











Projektowanie solidnej schematu bazy danych wymaga precyzji. Diagram relacji encji (ERD) pełni rolę projektu tego struktury, przekładając złożoną logikę biznesową na format wizualny, który mogą zrozumieć programiści i stakeholderzy. Jednak pomimo ich użyteczności, ERD często stają się źródłem nieporozumień w fazie modelowania. Niejasność symboli, błędne rozumienie liczności oraz zamieszanie dotyczące typów atrybutów mogą prowadzić do znacznej pracy nad poprawką w późniejszych etapach cyklu rozwoju.
Ten przewodnik zawiera szczegółowe omówienie konkretnych składników w ERD, które najczęściej powodują trudności wśród architektów baz danych i inżynierów. Poprzez wyjaśnienie różnic między silnymi a słabymi encjami, rozkładanie oznaczeń relacji oraz analizę klasifikacji atrybutów, możemy zmniejszyć błędy i zapewnić, że ostateczny model danych dokładnie odzwierciedla wymagania operacyjne.
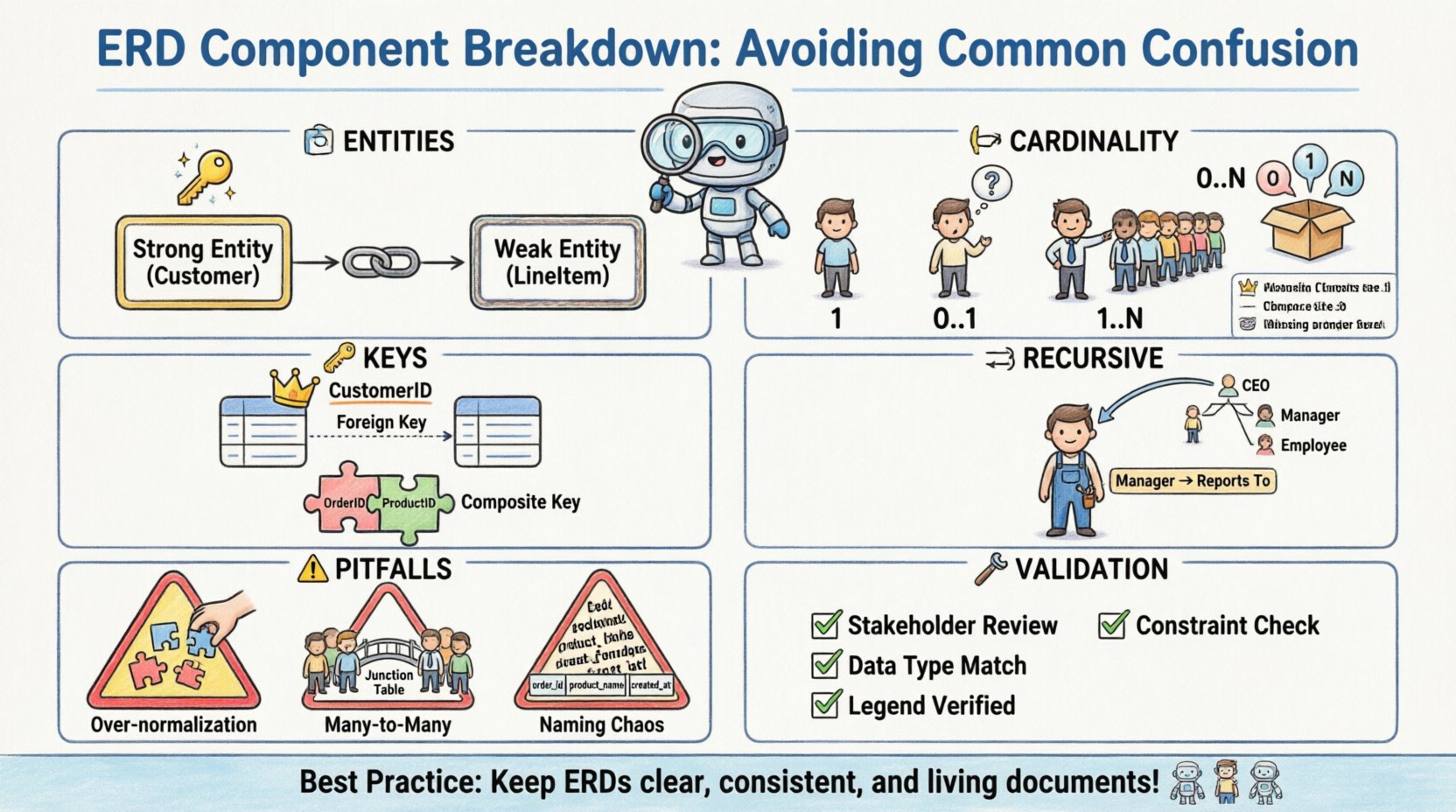
🏗️ Typy encji: rozróżnianie silnych od słabych
W centrum każdego ERD znajdują się encje. Odpowiadają one obiektom lub pojęciom, o których przechowywane są dane. Choć większość praktyków rozumie pojęcie tabeli, różnica między silnymi a słabymi encjami to miejsce, w którym najczęściej pojawia się pierwszy istotny punkt zamieszania.
- Silne encje: Te encje posiadają własny klucz główny. Są niezależne i nie opierają się na innych encjach w celu identyfikacji. Na przykład encja
Klientzazwyczaj ma unikalny identyfikator Klienta, co czyni ją encją silną. - Słabe encje: Te encje nie mogą być jednoznacznie identyfikowane wyłącznie na podstawie własnych atrybutów. Opierają się na relacji z inną encją, znaną jako rodzic identyfikujący, aby istnieć. Encja
