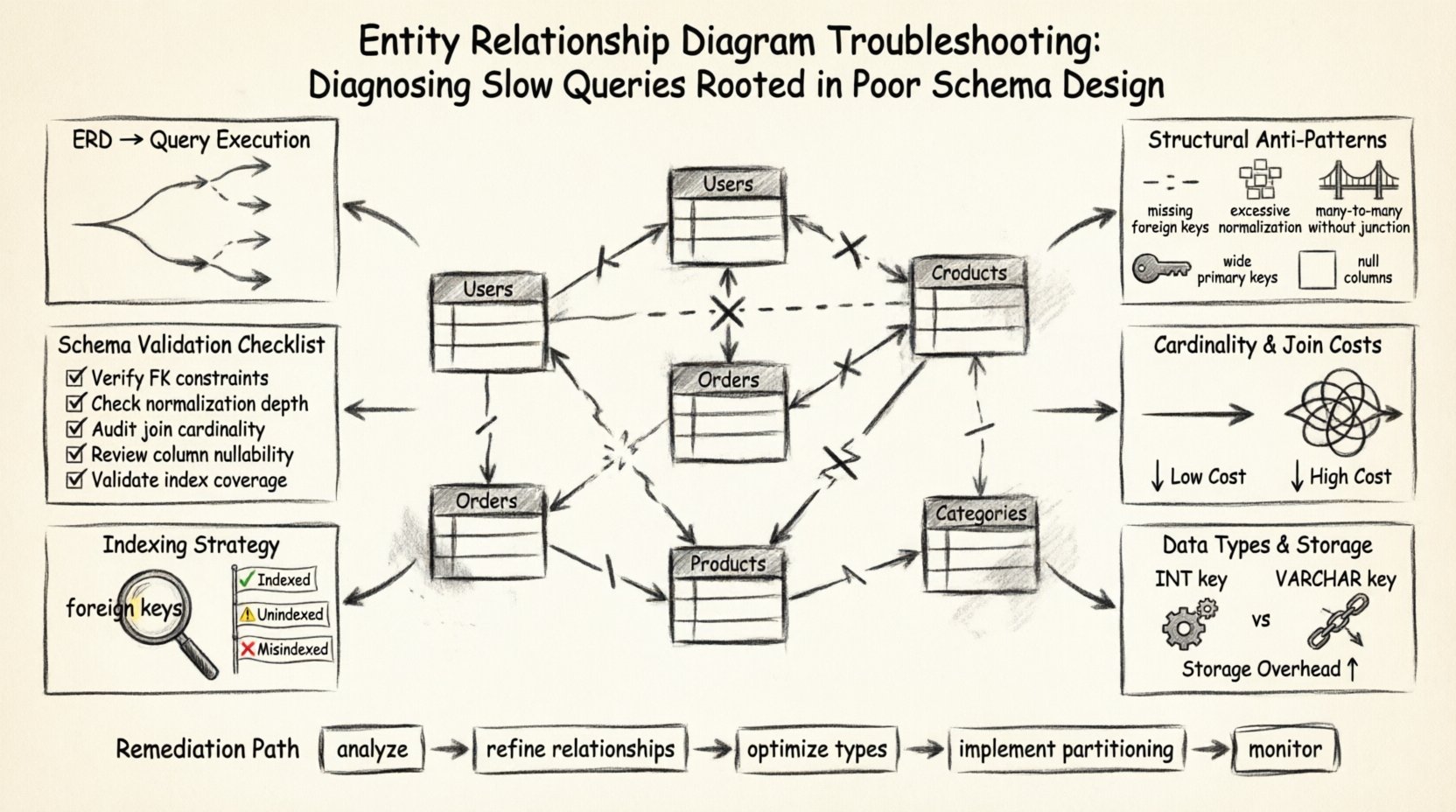
🏗️ Podstawa: Jak ERD wpływają na wykonanie zapytań
Zanim zdiagnozujesz problem, konieczne jest zrozumienie związku między wizualnym przedstawieniem danych a fizycznym wykonaniem poleceń. ERD to nie tylko diagram do dokumentacji; to zestaw zasad, które silnik bazy danych musi stosować. Każda linia łącząca tabele, każde zdefiniowane ograniczenie oraz każdy określony typ danych decyduje o tym, jak silnik przechowywania odczytuje i zapisuje informacje.
