











डेटाबेस प्रदर्शन अक्सर तब तक अदृश्य रहता है जब तक कि यह एक महत्वपूर्ण बफलेट नहीं बन जाता। जब उपयोगकर्ता लैग, टाइमआउट या अप्रतिक्रियाशील इंटरफेस का अनुभव करते हैं, तो मूल कारण अक्सर एप्लिकेशन लेयर की सतह के नीचे होता है। यह डेटा की संरचना में निहित होता है। डेटा के संरचना, संबंध और संग्रहण के नियम निर्धारित करने वाला ब्लूप्रिंट एंटिटी रिलेशनशिप डायग्राम (ERD) है। एक अच्छी तरह से बनाया गया ERD डेटा अखंडता और कुशल पुनर्प्राप्ति सुनिश्चित करता है। विपरीत रूप से, एक दोषपूर्ण डायग्राम लेटेंसी लाता है जिसे कोई भी एप्लिकेशन-स्तर के कैशिंग पूरी तरह से दूर नहीं कर सकता।
यह मार्गदर्शिका नीचे के स्कीमा डिज़ाइन के विश्लेषण द्वारा धीमी क्वेरीज़ के त्रुटि निवारण में गहराई से जाने की प्रदान करती है। हम अनुसंधान करेंगे कि ERD के भीतर संरचनात्मक निर्णय क्वेरी निष्पादन योजनाओं, I/O संचालन और समग्र प्रणाली की प्रतिक्रियाशीलता को कैसे प्रभावित करते हैं। संबंधात्मक डिज़ाइन के तकनीकी तत्वों को समझकर, आप प्रदर्शन समस्याओं के मूल कारण का निदान कर सकते हैं, बल्कि लक्षणों का उपचार करने के बजाय।
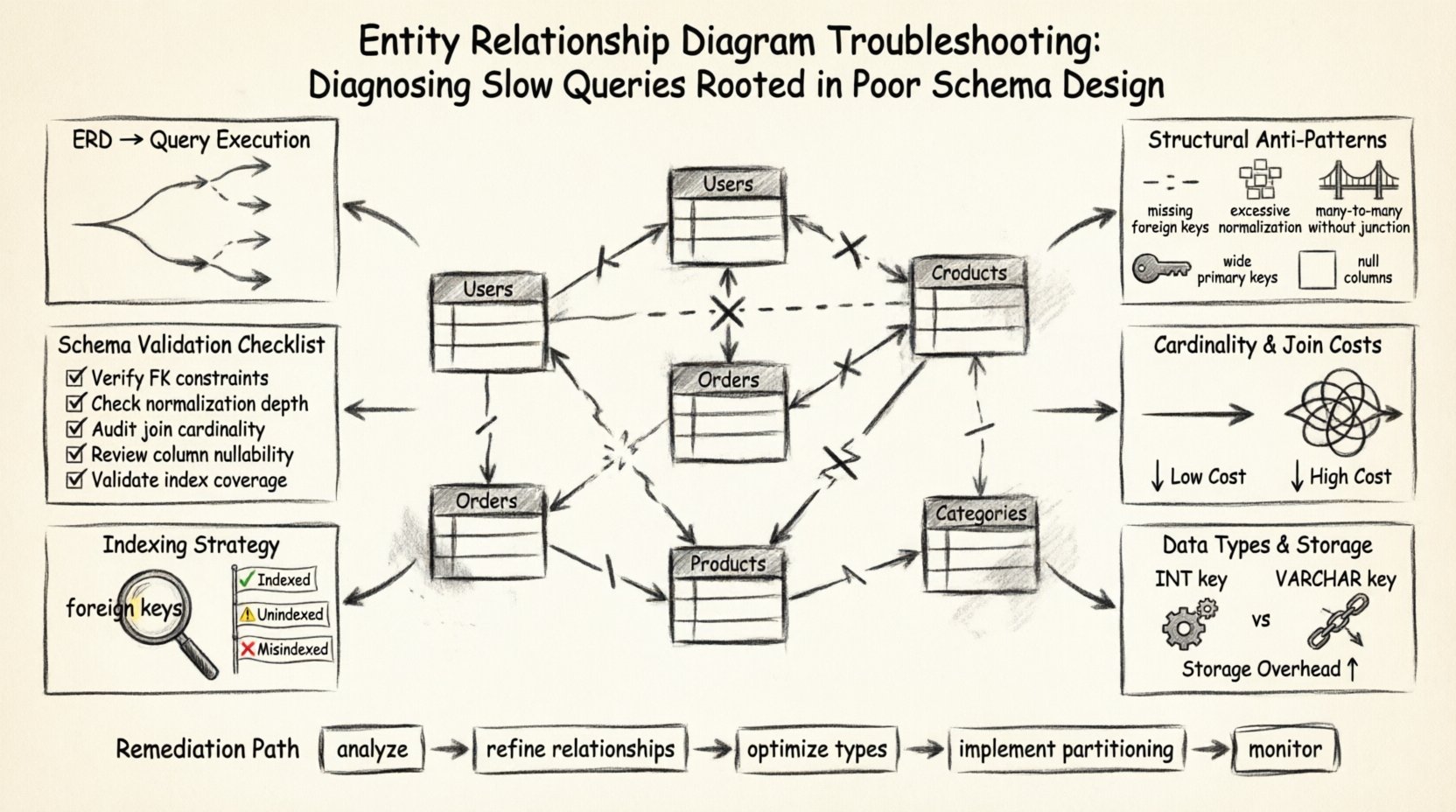
🏗️ मूल बातें: ERD कैसे क्वेरी निष्पादन को प्रभावित करते हैं
किसी समस्या का निदान करने से पहले, डेटा के दृश्य प्रतिनिधित्व और आदेशों के भौतिक निष्पादन के बीच संबंध को समझना आवश्यक है। ERD केवल दस्तावेज़ीकरण के लिए एक आरेख नहीं है; यह एक नियमों का समूह है जिसे डेटाबेस इंजन को लागू करना होता है। तालिकाओं के बीच खींची गई हर रेखा, प्रत्येक प्रतिबंध जो परिभाषित किया गया है, और प्रत्येक डेटा प्रकार जो निर्दिष्ट किया गया है, भंडारण इंजन द्वारा जानकारी को पढ़ने और लिखने के तरीके को निर्धारित करता है।
जब कोई क्वेरी प्रस्तुत की जाती है, तो डेटाबेस ऑप्टिमाइज़र अनुरोध का विश्लेषण स्कीमा मेटाडेटा के विरुद्ध करता है। यदि स्कीमा अस्पष्ट या अकुशल है, तो ऑप्टिमाइज़र एक उपयुक्त नहीं रास्ता चुन सकता है। इसका अक्सर परिणाम एक पूर्ण टेबल स्कैन के बजाय इंडेक्स सीक के रूप में दिखाई देता है, या एक नेस्टेड लूप जॉइन जो प्रोसेसिंग समय को घातीय रूप से बढ़ा देता है।
प्रदर्शन पर ERD के प्रभाव के मुख्य क्षेत्र निम्नलिखित हैं:
