











数据建模通常是任何软件应用中看不见的支柱。尽管运行业务逻辑的代码备受关注,但其底层的模式决定了性能、可扩展性和可维护性。对许多初级工程师而言,实体关系图(ERD)只是画方框和连线的简单练习。然而,这种简单性具有欺骗性。一个构建不当的ERD会带来不断累积的技术债务,导致查询复杂、数据完整性问题以及困难的迁移。
本指南探讨了隐藏的复杂性鸿沟。它指出了理论知识与实际应用之间脱节的根源。通过理解这些陷阱,开发者能够超越基础的绘图,迈向真正的架构思维。
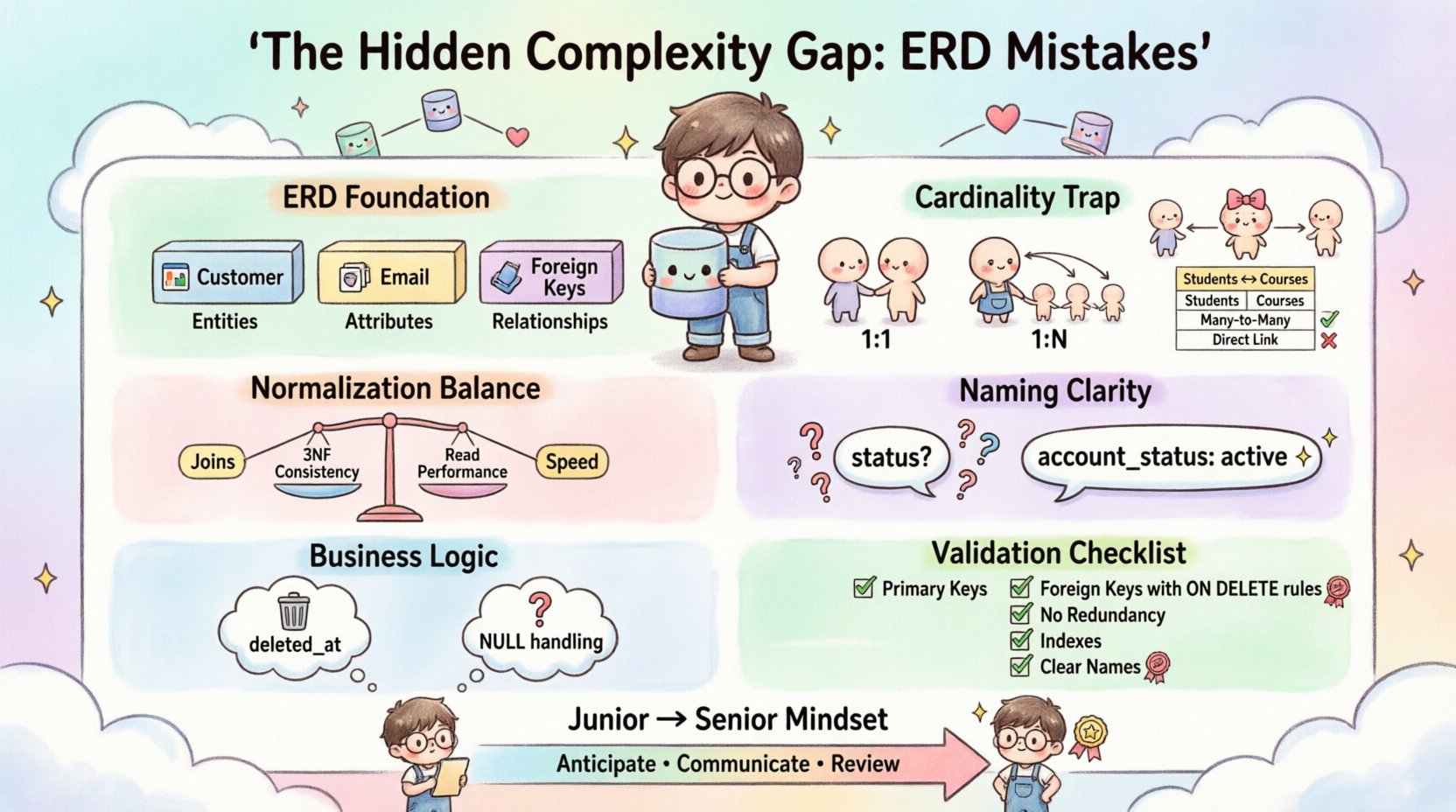
1. 理解数据建模的基础 🏗️
在深入探讨错误之前,必须明确ERD实际上代表什么。它不仅仅是一张图,而是应用与存储层之间的契约。ERD展示了实体(表)、属性(列)和关系(外键)。
当工程师将ERD视为一次创建后便被遗忘的静态产物时,他们就忽略了数据的动态本质。随着业务需求的变化,数据模型也会随之演进。初级工程师可能只关注当前功能,比如存储用户姓名,而忽略了该用户与其他实体(如订单、订阅或日志)之间的交互。
- 实体: 它们代表现实世界中的对象或概念(例如:客户、产品、发票)。
- 属性: 它们是定义实体的属性(例如:邮箱、价格、日期)。
- 关系: 它们定义了实体之间的交互方式(例如:一对多、多对多)。
一个健壮的模型应考虑到未来的增长。它应预见到‘客户’可能演变为‘用户’,或‘产品’可能需要多种变体。初始的图表应具备足够的灵活性,以适应这些变化,而无需完全重建。
2. 基数陷阱:误解关系 🔄
基数是数据库设计中结构失败最常见的原因。它定义了实体实例之间的数值关系。误解这一点会导致存储效率低下和复杂的连接逻辑。
常见的基数场景
工程师常常默认采用最显而易见的关系,而未考虑边缘情况。请考虑以下因假设错误而导致问题的场景:
- 一对一(1:1): 常被过度使用。如果两个实体存在一对一关系,通常应合并为单个表以减少连接开销,除非需要严格的权限隔离。
- 一对多(1:N): 最常见的关系。一个父记录关联多个子记录。外键必须位于子表中。
- 多对多(M:N): 这正是复杂性鸿沟扩大的地方。在关系模型中,没有中间表,直接的多对多关系在物理上是不可能实现的。
表格:基数实现错误
| 场景 | 错误方法 | 正确方法 |
|---|---|---|
| 学生与课程 | 在“学生”表中添加一个“CourseID”列 | 创建一个“Student_Course”关联表 |
| 订单和产品 | 将产品详情直接嵌入订单表中 | 通过订单项表进行关联 |
| 员工和部门 | 允许员工属于多个部门,而无需关联表 | 分离映射关系 |
当工程师试图通过重复数据将多对多关系强制放入单个表中时,会引入冗余。如果产品价格发生变化,必须在包含该产品的每个订单记录中进行更新。这违反了规范化原则,并带来维护上的噩梦。
3. 规范化误区与现实检验 📉
规范化是学术环境中教授的标准概念。其目标是减少数据冗余并提高完整性。然而,初级工程师常常过度规范化(达到5NF),而未考虑性能上的权衡。
过度规范化的陷阱
过度规范化的模式将数据拆分到过多的表中。虽然这能确保一致性,但迫使应用程序执行过多的连接操作。每次连接都会增加计算成本。在高流量系统中,这可能成为瓶颈。
- 1NF(第一范式):原子值。单个单元格中不能包含列表。
- 2NF(第二范式):无部分依赖。所有非键属性必须依赖于整个主键。