Gdy zapytanie jest przesłane, optymalizator bazy danych analizuje żądanie w stosunku do metadanych schematu. Jeśli schemat jest niejasny lub nieefektywny, optymalizator może wybrać nieoptymalną drogę. Często manifestuje się to jako pełne skanowanie tabeli zamiast wyszukiwania indeksu, albo zagnieżdżone połączenie pętli, które wykładniczo zwiększa czas przetwarzania.
Kluczowe obszary, w których ERD wpływa na wydajność, obejmują:
- Złożoność połączeń: Liczba zdefiniowanych relacji decyduje o liczbie połączeń wymaganych do pobrania powiązanych danych.
- Ograniczenia integralności danych:Klucze obce i ograniczenia unikalności dodają narzut do operacji zapisu, ale mogą zoptymalizować operacje odczytu.
- Poziomy normalizacji:Stopień podziału danych na tabele wpływa na objętość danych skanowanych podczas pobierania.
- Strategia indeksowania:Projekt schematu określa, gdzie logicznie można umieścić indeksy w celu wspierania typowych wzorców zapytań.
🔍 Identyfikowanie antypatternów strukturalnych
Wiele problemów z wydajnością wynika z wzorców, które były akceptowalne w fazie początkowego projektowania, ale stają się obciążeniem wraz ze wzrostem objętości danych. Te antypatterny często wydają się subtelne na diagramie, ale powodują istotne tarcie w silniku zapytań. Poniżej znajduje się analiza typowych wad strukturalnych i ich bezpośredniego wpływu na prędkość.
| Antypattern | Wizualny wskaźnik na ERD | Wpływ na wydajność |
|---|---|---|
| Brak kluczy obcych | Linie łączące tabele bez definicji ograniczeń. | Zezwala na pozostawione rekordy, zmuszając złożone zapytania do ręcznego filtrowania nieprawidłowych danych. |
| Zbyt duża normalizacja | Duża liczba tabel z relacjami jedno-kolumnowymi. | Wymaga nadmiernych połączeń do odtworzenia jednego logicznego obiektu, zwiększając zużycie procesora. |
| Wiele do wielu bez tabeli pośredniej | Bezpośrednie linie relacji wiele do wielu między dwoma encjami. | Silniki baz danych zwykle wymagają tabeli pośredniej; jej brak prowadzi do nieefektywnych obejść. |
| Szerokie klucze podstawowe | Klucze złożone z wielu dużych kolumn. | Zwiększa rozmiar wszystkich indeksów odnoszących się do tego klucza, spowalniając wyszukiwanie. |
| Kolumny wypełnione wartościami NULL | Atrybuty oznaczone jako dopuszczające wartości NULL bez uzasadnienia logicznego. | Może zapobiegać używaniu indeksów lub zmniejszać selektywność indeksu, prowadząc do pełnych skanowań. |
🔗 Moc relacji i koszty łączenia
Moc relacji określa, ile wystąpień jednego obiektu jest powiązanych z wystąpieniami innego obiektu. Jest to najważniejszy aspekt ERD w kontekście wydajności zapytań. Niepoprawne definicje mocy relacji zmuszają system do przetwarzania więcej wierszy niż jest to konieczne, aby spełnić zapytanie.
Podczas rozwiązywania problemów z wolnymi zapytaniami musisz zweryfikować, czy relacje na schemacie odpowiadają wymaganiom logicznym aplikacji. Jeśli relacja jest zdefiniowana jako wiele do wielu, gdy powinna być jedna do wielu, silnik zapytań przygotuje się do połączenia poprzez tabelę pośrednią, która może nie istnieć lub być wypełniona nieefektywnie.
