











पिछले दस वर्षों में डेटा प्रबंधन का दृश्य बहुत बदल गया है। जैसे-जैसे एप्लिकेशनों का आकार और जटिलता बढ़ी, पिछले समय की कठोर संरचनाएं दरारें दिखाने लगीं। NoSQL डेटाबेस विशाल डेटासेट्स, उच्च गति वाले स्ट्रीम और असंरचित जानकारी को संभालने के लिए उभरे, जिन्हें पारंपरिक संबंधात्मक मॉडल दक्षतापूर्वक समायोजित करने में कठिनाई होती थी। इस विकास ने वार्किटेक्ट्स और डेवलपर्स के बीच एक लगातार विवाद को जन्म दिया: क्या NoSQL पारंपरिक एंटिटी रिलेशनशिप डायग्राम्स (ERDs) की आवश्यकता को समाप्त कर देगा? 🤔
इसका उत्तर देने के लिए, हमें शोर और विज्ञापन के पार जाना होगा और डेटा मॉडलिंग के मूल उद्देश्य का अध्ययन करना होगा। जब तक NoSQL तकनीकों ने हमारे डेटा संग्रहण के तरीके को बदल दिया है, लेकिन रिलेशनशिप को दृश्य रूप से दिखाने और जानकारी को संरचित करने की आवश्यकता सिस्टम स्थिरता के लिए एक मूल आवश्यकता बनी हुई है। यह गाइड स्कीमा डिजाइन के बारीकियों, पॉलीग्लॉट पर्सिस्टेंस दुनिया में ERD की भूमिका और उद्योग के भविष्य की ओर देखता है।
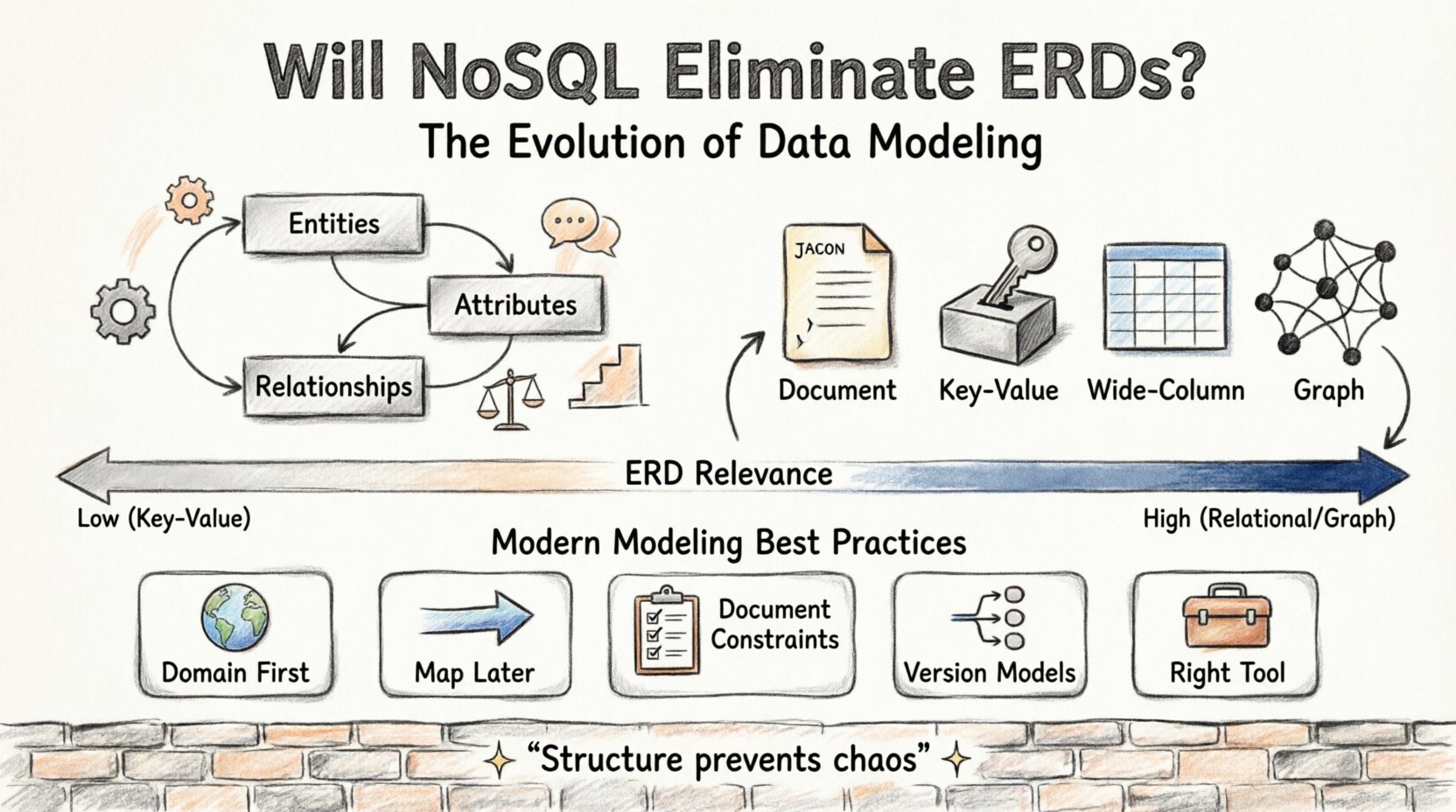
आधार को समझना: एक ERD क्या है? 🏗️
एक एंटिटी रिलेशनशिप डायग्राम डेटा संरचनाओं और उनके एक दूसरे से संबंधों का दृश्य प्रतिनिधित्व है। इसका विकास 1970 के शुरुआती वर्षों में किया गया था और यह संबंधात्मक डेटाबेस डिजाइन के लिए ब्लूप्रिंट बन गया। एक ERD एंटिटी (टेबल), एट्रिब्यूट (कॉलम) और रिलेशनशिप (विदेशी की) को निरूपित करने के लिए विशिष्ट प्रतीकों का उपयोग करता है।
एक ERD के प्राथमिक उद्देश्यों में शामिल हैं:
- स्पष्टता:डेवलपर्स के लिए डेटा प्रवाह को समझने के लिए एक दृश्य मानचित्र प्रदान करना।
- अखंडता:यह सुनिश्चित करना कि डेटा नियम प्रणाली लाइव होने से पहले लागू किए जाएँ।
- संचार:व्यवसाय स्टेकहोल्डर्स और इंजीनियरिंग टीमों के बीच एक सार्वभौमिक भाषा के रूप में कार्य करना।
- नॉर्मलाइजेशन:पुनरावृत्ति को कम करने और सुसंगतता में सुधार करने के लिए डेटा को व्यवस्थित करना।
एक संबंधात्मक संदर्भ में, इन डायग्राम्स वैकल्पिक नहीं हैं। ये एप्लिकेशन और स्टोरेज इंजन के बीच संविदा हैं। इनके बिना, जॉइन्स को योजना बनाना असंभव हो जाता है, और लेनदेन संपूर्णता के लिए खतरा होता है।