- जॉइन की जटिलता: परिभाषित संबंधों की संख्या रिलेटेड डेटा प्राप्त करने के लिए आवश्यक जॉइन्स की संख्या निर्धारित करती है।
- डेटा अखंडता प्रतिबंध: विदेशी कुंजियाँ और अद्वितीय प्रतिबंध लेखन संचालन पर अतिरिक्त भार डालते हैं, लेकिन पठन संचालन को अनुकूलित कर सकते हैं।
- नॉर्मलाइज़ेशन स्तर: डेटा के तालिकाओं के बीच विभाजन की डिग्री पुनर्प्राप्ति के दौरान स्कैन की गई डेटा मात्रा को प्रभावित करती है।
- इंडेक्सिंग रणनीति: स्कीमा डिज़ाइन निर्धारित करता है कि सामान्य क्वेरी पैटर्न के समर्थन के लिए इंडेक्स कहाँ तार्किक रूप से रखे जा सकते हैं।
🔍 संरचनात्मक एंटी-पैटर्न की पहचान करना
बहुत से प्रदर्शन समस्याएं उन पैटर्नों से उत्पन्न होती हैं जो प्रारंभिक डिज़ाइन चरण में स्वीकार्य थे, लेकिन डेटा के आकार बढ़ने के साथ लाभहीन हो जाते हैं। इन एंटी-पैटर्न को आरेख में अक्सर सूक्ष्म रूप से दिखाई देता है, लेकिन क्वेरी इंजन में महत्वपूर्ण बाधाएं उत्पन्न करते हैं। नीचे सामान्य संरचनात्मक दोषों और उनके गति पर सीधे प्रभाव का विश्लेषण दिया गया है।
| एंटी-पैटर्न | ERD में दृश्य संकेतक | प्रदर्शन प्रभाव |
|---|---|---|
| अनुपस्थित विदेशी कुंजियाँ | प्रतिबंध परिभाषाओं के बिना तालिकाओं को जोड़ने वाली रेखाएँ। | अनाथ रिकॉर्ड को अनुमति देता है, जिससे जटिल क्वेरीज़ को अमान्य डेटा को हाथ से फ़िल्टर करने के लिए मजबूर किया जाता है। |
| अत्यधिक नॉर्मलाइज़ेशन | एकल कॉलम संबंध वाली उच्च संख्या में तालिकाएँ। | एकल तार्किक एकता को पुनर्निर्माण करने के लिए अत्यधिक जॉइन्स की आवश्यकता होती है, जिससे CPU उपयोग बढ़ता है। |
| जंक्शन के बिना बहु-से-बहु संबंध | दो एंटिटी के बीच सीधे बहु-से-बहु संबंध रेखाएँ। | डेटाबेस इंजन आमतौर पर ब्रिज टेबल की आवश्यकता होती है; इसकी अनुपस्थिति अकुशल विकल्पों को जन्म देती है। |
| चौड़ी प्राथमिक कुंजियाँ | एक से अधिक बड़े कॉलम वाले कॉम्पोजिट कीज़। | इस की को संदर्भित करने वाले सभी इंडेक्स के आकार को बढ़ाता है, जिससे खोज धीमी हो जाती है। |
| नल-भरे कॉलम | वे विशेषताएँ जिन्हें तार्किक कारण के बिना नल-संभव चिह्नित किया गया है। | इंडेक्स के उपयोग को रोक सकता है या इंडेक्स की चयनक्षमता को कम कर सकता है, जिससे पूर्ण स्कैन होते हैं। |
