
डेटा फ्लो डायग्राम (DFD) एक महत्वपूर्ण दृश्य भाषा के रूप में काम करते हैं जो जानकारी के एक प्रणाली में गति को समझने में मदद करते हैं। वे प्रक्रियाओं, डेटा स्टोर, बाहरी एकाधिकार और उन्हें जोड़ने वाले फ्लो के संरचित दृश्य प्रदान करते हैं। हालांकि, एक सटीक डायग्राम बनाना केवल बॉक्स और तीर बनाने से अधिक है। इसके लिए तर्क, सुसंगतता और डेटा अखंडता के प्रति अनुशासित दृष्टिकोण की आवश्यकता होती है। जब इन तत्वों को नजरअंदाज किया जाता है, तो परिणामी मॉडल भ्रमित, गलतफहमी उत्पन्न करने वाला या विकास के उद्देश्यों के लिए पूरी तरह से अमान्य हो जाता है। इस मार्गदर्शिका में मॉडलिंग प्रक्रिया के दौरान सामना की जाने वाली सबसे आम गलतियों का विश्लेषण किया गया है और उन्हें रोकने के लिए स्पष्ट, क्रियान्वयन योग्य रणनीतियाँ प्रदान की गई हैं।
🧩 मूल घटकों को समझें
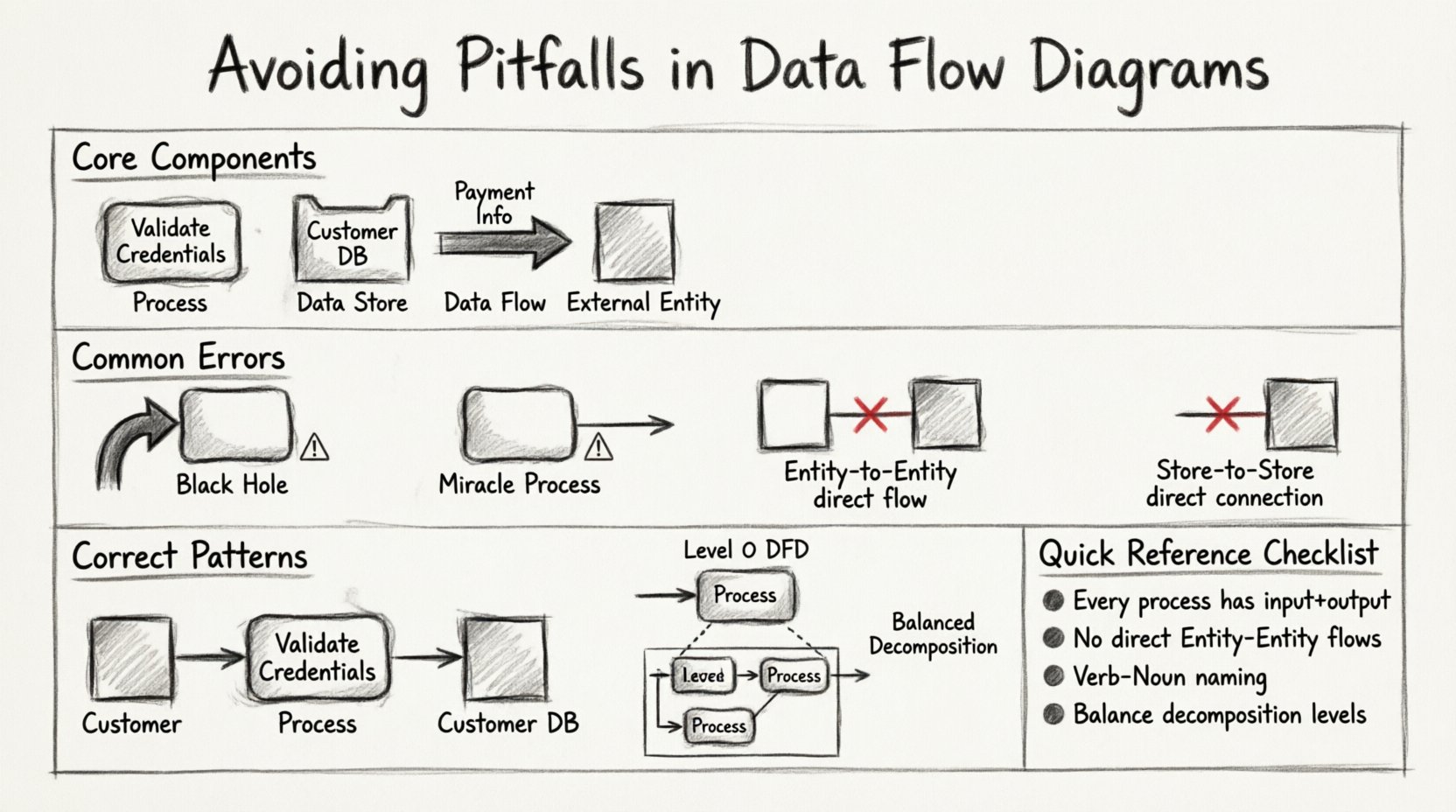
गलतियों में डूबने से पहले, हर डेटा फ्लो डायग्राम के चार मूल घटकों को समझने के लिए एक मजबूत समझ बनाना आवश्यक है। एक क्षेत्र में गलती अक्सर पूरे मॉडल में फैल जाती है। इन घटकों को एक दूसरे के साथ बदला नहीं जा सकता है, और उन्हें गलती से भ्रमित करना संरचनात्मक विफलता का प्रमुख कारण है।
- प्रक्रियाएँ: ये डेटा के परिवर्तन करने वाली क्रियाओं का प्रतिनिधित्व करते हैं। ये स्थिर भंडारण नहीं हैं; वे सक्रिय परिवर्तन हैं। मानक नोटेशन में, इन्हें गोल आयत या वृत्त के रूप में दिखाया जाता है।
- डेटा स्टोर: ये ऐसे भंडार हैं जहाँ जानकारी प्रक्रियाओं के बीच रुकती है। इनका अर्थ है लंबे समय तक रहना। आमतौर पर इन्हें खुले छोर वाले आयत या समानांतर रेखाओं के रूप में दिखाया जाता है।
- डेटा फ्लो: ये डेटा की गति को दिखाने वाले तीर हैं। ये इनपुट और आउटपुट का प्रतिनिधित्व करते हैं, लेकिन कभी भी स्टोरेज का प्रतिनिधित्व नहीं करते।
- बाहरी एकाधिकार: ये प्रणाली की सीमा के बाहर डेटा के स्रोत या गंतव्य हैं। वे प्रणाली से बातचीत करते हैं, लेकिन उसके नियंत्रण में नहीं हैं।
जब डेटा फ्लो को प्रक्रिया के रूप में लिया जाता है, या जब डेटा स्टोर को एक जुड़ी प्रक्रिया के बिना तीर के सिरे के साथ बनाया जाता है, तो अक्सर भ्रम पैदा होता है। यहाँ सटीकता निर्माण के बाद की मॉडलिंग गलतियों के अधिकांश को रोकती है।