NoSQL का विघटन: एक नया पैराडाइम 📉
NoSQL डेटाबेस को विद्रोह के लिए नियमों को तोड़ने के लिए नहीं बनाया गया था। उनका जन्म आवश्यकता से हुआ था। जैसे-जैसे वेब का पैमाना बढ़ा, क्षैतिज स्केलिंग (अधिक सर्वर जोड़ना) की आवश्यकता ऊर्ध्वाधर स्केलिंग (एक सर्वर की शक्ति बढ़ाना) की तुलना में अधिक महत्वपूर्ण हो गई। संबंधात्मक डेटाबेस जो अक्सर क्षैतिज स्केलिंग में कठिनाई महसूस करते हैं, उनके स्थान पर विकल्प आ गए।
NoSQL सिस्टम के कई वर्ग हैं, जिनमें प्रत्येक के अलग-अलग मॉडलिंग आवश्यकताएं हैं:
- दस्तावेज़ स्टोर्स:डेटा को JSON-जैसे दस्तावेज़ों में संग्रहीत करते हैं। संबंध अक्सर विदेशी की के माध्यम से जुड़े होते हैं, बल्कि एम्बेडेड होते हैं।
- की-वैल्यू स्टोर्स:यूनिक पहचानकर्ताओं पर आधारित सरल खोज। कोई जटिल संबंध नहीं।
- वाइड-कॉलम स्टोर्स:वितरित प्रणालियों में विशाल डेटासेट्स के लिए अनुकूलित। स्कीमा लचीला है और पढ़ने के समय परिभाषित किया जाता है।
- ग्राफ डेटाबेस:बहुत अधिक जुड़े हुए डेटा के लिए विशेष रूप से डिज़ाइन किया गया है। नोड्स और एजेस टेबल्स और रोज़ के स्थान पर आते हैं।
इन मॉडल्स में से कई में, कठोर, पूर्व-निर्धारित स्कीमा की अवधारणा ढीली हो गई है। इस लचीलेपन ने यह मान्यता जन्म दी कि पारंपरिक योजना उपकरण जैसे ERD पुराने हो गए हैं। डेवलपर्स को कोडिंग शुरू करने, डेटा भेजने और बाद में संरचना ठीक करने की अनुमति मिली। इस प्रक्रिया को अक्सर “रीड-पर-स्कीमा” कहा जाता है।
क्यों “No ERD” का भ्रम बना हुआ है 🚫📄
नोस्क्वल डिज़ाइन की आवश्यकता नहीं होती है, इस विचार का उद्भव प्रारंभिक उपयोग में आसानी से उत्पन्न हुआ है। एक दस्तावेज़-आधारित भंडार में, आप कॉलम को पहले परिभाषित किए बिना एक रिकॉर्ड डाल सकते हैं। यह गति प्रोटोटाइपिंग के लिए आकर्षक है। हालांकि, जैसे-जैसे एप्लिकेशन बढ़ता है, इस अव्यवस्था के कारण तकनीकी देनदारी उत्पन्न होती है।
आम गलतफहमियाँ शामिल हैं:
- “यह सिर्फ जेसॉन है।” जबकि पेलोड जेसॉन जैसा दिखता है, तथापि आधारभूत स्टोरेज इंजन को प्रभावी रूप से प्रश्न पूछने के लिए संगठन की आवश्यकता होती है।
