











सिस्टम विश्लेषण और डिजाइन जटिल तर्क को समझाने के लिए दृश्य प्रतिनिधित्व पर भारी निर्भरता रखता है। उपलब्ध विभिन्न उपकरणों में, डेटा फ्लो डायग्राम (DFD) जानकारी के आंदोलन को नक्शा बनाने के लिए एक मूल बिंदु बना हुआ है। इसके व्यापक उपयोग के बावजूद, DFD वास्तव में क्या प्रतिनिधित्व करता है और सिस्टम मॉडलिंग के विस्तृत संदर्भ में यह कैसे काम करता है, इसके बारे में महत्वपूर्ण भ्रम है। इस गाइड में डेटा फ्लो डायग्राम के चारों ओर फैली सबसे लंबी चल रही गलतफहमियों और भ्रमों को दूर किया गया है, जिससे विश्लेषकों, डेवलपर्स और हितधारकों को स्पष्टता मिलती है।
DFD की वास्तविक प्रकृति को समझना सटीक सिस्टम दस्तावेजीकरण बनाने के लिए आवश्यक है। सही तरीके से उपयोग किया जाए, तो वे प्रक्रियात्मक तर्क में फंसे बिना डेटा के आंदोलन को स्पष्ट करते हैं। हालांकि, जब इन्हें गलत समझा जाता है, तो यह डिजाइन की कमियों और संचार के विघटन की ओर जाता है। हम मुख्य घटकों, सामान्य त्रुटियों और सर्वोत्तम प्रथाओं का अध्ययन करेंगे ताकि आपके डायग्राम अपने उद्देश्य को प्रभावी ढंग से पूरा कर सकें। 🛠️
डेटा फ्लो डायग्राम क्या है? 🤔
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का दृश्य प्रतिनिधित्व है। अन्य आरेखों के विपरीत जो सिस्टम कैसे काम करता है (नियंत्रण प्रवाह) पर ध्यान केंद्रित करते हैं, DFD डेटा के क्या आंदोलन हो रहे हैं और वे कहाँ जा रहे हैं, इस पर ध्यान केंद्रित करता है। यह एक सिस्टम को ऐसे प्रक्रियाओं में विभाजित करता है जो इनपुट डेटा को आउटपुट डेटा में बदलते हैं।
मुख्य उद्देश्य सिस्टम के इनपुट और आउटपुट को दृश्य रूप से दिखाना है, जिसमें डेटा के विभिन्न चरणों से गुजरने के दौरान उसके परिवर्तन को दिखाया जाता है। इस अमूल्य अवधारणा के कारण टीमें सिस्टम के मूल बातों पर ध्यान केंद्रित कर सकती हैं, न कि विशिष्ट कार्यान्वयन विवरणों पर।
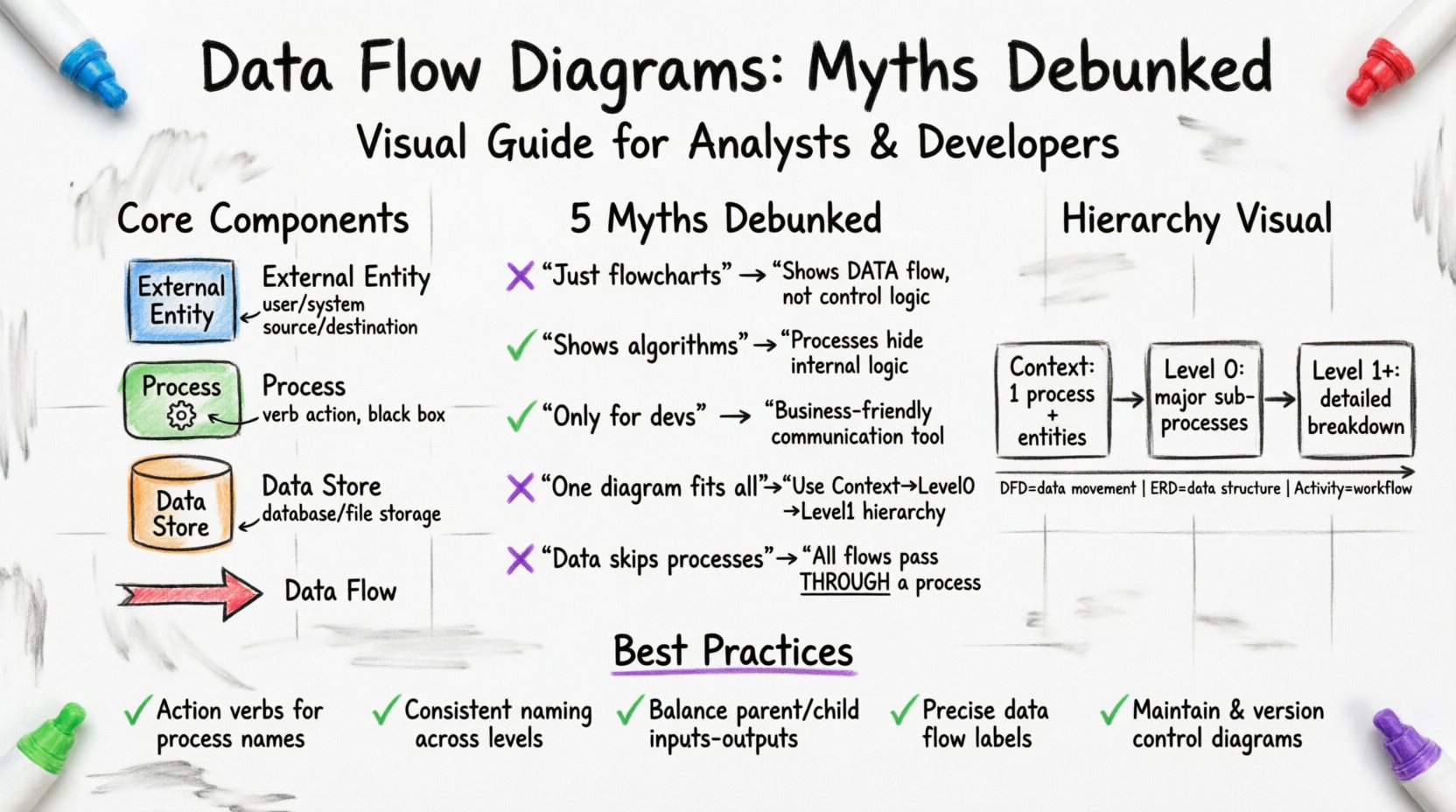
DFD के मुख्य घटक
एक वैध आरेख बनाने के लिए, चार मूल तत्वों को समझना आवश्यक है:
- बाहरी एकाधिकार: ये सिस्टम सीमा के बाहर डेटा के स्रोत या गंतव्य का प्रतिनिधित्व करते हैं। इनमें मानव उपयोगकर्ता, अन्य प्रणालियाँ या हार्डवेयर उपकरण शामिल हो सकते हैं। इन्हें आमतौर पर वर्ग या वृत्त के रूप में दिखाया जाता है। 🖥️
