











डेटा फ्लो डायग्राम (DFD) सिस्टम विश्लेषण और डिजाइन की एक मूल बात बने हुए हैं। जबकि इन्हें अक्सर परिचयात्मक कोर्स में पेश किया जाता है, जटिल सॉफ्टवेयर इंजीनियरिंग परिदृश्यों में उनके उपयोग के लिए एक सूक्ष्म दृष्टिकोण की आवश्यकता होती है। इस गाइड में डेटा फ्लो डायग्राम बनाने, विश्लेषण करने और बनाए रखने की उन्नत तकनीकों का अध्ययन किया गया है। हम बेसिक बॉक्स-एंड-अरो प्रतिनिधित्व से आगे बढ़कर समानांतरता, डेटा अखंडता और संरचनात्मक संरेखण को संबोधित करते हैं। चाहे आप पुराने सिस्टम को रीफैक्टर कर रहे हों या नए माइक्रोसर्विस आर्किटेक्चर डिजाइन कर रहे हों, इन डायग्राम को समझने से संचार में स्पष्टता और कार्यान्वयन में सटीकता सुनिश्चित होती है।
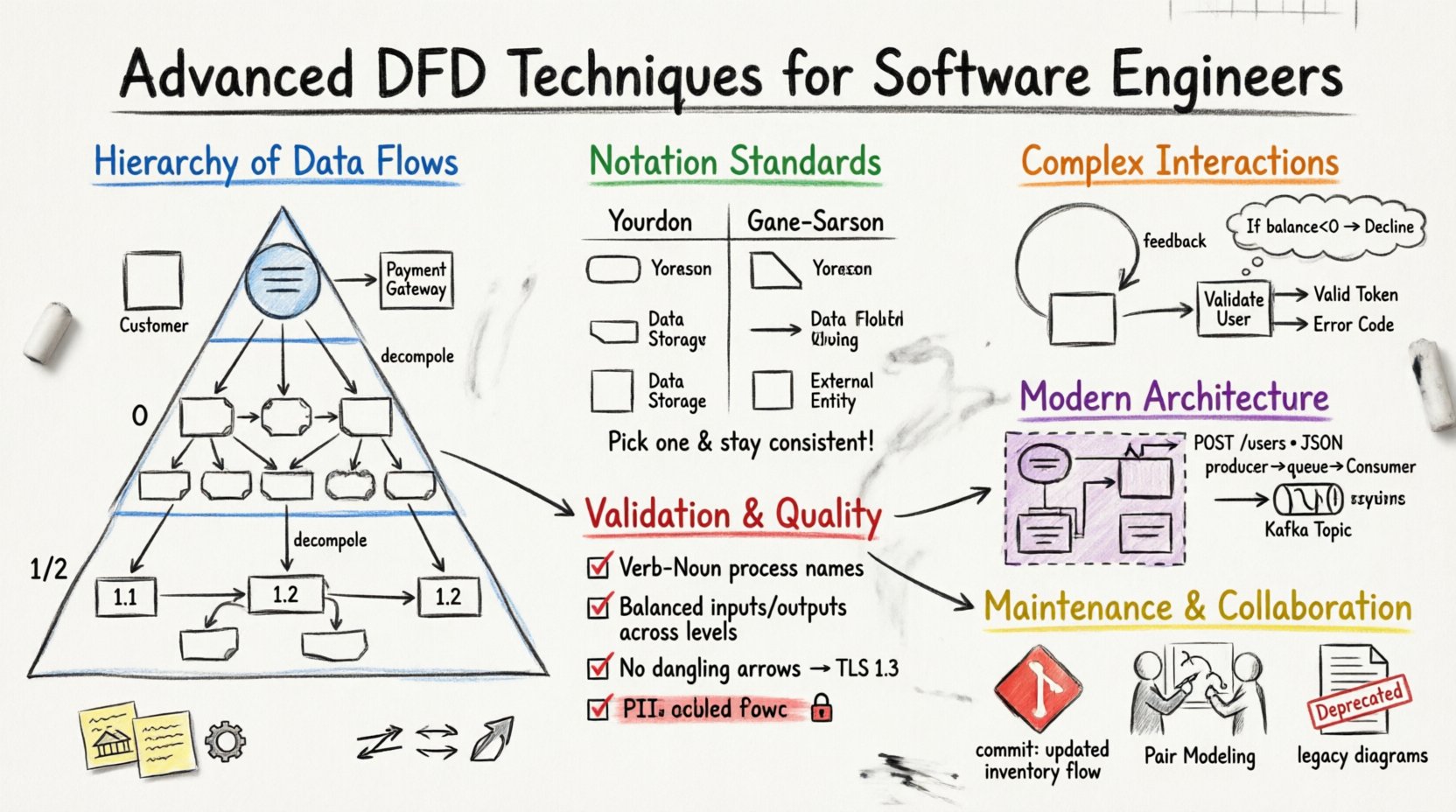
🏗️ डेटा फ्लो के पदानुक्रम को समझना
एक मजबूत DFD रणनीति परतदार दृष्टिकोण पर निर्भर करती है। एक ही स्तर पर सिस्टम का दृश्य प्रस्तुत करने से आवश्यक निर्भरताओं को छिपाया जा सकता है। सिस्टम को विशिष्ट स्तरों में विभाजित करके इंजीनियर जटिलता को प्रबंधित कर सकते हैं और संबंधित विवरणों पर ध्यान केंद्रित रख सकते हैं।
🌐 संदर्भ डायग्राम: मैक्रो दृश्य
संदर्भ डायग्राम सिस्टम की सीमा को परिभाषित करता है। इसमें सॉफ्टवेयर को एकल प्रक्रिया के रूप में दर्शाया जाता है और उससे बाहरी अंतर्क्रिया करने वाले सभी एकाधिकारियों को पहचाना जाता है। यह स्तर परियोजना की सीमा को परिभाषित करने के लिए निर्णायक है।
- बाहरी एकाधिकारी: ये उपयोगकर्ता, अन्य सिस्टम या सीमा के बाहर स्थित हार्डवेयर उपकरण हैं। उदाहरण के लिए एक ग्राहक, एक भुगतान गेटवे या एक पुराना डेटाबेस हो सकता है।
- डेटा प्रवाह: तीर सिस्टम में या उससे बाहर जाने वाली जानकारी के आंदोलन को दर्शाते हैं। लेबल में सामग्री को निर्दिष्ट करना आवश्यक है, जैसे कि “आदेश अनुरोध” या “बिल डेटा”।
- एकल प्रक्रिया: सिस्टम को एक गोलाकार आयत के रूप में दर्शाया जाता है, जिसे अक्सर सिस्टम के नाम से लेबल किया जाता है।
जब संदर्भ डायग्राम बनाते समय आंतरिक प्रक्रियाओं को शामिल न करें। उद्देश्य इंटरफेस संवाद बनाना है। यदि कोई एकाधिकारी डेटा भेजता है लेकिन कभी उसे नहीं प्राप्त करता है, तो जांचें कि क्या उस प्रवाह की आवश्यकता है। इसी तरह, सुनिश्चित करें कि बाहरी स्रोतों से आवश्यक सभी इनपुट को लिया गया है।
📉 स्तर 0: सिस्टम समीक्षा