- “संबंध महत्वपूर्ण नहीं हैं।” डेटा दुर्लभ रूप से अलग-अलग होता है। एक उपयोगकर्ता के आदेश होते हैं, आदेशों में आइटम होते हैं, और आइटमों में श्रेणियाँ होती हैं। इन लिंक को नजरअंदाज करने से डेटा की दोहराव और असंगति उत्पन्न होती है।
- “स्कीमा विकास स्वचालित है।” योजना बनाए बिना वितरित प्रणाली में डेटा की संरचना बदलने से माइग्रेशन के दौरान बंदी या डेटा क्षति हो सकती है।
आधुनिक आर्किटेक्चर में ईआरडी की भूमिका 🔄
जबकि ईआरडी का सख्त 1-से-1 मैपिंग एसक्यूएल टेबल्स के साथ धुंधला हो रहा है, वह अवधारणा ईआरडी की अवधारणा विकसित हो रही है। यह अब सिर्फ टेबल्स के बारे में नहीं है; यह डेटा कनेक्टिविटी के बारे में है। नोस्क्वल पर्यावरण में भी, डेटा एंटिटीज के कैसे जुड़ती हैं, इसकी समझ प्रदर्शन और रखरखाव के लिए महत्वपूर्ण है।
यहाँ विभिन्न स्टोरेज प्रकारों के बीच डेटा मॉडलिंग के कार्य कैसे बदलता है, इसका विवरण है:
| डेटाबेस प्रकार | मॉडलिंग फोकस | ईआरडी प्रासंगिकता |
|---|---|---|
| संबंधित (एसक्यूएल) | नॉर्मलाइजेशन, विदेशी कीज़ | उच्च (आवश्यक) |
| दस्तावेज़ स्टोर | अनॉर्मलाइजेशन, एम्बेडिंग | मध्यम (अवधारणात्मक) |
| ग्राफ डेटाबेस | नोड्स, एजेस, ट्रैवर्सल | उच्च (अलग तरीके से दृश्याकृत) |
| की-वैल्यू स्टोर | पहचानकर्ता खोज | निम्न (न्यूनतम) |
| वाइड-कॉलम | पार्टीशन कीज़, क्लस्टरिंग | मध्यम (संरचनात्मक) |
जैसा कि तालिका में दिखाया गया है, डायग्रामिंग की प्रासंगिकता बदल जाती है। ग्राफ डेटाबेस के लिए एक दृश्य डायग्राम वास्तव में कीव-वैल्यू स्टोर की तुलना में अधिक महत्वपूर्ण होता है। शब्दावली में “टेबल्स” से “नोड्स” में बदलाव आता है, लेकिन संबंधों को समझने की आवश्यकता बनी रहती है।
जब एरडीएस अभी भी आवश्यक होते हैं 🛡️
ऐसे विशिष्ट परिस्थितियाँ हैं जहाँ डिज़ाइन चरण को छोड़ना विफलता का रास्ता है। यहाँ तक कि लचीले नो-एसक्यूएल स्टोरेज के साथ भी, कुछ सीमाएँ लागू होती हैं।
1. डेटा अखंडता और सुसंगतता
वित्तीय प्रणालियों या इन्वेंट्री प्रबंधन में, डेटा सटीकता अनिवार्य है। यदि आप एक डॉक्यूमेंट स्टोर में स्कीमा को परिभाषित किए बिना एक लेनदेन स्टोर करते हैं, तो आप अमान्य स्थिति के डेटा डालने के जोखिम में हैं। एक डायग्राम यह निर्धारित करने में मदद करता है कि रेफरेंशियल इंटीग्रिटी चेक कहाँ आवश्यक हैं, भले ही वे डेटाबेस लेयर के बजाय एप्लीकेशन लेयर में लागू किए जाएँ।