- प्रक्रियाएँ: ये डेटा पर किए जाने वाले क्रियाकलाप या रूपांतरण हैं। एक प्रक्रिया इनपुट डेटा लेती है, इसे बदलती है और आउटपुट डेटा उत्पन्न करती है। इन्हें आमतौर पर गोल किनारे वाले आयत या वृत्त के रूप में दिखाया जाता है। ⚙️
- डेटा स्टोर: ये वे स्थान हैं जहाँ डेटा बाद में उपयोग के लिए रखा जाता है, जैसे फाइलें, डेटाबेस या भौतिक आर्काइव। इन्हें निष्पादित नहीं किया जाता है; ये सक्रिय स्टोरेज नहीं हैं। 🗄️
- डेटा प्रवाह: ये डेटा के एकाधिकार, प्रक्रियाओं और स्टोर के बीच ले जाने वाले मार्ग हैं। इन्हें गति की दिशा दिखाने वाले तीरों द्वारा दर्शाया जाता है। 🏹
प्रत्येक घटक एक विशिष्ट कार्य करता है। इन तत्वों को गलत तरीके से मिलाने से अवैध आरेख बनते हैं जो सिस्टम के वास्तविक व्यवहार को संचारित नहीं कर पाते हैं।
डेटा फ्लो डायग्राम के बारे में आम भ्रम 🚫
उद्योग में DFD के बारे में बहुत सारी भ्रम फैली हुई है। बहुत से पेशेवर ऐसी मान्यताएँ लेकर चलते हैं जो प्रभावी मॉडलिंग को रोकती हैं। नीचे, हम पांच सबसे आम भ्रमों को खंडित करते हैं।
भ्रम 1: DFD सिर्फ जटिल फ्लोचार्ट हैं 📉
यह शायद सबसे व्यापक त्रुटि है। जबकि दोनों आरेख तीर और आकृतियों का उपयोग करते हैं, उनका उद्देश्य बहुत अलग है।
- फ्लोचार्ट नियंत्रण प्रवाह का वर्णन करते हैं। वे क्रियाओं के क्रम, निर्णय बिंदु (हाँ/नहीं शाखाएँ), और लूप दिखाते हैं। वे प्रश्न का उत्तर देते हैं: “अगला क्या होगा?”
- डेटा फ्लो डायग्राम डेटा के आंदोलन का वर्णन करते हैं। वे लूप या निर्णय तर्क नहीं दिखाते हैं। वे प्रश्न का उत्तर देते हैं: “डेटा कहाँ जाता है?”
यदि आप एक निर्णय के लिए एक हीरे के आकार को बनाते हैं, तो आप एक फ्लोचार्ट बना रहे हैं, DFD नहीं। DFD में, एक निर्णय सिर्फ डेटा को फ़िल्टर करने वाली एक प्रक्रिया है। लिया गया मार्ग नहीं दिखाया जाता है; केवल परिणामी डेटा प्रवाह दिखाया जाता है। इन अवधारणाओं को मिलाने से अस्पष्टता उत्पन्न होती है कि क्या आरेख तर्क का प्रतिनिधित्व करता है या डेटा का।
भ्रम 2: DFD तर्क और एल्गोरिदम दिखाते हैं 🧠
विश्लेषक अक्सर एक DFD प्रक्रिया बबल में बहुत अधिक विवरण डालने की कोशिश करते हैं। वे प्रक्रिया वृत्त के अंदर पसोडो-कोड लिख सकते हैं या जटिल एल्गोरिदम का वर्णन कर सकते हैं। इससे अमूल्यता के सिद्धांत का उल्लंघन होता है।