⚠️ “काला छेद” और “चमत्कार” प्रक्रियाएँ
DFD मॉडलिंग में सबसे गंभीर तर्कपूर्ण गलतियों में से दो डेटा के संरक्षण से संबंधित हैं। प्रत्येक प्रक्रिया को पदार्थ के संरक्षण के नियम का सम्मान करना चाहिए, जिसे यहाँ जानकारी के लिए अनुकूलित किया गया है: डेटा बिना किसी निशान के सरलता से दिखाई दे या गायब नहीं हो सकता।
1. काला छेद प्रक्रिया
एक काला छेद तब होता है जब किसी प्रक्रिया के इनपुट होते हैं लेकिन आउटपुट नहीं होते हैं। डेटा प्रक्रिया में प्रवेश करता है, लेकिन कुछ भी बाहर नहीं जाता है। एक कार्यात्मक प्रणाली में यह असंभव है। यदि डेटा का उपयोग किया जाता है, तो उसे किसी अन्य चीज में परिवर्तित किया जाना चाहिए, स्टोर किया जाना चाहिए, या आगे भेजा जाना चाहिए।
- लक्षण: एक तीर किसी प्रक्रिया में जाता है, लेकिन कोई तीर बाहर नहीं निकलता है।
- कारण: मॉडलर मानता है कि डेटा को “संभाला गया” है बिना परिणाम के निर्दिष्ट किए। यह अक्सर तब होता है जब लीगेसी प्रणालियों का वर्णन करते समय आउटपुट को नजरअंदाज किया जाता है या खो दिया जाता है।
- परिणाम: प्रणाली बनाने वाले डेवलपर्स को इनपुट डेटा के साथ क्या करना है, इसका पता नहीं चलेगा। यह तर्क प्रवाह को रोक देता है।
- समाधान: सुनिश्चित करें कि प्रत्येक इनपुट का एक संबंधित आउटपुट हो। यदि डेटा स्टोर किया जाता है, तो डेटा स्टोर तक एक फ्लो बनाएँ। यदि इसकी रिपोर्ट की जाती है, तो बाहरी एकाधिकार तक एक फ्लो बनाएँ।
2. चमत्कार प्रक्रिया
विपरीत रूप से, एक चमत्कार प्रक्रिया वह है जिसके आउटपुट होते हैं लेकिन इनपुट नहीं होते हैं। प्रणाली जादू की तरह हवा में से जानकारी उत्पन्न करती है। हालांकि प्रणाली के डिफ़ॉल्ट मान हो सकते हैं, लेकिन डेटा के निर्माण के लिए आमतौर पर एक ट्रिगर या प्रारंभिक स्थिति की आवश्यकता होती है।
- लक्षण: एक तीर किसी प्रक्रिया से बाहर निकलता है, लेकिन कोई तीर इसमें प्रवेश नहीं करता है।
- कारण: मॉडलर यह भूल जाता है कि प्रारंभिक डेटा कहाँ से आता है। वे मान लेते हैं कि प्रक्रिया डेटा को स्वतंत्र रूप से उत्पन्न करती है।