2. जटिल क्वेरी पैटर्न
जैसे-जैसे डेटासेट बढ़ता है, डेटा को प्रश्न करना एक्सपोनेंशियल रूप से मुश्किल हो जाता है। यदि आप डेटा कैसे प्राप्त करेंगे, इसकी योजना नहीं बनाते हैं, तो आपको पूरी टेबल स्कैन करने या अक्षम लुकअप करने के लिए मजबूर होना पड़ सकता है। पढ़ने के पैटर्न को समझना डॉक्यूमेंट या कॉलम की संरचना निर्धारित करने में मदद करता है।
3. टीम सहयोग
बड़ी टीमें डेटा संरचना के बारे में मौखिक सहमति पर भरोसा नहीं कर सकती हैं। एरडीएस दस्तावेज़ीकरण के रूप में काम करता है। जब कोई नया डेवलपर शामिल होता है, तो वह डायग्राम को देखकर डोमेन मॉडल को समझता है। इसके बिना, ऑनबोर्डिंग लंबी होती है और बग बढ़ते हैं।
4. पॉलीग्लॉट पर्सिस्टेंस
आधुनिक एप्लीकेशन अक्सर एक साथ कई डेटाबेस प्रकार का उपयोग करते हैं। आप उपयोगकर्ता खातों के लिए एक संबंधात्मक स्टोर, उत्पाद कैटलॉग के लिए एक डॉक्यूमेंट स्टोर और सुझाव इंजन के लिए एक ग्राफ स्टोर का उपयोग कर सकते हैं। इन विभिन्न स्टोर के बीच डेटा के प्रवाह को मैप करने के लिए संपूर्ण सिस्टम आर्किटेक्चर डायग्राम की आवश्यकता होती है।
नो-एसक्यूएल के लिए मॉडलिंग: पारंपरिक एरडीएस से आगे 🧠
नो-एसक्यूएल को अपनाने के लिए मानसिकता में परिवर्तन की आवश्यकता होती है। पारंपरिक नॉर्मलाइजेशन नियम (1NF, 2NF, 3NF) अक्सर उल्टे हो जाते हैं। आवश्यक क्वेरी की संख्या को कम करने के लिए डेनॉर्मलाइजेशन एक बेस्ट प्रैक्टिस बन जाता है। यहीं पर “डायग्राम” का आकार बदल जाता है।
डेनॉर्मलाइजेशन पैटर्न:
- एम्बेडिंग:एक ही दस्तावेज़ के भीतर संबंधित डेटा स्टोर करना। उदाहरण: उपयोगकर्ता प्रोफाइल के भीतर पता स्टोर करना।
- रेफरेंसिंग:अलग दस्तावेज़ रखना और आईडी द्वारा लिंक करना। उदाहरण: एक ऑर्डर दस्तावेज़ में उपयोगकर्ता आईडी।
- एग्रीगेशन:रनटाइम गणित से बचने के लिए डेटा की पूर्व-गणना करना। उदाहरण: कुल कार्ट मूल्य स्टोर करना।
इन संरचनाओं के डिज़ाइन करते समय, वास्तुकार अक्सर एक बनाते हैंलॉजिकल डेटा मॉडलएक सख्त भौतिक एरडीएस के बजाय। इस मॉडल में विशिष्ट टेबल परिभाषाओं के बिना संबंधों और कार्डिनैलिटी पर ध्यान केंद्रित किया जाता है। यह ऐसे प्रश्नों के उत्तर देता है जैसे:
- क्या यह एक-एक या एक-बहुत संबंध है?