इसे “टॉप-लेवल” या “पैरेंट” डायग्राम के रूप में भी जाना जाता है, स्तर 0 संदर्भ डायग्राम में एकल प्रक्रिया को प्रमुख उपप्रणालियों या कार्यात्मक क्षेत्रों में विस्तारित करता है। इस स्तर पर सिस्टम की क्षमताओं का उच्च स्तर का नक्शा प्रदान किया जाता है, बिना आंतरिक तर्क के विवरण के।
स्तर 0 की मुख्य विशेषताएं निम्नलिखित हैं:
- प्रमुख प्रक्रियाएं: आमतौर पर 5 से 9 प्रक्रियाएं। बहुत अधिक प्रक्रियाएं उच्च स्तर के समूहन की आवश्यकता को दर्शाती हैं; बहुत कम प्रक्रियाएं कार्यक्षमता के अभाव को संकेत करती हैं।
- डेटा भंडार: यह पहचानें कि स्थायी डेटा कहां रखा जाता है। इस स्तर पर यह दिखाया जाता है कि डेटा संग्रहीत है, लेकिन आवश्यक नहीं कि इसकी संरचना कैसी है।
- प्रवाह सुसंगतता: संदर्भ डायग्राम से प्रत्येक इनपुट और आउटपुट यहां दिखाए जाने चाहिए। इससे यह सुनिश्चित होता है कि विभाजन ने सिस्टम के बाहरी संवाद को नहीं बदला है।
🧩 स्तर 1 और 2: विभाजन रणनीतियां
जैसे ही आप स्तर 1 और स्तर 2 में गहराई से जाते हैं, ध्यान विशिष्ट कार्यों और डेटा संशोधन पर जाता है। यहीं इंजीनियरिंग कार्य की तर्क प्रणाली को दस्तावेजीकृत किया जाता है।
- विभाजन: स्तर 0 प्रक्रियाओं को उप-प्रक्रियाओं में विभाजित करें। उदाहरण के लिए, “आदेश प्रक्रिया” को “इन्वेंटरी की पुष्टि”, “भुगतान लेना” और “रसीद उत्पन्न करना” में बदला जा सकता है।
- विस्तार: प्रत्येक प्रक्रिया को संख्या दी जानी चाहिए (जैसे 1.0, 1.1, 1.2), ताकि डायग्रामों के बीच संबंधों को ट्रैक किया जा सके।
- डेटा भंडार पहुंच: स्पष्ट रूप से चिह्नित करें कि कौन सी प्रक्रियाएं किस डेटा भंडार से पढ़ती हैं या लिखती हैं। बाहरी एकाधिकारियों और डेटा भंडारों के बीच सीधे कनेक्शन से बचें; सभी पहुंच को एक प्रक्रिया के माध्यम से जाना चाहिए।
जब अपघटन कर रहे हों, तो यह सुनिश्चित करें कि डेटा प्रवाह नष्ट न हों। एक सामान्य त्रुटि यह है कि एक बच्चे के आरेख में एक डेटा प्रवाह को छोड़ देना जो मूल आरेख में मौजूद था। इसे एक “संतुलन” उल्लंघन के रूप में जाना जाता है।
🔣 नोटेशन मानक और प्रतीक अर्थविज्ञान
सही नोटेशन प्रणाली चुनने से यह सुनिश्चित होता है कि आरेख विकास टीम द्वारा सार्वभौमिक रूप से समझे जाएं। मानकों में भिन्नता होती है, लेकिन उद्योग में दो मुख्य विचारधाराएं प्रमुख हैं।
| विशेषता | योर-डॉनेल नोटेशन | गेन-सर्सन नोटेशन |
|---|---|---|
