











W świecie architektury oprogramowania nieliczne pojęcia mają takie znaczenie jak diagram relacji encji (ERD). Jest to projekt Twoich danych, mapa prowadząca programistów przez skomplikowaną przestrzeń tabel, kluczy i relacji. Gdy aplikacja działa powoli, pierwszą reakcją często jest oskarżenie schematu. Założenie jest jasne: jeśli diagram jest idealny, wydajność musi być idealna.
To powszechny błąd. 🧐 Choć dobrze zaprojektowany ERD jest podstawą, nie jest jedynym rozwiązaniem dla szybkości. Idealny model logiczny nie przekłada się automatycznie na szybką realizację fizyczną. Zrozumienie różnicy między teorią projektowania a rzeczywistością działania w czasie rzeczywistym jest kluczowe dla budowy systemów, które pozostają reaktywne pod presją.
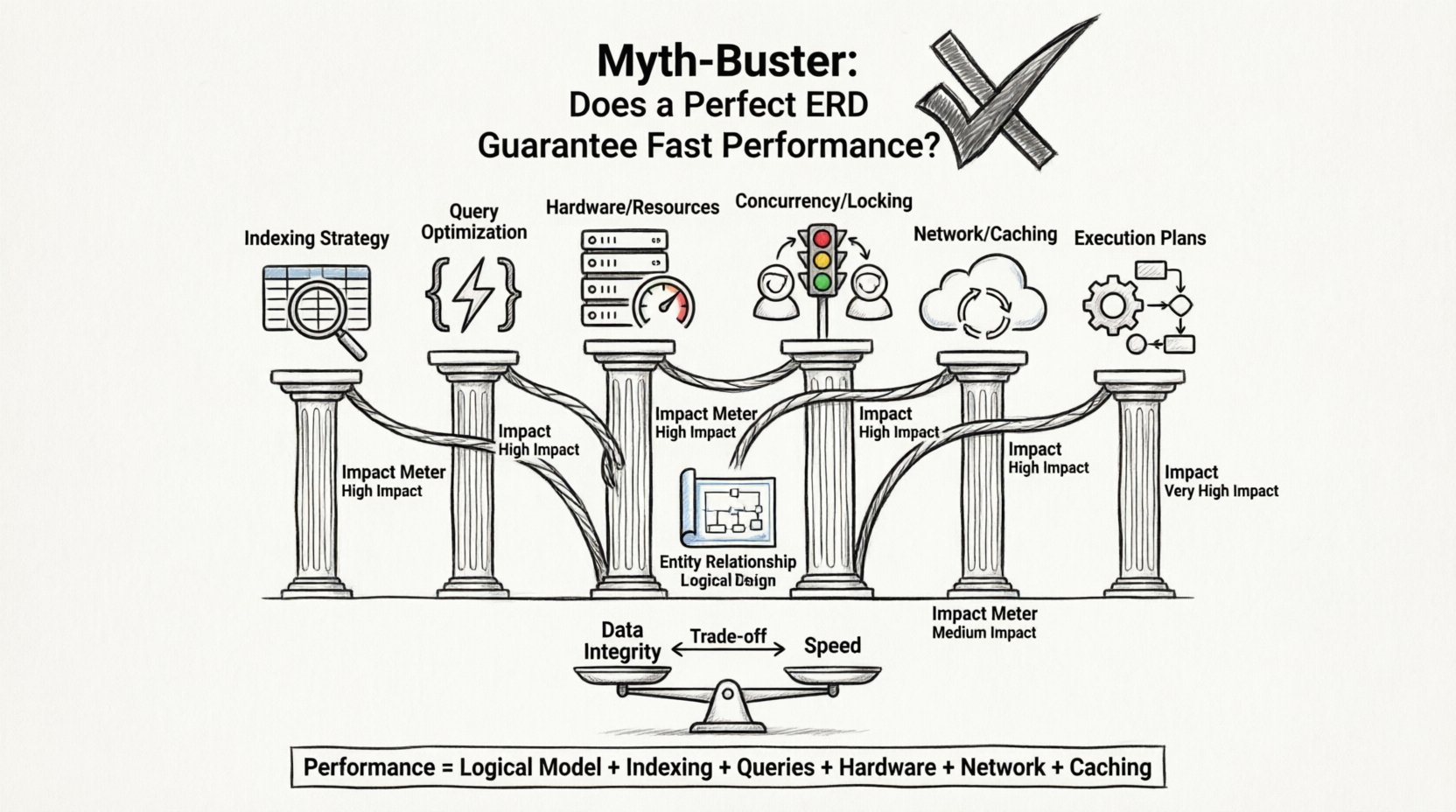
Ten przewodnik wyjaśnia, dlaczego idealny ERD nie gwarantuje szybkich czasów odpowiedzi, oraz jakie inne kluczowe czynniki wpływają na wydajność bazy danych. Przeanalizujemy warstwy obsługi danych – od silników przechowywania po opóźnienia sieciowe – aby ujawnić prawdziwe czynniki wydajności aplikacji.
📐 Zrozumienie diagramu relacji encji
Zanim przejdziemy do metryk wydajności, musimy wyjaśnić, co dokładnie oznacza ERD. ERD to artefakt logiczny. Opisujeco dane istnieją ijak są ze sobą powiązane. Definiuje encje (tabelki), atrybuty (kolumny) i relacje (klucze obce).
- Encje:Obiekty z rzeczywistego świata przedstawione jako tabele.
- Atrybuty:Cechy tych obiektów przechowywane w kolumnach.
- Relacje:Połączenia między encjami, często wymuszane za pomocą kluczy głównych i obcych.
