











数据库模式是动态的产物。它们随着所支持的业务逻辑一同演进。随着时间推移,随着需求变化和新功能的引入,底层数据结构往往变得复杂。这种复杂性在视觉上表现为一个过度膨胀的实体关系图(ERD)。膨胀的ERD可能导致性能下降、维护困难,并增加数据完整性问题的风险。
重构这些图表不仅仅是外观上的美化。它是一种需要精准操作的结构性干预。主要目标是在转换过程中确保数据绝对不丢失或损坏的同时,简化模式结构、提升可读性,并优化查询性能。本指南提供了一种系统化的方法来管理这一过程。
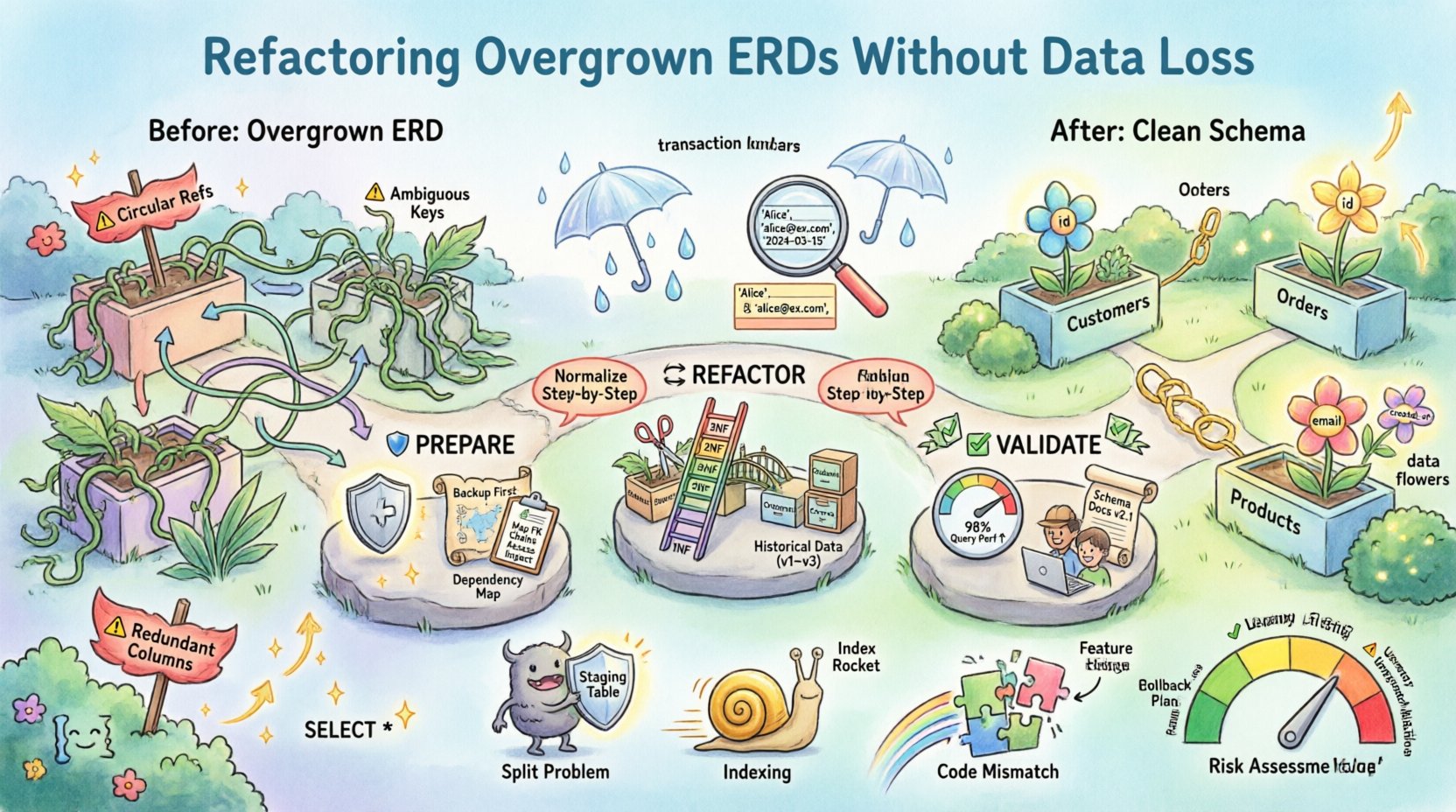
📉 为什么ERD会变得难以管理
理解模式膨胀的根本原因,是解决问题的第一步。一个在缺乏治理的情况下自然生长的ERD通常会表现出特定症状。识别这些模式,有助于进行有针对性的干预。
- 冗余列:相同的数据点被存储在多个表中。这会导致同步难题,即更新一个实例时,另一个实例不会随之更新。
- 过度反规范化:虽然反规范化能提升读取速度,但过度使用会使写入操作复杂化,并增加存储开销。
- 弱关系:多对多关系通常使用包含多个外键的单个表来实现,而不是使用正确的关联表。
- 隐式业务逻辑:数据类型和约束可能依赖于应用层的检查,而非数据库层的强制执行,这使得模式变得脆弱。
- 孤立的实体:存在一些表不再被任何活跃的应用模块引用,但仍保留在物理存储中。
当这些因素累积时,ERD就会变成一团乱麻。可视化关系变得困难,任何修改过程中引入错误的风险也会呈指数级增长。
🛡️ 为模式变更做准备
在修改任何一条DDL(数据定义语言)之前,必须进行严格的准备阶段。该阶段可最大限度降低风险,并确保在出现问题时能够回滚。
1. 全面的备份策略
数据安全至关重要。备份不仅仅是文件;它是一个验证点。
- 逻辑备份:以人类可读的格式(如SQL转储)导出模式定义和数据。
- 物理快照:如果平台支持,创建存储卷在某一时间点的快照。
- 只读副本:如果可能,启动生产环境的副本。首先在此处执行所有测试和迁移脚本。
2. 依赖关系映射
表并非孤立存在。每个实体都会被应用代码、存储过程或外部报告工具引用。你必须识别出数据的每一个使用者。
- 审查应用代码中对表的直接引用。
- 检查是否存在依赖于特定列的视图或物化视图。
- 识别任何计划任务或ETL(提取、转换、加载)流程,这些流程从受影响的表中导入或导出数据。
3. 影响分析
记录当前状态。建立行数、数据分布和查询执行时间的基线。该基线使您能够在重构前后对比系统状态,以确保一致性。
| 检查清单项目 | 优先级 | 备注 |
|---|---|---|
