











Dalam evolusi arsitektur perangkat lunak, sedikit tantangan yang sekaligus terus-menerus seperti ketegangan antara pemodelan data historis dan persyaratan skalabilitas modern. Banyak organisasi menemukan diri mereka mengelola sistem backend yang dibangun berdasarkan Diagram Hubungan Entitas (ERD) yang dirancang bertahun-tahun lalu, seringkali berdasarkan asumsi yang berbeda mengenai beban kerja, konkurensi, dan perangkat keras. Ketika skema warisan menghadapi permintaan berkecepatan tinggi, penurunan kinerja bukan sekadar gangguan; itu adalah kegagalan struktural. Panduan ini mengeksplorasi realitas teknis dalam mengoptimalkan diagram-diagram ini tanpa meninggalkan logika bisnis yang tersemat di dalamnya.
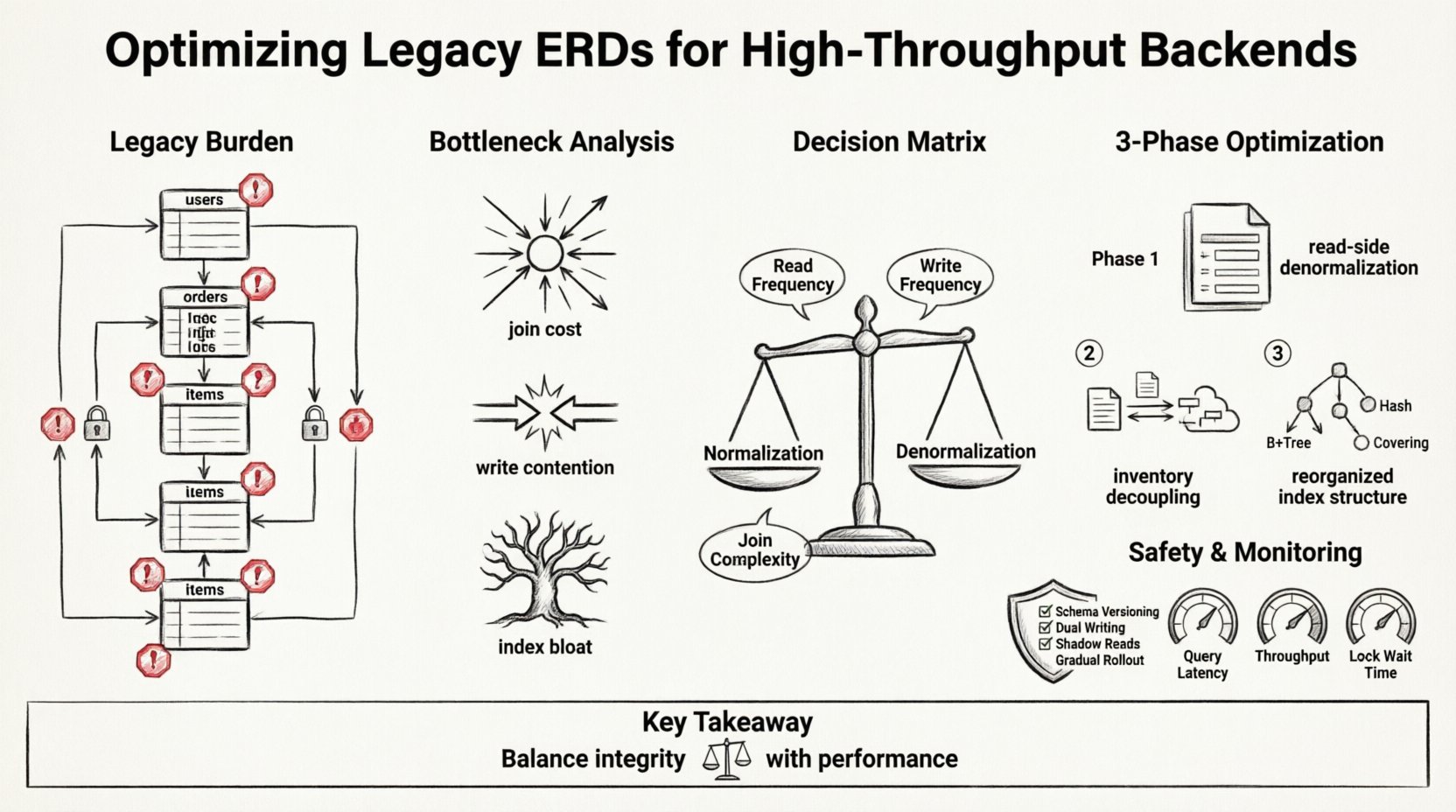
Memahami Beban Warisan 💾
ERD warisan sering mencerminkan kebutuhan masa lalu. Mereka mengutamakan integritas data dan normalisasi di atas segalanya. Dalam lingkungan node tunggal dengan lalu lintas sedang, pendekatan ini berjalan dengan baik. Ketaatan ketat terhadap Bentuk Normal Ketiga (3NF) meminimalkan redundansi dan menjamin konsistensi. Namun, ketika sistem berkembang hingga mencapai jutaan transaksi per detik, biaya dari hubungan-hubungan ini menjadi tidak terjangkau.