- परिणाम: प्रणाली की तर्कशक्ति टूटी हुई है। इनपुट के बिना, प्रक्रिया कार्य नहीं कर सकती है। इससे एक ऐसी निर्भरता का अनुमान लगता है जो वास्तव में नहीं है।
- सुधार: आउटपुट को उसके स्रोत तक ट्रेस करें। क्या कोई बाहरी एजेंसी इसे प्रदान कर रही है? क्या यह डेटा स्टोर से आ रहा है? क्या यह पिछली प्रक्रिया का परिणाम है?
🔗 एजेंसियों के बीच डेटा प्रवाह
DFD नियमों के सबसे सामान्य उल्लंघन में से एक दो बाहरी एजेंसियों के बीच सीधा कनेक्शन है। सख्त विधि के अनुसार, डेटा एक बाहरी एजेंसी से दूसरी बाहरी एजेंसी में सीधे प्रवाहित नहीं हो सकता है। इसे प्रणाली की सीमा से गुजरना चाहिए।
| गलत पैटर्न | सही पैटर्न | तर्कसंगतता |
|---|---|---|
| एजेंसी A ────> एजेंसी B | एजेंसी A ───> प्रक्रिया ───> एजेंसी B | प्रणाली को लेनदेन में शामिल होना चाहिए। |
| ग्राहक ───> विक्रेता | ग्राहक ───> आदेश प्रक्रिया ───> विक्रेता | आदेश प्रणाली संबंध को मध्यस्थता करती है। |
यह नियम सुनिश्चित करता है कि प्रणाली की सीमा का सम्मान किया जाता है। यदि दो एजेंसियाँ सीधे बातचीत करती हैं, तो उनके द्वारा उपयोग की जा रही प्रक्रिया वर्तमान आरेख के बाहर है। इस प्रवाह को शामिल करना इस बात का संकेत देता है कि प्रणाली को बाहर रखा गया है, जो प्रणाली के मॉडलिंग के उद्देश्य के विरोध में है।
🏷️ नामकरण प्रथाएँ और अस्पष्टता
एक आरेख बेकार हो जाता है यदि पाठक को यह समझने में कठिनाई होती है कि प्रतीक क्या दर्शाते हैं। सामान्य नामकरण एक सूक्ष्म लेकिन व्यापक त्रुटि है। “प्रक्रिया 1” या “डेटा A” जैसे लेबल को कोई मूल्य नहीं होता है। हालांकि, अत्यधिक जटिल नाम आरेख को भारी बना सकते हैं। लक्ष्य स्पष्टता और विशिष्टता है।
प्रक्रिया नामकरण
प्रक्रियाओं के नाम एक क्रिया और एक संज्ञा के साथ रखे जाने चाहिए। इससे क्रिया का वर्णन होता है जो किया जा रहा है।
- बुरा: “प्रक्रिया 1”, “लॉगिन”, “डेटा का प्रबंधन”
- अच्छा: “उपयोगकर्ता प्रमाणपत्र की पुष्टि करें”, “कर की गणना करें”, “बिल जनरेट करें”
क्रियाओं का उपयोग करने से यह सुनिश्चित होता है कि पाठक को जो परिवर्तन हो रहा है, उसे समझ आए। यदि नाम केवल एक संज्ञा है, तो इसका अर्थ डेटा स्टोर होता है, प्रक्रिया नहीं।
