











बादल के लिए सॉफ्टवेयर बनाने के लिए सोचने के तरीके में बदलाव की आवश्यकता होती है। पारंपरिक मोनोलिथिक आर्किटेक्चर में तंतु जुड़े घटकों पर निर्भरता थी जो मेमोरी और स्थानीय फाइल सिस्टम के साझा करते थे। हालांकि, बादल-स्वामी एप्लिकेशन वितरित वातावरणों में काम करते हैं, जो अक्सर कई नेटवर्कों और सुरक्षा सीमाओं को पार करते हैं। इस जटिलता को समझने के लिए, इंजीनियरों को सिस्टम के माध्यम से जानकारी के आने-जाने के तरीके के स्पष्ट दृश्य प्रतिनिधित्व की आवश्यकता होती है। यहां डेटा फ्लो डायग्राम (DFD) एक आवश्यक उपकरण बन जाता है। प्रक्रियाओं, स्टोर्स और बाहरी एजेंसियों के बीच डेटा के प्रवाह को मैप करके, टीमें अनुमान पर निर्भर न होकर टिकाऊ, स्केलेबल और सुरक्षित सिस्टम डिज़ाइन कर सकती हैं।
यह गाइड बादल-स्वामी संदर्भों के लिए DFD सिद्धांतों को लागू करने के तरीकों का अध्ययन करती है। हम मुख्य घटकों, वितरित प्रणालियों के लिए आवश्यक अनुकूलनों और बुनियादी ढांचे के विकास के साथ बदलते रहने वाले डायग्राम बनाने के व्यावहारिक चरणों का अध्ययन करेंगे। चाहे आप माइक्रोसर्विस इकोसिस्टम या सर्वरलेस फंक्शन चेन डिज़ाइन कर रहे हों, डेटा के आने-जाने को समझना विश्वसनीय इंजीनियरिंग की नींव है।
🌩️ बादल-स्वामी मॉडलिंग की ओर बदलाव को समझना
एक पारंपरिक ऑन-प्रेमाइस वातावरण में, एक प्रणाली अक्सर एक ही भौतिक सीमा के भीतर मौजूद होती है। डेटा प्रक्रियाओं के बीच स्थानीय रूप से प्रवाहित होता है। एक बादल-स्वामी सेटिंग में, सीमाएं तरल होती हैं। एकल तार्किक एप्लिकेशन में लाखों स्वतंत्र सेवाएं हो सकती हैं जो कंटेनर में चल रही हों, अलग-अलग क्षेत्रों या उपलब्धता क्षेत्रों में ऑर्केस्ट्रेट की जा रही हों। नेटवर्क लेटेंसी, अंततः संगति और सुरक्षा नीतियां ऐसे चर लाती हैं जो मोनोलिथिक डिज़ाइन में नहीं होते।
इस वातावरण के लिए डेटा फ्लो डायग्राम बनाते समय, आपको निम्नलिखित को ध्यान में रखना होगा:
- नेटवर्क सीमाएं:डेटा अक्सर सार्वजनिक नेटवर्कों या सुरक्षित VPCs को पार करता है। प्रत्येक हॉप एक संभावित विफलता या लेटेंसी का बिंदु है।
- राज्य प्रबंधन:बादल सेवाएं अक्सर राज्यहीन होती हैं। प्रक्रियाओं को राज्य को मेमोरी में नहीं रखकर बाहरी स्टोर से राज्य प्राप्त करना होता है।