DFD में एक प्रक्रिया एक “काला बॉक्स” है। यह इनपुट को आउटपुट में बदलती है, लेकिन आंतरिक यांत्रिकी छिपी रहती है। यदि आप तर्क को समझाना चाहते हैं, तो संरचित अंग्रेजी विवरण या अलग एल्गोरिदमिक फ्लोचार्ट का उपयोग करें। DFD का काम प्रक्रियाओं के बीच संबंध दिखाना है, न कि आंतरिक कोड का।
- गलत: प्रक्रिया बॉक्स के अंदर “यदि शेष राशि > 0, तो शुल्क काटें” लिखना।
- सही: प्रक्रिया को “शुल्क की गणना” नाम देना और डेटा प्रवाह “खाता शेष” को प्रवेश करते और “शुल्क गणना” को बाहर निकलते दिखाना।
प्रचार 3: DFDs केवल विकासकर्मियों के लिए होते हैं 👨💻
कुछ लोग मानते हैं कि DFDs तकनीकी वस्तुएँ हैं जो केवल कोडिंग टीमों के लिए होती हैं। इससे उनकी उपयोगिता सीमित हो जाती है। DFDs व्यापार स्टेकहोल्डर्स, प्रोजेक्ट मैनेजर्स और ग्राहकों के लिए उत्तम संचार उपकरण हैं।
क्योंकि DFDs कोड के बजाय डेटा पर ध्यान केंद्रित करते हैं, इसलिए वे भाषा-निरपेक्ष होते हैं। एक व्यापार मालिक DFD को देखकर ग्राहक की जानकारी के बिलिंग प्रणाली में कैसे आगे बढ़ती है, बिना डेटाबेस स्कीमा या API एंडपॉइंट्स के बारे में जाने के समझ सकता है। इससे आवश्यकता संग्रह और मान्यता के लिए इनकी बहुत आवश्यकता होती है।
प्रचार 4: एक आरेख सभी परिदृश्यों के लिए फिट होता है 📐
लोग अक्सर पूरी प्रणाली को एक ही पृष्ठ पर बनाने की कोशिश करते हैं। इससे भारी बनावट और पढ़ने में कठिनाई होती है। DFDs पदानुक्रमिक होते हैं। इन्हें विस्तार के स्तरों में बाँटा जाना चाहिए।
- संदर्भ आरेख: सर्वोच्च स्तर। प्रणाली को एक प्रक्रिया के रूप में दिखाता है और बाहरी एकाधिकारों के साथ इसके बातचीत को दिखाता है।
- स्तर 0 आरेख: मुख्य प्रक्रिया को प्रमुख उप-प्रक्रियाओं में विभाजित करता है।
- स्तर 1 आरेख: विशिष्ट उप-प्रक्रियाओं को आगे विभाजित करता है।
इस सभी विवरण को एक दृश्य में बाँधने से संरचना छिप जाती है। प्रत्येक स्तर को अपने आप में खड़ा रहना चाहिए, जबकि अन्य स्तरों के साथ संगत रहना चाहिए।
प्रचार 5: डेटा प्रवाह प्रक्रियाओं को बिना रुके पार कर सकता है 🔄
DFD मॉडलिंग में एक कठोर नियम है कि डेटा एक बाहरी एकाधिकार से दूसरे बाहरी एकाधिकार या एक डेटा स्टोर से दूसरे डेटा स्टोर तक सीधे प्रवाहित नहीं हो सकता है। सभी डेटा को एक प्रक्रिया से गुजरना चाहिए।