डेटा प्रवाह नामकरण
डेटा प्रवाह जानकारी के आवागमन का प्रतिनिधित्व करते हैं। उन्हें स्थानांतरित किए जा रहे विशिष्ट डेटा पैकेट के साथ लेबल किया जाना चाहिए।
- बुरा: “डेटा”, “जानकारी”, “विवरण”
- अच्छा: “भुगतान जानकारी”, “ग्राहक आईडी”, “शिपिंग पता”
सामंजस्य महत्वपूर्ण है। यदि आप एक जगह इसे “ग्राहक आईडी” कहते हैं, तो दूसरी जगह इसे “ग्राहक संख्या” नहीं कहना चाहिए। इससे समीक्षा प्रक्रिया के दौरान भ्रम पैदा होता है।
⚖️ संतुलन और विघटन
DFD पदानुक्रमिक होते हैं। आप संदर्भ आरेख (स्तर 0) से शुरू करते हैं और फिर एकल प्रक्रिया को स्तर 1 DFD में विघटित करते हैं। यहीं सबसे अधिक तकनीकी त्रुटियाँ होती हैं। संतुलन के सिद्धांत के अनुसार, मातृ प्रक्रिया के इनपुट और आउटपुट को उप-आरेख में बच्चे प्रक्रियाओं के संग्रहित इनपुट और आउटपुट के साथ मेल बैठना चाहिए।
संतुलन नियम
यदि संदर्भ आरेख में “आदेश” के प्रवाह को प्रणाली में प्रवेश करते हुए दिखाया गया है, तो स्तर 1 DFD में उसी “आदेश” प्रवाह को एक बच्चे प्रक्रिया में प्रवेश करते हुए दिखाना होगा। विघटन के दौरान डेटा खोने की अनुमति नहीं है।
- आम त्रुटि: स्तर 1 आरेख में एक नया इनपुट जोड़ा गया है जो स्तर 0 आरेख में उपस्थित नहीं था।
- आम त्रुटि: स्तर 1 आरेख में एक आउटपुट को हटा दिया गया है जो स्तर 0 आरेख में मौजूद था।
संतुलन क्यों महत्वपूर्ण है
जब कोई आरेख संतुलित नहीं होता है, तो प्रणाली के दायरे में बिना दस्तावेजीकरण के बदलाव हो जाता है। इससे नई कार्यक्षमता या खोई गई कार्यक्षमता का अनुमान लगाया जाता है। विकास के दौरान, इससे गायब फीचर्स या अप्रत्याशित बग्स होते हैं। संतुलन बनाए रखने के लिए:
- मातृ प्रक्रिया के सभी इनपुट और आउटपुट की सूची बनाएं।
- बच्चे प्रक्रियाओं को बनाएं।
- सत्यापित करें कि प्रत्येक मातृ इनपुट बच्चे के इनपुट के रूप में दिखाई दे।
- सत्यापित करें कि प्रत्येक मातृ आउटपुट बच्चे के आउटपुट के रूप में दिखाई दे।
- यदि डेटा बच्चे में दिखाई देता है लेकिन मातृ में नहीं, तो मातृ संदर्भ का विस्तार करें या डेटा को बच्चे से हटा दें।
🗄️ डेटा स्टोर कनेक्शन