- Moc relacji:Relacja liczbowo między encjami (jeden do jednego, jeden do wielu).
Głównym celem ERD jest integralność danych. Zapewnia, że dane pozostają spójne, dokładne i użyteczne przez dłuższy czas. Zapobiega istnieniu zaniedbanych rekordów i utrzymuje integralność referencyjną. Jednak integralność nie jest tym samym co prędkość. Zamek, który trzyma drzwi zamknięte, chroni zawartość w środku, ale nie sprawia, że drzwi otwierają się szybciej.
⚡ Równanie wydajności: poza schematem
Czas odpowiedzi aplikacji to suma wielu składników. Baza danych to tylko jedna część tego równania. Nawet jeśli silnik bazy danych pobiera dane natychmiast, aplikacja może nadal wydawać się wolna z powodu węzłów zakleszczenia w innych miejscach.
Oto kluczowe czynniki wpływające na prędkość, które często przeważają nad projektem schematu:
1. Strategia indeksowania
ERD definiuje klucze główne i obce, które często generują indeksy automatycznie. Jednak te domyślne indeksy rzadko są wystarczające dla złożonych zapytań. Wydajność zależy w dużej mierze od indeksów pomocniczych dopasowanych do konkretnych wzorców zapytań.
- Brakujące indeksy:Bez indeksu na kolumnie często używanej w filtracji, baza danych musi wykonać pełne skanowanie tabeli. Odczytuje każdy wiersz, co jest wykładniczo wolniejsze na dużych zestawach danych.
- Nadmiarowe obciążenie indeksów:Zbyt wiele indeksów spowalnia operacje zapisu. Każde wstawienie lub aktualizacja wymaga aktualizacji każdego indeksu powiązanego z tą tabelą.
- Wybieralność:Indeks na kolumnie o niskiej wybieralności (np. płeć lub status) może zostać zignorowany przez optymalizator zapytań.