| प्रक्रियाएँ | गोल आयत | काटे हुए कोनों वाले आयत |
| डेटा भंडार | खुले आयत | खुले आयत |
| बाहरी एकाधिकार | वर्ग | वर्ग |
| डेटा प्रवाह | तीर वाली रेखाएँ | तीर वाली रेखाएँ |
| लेबल | संज्ञा वाक्यांश | संज्ञा वाक्यांश |
सांस्कृतिकता महत्वपूर्ण है। एक ही दस्तावेज़ सेट के भीतर नोटेशन को मिलाना भ्रम पैदा करता है। एक मानक चुनें और सभी आरेखों में उसका पालन करें। चयन अक्सर इंजीनियरिंग संस्कृति या मौजूदा दस्तावेज़ टेम्पलेट पर निर्भर करता है।
⚙️ जटिल डेटा अंतरक्रियाओं का प्रबंधन
वास्तविक दुनिया के प्रणालियाँ दुर्लभ रूप से रेखीय होती हैं। इनमें लूप, शाखाओं वाली तर्क और असमान घटनाएँ शामिल होती हैं। इन गतिशीलताओं को एक स्थिर आरेख में प्रस्तुत करने के लिए विशिष्ट तकनीकों की आवश्यकता होती है।
🔄 लूप और पुनरावृत्तियों का प्रबंधन
DFD प्रवाह चार्ट नहीं हैं; वे नियंत्रण प्रवाह (यदि-तो-नहीं) को स्पष्ट रूप से नहीं दिखाते हैं। हालांकि, डेटा लूप आम हैं। उदाहरण के लिए, एक “कर की गणना” प्रक्रिया डेटा को “दर खोज” भंडार में भेज सकती है और परिणाम वापस प्राप्त कर सकती है।
- प्रतिपुष्टि लूप:पुनर्मूल्यांकन को दर्शाने के लिए एक प्रक्रिया में वापस लौटने वाले तीर का उपयोग करें। इन्हें स्पष्ट रूप से लेबल करें ताकि यह स्पष्ट हो कि कौन सा डेटा अद्यतन किया जा रहा है।
- पुनरावृत्तिपूर्ण प्रक्रियाएँ:यदि एक प्रक्रिया तब तक दोहराई जाती है जब तक कि एक शर्त पूरी नहीं हो जाती, तो शर्त को प्रक्रिया विवरण या पाठ अनोटेशन में चिह्नित करें। लूप को नियंत्रण प्रवाह रेखा के रूप में बनाने से बचें।
- डेटा अपडेट्स: एक अपडेट ऑपरेशन को दर्शाने के लिए डेटा स्टोर में वापस लौटने वाले डेटा फ्लो को दिखाएं।
🧭 निर्णय बिंदुओं का प्रतिनिधित्व करना
निर्णय तर्क प्रक्रिया विवरण में होना चाहिए, न कि आरेख में। “उपयोगकर्ता की पुष्टि करें” नाम वाली प्रक्रिया में आंतरिक तर्क का अनुमान होता है। “पुष्टि करें” और “अस्वीकृत करें” में प्रक्रिया को विभाजित न करें। प्रक्रिया को परमाणु रखें।
- आउटपुट भेदभाव: यदि कोई प्रक्रिया आंतरिक निर्णय के आधार पर अलग-अलग डेटा भेजती है, तो अलग-अलग डेटा फ्लो लेबल का उपयोग करें (उदाहरण के लिए, “वैध टोकन” बनाम “त्रुटि कोड”)।
- टिप्पणियाँ: निर्णय मानदंड को स्पष्ट करने के लिए टेक्स्ट बॉक्स का उपयोग करें। उदाहरण के लिए, “यदि बैलेंस < 0, तो फ्लो ‘अस्वीकृत करें’”।