| 验证备份完整性 | 高 | 确保校验和与源数据匹配 |
| 映射所有外键 | 高 | 记录父-子关系 |
| 识别活跃查询 | 中 | 使用查询日志查找高负载查询 |
| 审查访问控制 | 中 | 确保权限在迁移后仍然有效 |
🔄 重构方法论
重构的核心在于重构逻辑模型。这通常通过规范化实现,尽管为了性能可能保留有策略的反规范化。目标是实现清晰性和完整性。
1. 分析当前规范化程度
大多数遗留模式未达到第三范式(3NF)。向更高规范化程度迈进可减少冗余。
- 第一范式(1NF):确保原子性。单个单元格内不得存在重复组或多值属性。
- 第二范式(2NF):消除部分依赖。确保每个非键属性都完全依赖于主键。
- 第三范式(3NF):消除传递依赖。非键属性应仅依赖于主键,而不依赖于其他非键属性。
| 规范化级别 | 关键规则 | 优点 |
|---|---|---|
| 第一范式 | 仅原子值 | 消除复杂的解析逻辑 |
| 第二范式 | 完全依赖于主键 | 减少更新异常 |
| 第三范式 | 无传递依赖 | 提高数据一致性 |
2. 分解大型实体
当一个表包含过多列时,通常意味着不同的业务概念被混淆了。应将它们拆分为独立的表。
- 识别描述不同实体的列组(例如,用户资料与用户偏好)。
- 为该独立概念创建一个新表。
- 将相关列移动到新表中。
- 使用外键建立一对一关系。
3. 解决多对多关系
使用每张表中的一列直接连接两张表是一种常见的反模式。这应由一个关联表来替代。
- 创建一个新表作为桥梁。
- 将两个父表的主键作为外键包含在关联表中。
- 添加属于关系本身的任何特定属性(例如,关系建立的日期)。
4. 处理历史数据
重构通常会改变数据的存储方式。历史记录必须被准确保留。
- 不要简单地删除旧数据。它可能用于审计追踪或法律合规。
- 在切换应用程序连接之前,使用迁移脚本将现有数据转换为新格式。
- 如果旧表不再需要但必须保留以备记录,应将其归档。
✅ 确保数据完整性
在转换过程中,数据损坏的风险最高。完整性约束是你的安全网。
1. 外键约束
在数据库级别强制实施参照完整性。这可以防止孤儿记录,即子记录引用已不存在的父记录。
- 启用
级联仅在逻辑上必要时才更新或删除。 - 使用
限制或无操作以阻止会破坏关系的更改。
2. 事务管理
将所有迁移步骤包装在事务中。这确保了所有更改都会被应用,或者一个都不应用。部分更新会导致状态不一致。
- 在第一个 DDL 命令之前启动事务。
- 只有在所有验证检查通过后才提交。
- 如果发生错误,立即回滚。
3. 数据验证脚本
迁移完成后,运行脚本以验证数据。