2. Optymalizacja zapytań
Sposób żądania danych ma większą wartość niż sposób ich przechowywania. Źle napisane zapytanie może zniszczyć idealny schemat. Najczęstsze problemy to:
- Problemy N+1:Pobieranie rekordu nadrzędnego, a następnie pętla po nim w celu pobrania dzieci pojedynczo. Powoduje to wiele przejść do bazy danych zamiast jednego JOIN.
- Użycie SELECT *:Pobieranie wszystkich kolumn zwiększa ruch sieciowy i zużycie pamięci, nawet jeśli potrzebna jest tylko jedna.
- Niejawne konwersje:Porównywanie ciągu znaków z liczbą lub daty z znacznikiem czasu może uniemożliwić używanie indeksów.
- Złożone JOIN-y:Łączenie wielu dużych tabel bez odpowiedniego filtrowania znacznie zwiększa obciążenie obliczeniowe.
3. Sprzęt i infrastruktura
Efektywność oprogramowania nie może przekonać ograniczeń fizycznych. Podstawowy sprzęt wyznacza górny limit wydajności.
- Typ magazynowania:Dyski SSD są znacznie szybsze niż dyski HDD w przypadku operacji I/O losowych.
- Pamięć (RAM):Jeśli zestaw danych w użyciu mieści się w pamięci RAM, zapytania są prawie natychmiastowe. Jeśli dane muszą być pobierane z dysku, opóźnienie rośnie.
- Moc procesora:Złożone obliczenia, sortowanie i agregacja wymagają mocy przetwarzania.
- Opóźnienie sieciowe:Odległość między serwerem aplikacji a serwerem bazy danych dodaje milisekundy do każdego żądania.
4. Współbieżność i blokady
Gdy wiele użytkowników jednocześnie uzyskuje dostęp do systemu, baza danych musi zarządzać konfliktami. To właśnie tutaj wydajność często spada.
- Konflikty blokad:Jeśli jedna transakcja trzyma blokadę na wierszu, inne muszą czekać. Wysokie zawieszenie prowadzi do wygaśnięć i wolnych czasów odpowiedzi.
- Zamknięcia:Dwie transakcje czekające na siebie mogą spowodować zatrzymanie całego systemu.
- Poziomy izolacji:Wyższe poziomy izolacji (np. Serializable) zapewniają silniejsze gwarancje, ale zmniejszają współbieżność i szybkość.
📊 Wpływ ERD na inne czynniki wydajności
Aby wizualnie przedstawić wpływ ERD w porównaniu do innych zmiennych, rozważ następującą analizę. Ta tabela wyróżnia miejsca, w których ERD przynosi wartość, oraz te, w których się nie sprawdza.
| Czynnik | Wpływ na prędkość odczytu | Wpływ na prędkość zapisu | Rola ERD |
|---|---|---|---|
| Struktura schematu tabeli | Średnio | Średnio | Określa relacje i normalizację. |
| Indeksowanie | Wysoki | Niski | ERD definiuje klucze, ale nie wszystkie indeksy. |
| Logika zapytań | Bardzo wysoki | Średnio | ERD nie określa składni zapytań. |
| Zasoby sprzętowe | Wysoki | Wysoki | Brak. Niezależne od schematu. |
| Opóźnienie sieciowe | Wysoki | Średnio | Brak. Niezależne od schematu. |
| Pule połączeń | Średnio | Średnio | Brak. Konfiguracja aplikacji. |
🧱 Zastrzeżenie w normalizacji
Jednym z najbardziej dyskutowanych tematów w projektowaniu baz danych jest normalizacja. ERD zwykle dąży do trzeciej postaci normalnej (3NF), aby zmniejszyć nadmiarowość. Choć pozwala to zaoszczędzić miejsce i zapewnić spójność, może negatywnie wpływać na wydajność.
Gdy dane są bardzo znormalizowane, pojedynczy fragment informacji jest przechowywany w jednym miejscu. Aby go pobrać, system musi przejść przez wiele połączeń JOIN. Każde połączenie dodaje obciążenie obliczeniowe.