- परमाणुता: सुनिश्चित करें कि प्रत्येक प्रक्रिया एक तार्किक कार्य करे। यदि यह कई अलग-अलग निर्णयों को संभालती है, तो उन्हें अलग-अलग प्रक्रियाओं में विभाजित करने की विचार करें।
🔗 आधुनिक आर्किटेक्चर्स के साथ DFD का एकीकरण
सॉफ्टवेयर इंजीनियरिंग विकसित हुई है। वितरित प्रणालियों, क्लाउड कंप्यूटिंग और API-आधारित डिजाइनों की ओर बढ़ने के कारण डेटा फ्लो के दृष्टिकोण में बदलाव आया है। DFD को इन वास्तविकताओं को दर्शाने के लिए अपडेट करना चाहिए, बिना पुराने होने के।
☁️ माइक्रोसर्विसेज और API एंडपॉइंट्स
एक मोनोलिथिक आर्किटेक्चर में, एक प्रक्रिया एक मॉड्यूल का प्रतिनिधित्व कर सकती है। माइक्रोसर्विसेज वातावरण में, एक प्रक्रिया अक्सर एक सेवा उदाहरण का प्रतिनिधित्व करती है। डेटा फ्लो एक API कॉल में बदल जाता है।
- सेवा सीमाएँ:एक माइक्रोसर्विस का निर्माण करने वाली प्रक्रियाओं के सेट के चारों ओर एक बॉक्स खींचें। इस सीमा को पार करने वाले डेटा फ्लो नेटवर्क रिक्वेस्ट हैं।
- API संविदाएँ: डेटा फ्लो को विशिष्ट API एंडपॉइंट या पेलोड संरचना के साथ लेबल करें (उदाहरण के लिए, “POST /users”, “JSON पेलोड”)।
- राज्यहीनता: यदि कोई सेवा राज्यहीन है, तो सेवा सीमा के भीतर डेटा स्टोर न दिखाएं, बशर्ते कि यह अस्थायी कैशिंग के लिए न हो। स्थायी भंडारण बाहरी होना चाहिए।
📨 असमान समय संदेश और कतारें
सभी डेटा फ्लो वास्तविक समय में नहीं होते हैं। बैकग्राउंड कार्य और घटना-आधारित आर्किटेक्चर कतारों पर निर्भर करते हैं।
- कतारों को डेटा स्टोर के रूप में: संदेश कतारों (उदाहरण के लिए, RabbitMQ, Kafka विषय) को डेटा स्टोर प्रतीक का उपयोग करके दर्शाएं। इससे स्पष्ट होता है कि डेटा अस्थायी रूप से संरक्षित होता है।
- उत्पादक/उपभोक्ता: उत्पादक प्रक्रिया को कतार में लिखते हुए और उपभोक्ता प्रक्रिया को उसमें से पढ़ते हुए दिखाएं। फ्लो अलग-अलग है।
- लेटेंसी के प्रभाव: टिप्पणियों में नोट करें कि लेखन के बाद डेटा तुरंत उपलब्ध नहीं होता है। यह विफलता के परिदृश्यों में सिस्टम के व्यवहार को समझने के लिए महत्वपूर्ण है।
🛡️ सत्यापन और सुसंगतता जांच
एक आरेख केवल तभी उपयोगी है जब वह प्रणाली का सही प्रतिनिधित्व करता है। सत्यापन सुनिश्चित करता है कि मॉडल गणितीय और तार्किक रूप से सही है। इंजीनियरों को दस्तावेज़ीकरण के अंतिम रूप देने से पहले इन जांचों को करना चाहिए।
⚖️ डेटा संतुलन सत्यापन