- असमान समय संचार:समकालिक कॉल (अनुरोध-प्रतिक्रिया) हमेशा सबसे अच्छा फिट नहीं होते हैं। मैसेज क्यू और इवेंट स्ट्रीम घटकों के बीच डेटा के प्रवाह को बदल देते हैं।
- सुरक्षा क्षेत्र:परिधि में प्रवेश करने वाले डेटा को आंतरिक प्रक्रियाओं तक पहुंचने से पहले प्रमाणीकृत और एन्क्रिप्ट किया जाना चाहिए।
इन प्रतिबंधों को जल्दी से दृश्याकृत करने से आर्किटेक्चरल ऋण से बचा जा सकता है। नेटवर्क सेगमेंटेशन या राज्यहीन आवश्यकताओं को नजरअंदाज करने वाला डायग्राम एक ऐसी प्रणाली के रूप में बनेगा जिसे डिबग और स्केल करना मुश्किल होगा। लक्ष्य केवल यह दिखाना नहीं है कि डेटा कहां जाता है, बल्कि यह उजागर करना है कि यह कहां परिवर्तित, संग्रहीत और सुरक्षित किया जाता है।
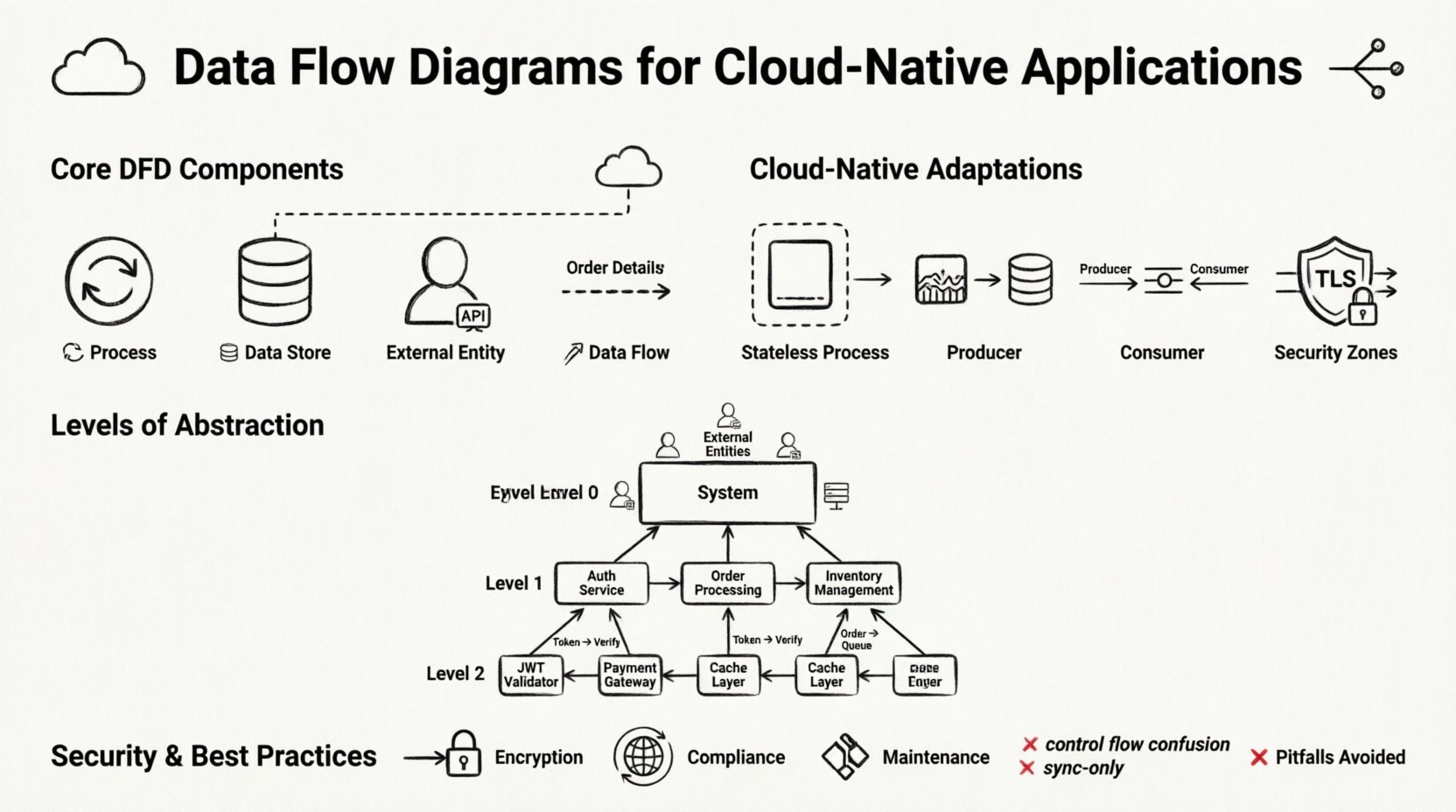
🧩 डेटा फ्लो डायग्राम के मुख्य घटक
बादल के लिए इन डायग्रामों के अनुकूलन से पहले, हमें मानक निर्माण ब्लॉक्स को स्थापित करना होगा। DFD एक फ्लोचार्ट नहीं है; यह नियंत्रण तर्क या समय को नहीं दिखाता है। यह डेटा के आने-जाने को दिखाता है। चार मुख्य तत्व वितरित प्रणालियों में भी स्थिर रहते हैं।
1. प्रक्रियाएं 🔄
एक प्रक्रिया एक गतिविधि का प्रतिनिधित्व करती है जो इनपुट डेटा को आउटपुट डेटा में बदलती है। बादल-स्वामी संदर्भ में, एक प्रक्रिया अक्सर एक फंक्शन, कंटेनरीकृत एप्लिकेशन या माइक्रोसर्विस इंस्टेंस होती है। प्रक्रियाओं के नाम उनके तकनीकी नाम के बजाय उनके कार्य के आधार पर रखना महत्वपूर्ण है। उदाहरण के लिए, “UserService API” के बजाय “Validate User Credentials” का उपयोग करें। इससे डायग्राम डेटा परिवर्तन तर्क पर केंद्रित रहता है।
- परिवर्तन:प्रत्येक प्रक्रिया को डेटा को किसी तरह बदलना चाहिए। यदि डेटा बिना परिवर्तन के गुजरता है, तो इसे प्रक्रिया के रूप में नहीं दर्शाया जाना चाहिए।
- एन्कैप्सुलेशन:माइक्रोसर्विस में, प्रत्येक प्रक्रिया एन्कैप्सुलेटेड होती है। आंतरिक तर्क छिपा होता है; डायग्राम के लिए केवल इनपुट और आउटपुट इंटरफेस महत्वपूर्ण होते हैं।
- राज्यहीनता:अधिकांश बादल प्रक्रियाएं अस्थायी होती हैं। वे पिछले बातचीत की याद नहीं रखती हैं। इसे डेटा प्रवाह आवश्यकताओं में प्रतिबिंबित किया जाना चाहिए।
2. डेटा स्टोर्स 🗄️
