











Projektowanie architektury danych dla dużego systemu backendowego to podstawowa czynność, która decyduje o trwałości i stabilności całej aplikacji. Diagram relacji encji, często skrótowo nazywany ERD, pełni rolę projektu dla tej architektury. Wizualnie przedstawia strukturę danych, definiując sposób, w jaki różne fragmenty informacji łączą się, są powiązane i oddziałują na siebie w systemie. W kontekście przedsiębiorstwa, gdzie spójność danych, integralność i skalowalność są kluczowe, przestrzeganie ustanowionych standardów ERD nie jest tylko najlepszą praktyką; jest koniecznością.
Bez znormalizowanego podejścia do modelowania danych systemy backendowe są narażone na niewydolność. Niespójne konwencje nazewnictwa, niejasne relacje oraz słabe normalizowanie mogą prowadzić do węzłów przepustowości, trudnych cyklów utrzymania oraz uszkodzeń danych. Niniejszy przewodnik omawia kluczowe standardy i metodyki wymagane do tworzenia wytrzymały systemów baz danych odpowiednich dla skomplikowanych środowisk przedsiębiorstw. Przeanalizujemy podstawowe elementy, systemy oznaczeń, zasady normalizacji oraz strategie zarządzania, które zespoły zawodowe stosują, aby zapewnić, że ich warstwy danych pozostają wiarygodne przez długie lata.
Podstawowe elementy ERD dla przedsiębiorstwa 🧩
Zanim przejdziemy do konkretnych standardów, konieczne jest zrozumienie podstawowych elementów, z których składa się ERD. Każdy diagram w środowisku zawodowym opiera się na trzech głównych elementach. Te elementy działają razem, aby opisać strukturę logiczną danych.
- Encje: Odnoszą się do rzeczywistych obiektów lub pojęć, o których przechowywane są dane. W kontekście backendu encja często odpowiada bezpośrednio tabeli bazy danych. Przykłady toKlient, Zamówienie, lubProdukt. Encje muszą być jasno zdefiniowane, aby zapewnić, że każdy rekord ma unikalne identyfikator.
- Atrybuty: Atrybuty opisują konkretne właściwości lub cechy encji. Odpowiadają kolumnom w tabeli. Dla encjiKlient atrybuty mogą obejmowaćIDKlienta, ImięiNazwisko, orazAdresEmail. Poprawne definiowanie typów danych dla atrybutów jest kluczowe dla integralności danych.
- Relacje: Relacje definiują sposób, w jaki encje oddziałują na siebie. Ustanawiają ograniczenia i powiązania między tabelami. Na przykład pojedynczyKlient może złożyć wieleZamówień. Ta relacja określa ograniczenia kluczy obcych oraz logikę łączenia wymagane w backendzie.