एक आरेख में प्रवेश करने वाले प्रत्येक डेटा प्रवाह की गणना की जानी चाहिए। यह डेटा के संरक्षण का सिद्धांत है।
- इनपुट/आउटपुट मैचिंग: सुनिश्चित करें कि मातृ आरेख से प्रत्येक इनपुट बाल आरेख में दिखाई दे। कोई भी इनपुट गायब नहीं हो सकता।
- आउटपुट पूर्णता: उच्च स्तर पर परिभाषित सभी आउटपुट को निम्न स्तर पर उपलब्ध होना चाहिए। यदि एक बाल प्रक्रिया एक नया आउटपुट उत्पन्न करती है, तो इसे एक नए आवश्यकता या आंतरिक प्रभाव के रूप में तर्कसंगत बनाया जाना चाहिए।
- स्टोर संगतता: डेटा स्टोर को सभी स्तरों पर संगत रहना चाहिए। यदि लेवल 1 में एक स्टोर बनाया गया है, तो लेवल 0 में भी उसका अस्तित्व होना चाहिए।
🏷️ नामकरण प्रथाएँ
नामकरण में स्पष्टता अस्पष्टता को रोकती है। खराब लेबल तकनीकी दस्तावेज़ीकरण में गलत व्याख्या का सबसे सामान्य स्रोत हैं।
- क्रिया-संज्ञा प्रारूप: प्रक्रियाओं के नाम क्रिया और संज्ञा के साथ रखे जाने चाहिए (उदाहरण के लिए, “कर की गणना करें”, “प्रोफ़ाइल अपडेट करें”)। केवल संज्ञा (उदाहरण के लिए, “कर”) या वस्तु के बिना क्रिया वाक्यांश (उदाहरण के लिए, “गणना कर रहे हैं”) का उपयोग न करें।
- डेटा प्रवाह लेबल: विशिष्ट संज्ञाओं का उपयोग करें (उदाहरण के लिए, “इन्वॉइस आईडी”, “उपयोगकर्ता सत्र”)। “डेटा” या “जानकारी” जैसे अस्पष्ट शब्दों से बचें।
- एकांत नाम: बाहरी एकांतों की संगतता होनी चाहिए। “ग्राहक” का एक ही आरेख सेट में “ग्राहक” या “उपयोगकर्ता” में बदलना नहीं चाहिए।
🔄 रखरखाव और दस्तावेज़ीकरण जीवनचक्र
DFD स्थिर अस्तित्व नहीं हैं। वे सॉफ्टवेयर में परिवर्तन के साथ विकसित होने चाहिए। एक अद्यतन आरेख, बिना किसी आरेख के होने से भी बदतर है, क्योंकि यह गलत समझ का भ्रम पैदा करता है।
📦 आरेखों के लिए संस्करण नियंत्रण
आरेखों को कोड की तरह लें। उन्हें स्रोत कोड भंडार के साथ एक संस्करण नियंत्रण प्रणाली में संग्रहीत करें।
- कमिट संदेश: आरेख के कमिट में परिवर्तनों का दस्तावेज़ीकरण करें। “भुगतान गेटवे प्रक्रिया जोड़ी गई”, “इन्वेंटरी प्रवाह अद्यतन किया गया”।
- दृश्य तुलना: अनचाहे संरचनात्मक परिवर्तनों को देखने के लिए ऐसे उपकरणों का उपयोग करें जो आरेखों की दृश्य तुलना की अनुमति देते हैं।
- संबंध: आरेखों को उन विशिष्ट पुल अनुरोधों या टिकटों से जोड़ें जिन्होंने परिवर्तन का कारण बनाया है। इससे ट्रेसेबिलिटी प्रदान होती है।
🤝 सहयोग रणनीतियाँ