एक डेटा स्टोर एक स्थान का प्रतिनिधित्व करता है जहां डेटा प्रक्रिया के बिना विश्राम करता है। बादल में, यह एक संबंधात्मक डेटाबेस, एक नो-एसक्यूएल दस्तावेज़ स्टोर, एक ऑब्जेक्ट स्टोरेज बैकेट या एक वितरित कैश हो सकता है। फाइल सिस्टम के विपरीत, बादल डेटा स्टोर्स को अक्सर नेटवर्क के माध्यम से प्राप्त किया जाता है।
- स्थायित्व:यदि डेटा को प्रक्रिया विफलता या रीस्टार्ट के बाद भी बचाए रखना है, तो इसे स्टोर में सहेजा जाना चाहिए।
- पहुंच पैटर्न: पढ़ने पर आधारित स्टोर लेखन पर आधारित स्टोर से अलग होते हैं। यदि एक्सेस का प्रकार आर्किटेक्चर को महत्वपूर्ण रूप से प्रभावित करता है, तो डायग्राम में उसका प्रकार दर्शाना चाहिए।
- सुरक्षा:संवेदनशील डेटा स्टोर के लिए अलग एक्सेस नियंत्रण की आवश्यकता होती है। यह अंतर सुरक्षा ऑडिट के लिए महत्वपूर्ण है।
3. बाहरी एजेंसियाँ 👥
बाहरी एजेंसियाँ सिस्टम सीमा के बाहर डेटा के स्रोत या गंतव्य होती हैं। इनमें मानव उपयोगकर्ता, तृतीय पक्ष के API, पुराने सिस्टम या हार्डवेयर उपकरण शामिल हो सकते हैं। क्लाउड-नेटिव डायग्राम में, बाहरी एजेंसियाँ आमतौर पर इंटरनेट या अन्य क्लाउड सेवाओं के किनारे का प्रतिनिधित्व करती हैं।
- भरोसेमंद बनाम अनभरोसेमंद:एक ज्ञात आंतरिक सेवा से आने वाले डेटा और सार्वजनिक इंटरनेट ट्रैफिक के बीच अंतर करें।
- प्रारंभ करना:एजेंसियाँ आमतौर पर प्रवाह की शुरुआत करती हैं। एक उपयोगकर्ता अनुरोध एक प्रक्रिया को प्रारंभ करता है; एक योजित कार्य डेटा सिंक को प्रारंभ करता है।
4. डेटा प्रवाह 📡
डेटा प्रवाह घटकों को जोड़ने वाले तीर होते हैं। इनका अर्थ डेटा के स्थानांतरण का होता है। क्लाउड वातावरण में, इन प्रवाहों को आमतौर पर नेटवर्क के माध्यम से गुजरना होता है। तीरों पर लेबल आवश्यक हैं। इन्हें प्रोटोकॉल के बजाय डेटा पैकेट का वर्णन करना चाहिए। उदाहरण के लिए, तीर को “ऑर्डर विवरण” के रूप में लेबल करें, “HTTP POST” के बजाय। इससे डायग्राम प्रोटोकॉल-स्वतंत्र रहता है और भविष्य के लिए उपयुक्त बना रहता है।
- दिशात्मकता:प्रवाह एकदिशीय होते हैं। यदि डेटा आगे-पीछे जाता है, तो दो अलग-अलग तीर खींचें।
- आयतन:उच्च आयतन वाले डेटा प्रवाहों के लिए निम्न आयतन वाले नियंत्रण प्रवाहों की तुलना में अलग इंफ्रास्ट्रक्चर (उदाहरण के लिए, निर्दिष्ट बैंडविड्थ) की आवश्यकता हो सकती है।
- एन्क्रिप्शन:सुरक्षा सीमाओं को पार करने वाले प्रवाहों को एन्क्रिप्टेड के रूप में चिह्नित किया जाना चाहिए ताकि संगतता की आवश्यकताओं को उजागर किया जा सके।