- संबंध के किस पक्ष को “मालिक” कहा जाता है?
- इस डेटा को पढ़ने की तुलना में लिखने की आवृत्ति कितनी है?
नो-एसक्यूएल सिस्टम के डायग्रामिंग में चुनौतियाँ ⚠️
लचीले स्कीमा के लिए डायग्राम बनाना अद्वितीय चुनौतियाँ पेश करता है। पारंपरिक उपकरणों को निश्चित कॉलम की उम्मीद होती है। नो-एसक्यूएल के लिए डायनामिक संरचनाओं की उम्मीद होती है। इस असंगति के कारण डिज़ाइन प्रक्रिया में तनाव उत्पन्न हो सकता है।
1. स्कीमा विकास
क्योंकि NoSQL स्कीमा बदलाव की अनुमति देता है, टीमें अक्सर आगे की योजना बनाने के दबाव को कम महसूस करती हैं। हालांकि, वितरित प्रणाली में मूल डेटा संरचना में बदलाव करना महंगा हो सकता है। माइग्रेशन स्क्रिप्ट्स को ध्यान से लिखना आवश्यक है। एक आरेख समय के साथ संस्करण परिवर्तनों को ट्रैक करने में मदद करता है।
2. प्रश्न-पहले डिज़ाइन
NoSQL में, आप अक्सर डेटा संरचना को उसके अनुरोध करने के तरीके के आधार पर डिज़ाइन करते हैं, बस उसे कैसे स्टोर करना है, इसके आधार पर नहीं। इसे ‘प्रश्न-चालित डिज़ाइन’ के रूप में जाना जाता है। एक पारंपरिक ERD स्टोरेज की कुशलता पर ध्यान केंद्रित करता है। एक NoSQL मॉडल प्रश्न की कुशलता पर ध्यान केंद्रित करता है। आरेख पढ़ने के मार्गों को दर्शाना चाहिए, बस लेखन मार्गों को नहीं।
3. दृश्य जटिलता
ग्राफ डेटाबेस अत्यंत घने आरेखों के नतीजे के रूप में निकल सकते हैं। हजारों नोड्स के साथ, एक स्थिर छवि पढ़ने योग्य नहीं बन जाती है। इस पैमाने को संभालने के लिए स्वचालित विज़ुअलाइज़ेशन टूल्स की आवश्यकता होती है, लेकिन तार्किक संबंधों को अभी भी परिभाषित करना आवश्यक है।
डेटा मॉडलिंग में भविष्य के प्रवृत्तियाँ 🚀
उद्योग हाइब्रिड दृष्टिकोण की ओर बढ़ रहा है। हम संरचना छोड़ रहे नहीं हैं, लेकिन हम उसे अनुकूलित कर रहे हैं। यहाँ भविष्य में संभावित रूप से क्या होगा, उसके बारे में है।
- स्कीमा सत्यापन स्तर:बहुत सारे NoSQL इंजन अब वैकल्पिक स्कीमा सत्यापन प्रदान करते हैं। इससे NoSQL की लचीलापन के साथ SQL की सुरक्षा मिलती है। इससे ERD की आवश्यकता फिर से उभरती है, क्योंकि आपको उन नियमों को परिभाषित करना होगा जिन्हें आप लागू करना चाहते हैं।
- डेटा मेश: यह संरचनात्मक प्रवृत्ति डेटा स्वामित्व को विकेंद्रीकृत करती है। अलग-अलग टीमें अपने डेटा क्षेत्रों के स्वामी होती हैं। ERD वैश्विक नक्शों के बजाय क्षेत्र-विशिष्ट अनुबंध बन जाते हैं।
- आईएआई-सहायता वाला मॉडलिंग: कृत्रिम बुद्धिमत्ता टूल्स प्रश्न लॉग्स के आधार पर स्कीमा डिज़ाइन के सुझाव देना शुरू कर रहे हैं। इन टूल्स वास्तविक उपयोग पैटर्नों से ERD जैसे दृश्य प्राप्त कर सकते हैं।