W rozwoju systemów klasy enterprise te elementy nie są tylko abstrakcyjnymi pojęciami; są podstawą optymalizacji zapytań, kontroli dostępu oraz strategii migracji danych. Dobrze dokumentowany ERD pozwala programistom zrozumieć przepływ danych bez konieczności analizowania każdej linii kodu.
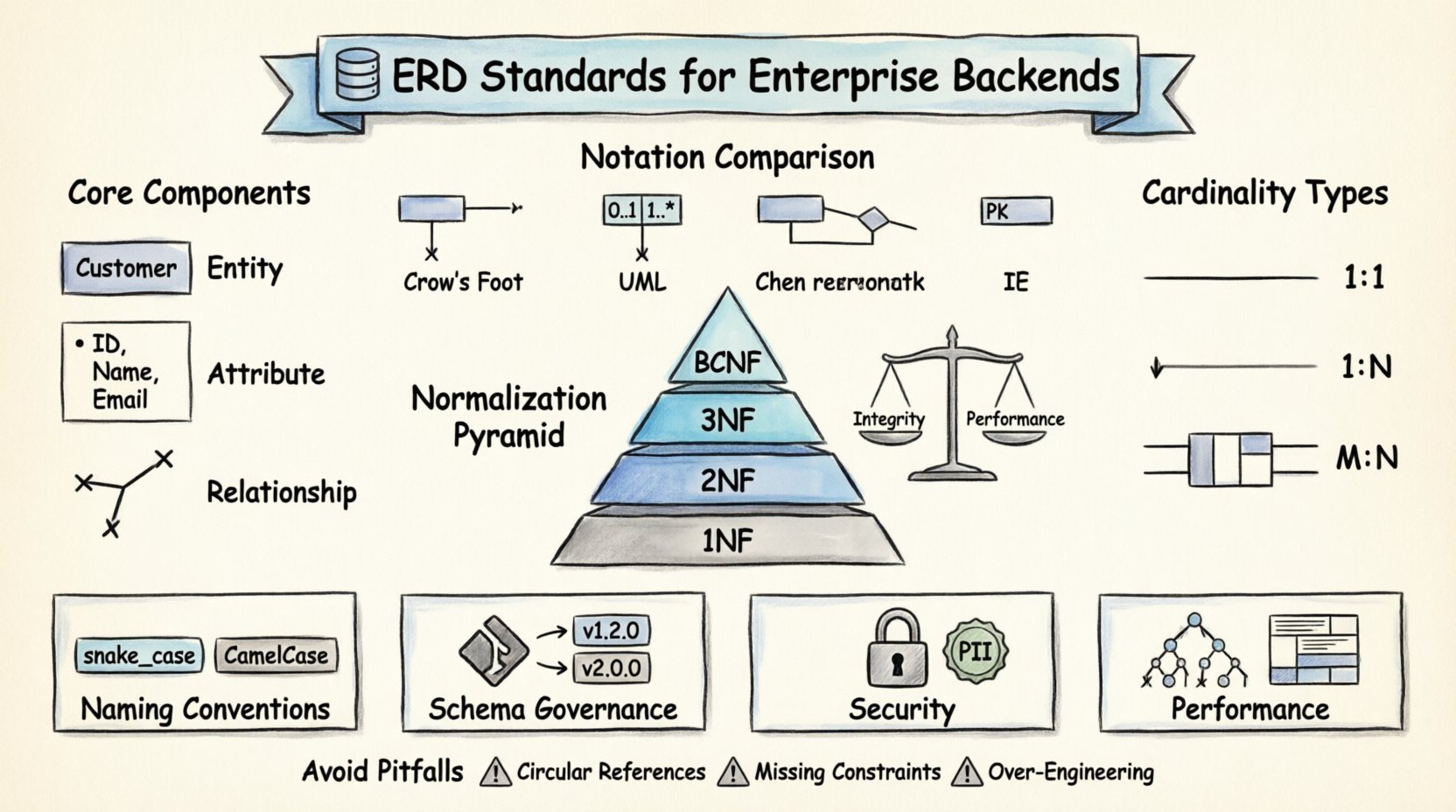
Standardy notacji i konwencje wizualne 📐
Nie ma jednego uniwersalnego składni dla rysowania diagramów ERD, ale istnieją szeroko przyjęte standardy zapewniające przejrzystość i spójność między różnymi zespołami. Wybór notacji i jej przestrzeganie to kluczowe decyzje zarządzania.
Notacja Chen vs. Notacja kłykci
Historически notacja Chen była standardem, używając prostokątów do przedstawiania encji i rombów do relacji. Choć jasna, jest mniej powszechna w nowoczesnych narzędziach do tworzenia oprogramowania. Notacja kłykci stała się preferowaną w branży z kilku powodów:
- Jasność w kardynalności: Używa określonych symboli (linii, kół i „łap”) do wizualnego oznaczania relacji jeden do jednego, jeden do wielu i wiele do wielu.
- Wsparcie narzędziowe: Większość nowoczesnych narzędzi do projektowania baz danych i narzędzi do odwrotnej inżynierii obsługuje domyślnie notację kłykci lub symbole pochodzące z UML.
- Czytelność: Jest zazwyczaj bardziej skondensowana i łatwiejsza do odczytania podczas pracy z złożonymi, wzajemnie powiązanymi schematami.
Porównanie systemów notacji
| Styl notacji | Reprezentacja encji | Reprezentacja relacji | Najlepsze zastosowanie |
|---|---|---|---|
| Kłykci | Prostokąt | Linie z symbolami (kłykci, koło, linia) | Projektowanie baz danych relacyjnych |
| Diagram klas UML | Pudełko klasy z kompartmentami | Strzałki z mnożnikami (0..1, 1..*) | Modelowanie obiektowe |
| Chen | Prostokąt | Kształt rombu łączący encje | Modele akademickie/teoretyczne |
| IE (Inżynieria informacji) | Prostokąt z atrybutami | Linie z oznaczeniami kluczy głównych | Dokumentacja systemu dziedziczonego |
Dla backendów przedsiębiorstw ogólnie zaleca się notację Crow’s Foot ze względu na jej bezpośrednią mapę na ograniczenia relacyjne. Minimalizuje niepewność podczas interpretacji diagramu przez programistów podczas implementacji.