- 比较旧表和新表之间的行数。
- 在关键列上计算校验和,以确保完全匹配。
- 检查之前不可为空的列中是否存在空值。
- 验证所有唯一性约束是否都已满足。
⚠️ 常见陷阱与解决方案
即使计划周密,问题仍可能发生。提前预见这些问题可以减少停机时间。
1. “拆分”问题
拆分表时,可能会遇到重复键。如果拆分的是复合键,请确保新键在新结构中仍保持唯一性。
- 解决方案: 使用临时暂存表在应用新架构之前重新组织数据。
2. 索引性能
新关系需要新的索引。如果没有索引,对新关联表的查询将变得缓慢。
- 解决方案: 在创建后立即在外键列上创建索引。不要仅依赖主键索引。
3. 应用程序代码不匹配
数据库发生了变化,但应用程序代码并未立即更新。这会导致运行时错误。
- 解决方案: 在过渡期间实施功能标志或双写策略。允许旧的和新的数据结构短暂共存。
4. 数据类型不匹配
重构通常涉及更改数据类型(例如,VARCHAR 转为 INT)。如果要转换的字段中包含非数字字符,迁移将失败。
- 解决方案: 在迁移前的步骤中清理数据。创建无效数据的报告以供人工审查。
🚀 重构后验证
迁移脚本完成后,工作并未结束。系统必须在类似生产环境的环境中进行验证。
- 性能基准测试: 运行基线检查中使用的相同查询集。比较执行时间和资源使用情况。
- 用户验收测试: 让应用程序用户执行标准工作流程,以确保数据在用户界面中正确显示。
- 监控设置: 为涉及的特定表启用增强的日志记录和监控。关注错误激增或延迟增加的情况。
- 文档更新: 更新实体关系图、数据字典和API文档,以反映新的结构。
📝 风险评估矩阵
| 风险因素 | 影响 | 缓解策略 |
|---|---|---|
| 意外数据丢失 | 严重 | 开始前验证备份;使用事务 |
| 停机时间 | 高 | 安排在维护窗口期间;使用蓝绿部署 |
| 性能下降 | 中等 | 使用生产规模的数据进行测试;优化索引 |
| 应用程序中断 | 高 | 功能标志;逐步推出 |
重构实体关系图是一项有纪律的工程任务。它需要在理论数据建模原则与实际操作约束之间取得平衡。通过遵循结构化的方法,保持严格的数据完整性检查,并为过渡做好充分准备,您可以在不损害信息资产可靠性的情况下,现代化您的数据架构。
现代系统的复杂性要求我们必须保持警惕。定期审查ERD应成为开发周期的一部分,以防止过度膨胀再次成为关键问题。应将模式视为应用程序基础设施的关键组成部分,值得像对待代码本身一样给予同等的关注和维护。
这项努力是否成功,取决于迁移后系统的稳定性以及其所持数据的持续准确性。只要保持耐心与精准,实现更清洁、更高效的数据库结构是完全可行的。