- 3NF(第三范式):无传递依赖。属性不应依赖于其他非键属性。
一个常见错误是认为3NF总是目标。在某些情况下,去规范化是一种有意的设计选择。例如,将“订单总金额”直接存储在订单表中,可以避免每次显示订单时都重新计算项目总和。这以写入性能为代价换取读取性能。
表格:规范化 vs. 去规范化
| 因素 | 规范化(3NF) | 去规范化 |
|---|---|---|
| 数据冗余 | 低 | 高 |
| 写入速度 | 快 | 较慢 |
| 读取速度 | 较慢(连接更多) | 快速 |
| 数据完整性 | 高 | 较低(需要逻辑) |
是否反规范化必须以数据为导向。这不应随意发生。工程师在合并表之前需要分析查询性能。在没有上下文的情况下盲目遵循规范化规则,会导致系统虽然一致但运行缓慢。
4. 命名规范与语义清晰性 🏷️
模式名称是数据库的词汇。如果词汇模糊,系统对未来的开发者来说就会变得难以理解。这是一个常见问题,即为了简洁而牺牲了技术精确性。
一个名为状态是危险的。它是什么意思?是活跃账户吗?待处理的付款吗?已删除的记录吗?没有上下文,其含义就丢失了。同样,使用复数名称表示表(例如,用户)与单数(例如,用户)会造成不一致。
- 一致性: 如果一个表使用了
蛇形命名法,那么所有表都必须使用蛇形命名法. - 描述性: 使用能描述数据的名称,而不仅仅是格式。避免使用像
表1或数据. - 上下文: 如果存在歧义,应在关系键中包含实体名称。使用
用户ID而不是仅仅使用id在可能的情况下。
考虑一个拥有多种用户类型的系统:管理员、客户和供应商。一个名为Users的表中可能包含一个role列。这是一个“上帝表”。更好的做法是使用独立的表或明确的继承策略。当不同角色的权限和数据访问规则存在显著差异时,这种区别就变得至关重要。
5. 在技术设计中忽略业务逻辑 🧠
初级工程师和高级工程师之间最大的差距在于对业务逻辑的理解。初级工程师可能构建一个完全符合当前代码需求的数据库模式,但当业务规则发生变化时,它就会失效。
“软删除”的误解
许多开发者只是简单地向表中添加一个deleted_at列。这在简单情况下是可行的。然而,如果一个用户被删除,其关联的日志是否也应该被删除?其财务记录是否应保留以满足审计合规要求?ERD 应通过约束和触发器来体现这些限制,而不仅仅是依赖应用程序代码。
“Null”问题
允许 NULL 值通常会带来隐藏的复杂性。在某些情况下,NULL 在语义上与空字符串或零不同。如果一个字段是可选的,ERD 应明确表示这一点。然而,不建议将 NULL 用于逻辑控制。
- 参照完整性:外键理想情况下不应为 NULL,除非该关系确实是可选的。
- 计算:NULL 值会传播到计算中,导致结果为 NULL。这可能会破坏聚合查询。
- 索引:不同数据库引擎对索引中 NULL 值的处理方式不同,可能会影响查询性能。
6. 低质量设计带来的维护负担 🔧
技术债务不仅仅是代码运行缓慢的问题,更在于结构上的僵化。设计不良的 ERD 会使更改变得痛苦。当出现新需求时,例如添加一个与“配送地址”分开的“账单地址”,工程师必须评估当前模式是否支持这一需求。
迁移噩梦
更改包含数百万条记录的生产数据库的模式需要仔细规划。如果 ERD 在设计时未考虑迁移,修改列类型或拆分表可能会导致系统锁定数小时。这种停机时间会影响收入和用户信任。
缓解此问题的策略包括:
- 模式的版本控制:将数据库结构视为应用程序代码一样对待。
- 向后兼容性:先添加列,再删除列。在迁移完成前保留旧列。