यदि डेटा एंटिटी A से डेटा स्टोर B में जाता है, तो इसे एक प्रक्रिया से गुजरना चाहिए। इससे यह सुनिश्चित होता है कि डेटा पर कार्रवाई की जा रही है या वैधता की जा रही है। सीधे कनेक्शन की अनुमति देने से यह बताता है कि प्रणाली को डेटा पर कोई नियंत्रण नहीं है, जो सॉफ्टवेयर इंजीनियरिंग में दुर्लभ होता है।
DFD स्तरों और पदानुक्रम को समझना 📚
जटिलता को प्रबंधित करने के लिए बहु-स्तरीय DFD संरचना बनाना आवश्यक है। यहाँ इस पदानुक्रम के आम तरीके को दिखाया गया है।
स्तर 0: संदर्भ आरेख
यह सारांश है। यह प्रणाली की सीमा को परिभाषित करता है। एकल प्रक्रिया वृत्त के अंदर सब कुछ प्रणाली है। बाहर सब कुछ बाहरी है। यह आरेख स्टेकहोल्डर्स को प्रोजेक्ट के दायरे को तुरंत समझने में मदद करता है।
स्तर 1: विघटन
यहाँ, स्तर 0 की एकल प्रक्रिया को प्रमुख कार्यात्मक क्षेत्रों में विस्तारित किया जाता है। उदाहरण के लिए, “आदेश प्रोसेसिंग प्रणाली” को “आदेश प्राप्त करें”, “भुगतान प्रक्रिया करें” और “माल भेजें” में बदला जा सकता है। इस स्तर पर आंतरिक संरचना का उच्च स्तर का दृश्य प्रदान किया जाता है।
स्तर 2 और आगे: विस्तृत विभाजन
इन स्तरों में स्तर 1 से विशिष्ट प्रक्रियाओं में गहराई से जाया जाता है। आप विभाजन तब रोकते हैं जब एक प्रक्रिया इतनी सरल हो जाती है कि आगे के विवरण के बिना समझी जा सकती है, या जब वह इतनी छोटी हो जाती है कि उपयोगी नहीं होती है (उदाहरण के लिए, एक लाइन कोड)।
| स्तर | केंद्र | जटिलता | प्राथमिक दर्शक |
|---|---|---|---|
| संदर्भ (स्तर 0) | प्रणाली सीमा | कम | हितधारक |
| स्तर 0 | मुख्य उप-प्रणालियाँ | मध्यम | प्रोजेक्ट प्रबंधक |
| स्तर 1+ | विशिष्ट प्रक्रियाएँ | उच्च | विकासकर्ता |
DFD बनाम अन्य मॉडलिंग आरेख 🔄
DFD और अन्य मॉडलिंग तकनीकों के बीच अक्सर भ्रम पैदा होता है। यह जानना महत्वपूर्ण है कि किस उपकरण का उपयोग कब करना है।
डेटा प्रवाह आरेख बनाम एंटिटी संबंध आरेख (ERD)
- DFD: गतिशील व्यवहार पर ध्यान केंद्रित करता है। डेटा समय के साथ कैसे आगे बढ़ता है। यह प्रक्रियाओं और प्रवाहों को दिखाता है।
- ERD: स्थिर संरचना पर ध्यान केंद्रित करता है। डेटा कैसे संग्रहीत और संबंधित है। यह तालिकाओं, कुंजियों और संबंधों को दिखाता है।