☁️ वितरित प्रणालियों के लिए DFD का अनुकूलन
मानक DFD के अनुसार एक संगठित प्रणाली मानी जाती है। क्लाउड-नेटिव प्रणालियाँ वितरित होती हैं। इस संदर्भ में DFD को उपयोगी बनाने के लिए, आपको इंफ्रास्ट्रक्चर की वितरित प्रकृति को स्पष्ट रूप से मॉडल करना होगा। इसमें नेटवर्क टोपोलॉजी और सेवा सीमाओं का प्रतिनिधित्व करने वाले अब्स्ट्रैक्शन के स्तर जोड़ने शामिल हैं।
सेवा सीमाएँ
माइक्रोसर्विसेज क्लाउड-नेटिव एप्लिकेशन के मानक निर्माण ब्लॉक हैं। प्रत्येक सेवा को आपके डायग्राम में एक अलग प्रक्रिया के रूप में होना चाहिए। हालांकि, प्रत्येक सेवा को बनाने से भारी बन सकता है। एक सामान्य दृष्टिकोण यह है कि संबंधित सेवाओं को एक तार्किक क्षेत्र में समूहित करना, जैसे कि “बिलिंग क्षेत्र” या “उपयोगकर्ता प्रबंधन क्षेत्र”। इससे आप उच्च स्तर के प्रवाह को देख सकते हैं जबकि आंतरिक जटिलता को छिपाए रख सकते हैं।
API गेटवे
अधिकांश क्लाउड-नेटिव एप्लिकेशन एक API गेटवे या लोड बैलेंसर के पीछे स्थित होते हैं। यह घटक एकमात्र प्रवेश बिंदु के रूप में कार्य करता है। DFD में, गेटवे एक प्रक्रिया है जो अनुरोधों को रूट करती है। यह प्रमाणीकरण, दर सीमा और प्रोटोकॉल अनुवाद का प्रबंधन करता है। गेटवे को एक साधारण पाइप के रूप में न लें; यह डेटा के प्रवाह को सक्रिय रूप से परिवर्तित करता है।
घटना-आधारित आर्किटेक्चर
बहुत से आधुनिक प्रणालियाँ घटना-आधारित पैटर्न का उपयोग करती हैं। एक उत्पादक घटना उत्पन्न करता है, और एक उपभोक्ता बाद में इसका प्रसंस्करण करता है। इससे प्रक्रिया और डेटा प्रवाह के तात्कालिक संबंध का ब्रेक होता है। DFD में, आप इसे एक घटना कतार या स्ट्रीम के रूप में डेटा स्टोर के रूप में दर्शाते हैं। उत्पादक घटना लिखता है; उपभोक्ता इसे पढ़ता है। यह अलगाव लचीलापन के लिए महत्वपूर्ण है।
| घटक | पारंपरिक मोनोलिथ | क्लाउड-नेटिव अनुकूलन |
|---|---|---|
| प्रक्रिया | मेमोरी में कार्य | कंटेनरीकृत माइक्रोसर्विस / सर्वरलेस फंक्शन |
| डेटा स्टोर | स्थानीय फ़ाइल / SQL डीबी | प्रबंधित क्लाउड डेटाबेस / ऑब्जेक्ट स्टोरेज |
| फ्लो | स्थानीय मेमोरी कॉल | HTTP / gRPC / मैसेज क्यू |
| स्टेट | साझा मेमोरी | बाहरीकृत स्टेट स्टोर |
📉 क्लाउड आर्किटेक्चर में स्तरों का अब्स्ट्रैक्शन