🔗 संबंध गणना और जॉइन लागत
गणना यह निर्धारित करती है कि एक एकांकी के कितने उदाहरण दूसरे एकांकी के उदाहरणों से संबंधित हैं। यह प्रश्न प्रदर्शन के संदर्भ में ईआरडी का सबसे महत्वपूर्ण पहलू है। गलत गणना परिभाषाएँ प्रणाली को एक प्रश्न को संतुष्ट करने के लिए आवश्यक से अधिक पंक्तियों को प्रसंस्कृत करने के लिए मजबूर करती हैं।
धीमे प्रश्नों के निराकरण के दौरान, आपको यह सत्यापित करना होगा कि आरेख में संबंध एप्लिकेशन की तार्किक आवश्यकताओं के अनुरूप हैं। यदि एक संबंध को बहु-से-बहु के रूप में परिभाषित किया गया है जबकि इसे एक-से-बहु होना चाहिए, तो प्रश्न इंजन एक संयोजन तालिका के माध्यम से जॉइन करने के लिए तैयार होगा, जो मौजूद नहीं हो सकती है या अकुशलता से भरी हो सकती है।
आम गणना समस्याएँ
- अपरिभाषित गणना: यदि आरेख नहीं बताता है कि कोई संबंध अनिवार्य है या वैकल्पिक, तो प्रश्न ऑप्टिमाइज़र दुर्भाग्यपूर्ण परिदृश्य को मान सकता है, जिससे नल मानों के लिए अतिरिक्त जांच जोड़ी जाती है।
- पुनरावर्ती संबंध: स्व-संदर्भित तालिकाएँ (उदाहरण के लिए, एक कर्मचारी तालिका जो अपने आप को एक प्रबंधक के लिए संदर्भित करती है) प्रश्नों में गहन नेस्टिंग का कारण बन सकती हैं। अपने संदर्भित कॉलम पर उचित इंडेक्सिंग के बिना, इन प्रश्नों की गति घातीय रूप से धीमी हो जाती है।
- चक्रीय निर्भरताएँ: जटिल संबंधों के जाल जहाँ तालिका A को B से जोड़ा गया है, B को C से जोड़ा गया है, और C वापस A से जुड़ी है। इस संरचना के कारण इंजन के लिए डेटा ग्राफ का अनुसरण करना मुश्किल हो जाता है, जिसके परिणामस्वरूप अस्थायी तालिकाएँ मेमोरी में बनाई जाती हैं।
इन समस्याओं को कम करने के लिए, सुनिश्चित करें कि ईआरडी वैकल्पिक और अनिवार्य लिंक के बीच स्पष्ट अंतर बनाता है। अनिवार्य लिंक ऑप्टिमाइज़र को नल जांच को छोड़ने की अनुमति देते हैं, जिससे निष्पादन गति में सुधार होता है। वैकल्पिक लिंक के लिए संबंध न मौजूद होने के मामलों को संभालने के लिए अतिरिक्त तर्क की आवश्यकता होती है।
📏 डेटा प्रकार और स्टोरेज दक्षता