- एकीकृत प्रश्न इंजन: नए इंजन विभिन्न डेटाबेस प्रकारों (SQL और NoSQL) के बीच एक साथ प्रश्न करने की अनुमति देते हैं। इसके लिए एक एकीकृत मेटाडेटा लेयर की आवश्यकता होती है, जो मूल रूप से एक वैश्विक ERD के रूप में कार्य करता है।
आधुनिक डेटा मॉडलिंग के लिए सर्वोत्तम प्रथाएं 📝
यदि आप आज किसी प्रणाली का डिज़ाइन कर रहे हैं, तो दस्तावेज़ीकरण के लिए आपको कैसे प्रक्रिया अपनानी चाहिए? यहाँ कार्यान्वयन योग्य दिशानिर्देश हैं।
1. डेटाबेस के बजाय क्षेत्र से शुरुआत करें
पहले व्यावसायिक एकाइयों को परिभाषित करें। एक ‘ग्राहक’ क्या है? एक ‘उत्पाद’ क्या है? यह यह निर्भर नहीं करता है कि आप उन्हें SQL या NoSQL में स्टोर करते हैं या नहीं। इन एकाइयों और उनके संबंधों को सार्वभौमिक रूप से परिभाषित करने के लिए ERD का उपयोग करें।
2. बाद में स्टोरेज के लिए मैप करें
जब डोमेन मॉडल स्पष्ट हो जाए, तो इसे स्टोरेज तकनीक के साथ मैप करें। तय करें कि कहाँ अनियमितता को दूर करना है। तय करें कि कहाँ सामान्यीकरण करना है। इस चिंता के विभाजन से डिज़ाइन लचीला रहता है।
3. सीमाओं को स्पष्ट रूप से दस्तावेज़ करें
यहां तक कि यदि डेटाबेस सीमाओं को लागू नहीं करता है, तो उन्हें दस्तावेज़ करें। स्पष्ट रूप से कहें: ‘उपयोगकर्ता ID अद्वितीय होना चाहिए’ या ‘आदेश तिथि भविष्य में नहीं हो सकती है’। इससे यह सुनिश्चित होता है कि एप्लिकेशन परत उस चीज़ को लागू करती है जो स्टोरेज परत अनुमति देती है।
4. अपने मॉडलों को संस्करण दें
अपने डेटा मॉडलों को कोड की तरह लें। उन्हें वर्जन नियंत्रण में रखें। जब आप किसी संबंध में बदलाव करें, तो बदलाव को कमिट करें। इससे यह दिखाई देता है कि प्रणाली कैसे विकसित हुई।
5. काम के लिए सही उपकरण का उपयोग करें
SQL ERD टूल को ग्राफ डेटाबेस के मॉडलिंग के लिए बाध्य न करें। उन उपकरणों का उपयोग करें जो आपके द्वारा उपयोग किए जा रहे विशिष्ट डेटा प्रकार का समर्थन करते हैं। दस्तावेज़ों के लिए, स्कीमा परिभाषा फ़ाइलों का उपयोग करें। ग्राफ के लिए, नोड-लिंक आरेखों का उपयोग करें।
दृष्टिकोणों की तुलना: एक साइड-बाय-साइड नज़र 🔍
लाभ-हानि को समझना आपके विशिष्ट प्रोजेक्ट के लिए सही निर्णय लेने में मदद करता है। नीचे दी गई तालिका दोनों दृष्टिकोणों की तुलना करती है।
| पहलू | पारंपरिक एरडी (संबंधित) | आधुनिक नो-एसक्यूएल मॉडलिंग |
|---|---|---|
| संरचना | निश्चित स्कीमा | लचीला / गतिशील स्कीमा |
| संबंध | विदेशी कुंजियाँ | एम्बेड करता है या संदर्भित करता है |