जटिल प्रणालियों के लिए आरेखों के कई स्तरों की आवश्यकता होती है। एक ही दृश्य में हर विवरण को कैप्चर करने की कोशिश करने से भ्रम उत्पन्न होता है। सही तरीके से लागू करने पर मानक DFD दृष्टिकोण स्तर 0, 1 और 2 क्लाउड प्रणालियों के लिए अच्छा काम करता है।
स्तर 0: संदर्भ आरेख
संदर्भ आरेख पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है। यह प्रणाली के साथ बातचीत करने वाले बाहरी तत्वों पर जोर देता है। क्लाउड एप्लिकेशन के लिए, यह सीमा को परिभाषित करता है। यह प्रश्न का उत्तर देता है: “प्रणाली में क्या प्रवेश करता है, और क्या इससे बाहर निकलता है?” यह सबसे ऊंचे स्तर का दृश्य है, जो तकनीकी विवरणों के बिना सीमा को समझने के लिए रुचि रखने वाले स्टेकहोल्डर्स के लिए उपयोगी है।
- फोकस: प्रणाली की सीमाएं और बाहरी इंटरफेस।
- विवरण: न्यूनतम। एक केंद्रीय प्रक्रिया।
- उपयोग के मामले: प्रोजेक्ट स्कोप परिभाषा और उच्च स्तर की सुरक्षा योजना।
स्तर 1: मुख्य प्रक्रियाएं
स्तर 1 केंद्रीय प्रक्रिया को मुख्य उप-प्रक्रियाओं में बांटता है। क्लाउड-नेटिव संदर्भ में, ये आमतौर पर मुख्य कार्यात्मक क्षेत्र होते हैं। उदाहरण के लिए, एक ई-कॉमर्स प्लेटफॉर्म के लिए स्तर 1 आरेख में “ऑर्डर प्रोसेसिंग”, “इन्वेंट्री मैनेजमेंट” और “भुगतान हैंडलिंग” को अलग-अलग प्रक्रियाओं के रूप में दिखाया जा सकता है। इस स्तर पर यह पता चलता है कि डेटा प्रमुख सेवा समूहों के बीच कैसे आता-जाता है।
- फोकस: प्रमुख कार्यात्मक मॉड्यूल और उनके बीच के बातचीत।
- विवरण: प्रत्येक प्रमुख मॉड्यूल के लिए इनपुट और आउटपुट।
- उपयोग के मामले: आर्किटेक्चरल समीक्षा और सेवा विघटन।
स्तर 2: विस्तृत तर्क
स्तर 2 विशिष्ट उप-प्रक्रियाओं में गहराई से जाता है। यहीं तकनीकी कार्यान्वयन विवरण महत्वपूर्ण होते हैं। उदाहरण के लिए, “भुगतान हैंडलिंग” प्रक्रिया को “कार्ड की पुष्टि करें”, “खाते को चार्ज करें” और “रसीद को अपडेट करें” दिखाने के लिए विस्तारित किया जा सकता है। इस स्तर का उपयोग विशिष्ट सेवाओं को कार्यान्वित करने वाले डेवलपर्स द्वारा किया जाता है।
- फोकस:विशिष्ट सेवाओं की आ inter्नल तर्कवाद।
- विवरण:विशिष्ट डेटा परिवर्तन और स्थानीय डेटा स्टोर।
- उपयोग के मामले:विकास कार्यान्वयन और परीक्षण परिदृश्य।
🔒 डेटा मैपिंग में सुरक्षा और अनुपालन