स्कीमा परिभाषा के भीतर डेटा प्रकारों का चयन स्टोरेज आकार और तुलना गति पर गहन प्रभाव डालता है। दो अलग-अलग प्रकार के कॉलम की तुलना करने वाला प्रश्न अक्सर अप्रत्यक्ष रूपांतरण को निष्पादित करता है। इन रूपांतरणों के कारण इंडेक्स के उपयोग को रोका जाता है और इंजन को हर पंक्ति को प्रसंस्कृत करने के लिए मजबूर किया जाता है।
स्टोरेज प्रभाव
जब स्कीमा सभी कॉलम के लिए एक सामान्य डेटा प्रकार का उपयोग करता है, जैसे कि छोटे कोड के लिए एक बड़ा टेक्स्ट फ़ील्ड, तो यह अधिक डिस्क स्पेस और मेमोरी का उपयोग करता है। इससे बफर पूल का प्रभावी आकार कम हो जाता है, जिसका अर्थ है कि मेमोरी में कम गर्म डेटा पेज रखे जा सकते हैं। परिणामस्वरूप, प्रणाली को धीमी डिस्क सबसिस्टम से अधिक डेटा पढ़ना होता है।
तुलना प्रदर्शन
पूर्णांक तुलना डेटा तुलना से काफी तेज होती है। यदि ईआरडी एक विदेशी की को डेटा प्रकार के रूप में डेटा (उदाहरण के लिए, VARCHAR) के बजाय पूर्णांक (उदाहरण के लिए, INT) के रूप में परिभाषित करती है, तो जॉइन ऑपरेशन को प्रत्येक अक्षर की तुलना करनी होगी, बजाय बाइनरी संख्यात्मक तुलना के। इससे प्रत्येक प्रसंस्कृत पंक्ति के लिए सीपीयू साइकिल्स जोड़े जाते हैं।
- स्थिर लंबाई वाले प्रकार का उपयोग करें: देश कोड या स्थिति फ्लैग जैसे क्षेत्रों के लिए, स्थिर लंबाई वाले डेटा प्रकार का उपयोग करें। चर लंबाई वाले डेटा प्रकार प्रत्येक पढ़ाई पर लंबाई की गणना के लिए अतिरिक्त ओवरहेड लाते हैं।
- कीज़ में बड़े टेक्स्ट से बचें: कभी भी एक टेक्स्ट-भारी कॉलम को प्राथमिक या विदेशी की के रूप में उपयोग न करें। इससे उसके संदर्भित सभी इंडेक्स बढ़ जाते हैं।
- माता-पिता और बच्चे के प्रकार को मैच करें: सुनिश्चित करें कि बच्चे की तालिका में डेटा प्रकार माता-पिता तालिका के बिल्कुल मेल खाता है। यहां तक कि थोड़ा सा अंतर (उदाहरण के लिए, INT बनाम BIGINT) भी जॉइन के दौरान रूपांतरण के लिए मजबूर कर सकता है।
🔑 इंडेक्सिंग दृश्यता और रणनीति
ईआरडी तार्किक संरचना का दृश्य प्रतिनिधित्व है, लेकिन इसे भौतिक इंडेक्सिंग रणनीति को भी प्रभावित करना चाहिए। जबकि इंडेक्स अक्सर स्कीमा बनाने के बाद जोड़े जाते हैं, डिज़ाइन चरण में यह अनुमान लगाना चाहिए कि इंडेक्स की आवश्यकता कहाँ होगी। एक प्रश्न जो एक इंडेक्स नहीं वाले कॉलम द्वारा फ़िल्टर करता है, डिज़ाइन की कमी का प्राथमिक संकेत है।
ERD में इंडेक्सिंग के अवसर