Typowe problemy z mocą relacji
- Nieokreślona moc relacji: Jeśli schemat nie określa, czy relacja jest obowiązkowa czy opcjonalna, optymalizator zapytań może założyć najgorszy przypadek, dodając dodatkowe sprawdzanie wartości NULL.
- Relacje rekurencyjne:Tabele odnoszące się do siebie (np. tabela Employee odnosząca się do siebie dla menedżera) mogą powodować głębokie zagnieżdżenie w zapytaniach. Bez odpowiedniego indeksowania kolumny odnoszącej się do siebie, te zapytania stają się wykładniczo wolniejsze.
- Zależności cykliczne:Złożone sieci relacji, gdzie tabela A łączy się z B, B z C, a C zwraca się do A. Ta struktura utrudnia przeszukiwanie grafu danych dla silnika, często prowadząc do tworzenia tabel tymczasowych w pamięci.
Aby ograniczyć te problemy, upewnij się, że ERD jasno rozróżnia relacje opcjonalne i obowiązkowe. Relacje obowiązkowe pozwalają optymalizatorowi pominąć sprawdzanie wartości NULL, co poprawia szybkość wykonania. Relacje opcjonalne wymagają dodatkowej logiki do obsługi przypadków, gdy relacja nie istnieje.
📏 Typy danych i wydajność przechowywania
Wybór typów danych w definicji schematu ma istotny wpływ na rozmiar przechowywania i szybkość porównania. Zapytanie porównujące dwie kolumny o różnych typach często wywołuje niejawne konwersje. Te konwersje uniemożliwiają używanie indeksów i zmuszają silnik do przetwarzania każdego wiersza.
Skutki przechowywania
Gdy schemat używa ogólnego typu danych dla wszystkich kolumn, np. dużego pola tekstowego dla krótkich kodów, zużywa więcej miejsca na dysku i pamięci. Zmniejsza to skuteczną wielkość puli buforów, co oznacza, że mniej stron danych z pamięci podręcznej może być przechowywanych w pamięci. W rezultacie system musi odczytywać więcej danych z wolniejszego podsystemu dysku.
Wydajność porównania
Porównania liczb całkowitych są znacznie szybsze niż porównania ciągów znaków. Jeśli ERD definiuje klucz obcy jako ciąg (np. VARCHAR) zamiast liczby całkowitej (np. INT), operacja łączenia musi porównywać znak po znaku, zamiast używać porównania numerycznego binarnego. To dodaje cykle procesora do każdego przetworzonego wiersza.
- Używaj typów o stałej długości: Dla pól takich jak kody krajów lub flagi stanu używaj ciągów o stałej długości. Ciągi zmiennej długości wprowadzają narzut przy obliczaniu długości przy każdym odczycie.
- Unikaj dużych tekstów w kluczach: Nigdy nie używaj kolumny z dużą ilością tekstu jako klucza głównego lub obcego. Powoduje to rozszerzanie każdego indeksu, który na nią odnosi się.
- Dopasuj typy rodzica i dziecka: Upewnij się, że typ danych w tabeli potomnej dokładnie odpowiada typowi w tabeli rodzicielskiej. Nawet niewielka różnica (np. INT vs BIGINT) może wymusić konwersję podczas łączeń.
🔑 Widoczność indeksowania i strategia
ERD to wizualne przedstawienie struktury logicznej, ale powinien również wpływać na strategię indeksowania fizycznego. Choć indeksy często dodaje się po zbudowaniu schematu, faza projektowania powinna przewidywać, gdzie są potrzebne. Zapytanie filtrowane według kolumny, która nie jest indeksowana, jest głównym wskaźnikiem luki w projekcie.