Pertimbangkan ciri-ciri umum berikut yang ditemukan dalam skema lama:
- Rantai Join yang Dalam:Kueri yang membutuhkan lima atau lebih join untuk mengambil satu catatan.
- Kendala Kunci Asing yang Berat:Pemeriksaan integritas yang kaku yang menghambat penulisan bersamaan.
- Penyimpanan Kunci Terpusat:Titik panas pada tabel-tabel tertentu yang menjadi hambatan saat beban puncak.
- Kesenjangan Denormalisasi:Kurangnya penyimpanan data yang berulang untuk operasi baca yang intensif.
Pola-pola ini tidak secara inheren “salah.” Mereka benar pada zamannya. Tantangannya terletak pada penyesuaian mereka terhadap lingkungan terdistribusi dan konkurensi tinggi di mana latensi adalah mata uang utama.
Menganalisis Kemacetan 🔍
Sebelum mengubah diagram, seseorang harus memahami di mana sistem mengalami penurunan kinerja. Backend berkecepatan tinggi sering dibatasi oleh operasi I/O, latensi jaringan antar layanan, dan persaingan kunci. ERD menentukan bagaimana data diakses, yang secara langsung memengaruhi metrik-metrik ini.
1. Biaya Join
Setiap join adalah bacaan disk dan siklus CPU. Dalam sistem warisan, permintaan profil pengguna tunggal bisa memicu deretan pencarian lintas lima tabel. Seiring meningkatnya lalu lintas, basis data menghabiskan lebih banyak waktu untuk menavigasi hubungan daripada mengeksekusi logika. Hal ini terutama benar ketika indeks tidak dapat mencakup seluruh jalur join.
2. Persaingan Penulisan
Normalisasi mengharuskan menulis data ke beberapa lokasi untuk menjaga integritas. Jika sebuah transaksi memperbarui profil pengguna dan mencatat kejadian aktivitas, dua tabel harus dimodifikasi. Jika kedua tabel berada di shard yang sama, durasi kunci akan meningkat. Jika tersebar, transaksi menjadi komitmen dua tahap, menambahkan beban yang signifikan.
3. Pembesaran Indeks
Untuk mendukung join yang kompleks, sistem warisan menumpuk indeks. Seiring waktu, indeks-indeks ini memperlambat operasi penulisan. Basis data harus memperbarui setiap indeks pada setiap operasi insert atau update. Dalam skenario berkecepatan tinggi, amplifikasi penulisan ini dapat memenuhi sub-sistem penyimpanan.
Strategi Refaktor: Normalisasi vs. Denormalisasi ⚖️
Inti dari optimasi terletak pada merefleksikan kembali pertukaran antara integritas data dan kecepatan kueri. Meskipun normalisasi ketat menjamin konsistensi, sistem berkinerja tinggi seringkali membutuhkan denormalisasi yang pragmatis. Ini tidak berarti meninggalkan struktur; artinya menerima redundansi untuk mengurangi latensi.
Tabel berikut menguraikan matriks keputusan untuk perubahan skema:
| Kriteria | Tetap Normal | Terapkan Denormalisasi |
|---|---|---|
| Frekuensi Baca | Rendah (Pemrosesan Batch) | Tinggi (Dashboard real-time) |
| Frekuensi Tulis | Tinggi (Transaksi inti) | Rendah (Catatan audit) |
| Persyaratan Konsistensi | ACID Kuat | Konsistensi akhir dapat diterima |
| Kompleksitas Join | Sederhana (1-2 join) | Kompleks (3+ join) |
| Volatilitas Data | Statis (Data referensi) | Dinamis (Status pengguna) |
Menerapkan strategi ini membutuhkan perencanaan yang cermat. Anda tidak hanya mengubah tabel; Anda mengubah cara aplikasi memahami data.