डेटा स्टोर प्रणाली की मेमोरी हैं। वे सक्रिय नहीं होते हैं। वे डेटा को नहीं ले जाते हैं; प्रक्रियाएं डेटा को उनके बीच ले जाती हैं। एक आम गलती दो डेटा स्टोर को डेटा प्रवाह के साथ सीधे जोड़ना है।
गलत: डेटा स्टोर A ───> डेटा स्टोर B
सही: डेटा स्टोर A ───> प्रक्रिया ───> डेटा स्टोर B
बिना किसी प्रक्रिया के डेटा के भंडारों के बीच स्थानांतरण के कोई तंत्र नहीं है। यदि आप सीधी रेखा खींचते हैं, तो आप एक स्वचालित स्थानांतरण का अनुमान लगा रहे हैं जिसके लिए एक विशिष्ट प्रक्रिया को गतिशीलता को क्रियान्वित करने की आवश्यकता होती है। हमेशा डेटा स्टोर कनेक्शन को प्रक्रिया के माध्यम से रूट करें।
🔄 बाहरी एकाधिकार
एक ही बाहरी एकाधिकार को एक ही आरेख पर कई बार बनाना आम है ताकि स्थान बचाया जा सके या लाइन क्रॉसिंग कम की जा सके। यह एक दृश्य सुविधा है जो तार्किक त्रुटियों को लाती है।
- नियम: एक बाहरी एकाधिकार को एक दिए गए आरेख पर केवल एक बार दिखाया जाना चाहिए।
- कारण: यदि “ग्राहक” दो बार दिखाई देता है, तो ऐसा लगता है कि दो अलग-अलग लोग या भूमिकाएं हैं। इससे दो अलग-अलग डेटा स्रोतों का अनुमान होता है।
- सुधार: यदि रेखाएं बहुत लंबी हैं, तो कनेक्टर प्रतीक का उपयोग करें या लेआउट को फिर से बनाएं। बॉक्स की प्रतिलिपि न बनाएं।
🛡️ मॉडल सटीकता के लिए समीक्षा चेकलिस्ट
अपने आरेखों की दृढ़ता सुनिश्चित करने के लिए, किसी भी मॉडल के अंतिम रूप देने से पहले इस चेकलिस्ट का उपयोग करें। यह त्रुटियों को पकड़ने में मदद करता है जो आरेख बनाते समय आसानी से नजर गैर हो सकती हैं।
- इनपुट/आउटपुट जांच: क्या प्रत्येक प्रक्रिया में कम से कम एक इनपुट और एक आउटपुट है?
- प्रवाह दिशा: क्या सभी तीर सही दिशा में इशारा करते हैं? डेटा प्रवाह को स्रोत से गंतव्य की ओर जाना चाहिए।
- एंटिटी अलगाव: क्या दो बाहरी एंटिटी के बीच कोई सीधा प्रवाह है?
- स्टोर अलगाव: क्या दो डेटा स्टोर के बीच कोई सीधा प्रवाह है?
- नामकरण संगतता: क्या सभी लेबल दस्तावेज में स्पष्ट, विशिष्ट और संगत हैं?
- संतुलन: क्या लेवल 1 आरेख लेवल 0 संदर्भ आरेख के इनपुट/आउटपुट के साथ मेल खाता है?
- सीमा: क्या सभी बाहरी एंटिटी सिस्टम सीमा के बाहर हैं?