आपको अक्सर दोनों की आवश्यकता होती है। DFD आपको बताता है कि किस डेटा की आवश्यकता है, और ERD आपको बताता है कि इसे कैसे संग्रहीत करना है। एक ERD को डेटा गतिशीलता दिखाने के लिए बल न डालें, या DFD को डेटाबेस स्कीमा दिखाने के लिए बल न डालें।
डेटा प्रवाह आरेख बनाम UML गतिविधि आरेख
- DFD: डेटा-केंद्रित। नियंत्रण प्रवाह नहीं, कोई लूप नहीं।
- गतिविधि आरेख: व्यवहार-केंद्रित। तर्क, निर्णय और समानांतर प्रसंस्करण दिखाता है।
जब आपको कार्यप्रवाह या अवस्था परिवर्तन का वर्णन करने की आवश्यकता हो, तो गतिविधि आरेखों का उपयोग करें। जब आपको डेटा आवश्यकताओं का वर्णन करने की आवश्यकता हो, तो DFD का उपयोग करें।
सटीक DFD बनाने के लिए बेस्ट प्रैक्टिसेज ✅
अपने आरेखों को प्रभावी और सटीक बनाने के लिए, इन संरचनात्मक दिशानिर्देशों का पालन करें।
- क्रिया विशेषज्ञ शब्दों का उपयोग करें: प्रक्रिया के नाम हमेशा क्रिया शब्द से शुरू होने चाहिए (उदाहरण के लिए, “कर की गणना” के बजाय “कर गणना”)। इससे परिवर्तन के पहलू पर जोर दिया जाता है।
- नामकरण में सामंजस्य बनाए रखें: यदि डेटा प्रवाह स्तर 0 पर “इन्वॉइस” कहलाता है, तो स्तर 1 पर भी इसे “इन्वॉइस” कहना चाहिए। नाम बदलने से डेटा की पहचान को लेकर भ्रम पैदा होता है।
- अपने आरेखों को संतुलित करें: मातृ प्रक्रिया के इनपुट और आउटपुट को उसकी बच्ची प्रक्रियाओं के इनपुट और आउटपुट के साथ मेल बैठाना चाहिए। यदि “आदेश डेटा” स्तर 0 की प्रक्रिया में प्रवेश करता है, तो “आदेश डेटा” (या उसके घटक) को उस मातृ प्रक्रिया के बनाने वाली स्तर 1 की प्रक्रियाओं में प्रवेश करना चाहिए।
- भूत के प्रवाह से बचें: सुनिश्चित करें कि प्रत्येक तीर का एक उद्देश्य हो। यदि डेटा प्रवाह किसी प्रक्रिया में प्रवेश करता है लेकिन उपयोग नहीं किया जाता है, तो यह एक भूत प्रवाह है और इसे हटा देना चाहिए। विपरीत रूप से, यदि कोई प्रक्रिया डेटा उत्पन्न करती है लेकिन किसी का उपयोग नहीं करती है, तो डेटा अनाथ हो जाता है।
- डेटा स्टोर कनेक्शनों की सीमा निर्धारित करें: आवश्यकता न होने पर किसी प्रक्रिया को बहुत सारे डेटा स्टोर से सीधे जोड़ें। प्रवाह को तार्किक रखें।
बचने के लिए आम गलतियाँ ⚠️
यहां तक कि अनुभवी विश्लेषक भी गलतियां करते हैं। यहां वे बाधाएं हैं जो आरेख की गुणवत्ता को कमजोर करती हैं।
नियंत्रण और डेटा का मिश्रण करना