दस्तावेज़ीकरण एक टीम का प्रयास है। केवल एक वास्तुकार पर निर्भर रहना DFD के रखरखाव के लिए बॉटलनेक और अद्यतन नहीं जाने वाली जानकारी के लिए ले जाता है।
- जोड़ी मॉडलिंग: डिज़ाइन चरण के दौरान दो इंजीनियरों को एक साथ एक आरेख बनाने के लिए कहें। इससे त्रुटियों को जल्दी पकड़ा जा सकता है।
- समीक्षा चक्र: मानक कोड समीक्षा प्रक्रिया में DFD समीक्षा शामिल करें। यदि कोड में परिवर्तन होता है, तो आरेख को अद्यतन किया जाना चाहिए या असंगत बताया जाना चाहिए।
- जीवित दस्तावेज़: पुराने आरेखों को आर्काइव करने से बचें। इसके बजाय उन्हें रिपॉजिटरी के भीतर “अप्रचलित” या “पुराना” के रूप में चिह्नित करें। इससे इतिहास सुरक्षित रहता है बिना वर्तमान दृश्य को भारी बनाए।
🧠 उन्नत कार्यान्वयन विचार
दृश्य प्रतिनिधित्व से आगे, मूल डेटा संरचनाएँ और तर्क प्रवाह को निर्धारित करते हैं। इंजीनियरों को डेटा की भौतिक सीमाओं को ध्यान में रखना चाहिए।
📏 डेटा आयतन और थ्रूपुट
DFD तार्किक प्रवाह का वर्णन करते हैं, प्रदर्शन का नहीं। हालांकि, उच्च आयतन वाले प्रवाह डिज़ाइन को प्रभावित करते हैं।
- बड़े डेटा प्रवाह: यदि कोई प्रवाह बड़े फाइलों या लॉग्स को शामिल करता है, तो इसका चिह्नांकन लेबल के साथ करें। इससे एक अलग परिवहन तंत्र के उपयोग के निर्णय को प्रभावित कर सकता है।
- संपीड़न: ध्यान दें कि डेटा स्थानांतरण से पहले संपीड़ित किया गया है या नहीं। इससे प्राप्त करने वाले सिस्टम पर प्रोसेसिंग लोड प्रभावित होता है।
- एन्कोडिंग: यदि प्रवाह प्लेटफॉर्म सीमाओं को पार करता है (उदाहरण के लिए, UTF-8 बनाम ASCII), तो अक्षर एन्कोडिंग निर्दिष्ट करें।
🔒 सुरक्षा और पहुंच नियंत्रण
सुरक्षा एक बाद की बात नहीं है। इसे डेटा प्रवाह में दिखाई देना चाहिए।
- एन्क्रिप्शन: एन्क्रिप्शन की आवश्यकता वाले प्रवाहों को चिह्नित करें। “एन्क्रिप्टेड स्ट्रीम” या “TLS 1.3” जैसे लेबल का उपयोग करें।
- PII का प्रबंधन: विश्वसनीय व्यक्तिगत जानकारी वाले प्रवाहों को उजागर करें। इससे डिज़ाइन में संगतता आवश्यकताओं को पूरा करने में सुनिश्चित होता है।
- प्रमाणीकरण: यह दिखाएं कि प्रमाणपत्र कहाँ पारित किए जाते हैं। सामान्य पाठ में पासवर्ड दिखाने से बचें; इसे “प्रमाणीकरण टोकन” के रूप में लेबल करें।
📝 आरेख गुणवत्ता के लिए चेकलिस्ट
डेटा प्रवाह आरेखों के सेट को अंतिम रूप देने से पहले, इस सत्यापन चेकलिस्ट को चलाएं।
- क्या सभी बाहरी एकाधिकार स्पष्ट रूप से परिभाषित हैं?