Normalizacja: zapewnianie integralności danych 🔄
Normalizacja to proces organizowania danych w bazie danych w celu zmniejszenia nadmiarowości i poprawy integralności danych. Choć nowoczesne systemy czasem deznormalizują dane dla wydajności, zrozumienie zasad normalizacji jest kluczowe do projektowania solidnej początkowej schematu.
Formy normalne
- Pierwsza forma normalna (1NF): Każda kolumna musi zawierać wartości atomowe. Lista wartości w jednym polu jest zabroniona. Zapewnia to, że każda intersekcja wiersza i kolumny zawiera pojedynczy, niepodzielny fragment danych.
- Druga forma normalna (2NF): Tabela musi znajdować się w 1NF, a wszystkie atrybuty niekluczowe muszą być całkowicie zależne od klucza głównego. Zapobiega to częściowym zależnościom, gdy kolumna zależy tylko od części klucza złożonego.
- Trzecia forma normalna (3NF): Tabela musi znajdować się w 2NF, a nie może istnieć zależność przechodnia. Atrybuty niekluczowe nie powinny zależeć od innych atrybutów niekluczowych. Na przykład, jeśli Miasto zależy od Kod pocztowy, a Kod pocztowy zależy od ID, Miasto powinno zostać przeniesione do osobnej tabeli.
- Forma normalna Boyce’a-Codda (BCNF): Strictejsza wersja 3NF. Wymaga, aby dla każdej zależności funkcyjnej X → Y, X było nadkluczem. Pozwala rozwiązać pewne przypadki graniczne w 3NF, gdzie wyznacznik jest kluczem kandydującym, ale nie kluczem głównym.
Zalety i wady normalizacji
| Poziom | Zaleta | Koszt |
|---|---|---|
| Wysoka normalizacja (3NF/BCNF) | Minimalna nadmiarowość, wysoka integralność | Wymagane więcej łączeń dla zapytań |
| Niska normalizacja (denormalizowana) | Szybsza wydajność odczytu | Wyższe ryzyko niezgodności danych |
Systemy przedsiębiorstw typowo dążą do 3NF w swoich schematach transakcyjnych. Gdy wydajność odczytu staje się węzłem szybkości, denormalizacja jest stosowana selektywnie do określonych widoków lub tabel raportujących, a nie do głównego schematu transakcyjnego.
Zasady nazewnictwa i higiena schematu 🏷️
Spójna zasada nazewnictwa jest kluczowa dla utrzymywania systemu. Gdy wiele zespołów pracuje nad tym samym backendem, niejasność w nazewnictwie prowadzi do błędów. Standard powinien być zapisany i wspierany za pomocą narzędzi do analizy kodu lub skryptów weryfikacji schematu.
Zasady nazewnictwa tabel
- Liczba mnoga vs. liczba pojedyncza: Istnieje dyskusja, ale kluczowe jest zachowanie spójności. Imiona liczby mnogiej (np. Użytkownicy, Zamówienia) często brzmią lepiej w zdaniach angielskich. Imiona liczby pojedynczej (np. Użytkownik, Zamówienie) często są preferowane w kontekstach obiektowych. Wybierz jedną i stosuj ją globalnie.
- Podkreślenia vs. CamelCase: Podkreślenia (snake_case) to standard dla identyfikatorów SQL. CamelCase (camelCase) jest powszechny w kodzie aplikacji. Upewnij się, że warstwa bazy danych i warstwa aplikacji zgadzają się na strategię tłumaczenia.
- Unikaj słów kluczowych zarezerwowanych: Nigdy nie nadawaj nazwy tabeli ani kolumny za pomocą zarezerwowanych słów kluczowych bazy danych (np. Grupa, Wybór, Zamówienie). Zapobiega błędom składni w trakcie generowania zapytań.
- Prefiksy dla metadanych: Używaj prefiksów takich jak _audit, _log, lub _temp aby odróżnić tabele pomocnicze od głównych jednostek biznesowych.
Zasady nazewnictwa kolumn
- Klucze obce: Jasno wskazuj relację. Jeśli kolumna odnosi się do tabeli Użytkownicy nazwij ją user_id zamiast uid lub fk_user.
- Flagi logiczne: Używaj prefiksów takich jak is_ lub has_. Na przykład, is_active lub has_subscription.