निर्णय हीरे या लूप को शामिल न करें। यदि किसी प्रक्रिया में शर्ती मार्ग है, तो सिर्फ परिणामस्वरूप डेटा प्रवाह को दिखाएं। तर्क स्वयं प्रक्रिया विवरण में होना चाहिए, आरेख में नहीं।
डेटा स्टोर को नजरअंदाज करना
कुछ आरेख दृश्य को सरल बनाने के लिए डेटा स्टोर को छोड़ देते हैं। यह गलत है। डेटा स्टोर स्थायित्व का प्रतिनिधित्व करते हैं। उनके बिना, आरेख यह संकेत देता है कि डेटा क्षणभंगुर है और प्रसंस्करण के बाद खो जाता है। व्यावसायिक प्रणालियों में ऐसा बहुत दुर्लभ होता है।
अत्यधिक सजावट करना
रंग, आइकन या सजावटी तत्व जोड़ें तभी जब वे किसी विशिष्ट अर्थपूर्ण उद्देश्य के लिए हों (जैसे प्राथमिकता के लिए रंग कोडिंग)। दृश्य भाषा को मानक बनाए रखें ताकि स्पष्टता बनी रहे।
अस्पष्ट एंटिटी सीमाएं
सुनिश्चित करें कि आप जानते हैं कि क्या सिस्टम के अंदर है और क्या बाहर। यदि उपयोगकर्ता इंटरफेस सिस्टम का हिस्सा है, तो उपयोगकर्ता एंटिटी है। यदि उपयोगकर्ता इंटरफेस बाहरी है (जैसे वेब ब्राउज़र), तो सिस्टम सीमा अलग हो सकती है। यहां सामंजस्य बनाए रखने से स्कोप क्रीप को रोका जा सकता है।
डेटा प्रवाह नामकरण का महत्व 🏷️
डेटा प्रवाह के नामकरण का महत्व बहुत से लोगों को नहीं समझ में आता है। “डेटा” जैसा लेबल बेकार है। “ग्राहक जानकारी” जैसा लेबल बेहतर है। “ग्राहक नाम, पता और फ़ोन नंबर” जैसा लेबल सटीक है।
स्पष्ट नामकरण संचालन चरण के दौरान अस्पष्टता को रोकता है। जब डेवलपर्स को “इन्वॉइस” दिखता है, तो उन्हें ठीक वह संरचना उम्मीद होती है जो उन्हें चाहिए। यदि लेबल धुंधला है, तो वे ऐसी मान्यताएं बना सकते हैं जो एकीकरण त्रुटियों की ओर जाती हैं।
समय के साथ DFD को बनाए रखना 🔄
DFD स्थिर दस्तावेज़ नहीं हैं। प्रणालियां विकसित होती हैं और आवश्यकताएं बदलती हैं। आज सही वाला DFD छह महीने में अप्रचलित हो सकता है।
- संस्करण नियंत्रण:DFD को कोड की तरह लें। संशोधनों का रिकॉर्ड रखें।
- समीक्षा चक्र:स्टेकहोल्डर्स के साथ नियमित समीक्षा योजना बनाएं ताकि आरेख वर्तमान व्यावसायिक नियमों को दर्शाए।
- अपडेट ट्रिगर्स: जब भी कोई महत्वपूर्ण फीचर जोड़ा जाता है, डेटाबेस स्कीमा बदलता है, या तीसरे पक्ष के एकीकरण में परिवर्तन होता है, तो आरेख में बदलाव करें।
DFD के रखरखाव के अभाव में दस्तावेज़ीकरण और वास्तविकता के बीच असंगति उत्पन्न होती है। विकासकर्ता दस्तावेज़ीकरण को नज़रअंदाज़ करेंगे, और नए सदस्य गलत धारणा में रहेंगे। आरेख को प्रणाली के एक जीवंत कलाकृति के रूप में लीजिए।