Langkah demi Langkah Studi Kasus: Mesin Transaksi E-Commerce 🛒
Untuk mengilustrasikan proses ini, pertimbangkan platform e-commerce fiksi. Sistem warisan menangani pemrosesan pesanan, manajemen persediaan, dan profil pelanggan. ERD dirancang untuk satu instance basis data dengan fokus pada pencegahan penjualan berlebihan stok.
Kondisi Warisan
Dalam desain awal, tabel orders merujuk pada order_items, yang merujuk pada products. Tabel products merujuk pada inventory. Untuk menampilkan halaman detail pesanan, backend menjalankan query yang menggabungkan keempat tabel. Selain itu, setiap pembaruan pesanan memerlukan kunci pada tabel persediaan untuk memastikan akurasi.
Masalah Kunci yang Ditemukan:
- Latensi: Waktu muat halaman melonjak hingga 800ms selama acara penjualan.
- Kebuntuan:Kemacetan tinggi pada pembaruan inventaris menyebabkan pembatalan transaksi.
- Skalabilitas:Database tidak dapat membagi bagian dari
inventaristabel karena seringnya penggabungan lintas bagian.
Proses Optimalisasi
Tim memutuskan untuk merefaktor ERD dalam tiga tahap. Tujuannya adalah memisahkan jalur baca dari jalur tulis.
Tahap 1: Denormalisasi Sisi Baca
Langkah pertama melibatkan pembuatan salinan data produk dalam catatan pesanan. Alih-alih bergabung dengan tabel produktabel saat query, sistem menyalin nama produk, harga, dan SKU ke dalam tabel order_itemstabel pada saat pembelian.
- Manfaat:Riwayat pesanan tetap akurat meskipun data produk berubah nanti.
- Manfaat:Query tidak lagi memerlukan penggabungan ke tabel produk.
- Risiko:Ketidaksesuaian harga jika produk diperbarui setelah pesanan ditempatkan.
- Penanggulangan:Antarmuka pengguna menampilkan harga pada saat pembelian sebagai “Harga Historis”.
Tahap 2: Pemisahan Inventaris
Tabel inventaris adalah sumber perselisihan. Tim memindahkan pelacakan inventaris ke penyimpanan tulis terpisah dengan frekuensi tinggi. Sistem pesanan mengirim pesan asinkron untuk menahan stok alih-alih menjalankan kunci SQL sinkron.
- Manfaat:Throughput tulis meningkat 400%.
- Manfaat:Tidak ada lagi pemblokiran pada transaksi pesanan utama.
- Kompromi: Pesanan dapat ditempatkan bahkan jika persediaan sedang tidak sinkron secara sementara.
- Penanggulangan:Proses latar belakang menyelaraskan ketidaksesuaian antara sistem pesanan dan persediaan.
Fase 3: Pengulangan Struktur Indeks
Dengan data yang tidak dinormalisasi, indeks lama pada kunci asing menjadi tidak perlu. Tim menghapusnya dan menambahkan indeks komposit yang dioptimalkan untuk pola kueri baru. Sebagai contoh, indeks pada (customer_id, created_at) menggantikan kebutuhan untuk memindai seluruh tabel pesanan.
Fase Implementasi dan Keamanan 🛡️
Mengubah skema yang sedang berjalan merupakan operasi berisiko tinggi. Fase-fase berikut menjamin stabilitas selama transisi.
1. Versi Skema
Jangan langsung menghapus kolom lama. Biarkan kolom tersebut tetap ada tetapi tandai sebagai usang. Ini memungkinkan aplikasi melakukan rollback jika logika baru gagal. Gunakan skrip migrasi yang menambahkan kolom sebelum menghapusnya.
2. Penulisan Ganda
Selama transisi, tulis data ke struktur lama dan struktur baru. Logika aplikasi mengarahkan pembacaan ke struktur baru, tetapi penulisan dilakukan ke keduanya. Ini memberikan cadangan jika skema baru belum lengkap.
3. Bacaan Bayangan
Sebelum mengalihkan lalu lintas langsung, jalankan kueri baru pada salinan data produksi. Bandingkan hasil kueri lama terhadap kueri yang dioptimalkan untuk memastikan akurasi data.
4. Peluncuran Bertahap
Gunakan fitur flag untuk mengaktifkan skema baru bagi sebagian kecil pengguna (misalnya, 1%). Pantau tingkat kesalahan dan latensi. Jika metrik tetap stabil, tingkatkan persentase secara bertahap.