Możliwości indeksowania w ERD
Przy przeglądaniu diagramu pod kątem węzłów wydajnościowych, szukaj kolumn, które często są używane w warunkach wyszukiwania lub łączeniach.
- Klucze obce: Powinny być indeksowane prawie zawsze. Jeśli zapytanie łączy Table A z Table B za pomocą klucza obcego, a klucz w Table B nie jest indeksowany, silnik musi przeszukać całą Table B dla każdego wiersza w Table A.
- Flagi stanu: Kolumny definiujące stan rekordu (np. Is_Active, Order_Status) często są używane w klauzulach WHERE. Jeśli nie są indeksowane, filtrowanie staje się pełnym przeszukiwaniem tabeli.
- Zakresy dat: Tabele z dziennikami audytu lub logami transakcji często są zapytywane według daty. Kolumna daty powinna być indeksowana, aby umożliwić skuteczne przeszukiwanie zakresów.
Kluczowe jest zrównoważenie liczby indeksów pod kątem wydajności operacji zapisu. Każdy indeks dodaje narzut do operacji INSERT, UPDATE i DELETE. Jednak źle indeksowana schemat z dużym obciążeniem odczytu spowoduje opóźnienia systemowe, które przewyższają koszt zapisu. ERD pomaga wizualizować, które tabele są obciążone odczytem (np. tabele wyszukiwania) w porównaniu do tych obciążonych zapisem (np. logi transakcji), co prowadzi do decyzji dotyczącej indeksowania.
🚫 Patologia łączenia
Jednym z najczęściej występujących źródeł wolnych zapytań jest ścieżka łączenia. Odnosi się to do kolejności, w jakiej silnik bazy danych łączy tabele w celu spełnienia żądania. Źle zaprojektowany schemat może zmusić silnik do wyboru ścieżki logicznie poprawnej, ale obliczeniowo kosztownej.
Iloczyny kartezjańskie
Jeśli schemat nie zawiera odpowiednich ograniczeń lub logika zapytania nie określa poprawnie warunków łączenia, silnik może wygenerować iloczyn kartezjański. Zdarza się to, gdy każdy wiersz w Table A jest połączony z każdym wierszem w Table B. Rozmiar zestawu wyników rośnie wykładniczo, a zapytanie może przekroczyć czas limit lub zużyć całą dostępną pamięć.
W ERD zdarza się to często, gdy relacja wiele do wielu nie jest odpowiednio pośredniczona przez tabelę pośrednią, albo gdy tabela pośrednia nie zawiera niezbędnych ograniczeń kluczy obcych.
Podzapytanie w porównaniu do łączenia
Projektowanie schematu wpływa na to, czy zapytanie może być wykonane jako proste łączenie, czy wymaga podzapytania. Podzapytania często wykonują zapytanie wewnętrzne raz dla każdego wiersza zapytania zewnętrznego, co prowadzi do złożoności czasowej kwadratowej. Zazwyczaj preferowane jest znormalizowane podejście, które umożliwia bezpośrednie łączenia, w porównaniu do zdeformowanych struktur wymuszających podzapytania.
✅ Lista sprawdzania poprawności schematu
Aby systematycznie diagnozować wolne zapytania oparte na ERD, wykonaj szczegółową analizę. Ta lista kontrolna zapewnia, że przebadasz każdy kluczowy element projektu.
1. Przejrzyj ograniczenia kluczy obcych
- Czy wszystkie klucze obce są jawnie zdefiniowane na diagramie?
- Czy zawierają zasady kaskadowe, które mogą spowodować niechciane przemieszczanie danych?
- Czy typ danych po obu stronach relacji jest identyczny?
2. Analizuj częstotliwość łączeń
- Zidentyfikuj tabele, które są łączone ze sobą najczęściej w logice aplikacji.
- Czy te tabele są sąsiednie na diagramie, czy ścieżka wymaga przeszukiwania wielu pośrednich tabel?
- Czy któreś z tych pośrednich tabel można połączyć, aby zmniejszyć głębokość łączenia?