- Pola daty i czasu: Określ zakres. Użyj utworzono_w lub zaktualizowano_w zamiast ogólnego data lub czas.
Relacje i liczność 🔄
Zrozumienie liczności to różnica między działającą bazą danych a uszkodzoną. Liczność określa dokładną liczbę wystąpień jednej encji, które mogą lub muszą być powiązane z każdym wystąpieniem innej encji.
Typy relacji
- Jeden do jednego (1:1): Jedno wystąpienie encji A jest powiązane dokładnie z jednym wystąpieniem encji B. Jest to rzadkość w podstawowej logice biznesowej, ale powszechne dla danych bezpieczeństwa lub konfiguracji. Przykład: Użytkownik ma jedno Profil.
- Jeden do wielu (1:N): Jedno wystąpienie encji A jest powiązane z wieloma wystąpieniami encji B. Jest to najpowszechniejsza relacja. Przykład: Jedna Dział ma wielu Pracowników.
- Wiele do wielu (M:N): Wiele wystąpień encji A jest powiązanych z wieloma wystąpieniami encji B. Wymaga to tabeli pośredniej (encji asocjacyjnej). Przykład: Studenci i Przedmioty.
Opcjonalność i ograniczenia
Mocność nie mówi całej historii; opcjonalność to. Odnosi się to do tego, czy relacja jest obowiązkowa czy opcjonalna.
- Wymagane (Wymagane uczestnictwo): Instancja encji musi być powiązana z inną. Na przykład, Zamówienia musi mieć Klienta.
- Opcjonalne (Opcjonalne uczestnictwo): Instancja encji może istnieć bez relacji. Na przykład, Produkt może istnieć bez Zamówienia rekordu jeszcze.
Wymuszanie tych reguł na poziomie bazy danych za pomocą ograniczeń (NOT NULL, klucze obce) jest znacznie bardziej niezawodne niż wymuszanie ich w kodzie aplikacji. Chroni przed rozjazdem danych i zapewnia, że schemat pozostaje źródłem prawdy.
Zarządzanie schematem i kontrola wersji 📜
W środowiskach przedsiębiorstw schemat bazy danych to kod. Musi być wersjonowany, przeglądarkowany i zarządzany z taką samą starannością jak kod źródłowy aplikacji. Diagram ER nie jest dokumentem statycznym; ewoluuje wraz z zmianami wymagań biznesowych.
Strategie migracji
- Zgodność z przyszłością: Zmiany powinny być zaprojektowane tak, aby dopasować się do starych danych. Unikaj natychmiastowego usuwania kolumn; zamiast tego oznacz je jako przestarzałe.
- Zgodność wsteczna: Nowe wersje schematu nie powinny naruszać istniejących zapytań. Używaj widoków, aby ukryć zmiany przed warstwą aplikacji.
- Zmiany atomowe: Każdy skrypt migracji powinien reprezentować pojedynczą zmianę logiczną. Ułatwia to cofnięcie zmian, jeśli wystąpi błąd.
Utrzymanie dokumentacji
ERD, który nie jest aktualizowany, stanowi obciążenie. Upewnij się, że proces generowania diagramu jest automatyzowany. Optymalnie ERD powinien być generowany bezpośrednio z plików definicji schematu (DML), aby zapobiec rozbieżnościom między dokumentacją a rzeczywistym stanem bazy danych.
- Automatyzuj generowanie ERD przy każdym zatwierdzeniu.
- Wymagaj przeglądu schematu w procesie żądania zmiany (pull request).
- Oznacz główne wersje schematu, aby były zgodne z wydaniami aplikacji.
Zagadnienia bezpieczeństwa i prywatności 🔒
Backendy przedsiębiorstw obsługują poufne informacje. Faza projektowania ERD musi uwzględniać wymagania dotyczące bezpieczeństwa i prywatności, szczególnie w kontekście informacji identyfikujących osobę (PII).
Klasyfikacja danych
- Dane publiczne:Informacje, które mogą być udostępniane otwarcie. Nie wymagają specjalnej obsługi.
- Dane wewnętrzne:Informacje przeznaczone wyłącznie dla pracowników. Należy rozważyć stosowanie list kontroli dostępu (ACL).
- Dane ograniczone:Czułe dane, takie jak hasła, rekordy medyczne lub informacje finansowe. Te pola wymagają szyfrowania w stanie spoczynku i w trakcie przesyłania.