क्लाउड-नेटिव विकास में सुरक्षा को बाद में सोचने की बात नहीं है; यह एक डिजाइन आवश्यकता है। डेटा फ्लो डायग्राम सुरक्षा जोखिमों को पहचानने के लिए एक उत्कृष्ट उपकरण है। डेटा के मार्ग का पता लगाकर आप यह देख सकते हैं कि संवेदनशील जानकारी कहाँ खुली हो सकती है या गलत तरीके से स्टोर की जा रही है।
संवेदनशील डेटा की पहचान करना
सभी डेटा फ्लो एक जैसे नहीं होते हैं। व्यक्तिगत पहचान जानकारी (PII), वित्तीय रिकॉर्ड और स्वास्थ्य डेटा को सख्ती से संभालने की आवश्यकता होती है। अपने डायग्राम में संवेदनशील डेटा वाले फ्लो को चिह्नित करें। इससे यह सुनिश्चित होता है कि इस डेटा को छूने वाले प्रत्येक प्रक्रिया की अनुपालन के लिए समीक्षा की जाए।
- प्रसारण में एन्क्रिप्शन:नेटवर्क सीमाओं को पार करने वाले फ्लो को एन्क्रिप्ट किया जाना चाहिए (TLS/SSL)। इन फ्लो को स्पष्ट रूप से चिह्नित करें।
- आराम में एन्क्रिप्शन:संवेदनशील जानकारी रखने वाले डेटा स्टोर को एन्क्रिप्ट किया जाना चाहिए। इसे डेटा स्टोर लेबल में चिह्नित करें।
- पहुँच नियंत्रण: यह पहचानें कि कौन सी प्रक्रियाएँ विशिष्ट डेटा स्टोर को पढ़ने या लिखने की अनुमति रखती हैं। इससे भूमिका-आधारित पहुँच नियंत्रण (RBAC) सेट करने में मदद मिलती है।
अनुपालन सीमाएँ
अलग-अलग क्षेत्रों में अलग-अलग डेटा संप्रभुता कानून होते हैं। डेटा को एक विशिष्ट भौगोलिक सीमा के भीतर रहने की आवश्यकता हो सकती है। एक DFD इन प्रतिबंधों को दृश्यमान करने में मदद करता है। यदि क्षेत्र A में एक प्रक्रिया क्षेत्र B में डेटा भेजती है, तो इस फ्लो को कानूनी समीक्षा के लिए चिह्नित किया जाना चाहिए। इससे GDPR या CCPA जैसे नियमों के अनजाने उल्लंघन से बचा जा सकता है।
⚠️ सामान्य त्रुटियाँ और उनसे बचने के तरीके
क्लाउड सिस्टम के लिए DFD बनाना चुनौतीपूर्ण है। टीमें अक्सर पुराने पैटर्न को नए वातावरण में मैप करने की कोशिश करके सामान्य गलतियाँ करती हैं। इन त्रुटियों से बचने से यह सुनिश्चित होता है कि आपके डायग्राम सटीक और उपयोगी बने रहें।
1. नियंत्रण और डेटा फ्लो का मिश्रण
DFD में नियंत्रण तर्क को नहीं दिखाना चाहिए। नहीं चित्रित करें कि “यदि यह, तो वह।” तर्क के लिए निर्णय बिंदु या बाहरी नोट्स का उपयोग करें, लेकिन तीर को डेटा गति पर केंद्रित रखें। क्लाउड सिस्टम में, जहाँ नियंत्रण तर्क अक्सर ऑर्केस्ट्रेशन प्लेटफॉर्म द्वारा संभाला जाता है, DFD को पेलोड पर ध्यान केंद्रित करना चाहिए।