प्रदर्शन में बैंडविड्थ के लिए आरेख की समीक्षा करते समय, उन कॉलम को देखें जिनका अक्सर खोज की शर्तों या जॉइन में उपयोग किया जाता है।
- विदेशी कुंजियाँ: इन्हें लगभग हमेशा इंडेक्स किया जाना चाहिए। यदि कोई प्रश्न Table A को विदेशी कुंजी पर Table B से जोड़ता है, और Table B में कुंजी इंडेक्स नहीं है, तो इंजन को Table A की प्रत्येक पंक्ति के लिए पूरी Table B को स्कैन करना होगा।
- स्थिति झंडियाँ: वे कॉलम जो रिकॉर्ड की स्थिति को परिभाषित करते हैं (उदाहरण के लिए, Is_Active, Order_Status) अक्सर WHERE क्लॉज में उपयोग किए जाते हैं। यदि इन्हें इंडेक्स नहीं किया गया है, तो फ़िल्टरिंग पूरी टेबल स्कैन बन जाती है।
- तारीख सीमाएँ: ऑडिट ट्रेल या लेनदेन लॉग वाली टेबल अक्सर तारीख के आधार पर प्रश्न करती हैं। तारीख कॉलम को इंडेक्स करना चाहिए ताकि प्रभावी रेंज स्कैन किया जा सके।
लेखन प्रदर्शन के बीच इंडेक्स की संख्या को संतुलित करना महत्वपूर्ण है। प्रत्येक इंडेक्स INSERT, UPDATE और DELETE ऑपरेशन में अतिरिक्त ओवरहेड जोड़ता है। हालांकि, खराब इंडेक्स वाला रीड-हेवी स्कीमा सिस्टम लेटेंसी पैदा करेगा जो लेखन लागत को पार कर जाएगी। ERD यह देखने में मदद करता है कि कौन सी टेबलें रीड-हेवी (उदाहरण के लिए, लुकअप टेबल) हैं या लेखन-हेवी (उदाहरण के लिए, लेनदेन लॉग), जिससे इंडेक्सिंग निर्णय लिया जा सके।
🚫 जॉइन पैथोलॉजी
धीमे प्रश्नों के सबसे सामान्य स्रोतों में से एक जॉइन पथ है। इसका अर्थ है डेटाबेस इंजन द्वारा एक अनुरोध पूरा करने के लिए टेबलों को जोड़ने के क्रम को। खराब डिजाइन वाला स्कीमा इंजन को एक ऐसे पथ पर बाध्य कर सकता है जो तार्किक रूप से सही है लेकिन गणनात्मक रूप से महंगा है।
कार्टेशियन उत्पाद
यदि स्कीमा में उचित प्रतिबंध नहीं हैं या यदि प्रश्न तर्क सही तरीके से जॉइन शर्तों को निर्दिष्ट नहीं करता है, तो इंजन कार्टेशियन उत्पाद पैदा कर सकता है। यह तब होता है जब Table A की प्रत्येक पंक्ति को Table B की प्रत्येक पंक्ति के साथ जोड़ा जाता है। परिणाम सेट घातीय रूप से बढ़ता है, और प्रश्न समय सीमा से बाहर हो सकता है या सभी उपलब्ध मेमोरी का उपयोग कर सकता है।