3. Sprawdź możliwość wartości NULL
- Czy kolumny, które nigdy nie mogą mieć wartości NULL, są jawnie oznaczone jako NOT NULL?
- Czy schemat pozwala na wartości NULL w kolumnach, które są częścią indeksu?
4. Zweryfikuj typy danych
- Czy pola numeryczne używają najmniejszego odpowiedniego rozmiaru (np. TINYINT w porównaniu do BIGINT)?
- Czy pola tekstowe używają odpowiedniej długości, aby uniknąć obcinania lub nadmiarowego przechowywania danych?
5. Ocena pokrycia indeksów
- Czy klucze główne i klucze obce mają indeksy?
- Czy często filtrowane kolumny są indeksowane?
- Czy istnieje indeks złożony dla typowych zapytań wielokolumnowych?
🛠️ Prawdziwe kroki naprawcze
Po analizie ERD i wykryciu problemów następny etap to naprawa. Obejmuje on modyfikację schematu w celu dopasowania do wymagań wydajnościowych bez naruszania integralności danych.
Udoskonal relacje: Jeśli ERD pokazuje nadmiernie złożone relacje, rozważ ich uproszczenie. Może to oznaczać wprowadzenie denormalizacji w określonych obszarach o wysokim obciążeniu odczytu, aby zmniejszyć potrzebę łączenia tabel. Na przykład przechowywanie zapisanej liczby powiązanych elementów w tabeli nadrzędnej może usunąć konieczność łączenia i liczenia za każdym razem.
Optymalizuj typy danych: Zmień typy danych na bardziej wydajne alternatywy. Jeśli data jest przechowywana tylko z dokładnością do dnia, użyj typu tylko daty zamiast daty i godziny. Jeśli identyfikator jest numeryczny, upewnij się, że nie jest przechowywany jako ciąg znaków.
Wprowadź partycjonowanie: Dla bardzo dużych tabel ERD może wymagać odzwierciedlenia strategii partycjonowania. Choć partycjonowanie często jest szczegółem implementacji fizycznej, projekt logiczny powinien uwzględniać sposób grupowania danych. Partycjonowanie według daty lub regionu pozwala silnikowi skanować tylko odpowiednie fragmenty danych.
🔎 Ostateczne rozważania
Naprawa problemów z wydajnością to proces iteracyjny. ERD pełni rolę centralnego elementu w tym procesie. Traktując schemat jako żywy dokument, który odzwierciedla zarówno strukturę logiczną, jak i ograniczenia wydajności fizycznej, możesz utrzymać system bazodanowy, który pozostaje reaktywny w miarę wzrostu danych.
Pamiętaj, że żaden jeden projekt nie nadaje się do wszystkich scenariuszy. Schemat zoptymalizowany pod wysoką częstotliwość zapisów może działać inaczej niż schemat zoptymalizowany pod złożone zapytania analityczne. Celem jest dopasowanie projektu schematu do konkretnych wzorców dostępu aplikacji. Regularnie przeglądaj ERD pod kątem rzeczywistych metryk wydajności zapytań, aby wczesnie wykryć odchylenia.
Skupiając się na integralności strukturalnej modelu danych, eliminujesz przyczyny opóźnień. Ten podejście jest bardziej zrównoważone niż stosowanie poprawek na poziomie warstwy aplikacji. Solidna podstawa schematu zapewnia, że system może skalować się, dostosowywać i działać niezawodnie przez dłuższy czas.
Kontynuuj monitorowanie planów wykonania zapytań po wprowadzeniu zmian. Wizualizacja planu wykonania może potwierdzić, że optymalizator poprawnie wykorzystuje nowe indeksy i ograniczenia. Ten cykl zwrotny uzupełnia cykl rozwiązywania problemów, zapewniając, że teoretyczne ulepszenia w ERD przekładają się na rzeczywiste zyski wydajności w środowisku produkcyjnym.