📊 त्रुटियों और समाधानों की तुलना
निम्नलिखित तालिका महत्वपूर्ण त्रुटियों और उन्हें दूर करने के लिए आवश्यक विशिष्ट सुधारात्मक कार्रवाई का सारांश प्रस्तुत करती है।
| त्रुटि श्रेणी | दृश्य संकेतक | सुधारात्मक कार्रवाई |
|---|---|---|
| काला छेद | इनपुट तीर मौजूद है, आउटपुट तीर नहीं है | स्टोर या एंटिटी में आउटपुट प्रवाह जोड़ें |
| चमत्कार | आउटपुट तीर मौजूद है, इनपुट तीर नहीं है | स्रोत का पता लगाएं और इनपुट प्रवाह जोड़ें |
| एंटिटी-टू-एंटिटी | दो बॉक्स (एंटिटीज) के बीच तीर | उनके बीच एक प्रक्रिया डालें |
| स्टोर-टू-स्टोर | दो खुले आयतों के बीच तीर | एक प्रक्रिया के माध्यम से रास्ता बनाएं |
| एंटिटी की दोहराई गई प्रति | एक ही एंटिटी का नाम दो बार दिखाई देता है | एकल उदाहरण में मिलाएं |
| असंतुलित स्तर | स्तरों के बीच असंगत इनपुट/आउटपुट | प्रवाह को मातृ स्तर के अनुरूप समायोजित करें |
💡 खराब मॉडलिंग का प्रभाव
इस विस्तार का क्यों महत्व है? जब एक DFD में इन त्रुटियों का असर होता है, तो मॉडल और सॉफ्टवेयर की वास्तविकता के बीच का अंतर बढ़ जाता है। डेवलपर्स इन आरेखों पर निर्भर करते हैं कोड लिखने के लिए। यदि आरेख कहता है कि डेटा A से B जाता है, लेकिन कोड में उम्मीद है कि यह C जाएगा, तो सिस्टम विफल हो जाता है।
इसके अलावा, रखरखाव एक नरक बन जाता है। जब किसी सिस्टम को अपडेट करने की आवश्यकता होती है, तो डेवलपमेंट टीम आरेख को देखती है ताकि प्रभाव को समझ सके। यदि आरेख ब्लैक होल या चमत्कारों से भरा है, तो टीम नहीं जान सकती कि क्या टूटेगा। इससे ‘स्पैगेटी कोड’ और तकनीकी देनदारी का निर्माण होता है।
सटीक मॉडलिंग सॉफ्टवेयर के जीवनचक्र में एक निवेश है। यह प्रोजेक्ट के बाद के चरणों में बदलाव की लागत को कम करता है। एक साफ, तार्किक DFD व्यापार आवश्यकताओं और तकनीकी कार्यान्वयन के बीच एक संविदा के रूप में कार्य करता है।
🛠️ उपकरण बनाम पद्धति
आरेख बनाने के लिए उपयोग किए जाने वाले उपकरण और इसे बनाने के लिए उपयोग की जाने वाली पद्धति के बीच अंतर करना महत्वपूर्ण है। बहुत से मॉडलिंग उपकरण ऑटोमेशन के लिए विशेषताएं प्रदान करते हैं, जैसे असंतुलित प्रवाह को उजागर करना। हालांकि, कोई भी उपकरण व्यापार के तर्क के संबंध में मानव निर्णय को प्रतिस्थापित नहीं कर सकता।
- स्वचालन: उपकरण वाक्य रचना त्रुटियों की जांच कर सकते हैं, जैसे गायब लेबल या टूटे हुए कनेक्शन।
- तर्क: मानवों को यह सत्यापित करना होगा कि प्रवाह व्यापार संदर्भ में समझ में आता है या नहीं।
अपने मॉडल के सत्यापन के लिए सिर्फ सॉफ्टवेयर पर भरोसा न करें। एक आरेख वाक्य रचना के अनुसार पूर्ण हो सकता है, लेकिन तार्किक रूप से गलत हो सकता है। उदाहरण के लिए, एक उपकरण एक एंटिटी से दूसरी एंटिटी में डेटा प्रवाह की अनुमति दे सकता है, लेकिन पद्धति के अनुसार यह गलत है। हमेशा उपकरण की अनुमतियों के बावजूद DFD सिद्धांत के नियमों का अनुपालन करें।
🔍 वॉकथ्रू के माध्यम से सत्यापन
जब आरेख बन जाता है, तो उसका सत्यापन करना आवश्यक है। इसका सबसे अच्छा तरीका स्टेकहोल्डर्स के साथ वॉकथ्रू करना है। इसमें आरेख के चरण दर चरण अनुसरण करना शामिल होता है।
- संदर्भ से शुरू करें: क्लाइंट के साथ सीमा की पुष्टि करें। क्या यह सब कुछ कवर करता है जो उन्होंने उम्मीद की थी?