2. असमान गति वाले फ्लो को नजरअंदाज करना
क्लाउड सिस्टम लगभग 100% समान गति वाले नहीं होते हैं। कार्य पृष्ठभूमि में चलते हैं। यदि आप केवल समान गति वाले अनुरोध-प्रतिक्रिया फ्लो को बनाते हैं, तो आपका डायग्राम अधूरा होगा। हमेशा पृष्ठभूमि के कार्य और घटना प्रवाह को डेटा स्टोर में आने या निकलने वाले डेटा फ्लो के रूप में शामिल करें।
3. विशिष्ट उपकरणों के लिए अत्यधिक अनुकूलन करना
किसी विशिष्ट उपकरण या प्लेटफॉर्म की क्षमताओं के आधार पर अपने डायग्राम को डिजाइन न करें। यदि आप किसी विशिष्ट डेटाबेस या संदेश ब्रोकर का चयन करते हैं, तो जब आप तकनीक बदलते हैं, तो डायग्राम पुराना हो सकता है। भौतिक कार्यान्वयन के बजाय डेटा के तार्किक प्रवाह पर ध्यान केंद्रित करें।
4. त्रुटि फ्लो को नजरअंदाज करना
सफल मार्ग बनाना आसान है। विफलता के मार्ग कठिन हैं लेकिन आवश्यक हैं। क्लाउड वातावरण में, सेवाएँ अक्सर विफल होती हैं। यह दर्शाएं कि त्रुटि डेटा कहाँ लॉग किया जाता है या रीट्राई मैकेनिज्म कहाँ सक्रिय होते हैं। इससे लचीले मॉनिटरिंग और चेतावनी प्रणालियों के डिजाइन में मदद मिलती है।
🔄 समय के साथ डायग्राम को बनाए रखना
एक डायग्राम केवल तभी उपयोगी है जब वह सटीक हो। क्लाउड-नेटिव एप्लिकेशन तेजी से बदलते हैं। नई सेवाएँ जोड़ी जाती हैं, पुरानी सेवाएँ बंद कर दी जाती हैं, और डेटा मॉडल विकसित होते हैं। यदि डायग्राम चल रहे सिस्टम के अनुरूप नहीं है, तो यह भ्रामक दस्तावेज़ बन जाता है। यहाँ उन्हें बनाए रखने का तरीका है।
- संस्करण नियंत्रण: आरेखों को कोड के रूप में लें। उन्हें अपने एप्लिकेशन कोड के साथ-साथ अपने संस्करण नियंत्रण प्रणाली में संग्रहीत करें। इससे इतिहास और ट्रेसेबिलिटी सुनिश्चित होती है।
- समीक्षा चक्र: अपनी कोड समीक्षा प्रक्रिया में आरेख अपडेट को शामिल करें। यदि कोई डेवलपर डेटा फ्लो में बदलाव करता है, तो उसी कमिट या पुल रिक्वेस्ट में आरेख को अपडेट किया जाना चाहिए।
- स्वचालित उत्पादन: जहां संभव हो, कोड या इंफ्रास्ट्रक्चर-एज-कोड परिभाषाओं से आरेख उत्पन्न करें। इससे दस्तावेजीकरण और वास्तविकता के बीच का अंतर कम होता है।
- हितधारक समन्वय: गैर-तकनीकी हितधारकों के साथ आरेखों की नियमित समीक्षा करें। इससे यह सुनिश्चित होता है कि स्तर दर्शकों के लिए उपयुक्त बना रहे।