ERD में, यह तब होता है जब एक बहुत-से-बहुत-से संबंध को एक जंक्शन टेबल द्वारा सही तरीके से मध्यस्थता नहीं की जाती है, या जंक्शन टेबल में आवश्यक विदेशी कुंजी प्रतिबंध नहीं होते हैं।
उप-प्रश्न बनाम जॉइन
स्कीमा डिजाइन यह प्रभावित करता है कि क्या एक प्रश्न को सरल जॉइन के रूप में निष्पादित किया जा सकता है या उप-प्रश्न की आवश्यकता होती है। उप-प्रश्न अक्सर बाहरी प्रश्न की प्रत्येक पंक्ति के लिए आंतरिक प्रश्न को एक बार निष्पादित करते हैं, जिससे द्विघात समय जटिलता उत्पन्न होती है। सीधे जॉइन की अनुमति देने वाला सामान्यीकृत स्कीमा उप-प्रश्न को बाध्य करने वाली असामान्य संरचनाओं की तुलना में आमतौर पर प्राथमिकता दी जाती है।
✅ स्कीमा सत्यापन चेकलिस्ट
ERD के आधार पर धीमे प्रश्नों को व्यवस्थित ढंग से दूर करने के लिए, एक संरचित समीक्षा करें। इस चेकलिस्ट सुनिश्चित करती है कि आप डिजाइन के प्रत्येक महत्वपूर्ण घटक की जांच करें।
1. विदेशी कुंजी प्रतिबंधों की समीक्षा करें
- क्या सभी विदेशी कुंजियाँ आरेख में स्पष्ट रूप से परिभाषित हैं?
- क्या इनमें ऐसे कैस्केडिंग नियम शामिल हैं जो अनचाहे डेटा गतिशीलता का कारण बन सकते हैं?
- क्या संबंध के दोनों ओर डेटा प्रकार समान हैं?
2. जॉइन आवृत्ति का विश्लेषण करें
- ऐसी टेबलों को पहचानें जिन्हें एप्लिकेशन तर्क में सबसे अधिक बार एक साथ जोड़ा जाता है।
- क्या ये टेबलें आरेख में पास-पड़ोस हैं, या क्या रास्ता बहुत बीच की टेबलों को पार करने की आवश्यकता है?
- क्या इनमें से किसी भी बीच की टेबल को संगठित करके जॉइन गहराई को कम किया जा सकता है?
3. नलता की जांच करें
- क्या वे कॉलम जो कभी नहीं खाली होते हैं, स्पष्ट रूप से NOT NULL के रूप में चिह्नित हैं?
- क्या स्कीमा इंडेक्स का हिस्सा बने कॉलम पर NULL की अनुमति देता है?
4. डेटा प्रकारों की पुष्टि करें
- क्या संख्यात्मक क्षेत्र सबसे छोटे उपयुक्त आकार का उपयोग कर रहे हैं (उदाहरण के लिए, TINYINT बनाम BIGINT)?
- क्या पाठ क्षेत्र सही लंबाई का उपयोग कर रहे हैं ताकि कटौती या अतिरिक्त भंडारण से बचा जा सके?
5. इंडेक्स कवरेज का आकलन करें
- क्या प्राथमिक कुंजियाँ और विदेशी कुंजियाँ में इंडेक्स हैं?
- क्या अक्सर फ़िल्टर किए जाने वाले कॉलम में इंडेक्स हैं?
- क्या सामान्य बहु-कॉलम प्रश्नों के लिए एक संयुक्त इंडेक्स है?