- प्रवाह का पालन करें: प्रवेश से निकास तक एक विशिष्ट डेटा के बारे में ट्रेस करें। क्या यह समझ में आता है?
- पूछें “क्यों”: यह डेटा यहाँ क्यों आवश्यक है? यह यहाँ क्यों संग्रहीत किया जाता है?
- मान्यताओं की जाँच करें: क्या डेटा के प्रसंस्करण के बारे में कोई ऐसी मान्यताएँ हैं जो दस्तावेज़ीकृत नहीं हैं?
इस सहयोगात्मक समीक्षा में अक्सर सबसे महत्वपूर्ण त्रुटियाँ पाई जाती हैं। स्टेकहोल्डरों को एहसास हो सकता है कि वे एक प्रक्रिया को स्वचालित समझते थे, जबकि वास्तव में यह हाथ से की जा रही है, या इसके विपरीत। इससे DFD में महत्वपूर्ण बदलाव आता है।
📝 सटीकता पर अंतिम विचार
एक डेटा प्रवाह आरेख बनाना तर्क और संचार का अभ्यास है। यह सिर्फ एक ड्राइंग कार्य नहीं है; यह यह बताने का एक तरीका है कि सिस्टम कैसे काम करता है। इस गाइड में बताए गए सामान्य त्रुटियों से बचकर आप यह सुनिश्चित करते हैं कि आपके आरेख विकास और रखरखाव के लिए भरोसेमंद संदर्भ हों।
चार घटकों पर ध्यान केंद्रित करें। प्रवाह और भंडारण के नियमों का सम्मान करें। नामकरण में सामंजस्य बनाए रखें। अपने स्तरों को संतुलित रखें। दूसरों के साथ जाँच करें। जब इन अभ्यासों का पालन किया जाता है, तो DFD स्पष्टता के लिए एक शक्तिशाली उपकरण बन जाता है, बजाय भ्रम के स्रोत के।
याद रखें कि लक्ष्य समझ है। यदि कोई आरेख भ्रमित करता है, तो वह विफल हो गया है, चाहे उसमें कितने बॉक्स हों। स्पष्टता को जटिलता से अधिक प्राथमिकता दें। एक सरल, सटीक आरेख कभी भी एक जटिल, दोषपूर्ण आरेख से बेहतर होता है।
🚀 मुख्य बातों का सारांश
- कभी डेटा न खोएं: काले छेद (आउटपुट के बिना इनपुट) और चमत्कार (इनपुट के बिना आउटपुट) से बचें।
- सीमाओं का सम्मान करें: बाहरी एजेंसियों या डेटा स्टोर्स के बीच कोई सीधा प्रवाह नहीं होना चाहिए।
- संतुलन बनाए रखें: विघटन के सभी स्तरों पर इनपुट और आउटपुट का मेल होना चाहिए।
- स्पष्ट नामों का उपयोग करें: प्रक्रियाओं के लिए क्रिया-संज्ञा, डेटा प्रवाह के लिए विशिष्ट संज्ञाएँ।
- कठोरता से समीक्षा करें: तार्किक त्रुटियों को पकड़ने के लिए चेकलिस्ट और वॉकथ्रू का उपयोग करें।
इन दिशानिर्देशों का पालन करने से एक दृढ़ मॉडल बनेगा जो परियोजना के निर्माण से लेकर डेप्लॉयमेंट तक प्रभावी ढंग से सेवा करेगा। अब सटीकता पर लगाए गए प्रयास से कोडिंग और परीक्षण चरणों में महत्वपूर्ण समय और संसाधन बचेंगे। प्रत्येक आरेख को एक महत्वपूर्ण दस्तावेज़ के रूप में मानें जो सिस्टम के व्यवहार को परिभाषित करता है।