कार्यान्वयन के लिए तकनीकी मामले 🛠️
डिज़ाइन से कार्यान्वयन में जाते समय, DFD एक नक्शा के रूप में कार्य करता है। यहाँ दिखाया गया है कि यह तकनीकी कार्य में कैसे बदलता है।
डेटाबेस स्कीमा के साथ मैपिंग
DFD में प्रत्येक डेटा स्टोर को डेटाबेस में एक तालिका या संग्रह के साथ मैप किया जाना चाहिए। डेटा प्रवाह कॉलम और संबंधों को इंगित करते हैं। यदि DFD में “शिपिंग पता” को “ग्राहक प्रोफ़ाइल” में प्रवाहित होते दिखाया गया है, तो डेटाबेस में इसके लिए एक फ़ील्ड होनी चाहिए। यदि ऐसा नहीं है, तो डिज़ाइन दोषपूर्ण है।
API एंडपॉइंट्स के साथ मैपिंग
DFD में प्रक्रियाएँ अक्सर API एंडपॉइंट्स या माइक्रोसर्विसेज़ में बदल जाती हैं। “उपयोगकर्ता की पुष्टि करें” नाम की प्रक्रिया `/auth/validate` एंडपॉइंट में बदल सकती है। डेटा प्रवाह अनुरोध और प्रतिक्रिया पेलोड को परिभाषित करते हैं।
सर्वोत्तम प्रथाओं पर निष्कर्ष 🎯
कठोर मॉडलिंग नियमों का पालन करने से यह सुनिश्चित होता है कि DFD प्रोजेक्ट चक्र के दौरान एक उपयोगी उपकरण बनी रहे। सामान्य गलत धारणाओं से बचकर नियंत्रण तर्क के बजाय डेटा गति पर ध्यान केंद्रित करने से टीमें स्पष्ट और कार्यान्वयन योग्य आरेख बना सकती हैं। याद रखें कि लक्ष्य संचार है, केवल दस्तावेज़ीकरण नहीं। यदि आरेख टीम को प्रणाली को समझने में सहायता नहीं करता है, तो इसका उद्देश्य विफल हो गया है।
नियमित समीक्षा, संगत नामकरण और उचित पदानुक्रम यह सफलता के रहस्य हैं। आरेख के साथ कोड के समान गंभीरता से व्यवहार करें। इस अनुशासन का लाभ कम त्रुटियों, स्पष्ट आवश्यकताओं और चिकने विकास चक्रों में मिलता है।
प्रणाली दृश्यीकरण पर अंतिम विचार 🌐
प्रणालियों को दृश्याकरण करना विज्ञान के समान कला भी है। डेटा प्रवाह आरेख डेटा गति को देखने के लिए एक विशिष्ट लेंस प्रदान करते हैं। वे अन्य उपकरणों को बदलते नहीं हैं, लेकिन उनके साथ पूरक होते हैं। उनकी सीमाओं और ताकत को समझकर विश्लेषक DFD का उपयोग लचीली, अच्छी तरह दस्तावेज़ीकृत प्रणालियाँ बनाने के लिए कर सकते हैं।
डेटा पर ध्यान केंद्रित रखें। प्रक्रियाओं को सामान्य रखें। स्तरों को संतुलित रखें। इन सिद्धांतों को ध्यान में रखते हुए, आपके मॉडलिंग प्रयास सटीक और मूल्यवान परिणाम देंगे।