Wyobraź sobie sytuację, w której chcesz wyświetlić profil użytkownika wraz z jego najnowszym zamówieniem i szczegółami produktu. W znormalizowanym modelu ERD może to wymagać połączenia czterech tabel. Jeśli te tabele są duże, procesor zużywa znaczną ilość czasu na sortowanie i dopasowywanie wierszy.
Denormalizacja to technika stosowana w celu przeciwdziałania temu. Polega na duplikowaniu danych w celu zmniejszenia potrzeby używania połączeń JOIN. Poprawia to szybkość odczytu, ale komplikuje operacje zapisu i zwiększa ryzyko niezgodności danych. Doskonały model ERD nie decyduje automatycznie, gdzie narysować tę granicę. Jest to decyzja strategiczna oparta na stosunku odczyt/zapis.
🔍 Głęboka analiza: plany wykonania zapytań
Silnik bazy danych nie wykonuje zapytań dokładnie tak, jak zostały napisane. Analizuje żądanie i generuje plan wykonania. Ten plan określa kolejność operacji, które indeksy użyć oraz czy wykonać skanowanie czy wyszukiwanie.
Model ERD dostarcza metadane dotyczące typów danych i ograniczeń. Jednak optymalizator używa statystyk dotyczących rozkładu danych do podejmowania decyzji. Jeśli statystyki są przestarzałe, optymalizator może wybrać plan podkrotny, ignorując najlepsze dostępne indeksy.
Na przykład, jeśli tabela ma 10 milionów wierszy, a statystyki zakładają, że ma 100, optymalizator może uznać, że pełne skanowanie jest tańsze niż wyszukiwanie po indeksie. To prowadzi do wolnej wydajności mimo dobrze zbudowanego modelu ERD.
🛡️ Integralność danych wobec szybkości
Istnieje inherentna sprzeczność między zapewnieniem integralności danych a maksymalizacją szybkości. Model ERD wymusza zasady integralności, takie jak ograniczenia i wyzwalacze.
- Ograniczenia kluczy obcych: Zapewniają integralność referencyjną. Przy usuwaniu lub aktualizacji system musi sprawdzić powiązane tabele. To dodaje opóźnienie operacjom zapisu.
- Wyzwalacze: Automatyczne skrypty uruchamiane przy zmianach danych. Choć przydatne do logiki, dodają czas przetwarzania do każdej transakcji.
- Ograniczenia unikalności: Wymagają od systemu sprawdzenia istniejących wartości przed wstawieniem nowych.
W systemach o wysokim przepływie te sprawdzania czasem są wyłączane lub odłożone, aby poprawić szybkość. Doskonały model ERD zawiera wszystkie te zasady, ale system o wysokiej wydajności może wymagać zmodyfikowanego podejścia.
🚦 Prawdziwe kroki w optymalizacji
Jeśli Twoja aplikacja działa wolno, nie rysuj od razu ponownie modelu ERD. Postępuj systematycznie, aby zidentyfikować węzeł zatkania.
1. Analiza wolnych zapytań
Włącz rejestrowanie zapytań, aby przechwytywać długie zapytania. Użyj narzędzi profilowania, aby zobaczyć, gdzie zużywany jest czas. Czy czeka na blokady? Czy skanuje wiersze? Czy przetwarza logikę?
2. Przegląd użycia indeksów
Sprawdź, które indeksy są faktycznie używane. Nieużywane indeksy zużywają pamięć i spowalniają zapisy. Twórz indeksy dopasowane do klauzul WHERE i JOIN w Twoich często wykonywanych zapytaniach.
3. Optymalizacja przydziału zasobów sprzętowych
Upewnij się, że serwer bazy danych ma wystarczająco dużo pamięci RAM do buforowania zestawu roboczego. Jeśli baza danych jest ograniczona pamięcią, dodanie więcej RAM da natychmiastowe efekty. Jeśli jest ograniczona procesorem, może być konieczne uaktualnienie procesora lub optymalizacja kodu.