PozycjaZamówieniaw systemie zamówień może istnieć wyłącznie w kontekście konkretnegoZamówienia.
Zamieszanie często wynika z tego, jak są wizualnie przedstawiane. Silna encja jest zazwyczaj rysowana jako standardowy prostokąt. Słaba encja jest często przedstawiana za pomocą podwójnego prostokąta. Niezdolność do wizualnego rozróżnienia tych elementów może prowadzić do błędów implementacji bazy danych, gdy tabela słabej encji jest tworzona bez odpowiednich ograniczeń kluczy obcych, które zapewniałyby jej zależność.
Skutki niepoprawnej klasyfikacji
Gdy słaba encja jest modelowana jako silna, baza danych może zezwolić na istnienie rekordów bez rodzica. Powoduje to powstanie danych sierot. Z kolei modelowanie silnej encji jako słabej narzuca niepotrzebną zależność, co może ograniczać jej użyteczność poza głównym kontekstem. Jest kluczowe ustalenie, czy obiekt może istnieć niezależnie, zanim nadamy mu status silnej encji.
- Sprawdzenie niezależności: Czy ten rekord może istnieć bez połączenia z innym rekordem?
- Źródło identyfikatora: Czy unikalny identyfikator pochodzi od samej encji czy od relacji?
- Zależność istnienia: Czy usunięcie rodzica automatycznie usuwa potomka?
🔗 Liczność i opcjonalność relacji
Relacje definiują sposób, w jaki encje ze sobą współdziałają. Liczność określa liczbę wystąpień jednej encji, które mogą lub muszą być powiązane z każdym wystąpieniem innej encji. To może być najbardziej powszechna źródłem zamieszania ze względu na różne style oznaczeń.