📋 अन्य आर्किटेक्चरल दृष्टिकोणों के साथ DFDs की तुलना
DFD को अन्य आरेखों जैसे अनुक्रम आरेख या सिस्टम आर्किटेक्चर आरेख के साथ भ्रमित करना आम है। अंतर को समझने से आपको काम के लिए सही उपकरण चुनने में मदद मिलती है।
| आरेख प्रकार | प्राथमिक फोकस | सबसे अच्छा उपयोग किसके लिए |
|---|---|---|
| डेटा फ्लो आरेख | डेटा के गतिशीलता और रूपांतरण | सिस्टम डिजाइन, सुरक्षा ऑडिटिंग, डेटा मैपिंग |
| अनुक्रम आरेख | वस्तुओं के बीच समय-आधारित अंतरक्रिया | API एकीकरण, कॉल चेन के डीबगिंग |
| सिस्टम आर्किटेक्चर | इंफ्रास्ट्रक्चर और डेप्लॉयमेंट | DevOps, स्केलिंग, हार्डवेयर आवश्यकताएं |
| एंटिटी-संबंध | डेटा संरचना और संबंध | डेटाबेस डिजाइन, स्कीमा योजना |
एक DFD इन दृष्टिकोणों को पूरक करता है। जबकि एक आर्किटेक्चर आरेख यह दिखाता है कि सर्वर कहाँ स्थित हैं, एक DFD यह दिखाता है कि जानकारी उनके बीच कैसे यात्रा करती है। जबकि एक अनुक्रम आरेख कॉल के क्रम को दिखाता है, एक DFD पेलोड को दिखाता है। उनका साथ में उपयोग करने से सिस्टम की एक पूरी तस्वीर मिलती है।
🚀 क्लाउड मॉडलिंग में भविष्य के प्रवृत्तियाँ
जैसे-जैसे क्लाउड तकनीक विकसित होती है, मॉडलिंग की आवश्यकताएं भी बदलती हैं। सर्वरलेस कंप्यूटिंग और एज कंप्यूटिंग के उदय नए चुनौतियाँ लाते हैं। डेटा फ्लो अधिक विकेंद्रीकृत हो रहे हैं। प्रक्रियाएं उपयोगकर्ता के पास अधिक नजदीक चल रही हैं। इस परिवर्तन के कारण DFD को एज नोड्स और अस्थायी गणना संसाधनों को ध्यान में रखना होगा।
इसके अलावा, कार्यप्रवाह में कृत्रिम बुद्धिमत्ता के एकीकरण से जटिलता बढ़ जाती है। AI मॉडल डेटा का उपयोग करते हैं और दृष्टिकोण उत्पन्न करते हैं। इन प्रक्रियाओं को अक्सर बड़े डेटासेट और विशिष्ट हार्डवेयर की आवश्यकता होती है। भविष्य के DFD को इन गणना-भारी प्रक्रियाओं और उन्हें आपूर्ति करने वाले डेटा पाइपलाइन का प्रतिनिधित्व करने की आवश्यकता होगी। मूल सिद्धांत वही रहेंगे, लेकिन विस्तार और दायरा बढ़ेगा।
क्लाउड की वास्तविकताओं के अनुरूप डेटा फ्लो आरेखों के मूल सिद्धांतों का पालन करते हुए इंजीनियरिंग टीमें ऐसे सिस्टम बना सकती हैं जो पारदर्शी, सुरक्षित और स्केलेबल हों। डेटा का दृश्यीकरण केवल दस्तावेजीकरण का अभ्यास नहीं है; यह डिजाइन प्रक्रिया का एक महत्वपूर्ण चरण है जो उत्पादन तक पहुंचने से पहले त्रुटियों को रोकता है।