| डिज़ाइन फोकस | नॉर्मलाइज़ेशन | अनॉर्मलाइज़ेशन / पढ़ने के पैटर्न |
| बदलाव की लागत | उच्च (माइग्रेशन) | मध्यम (एप्लीकेशन तर्क) |
| दस्तावेज़ीकरण | चित्र अनिवार्य है | चित्र बहुत सिफारिश किया जाता है |
इस तुलना से यह उजागर होता है कि सिद्धांत मॉडलिंग का स्थिर रहता है, भले ही कार्यान्वयन भिन्न होता है। आपको अभी भी यह जानने की आवश्यकता है कि डेटा कैसे जुड़ता है। आपको अभी भी यह जानने की आवश्यकता है कि डेटा का क्या अर्थ है।
संदेहात्मक लोगों का समाधान 🗣️
कभी-कभी, डेवलपर्स कहते हैं कि चित्र विकास को धीमा कर देते हैं। वे पहले कोड लिखना पसंद करते हैं और बाद में डेटा को ठीक करते हैं। छोटे स्क्रिप्ट्स के लिए यह काम करता है, लेकिन एंटरप्राइज सिस्टम के लिए यह विफल हो जाता है।
रिफैक्टरिंग की लागत को ध्यान में रखें। एक संबंधित डेटाबेस में, कॉलम जोड़ने के लिए माइग्रेशन की आवश्यकता होती है। एक नो-एसक्यूएल सिस्टम में, एक दस्तावेज़ संरचना बदलने के लिए लाखों रिकॉर्ड में पूरी तरह से डेटा रीराइट करने की आवश्यकता हो सकती है। एक खराब मॉडल को ठीक करने की लागत हमेशा योजना बनाने की लागत से अधिक होती है। चित्र इन महंगे ठीक करने के जोखिम को कम करते हैं।
भविष्य पर अंतिम विचार 🌅
क्या नो-एसक्यूएल एरडी को समाप्त कर देगा, इस प्रश्न का उत्तर चित्र के उद्देश्य को देखकर मिलता है। यदि उद्देश्य तालिका कॉलम को परिभाषित करना है, तो नो-एसक्यूएल ने वास्तव में उस विशिष्ट प्रकार के चित्र की आवश्यकता को कम कर दिया है। हालांकि, यदि उद्देश्य डेटा संबंधों, अखंडता और प्रवाह को दृश्यमान बनाना है, तो चित्र की आवश्यकता अभी भी मजबूत रहती है।
तकनीक विकसित होती है, लेकिन डेटा की जटिलता कम नहीं होती है। जैसे-जैसे प्रणालियाँ अधिक वितरित होती हैं, स्पष्ट दस्तावेज़ीकरण की आवश्यकता बढ़ती है। एरडी मर नहीं रही है; वह बदल रही है। यह भौतिक भंडारण के बारे में कम और तार्किक क्षेत्र के बारे में अधिक हो रही है।
वे वास्तुकार जो नो-एसक्यूएल परिवेश में डेटा मॉडलिंग को नजरअंदाज करते हैं, उन्हें ऐसी प्रणालियाँ बनाने का जोखिम है जो बनाने में तेज हैं लेकिन बनाए रखने में असंभव हैं। भविष्य उन लोगों का है जो लचीलापन और संरचना के बीच संतुलन बनाते हैं। हम चित्र बनाते रहेंगे, लेकिन वे अलग दिखेंगे, अलग मापदंडों पर ध्यान केंद्रित करेंगे, और अलग स्टोरेज इंजन के अनुकूल होंगे।
चयन चित्रों और नो-एसक्यूएल के बीच नहीं है। चयन अनुशासित मॉडलिंग और अव्यवस्थित अनुकूलन के बीच है। अनंत डेटा की दुनिया में, संरचना ही अव्यवस्था को रोकने वाली एकमात्र चीज है। 🧱✨