🛠️ सुधार के लिए व्यावहारिक चरण
जब ERD का विश्लेषण कर लिया जाता है और समस्याओं को पहचान लिया जाता है, तो अगला चरण सुधार होता है। इसमें डेटाबेस स्कीमा में परिवर्तन करना शामिल होता है ताकि प्रदर्शन की आवश्यकताओं के अनुरूप बनाया जा सके बिना डेटा अखंडता को नुकसान पहुँचाए बिना।
संबंधों को बेहतर बनाएँ:यदि ERD अत्यधिक जटिल संबंधों को दिखाता है, तो उन्हें सरल बनाने के बारे में सोचें। इसका मतलब हो सकता है कि विशिष्ट, पढ़ने वाले क्षेत्रों में डेनॉर्मलाइजेशन लागू करना जिससे जॉइन की आवश्यकता कम हो जाए। उदाहरण के लिए, मातृ तालिका में संबंधित आइटम की कैश की गई संख्या संग्रहीत करना जॉइन करने और हर बार गिनती करने की आवश्यकता को खत्म कर सकता है।
डेटा प्रकारों को अनुकूलित करें:डेटा प्रकारों को अधिक कुशल विकल्पों में बदलें। यदि तारीख केवल दिन के लिए संग्रहीत की जाती है, तो समय के साथ डेटाटाइम के बजाय केवल तारीख के प्रकार का उपयोग करें। यदि आईडी संख्यात्मक है, तो सुनिश्चित करें कि इसे एक स्ट्रिंग के रूप में संग्रहीत नहीं किया जाता है।
पार्टीशनिंग कार्यान्वित करें:बहुत बड़ी तालिकाओं के लिए, ERD में पार्टीशनिंग रणनीति को दर्शाना आवश्यक हो सकता है। हालांकि पार्टीशनिंग अक्सर एक भौतिक कार्यान्वयन विवरण होती है, लेकिन तार्किक डिजाइन में डेटा के समूहन के तरीके को ध्यान में रखना चाहिए। तारीख या क्षेत्र के आधार पर पार्टीशनिंग करने से इंजन को केवल संबंधित डेटा खंडों को स्कैन करने की अनुमति मिलती है।
🔎 अंतिम विचार
प्रदर्शन निराकरण एक आवर्ती प्रक्रिया है। ERD इस प्रक्रिया में मुख्य आर्टिफैक्ट के रूप में कार्य करता है। आरेख को एक जीवंत दस्तावेज के रूप में लेने से, जो तार्किक संरचना और भौतिक प्रदर्शन सीमाओं दोनों को दर्शाता है, आप एक डेटाबेस प्रणाली को बनाए रख सकते हैं जो डेटा बढ़ने के साथ भी प्रतिक्रियाशील रहती है।
याद रखें कि कोई भी एक डिजाइन सभी परिदृश्यों के लिए उपयुक्त नहीं होता है। उच्च आवृत्ति लेखन के लिए अनुकूलित स्कीमा का प्रदर्शन जटिल विश्लेषणात्मक प्रश्नों के लिए अनुकूलित स्कीमा से अलग हो सकता है। लक्ष्य आपके एप्लिकेशन के विशिष्ट एक्सेस पैटर्न के अनुरूप स्कीमा डिजाइन को अनुकूलित करना है। वास्तविक प्रश्न प्रदर्शन मापदंडों के बारे में नियमित रूप से ERD की समीक्षा करें ताकि विचलन को जल्दी पकड़ा जा सके।
डेटा मॉडल की संरचनात्मक अखंडता पर ध्यान केंद्रित करके, आप लेटेंसी के मूल कारणों को दूर करते हैं। यह दृष्टिकोण एप्लिकेशन लेयर पर पैच लगाने की तुलना में अधिक टिकाऊ है। एक मजबूत स्कीमा आधार यह सुनिश्चित करता है कि प्रणाली समय के साथ स्केल कर सके, अनुकूलित कर सके और विश्वसनीय रूप से काम कर सके।
परिवर्तन करने के बाद भी प्रश्न निष्पादन योजनाओं को निरीक्षण जारी रखें। निष्पादन योजना को दृश्याकृत करने से यह पुष्टि करने में मदद मिलती है कि ऑप्टिमाइज़र नए इंडेक्स और सीमाओं का सही तरीके से उपयोग कर रहा है। यह फीडबैक लूप त्रुटि निराकरण चक्र को पूरा करता है, जिससे यह सुनिश्चित होता है कि ERD में सैद्धांतिक सुधार लाइव परिवेश में भौतिक प्रदर्शन लाभ में बदल जाते हैं।