- क्या सभी डेटा प्रवाहों के वर्णनात्मक लेबल हैं?
- क्या प्रत्येक प्रक्रिया का नाम क्रिया-संज्ञा संरचना में है?
- क्या कोई भी प्रतिच्छेदन वाली रेखाएँ हैं जिन्हें स्पष्टता के लिए दूसरे रास्ते पर ले जाया जा सकता है?
- क्या मातृ आरेख में प्रत्येक इनपुट बच्चे आरेख में दिखाई देता है?
- क्या डेटा स्टोरेज को प्रक्रियाओं से सही तरीके से अलग किया गया है?
- क्या आरेख संदर्भ आरेख के साथ संतुलित है?
- क्या कोई लटकता त стрील (कोई गंतव्य नहीं वाले प्रवाह) है?
- क्या दस्तावेज सेट के पूरे में निर्देशांक स्थिर हैं?
- संवेदनशील प्रवाहों पर सुरक्षा सीमाओं को नोट किया गया है?
इन उन्नत तकनीकों का पालन करके, सॉफ्टवेयर � ingineers विकास के लिए विश्वसनीय नक्शे के रूप में कार्य करने वाले दस्तावेज तैयार कर सकते हैं। DFDs सामान्य आवश्यकताओं और वास्तविक कार्यान्वयन के बीच के अंतर को दूर करते हैं। वे स्टेकहोल्डर्स के बीच संचार को सुगम बनाते हैं, तर्क में अस्पष्टता को कम करते हैं और परीक्षण के लिए एक आधार तैयार करते हैं। जब अनुशासन के साथ बनाए रखा जाता है और कठोरता से अद्यतन किया जाता है, तो वे इंजीनियरिंग आर्सेनल में एक शक्तिशाली उपकरण बने रहते हैं।
🚀 सिस्टम मॉडलिंग पर अंतिम विचार
डेटा प्रवाह आरेख का मूल्य इसकी जटिलता को सरल बनाने की क्षमता में निहित है। यह व्याकरण और कार्यान्वयन विवरण की शोर से छुटकारा पाकर मूल्य के हस्तांतरण पर ध्यान केंद्रित करता है। सॉफ्टवेयर इंजीनियरों के लिए, इस ध्यान केंद्रित करना आवश्यक है। यह डिजाइन की कमियों का प्रारंभिक पता लगाने, नए सदस्यों के लिए स्पष्ट ओनबोर्डिंग और सिस्टम वास्तुकला के लिए साझा मानसिक मॉडल प्रदान करने में सक्षम बनाता है। मॉडलिंग की प्रक्रिया के प्रति प्रतिबद्ध रहें। इसमें प्रयास की आवश्यकता होती है, लेकिन सिस्टम स्पष्टता में निवेश का लाभ बहुत बड़ा है।
याद रखें कि आरेख एक उद्देश्य के लिए एक साधन है। यह कोड का समर्थन करता है, न कि इसके विपरीत। आरेखों को संक्षिप्त, सटीक और पहुंच योग्य रखें। जैसे ही सिस्टम विकसित होता है, आरेखों को उसके साथ विकसित होने दें। इस गतिशील दृष्टिकोण से यह सुनिश्चित होता है कि दस्तावेज़ीकरण एक जीवंत संपत्ति बनी रहे, न कि एक स्थिर बोझ।