Pemantauan dan Validasi 📊
Optimisasi bukanlah kejadian satu kali. Diperlukan pemantauan terus-menerus untuk memastikan perubahan tetap stabil di bawah beban. Indikator kinerja utama (KPI) harus ditetapkan sebelum memulai refactoring.
Metrik Inti yang Harus Dipantau:
- Latensi Kueri: Waktu respons persentil ke-95 dan ke-99.
- Throughput: Transaksi per detik (TPS) tanpa kesalahan.
- Waktu Tunggu Kunci: Waktu rata-rata transaksi menunggu kunci.
- Keterlambatan Replikasi: Keterlambatan antara node utama dan node replika (jika berlaku).
- Rasio Kenaikan Cache: Efektivitas strategi caching bacaan.
Ambang pemicu peringatan harus ditetapkan berdasarkan metrik dasar yang dikumpulkan sebelum perubahan. Jika terjadi lonjakan latensi, sistem harus secara otomatis kembali ke skema lama atau mengarahkan lalu lintas ke layanan cadangan.
Kesalahan Umum yang Harus Dihindari ⚠️
Bahkan dengan rencana yang kuat, utang teknis sering muncul kembali dengan cara yang tak terduga. Waspadai kesalahan-kesalahan umum ini.
- Mengabaikan Biaya Migrasi Data:Memindahkan terabita data ke struktur baru membutuhkan waktu. Rencanakan jendela pemeliharaan atau alat migrasi latar belakang.
- Terlalu Mengoptimalkan Bacaan: Jika Anda melakukan denormalisasi terlalu jauh, kinerja tulis akan menurun. Seimbangkan rasio baca/tulis pada beban kerja spesifik Anda.
- Melupakan Logika Aplikasi: Perubahan skema hanyalah separuh pertarungan. Kode aplikasi harus diperbarui untuk menangani struktur data baru.
- Mengabaikan Pengujian: Uji unit sering hanya mencakup jalur sukses. Uji beban berat diperlukan untuk menemukan kondisi persaingan dalam skema baru.
Strategi Pemeliharaan Jangka Panjang 🔧
Setelah optimasi selesai, tim harus memelihara arsitektur baru. Dokumentasi sangat penting. Setiap tabel, kolom, dan hubungan harus ditandai dengan tujuan dan kepemilikan.
Audit Rutin:
Atur tinjauan kuartalan terhadap ERD. Identifikasi tabel yang tumbuh secara tidak seimbang atau query yang menjadi lebih lambat. Pertumbuhan basis data sering mengungkapkan bottleneck baru yang tidak ada saat refactoring awal.
Pemeriksaan Skema Otomatis:
Integrasikan validasi skema ke dalam pipeline CI/CD. Cegah pengembang menambahkan join baru atau menghapus keterbatasan kritis tanpa persetujuan. Ini memastikan sistem tetap dioptimalkan seiring waktu.
Pelatihan Tim:
Pastikan semua insinyur backend memahami model data baru. Pemahaman bersama terhadap skema mengurangi kemungkinan munculnya utang teknis baru melalui query sementara.
Pikiran Akhir tentang Pemodelan Data 🔗
Mengoptimalkan Diagram Hubungan Entitas warisan adalah pertimbangan seimbang antara akurasi historis dan skalabilitas masa depan. Tidak ada satu skema “benar” yang tunggal. Model yang tepat adalah yang mendukung tujuan bisnis Anda saat ini sekaligus memberi ruang bagi pertumbuhan.
Dengan fokus pada bottleneck spesifik sistem Anda—baik itu biaya join, persaingan kunci, atau pembengkakan indeks—Anda dapat melakukan perbaikan yang terarah. Studi kasus ini menunjukkan bahwa bahkan struktur yang sangat melekat pun dapat dimodernisasi tanpa harus menulis ulang secara keseluruhan. Kuncinya adalah bergerak secara metodis, memvalidasi secara ketat, dan mempertahankan pandangan jelas terhadap pertukaran yang terlibat.
Pemodelan data tidak statis. Ia berkembang seiring lalu lintas yang dilayani. Anggap ERD Anda sebagai dokumen hidup yang membutuhkan perawatan dan perhatian yang sama seperti kode yang mengaksesnya. Dengan pendekatan yang tepat, Anda dapat mengubah sistem warisan menjadi mesin berkinerja tinggi yang mampu menangani tuntutan web modern.