Oznaczenia liczności
Istnieje wiele sposobów oznaczania liczności na diagramie. Niektórzy używają etykiet tekstowych takich jak „1” lub „N”, inni zaś stosują notację „kłosu kruka”. Mieszanie tych stylów lub błędne rozumienie symboli prowadzi do luk w logice schematu fizycznego.
| Symbol / Etykieta | Znaczenie | Przykładowy scenariusz |
|---|---|---|
| 1 | Dokładnie jeden | Osoba ma dokładnie jeden numer ubezpieczenia społecznego. |
| 0..1 | Zero lub jeden | Osoba może mieć zero lub jedno imię pośrednie. |
| 1..1 | Jeden i tylko jeden | Projekt musi mieć przypisanego jednego menedżera projektu. |
| 0..N | Zero do wielu | Zamówienie może mieć zero lub wiele pozycji. |
| 1..N | Jeden do wielu | Dział musi mieć jednego lub wielu pracowników. |
Opcjonalność i możliwość wartości null
Opcjonalność odnosi się do tego, czy relacja jest wymagana czy opcjonalna. Ma to bezpośredni wpływ na definicję klucza obcego w tabeli bazy danych. Jeśli relacja jest wymagana, kolumna klucza obcego nie może mieć wartości null. Jeśli opcjonalna, może mieć wartość null.
Zbyt często pojawia się zamieszanie, gdy diagram pokazuje linię pełną w porównaniu do linii przerywanej. Bez jasnej legendy programiści mogą założyć wymagane relacje tam, gdzie nie istnieją, co prowadzi do naruszeń ograniczeń podczas wprowadzania danych. Jest istotne, aby znaczenie stylów linii jasno zaznaczyć w dokumentacji modelu.
- Relacja wymagana: Zapis potomny musi istnieć, aby zapis nadrzędny był ważny.
- Relacja opcjonalna: Zapis potomny może zostać utworzony bez nadrzędnego, albo zapis nadrzędny może istnieć bez potomka.
- Ograniczenie klucza obcego: Musi być ustawione na
NOT NULLdla wymaganej,NULLdozwolone dla opcjonalnej.
🔑 Atrybuty i identyfikacja kluczy
Atrybuty to właściwości jednostki. Choć wydają się proste, klasyfikacja atrybutów na klucze, klucze obce i proste atrybuty powoduje częste błędy podczas normalizacji i wydajności zapytań.
Klucz główny w porównaniu z kluczem obcym
Klucz główny (PK) jednoznacznie identyfikuje wiersz. Klucz obcy (FK) łączy wiersz z tabelą nadrzędną. Błędy pojawiają się, gdy zamiast kluczy zastępczych używane są klucze naturalne, lub gdy klucz główny nie jest spójnie zdefiniowany na diagramie.
- Klucz naturalny:Klucz istniejący naturalnie w danych, np. numer ubezpieczenia społecznego lub adres e-mail. Mogą się zmieniać, co prowadzi do problemów z integralnością danych.
- Klucz zastępczy:Sztuczny klucz generowany przez system, np. liczbę całkowitą zwiększającą się automatycznie. Zazwyczaj są one preferowane ze względu na stabilność.
Klucze złożone
Klucz złożony składa się z dwóch lub więcej kolumn, które razem jednoznacznie identyfikują rekord. Jest to powszechne w tabelach pośrednich używanych do rozwiązywania relacji wiele do wielu. Zmęczenie wynika z kolejności kolumn oraz z tego, która tabela przechowuje klucz.
Jeśli kolejność kolumn w kluczu złożonym nie jest spójnie zachowana w powiązanych tabelach, złączenia mogą się nie powieść lub wymagać skomplikowanego rzutowania. Jest kluczowe, aby dokładnie zarejestrować kolejność kolumn w definicji klucza głównego.
🔁 Relacje rekurencyjne
Relacja rekurencyjna występuje, gdy jednostka jest powiązana sama ze sobą. Jest często używana do struktur hierarchicznych, takich jak wykresy organizacyjne lub listy materiałów. Zmęczenie wynika z reprezentacji wizualnej, ponieważ linia łączy jednostkę z samą sobą.
Bez jasnego oznaczenia często nie jest jasne, która strona relacji reprezentuje rodzica, a która potomka. Na przykład w tabeli Employee jeden pracownik zarządza drugim. Relacja musi jasno stwierdzać, że pracownik może być menedżerem innych pracowników.