4. Wprowadzenie buforowania
Nie każde żądanie musi trafiać do bazy danych. Użyj pamięci wewnętrznej (takiej jak Redis lub Memcached) do danych często dostępnego. Pozwala to całkowicie ominąć bazę danych podczas operacji odczytu.
5. Monitorowanie współbieżności
Monitorowanie czekania na blokady. Jeśli użytkownicy doświadczają przekroczeń czasu, przejrzyj długość transakcji. Utrzymuj transakcje krótkie, aby szybko zwolnić blokady.
🔄 Rola ewolucji schematu
Aplikacje się zmieniają. Wymagania się przesuwają. Schemat ERD musi ewoluować wraz z działalnością biznesową. Schemat, który był idealny sześć miesięcy temu, może dziś być przestarzały z powodu nowych funkcji lub wzrostu objętości danych.
Strategie migracji mają znaczenie. Przenoszenie danych z małej tabeli do dużej tabeli z partycjami może poprawić wydajność. Zmiana typów danych z VARCHAR na INTmoże zmniejszyć zużycie pamięci i poprawić szybkość przeszukiwania. Te decyzje są podejmowane po utworzeniu początkowego ERD.
Statyczne ERD nie uwzględniają wzrostu danych. Wraz ze skalowaniem danych zmieniają się charakterystyki wydajności. Projekt, który działał przy 10 000 rekordach, może zawieść przy 10 milionach. Dlatego optymalizacja wydajności to ciągły proces, a nie jednorazowa czynność.
🧩 Uwagi dotyczące NoSQL
Pojęcie ERD stosuje się najbardziej ściśle do baz danych relacyjnych. W środowiskach NoSQL model danych jest inny. Magazyny dokumentów, magazyny par klucz-wartość i bazy danych grafowych obsługują relacje inaczej.
W magazynie dokumentów dane mogą być osadzone, aby uniknąć łączeń. To symuluje denormalizację na potrzeby projektu. W bazie danych grafowych relacje są obiektami pierwszej kategorii, przechowywanymi jawnie w celu optymalizacji przeszukiwania.
Mityczne przekonanie, że ERD gwarantuje poprawność, jest tu jeszcze bardziej wyraźne. W NoSQL schemat często jest elastyczny lub dynamiczny. Wydajność zależy w dużej mierze od wzorców dostępu zdefiniowanych w kodzie aplikacji, a nie od sztywnego schematu.
🏁 Ostateczne rozważania na temat architektury danych
Tworzenie szybkiej aplikacji wymaga kompleksowego podejścia. ERD to kluczowy punkt wyjścia, zapewniający logiczne uporządkowanie danych. Zapobiega chaosowi i utrzymuje integralność. Jednak nie jest to silnik, który napędza szybkość.
Wydajność to wynik synergii między:
- Solidnym modelem logicznym.
- Strategicznym indeksowaniem.
- Skutecznym pisaniem zapytań.
- Wystarczającymi zasobami sprzętowymi.
- Poprawną konfiguracją sieci.
- Skutecznymi strategiami buforowania.
Przypisywanie powodu wolnych odpowiedzi schematowi to skrót, który prowadzi do błędnych rozwiązań. Doskonały schemat na papierze nie może zrekompensować wolnego dysku, przekroczenia czasu sieciowego lub źle napisanego zapytania. Prawdziwe inżynierowanie wydajności wymaga spojrzenia poza projekt do rzeczywistego przepływu danych.
Podczas audytu systemu zacznij od ERD, aby upewnić się o poprawności. Następnie przejdź do planu wykonania, aby zapewnić wydajność. Na końcu ocen infrastrukturę, aby zapewnić pojemność. Tylko poprzez działanie na wszystkich poziomach możesz osiągnąć odpowiedniość, jakiej oczekują użytkownicy.