Maskowanie i anonimizacja
W ERD oznacz pola, które wymagają maskowania w środowiskach nieprodukcyjnych. Pomaga to programistom zrozumieć, które kolumny wymagają specjalnej obsługi podczas testów. Choć sam diagram nie wprowadza zabezpieczeń, kieruje implementacją zasad bezpieczeństwa.
- Jawnie zidentyfikuj kolumny zawierające PII.
- Zdefiniuj pola audytu (np. last_modified_by) w celu śledzenia, kto uzyskał dostęp lub zmienił dane.
- Upewnij się, że klucze obce nie ujawniają wewnętrznych identyfikatorów, które mogłyby zostać przeanalizowane.
Planowanie wydajności i skalowalności 🚀
Choć ERD skupia się na strukturze, musi również uwzględniać wydajność. Schemat logicznie poprawny, ale fizycznie wolny, nie wytrzyma obciążenia.
Strategia indeksowania
Relacje zdefiniowane w ERD wskazują, gdzie są potrzebne indeksy. Klucze obce powinny być indeksowane, aby przyspieszyć łączenia i sprawdzanie ograniczeń. Jednak nadmiarowe indeksowanie może spowolnić operacje zapisu.
- Klucze podstawowe: Zawsze indeksowane.
- Klucze obce: Zawsze indeksowane w celu poprawy wydajności łączeń.
- Kolumny wyszukiwania: Kolumny często używane w klauzulach WHERE powinny mieć indeksy.
Partycjonowanie i rozmieszczanie danych
Dla dużych zbiorów danych, ERD może sugerować strategie partycjonowania. Jeśli dane są naturalnie grupowane (np. według Region lub Daty), powinno to być odzwierciedlone w projekcie schematu. Pozwala to bazie danych rozprowadzać obciążenie na wiele fizycznych węzłów.
Typowe pułapki do unikania ⚠️
Nawet doświadczone zespoły popełniają błędy. Rozpoznawanie typowych wzorców niepowodzeń pomaga w budowaniu odpornego systemu.
- Cykliczne odniesienia: Unikaj relacji, w których Encja A zależy od B, a B zależy od A, tworząc pętlę, która utrudnia usuwanie lub aktualizację danych.
- Brakujące ograniczenia: Opieranie się na kodzie aplikacji w celu wymuszania reguł (np. zapewnienie, że Cena jest dodatnia) jest ryzykowne. Używaj ograniczeń CHECK w bazie danych.
- Zbyt duża złożoność projektowa: Nie modeluj każdego możliwego przyszłego scenariusza. Projektuj zgodnie z obecnymi wymaganiami, z wystarczającą elastycznością do dostosowania, ale unikaj tworzenia tabel dla hipotetycznych przypadków użycia.
- Wartości zakodowane w kodzie: Unikaj przechowywania kodów stanu jako liczb całkowitych bez tabeli odnośnika. Używaj tabeli referencyjnej dla statusów takich jak StatusZamówienia aby zachować jasność.
Wdrażanie standardów w swoim procesie pracy 🛠️
Wprowadzenie tych standardów wymaga zmiany kultury. Nie wystarczy po prostu narysować schematu; schemat musi kierować procesem rozwoju.
- Projektowanie najpierw: Wymagaj zatwierdzenia ERD przed napisaniem jakichkolwiek skryptów migracji.
- Przeglądy kodu: Włącz zmiany schematu do standardowego zestawu sprawdzania kodu.
- Szczegółowe szkolenia: Upewnij się, że wszyscy inżynierowie backendu rozumieją koncepcje normalizacji i liczby jednoznaczności.
- Narzędzia:Inwestuj w narzędzia do projektowania schematów, które wspierają współpracę i wersjonowanie.
Traktując diagram relacji encji jako żyjący, oddychający element architektury systemu, zespoły korporacyjne mogą zapewnić, że ich warstwy danych pozostają solidne. Wkład w standaryzowanie fazy projektowania przynosi korzyści w postaci zmniejszonego długu technicznego i poprawionej niezawodności systemu. Dobrze zorganizowana baza danych jest fundamentem, na którym buduje się skalowalne aplikacje.
Gdy stawiasz priorytetem przejrzystość, spójność i integralność w modelowaniu danych, tworzysz fundament wspierający rozwój. Standardy przedstawione tutaj zapewniają ramy dla tego fundamentu. Ich przestrzeganie gwarantuje, że Twój backend pozostaje utrzymywalny, bezpieczny i wydajny w miarę rozwoju Twojej organizacji.