- 文档: ERD 应该是事实的来源。如果它与数据库不一致,那么数据库就是错误的。
7. ERD 验证的实用检查清单 ✅
为了确保设计的稳健性,工程师在最终确定图表之前应完成验证检查清单。这一过程有助于在实施开始前发现逻辑错误。
实施前验证
| 检查 | 问题 | 通过标准 |
|---|---|---|
| 主键 | 每个表都有唯一的标识符吗? | 是的,使用自增或 UUID |
| 外键 | 关系是否明确界定? | 是的,带有 ON DELETE/UPDATE 规则 |
| 冗余 | 是否有任何数据存储在多个位置? | 没有,除非有意进行反规范化 |
| 可扩展性 | 能否处理当前数据量的10倍? | 外键上存在索引 |
| 可读性 | 新员工能否在5分钟内理解流程? | 清晰的命名规范 |
8. 工具与概念 🛠️
很容易依赖特定工具的功能来解决设计问题。然而,工具是次要的,概念才是核心。无论使用可视化建模工具还是直接编写 SQL 脚本,其底层逻辑保持一致。
一些工程师创建的图表在视觉上看起来完美,但在目标数据库中在语法上是不可能的。例如,某些工具允许在可视化层中存在循环依赖,而数据库引擎会拒绝这些依赖。重点必须放在关系完整性规则上,而不是绘图界面。
- 视觉一致性: 使用关系的标准符号(乌鸦脚表示法)。
- 验证: 将模式运行在测试数据库上以验证约束条件。
- 协作:与理解业务领域的利益相关者一起审查图表,而不仅仅是技术同行。
9. 现实世界中的失败场景 ⚠️
理解抽象概念是一回事;在实践中看到它们失败是另一回事。以下是由于ERD设计不佳而导致实际问题的常见场景。
场景A:无限循环
一名开发人员在用户和团队其中用户属于一个团队,而团队由一名用户领导。如果外键指向同一张表但没有明确的根节点,在插入时就会出现循环引用错误。ERD必须明确区分“成员”和“领导”关系。
场景B:无声的数据丢失
一个订单表引用了产品表。ON DELETE约束设置为级联。当产品从目录中移除时,所有相关订单都会被删除。这会破坏历史销售数据。ERD应明确将参照操作定义为限制或设置为空,具体取决于业务需求。
场景C:搜索缓慢
创建了一张表,其中包含一个名称列。工程师经常查询此表以按名称查找用户。如果在设计阶段未定义索引,数据库将执行全表扫描。ERD应标明哪些列是搜索密集型的,需要建立索引。
10. 从初级到高级思维的转变 🚀
这一转变意味着将关注点从“它是否能工作?”转移到“它是否可扩展?”以及“是否易于维护?”。
- 预期:根据行业趋势预测未来需求。
- 沟通:将技术限制转化为业务风险。
- 审查:在未经同行审查前,切勿假设图表是正确的。
初级工程师通常独自工作。高级工程师则注重协作。ERD是一种沟通工具,它弥合了开发人员、产品经理和利益相关者之间的差距。如果图表令人困惑,期望就会出现偏差。
关于数据完整性的最后思考 🎯
构建数据库模式不是一次性的任务;而是一项持续的纪律。复杂性差距的存在是因为风险很高。应用程序代码中的错误可以立即修复。但数据模型中的错误通常需要迁移、数据清理和停机时间。
通过遵循严格的建模原则,深入理解基数,并将业务逻辑置于便利性之上,工程师可以缩小差距。目标不是创建一个完美的图表,而是建立一个支持软件演进的基础。数据是应用程序最具价值的资产。保护其结构是每一位参与构建过程的工程师的责任。
花时间审查你的图表。质疑每一个关系。验证每一个约束。在设计阶段投入的时间,可以节省维护阶段数月的工作量。