- Odwołanie do samego siebie:Klucz obcy w tabeli wskazuje z powrotem na klucz główny tej samej tabeli.
- Obsługa wartości null:Początek hierarchii zwykle ma wartość null w kolumnie ID menedżera.
- Ograniczenia głębokości:Zapytania rekurencyjne mogą stać się wąskimi gardłami wydajności, jeśli hierarchia jest bardzo głęboka.
⚠️ Powszechne pułapki modelowania
Poza konkretnymi elementami pewne wzorce strukturalne często prowadzą do zamieszania podczas implementacji. Wczesne rozpoznanie tych pułapek zapobiega kosztownym migracjom schematu.
1. Nadmierna normalizacja
Choć normalizacja zmniejsza nadmiarowość, nadmierna normalizacja może uczynić zapytania trudnymi do odczytania i wykonania. Tworzenie osobnej tabeli dla każdego atrybutu może niepotrzebnie fragmentować dane. Ważne jest, aby zrównoważyć trzecią postać normalną (3NF) z praktyczną wydajnością zapytań.
2. Relacja wiele do wielu bez tabel pośrednich
W fizycznej bazie danych relacja wiele do wielu nie może istnieć bezpośrednio. Musi zostać rozwiązana na dwie relacje jeden do wielu za pomocą tabeli pośredniej (jednostki asocjacyjnej). Pominięcie tego kroku prowadzi do modelu, który nie może być zaimplementowany w standardowym SQL.
- Model logiczny w porównaniu z fizycznym:Model logiczny może pokazywać bezpośrednią linię między dwiema jednostkami z licznością N:N.
- Realizacja fizyczna: Ta linia musi zostać podzielona przez nową tabelę zawierającą klucze obce z obu stron.
3. Niespójne konwencje nazewnictwa
Używanie różnych stylów nazewnictwa (np. customer_id vs CustomerID vs customerId) powoduje zamieszanie wśród programistów piszących zapytania. Na początku projektu powinien zostać ustalony standardowy styl nazewnictwa.
- Małe litery z podkreśleniami:
order_line_items - PascalCase:
OrderLineItems - CamelCase:
orderLineItems
🛠️ Strategie weryfikacji
Aby zapewnić, że ERD pozostaje dokładny i użyteczny, podczas procesu przeglądu należy podjąć konkretne kroki weryfikacyjne. Te kroki pomagają wykryć punkty zamieszania przed zamrożeniem schematu.
- Przejście z zaangażowanymi stronami: Przejrzyj diagram razem z użytkownikami biznesowymi, aby upewnić się, że relacje odpowiadają ich mentalnemu modelowi przepływu pracy.
- Weryfikacja ograniczeń: Sprawdź, czy każdy klucz obcy ma odpowiadający mu klucz główny.
- Spójność typów danych: Upewnij się, że atrybuty zdefiniowane jako liczby całkowite w jednej tabeli nie są zdefiniowane jako ciągi znaków w innej.
- Zgodność z legendą: Upewnij się, że wszystkie symbole użyte na diagramie odpowiadają podanej legendzie lub standardowi.
📝 Podsumowanie najlepszych praktyk
Utrzymanie przejrzystości na diagramie relacji encji wymaga dyscypliny. Przestrzeganie standardowych oznaczeń, jasne definiowanie liczności oraz rozróżnianie typów encji znacznie zmniejsza ryzyko nieporozumień. Celem nie jest jedynie narysowanie obrazka, ale stworzenie specyfikacji, która bezpośrednio przekłada się na stabilny i niezawodny system bazy danych.
Pamiętaj, że diagram to dokument żywy. W miarę zmian wymagań diagram ERD powinien być aktualizowany, aby odzwierciedlać te zmiany. Zapewnia to, że model danych będzie przez dłuższy czas poprawnie wspierać potrzeby biznesowe. Regularne przeglądy oraz przestrzeganie wytycznych strukturalnych przedstawionych w tym artykule pomogą zespołom uniknąć typowych pułapek, które zatrzymują projekty baz danych.