











为大规模后端系统设计数据架构是一项基础性任务,它决定了整个应用程序的持久性和稳定性。实体关系图(通常简称为ERD)是该架构的蓝图,它以可视化方式描绘数据结构,明确不同信息片段在系统内部如何连接、关联和交互。在企业环境中,数据一致性、完整性和可扩展性至关重要,因此遵循既定的ERD标准不仅是最佳实践,更是必要之举。
如果没有标准化的数据建模方法,后端系统可能会变得脆弱。命名约定不一致、关系模糊以及规范化不足可能导致性能瓶颈、维护困难和数据损坏。本指南探讨了构建适用于复杂企业环境的稳健数据库模式所必需的关键标准和方法。我们将研究专业团队为确保其数据层长期可靠而采用的核心组件、符号系统、规范化规则和治理策略。
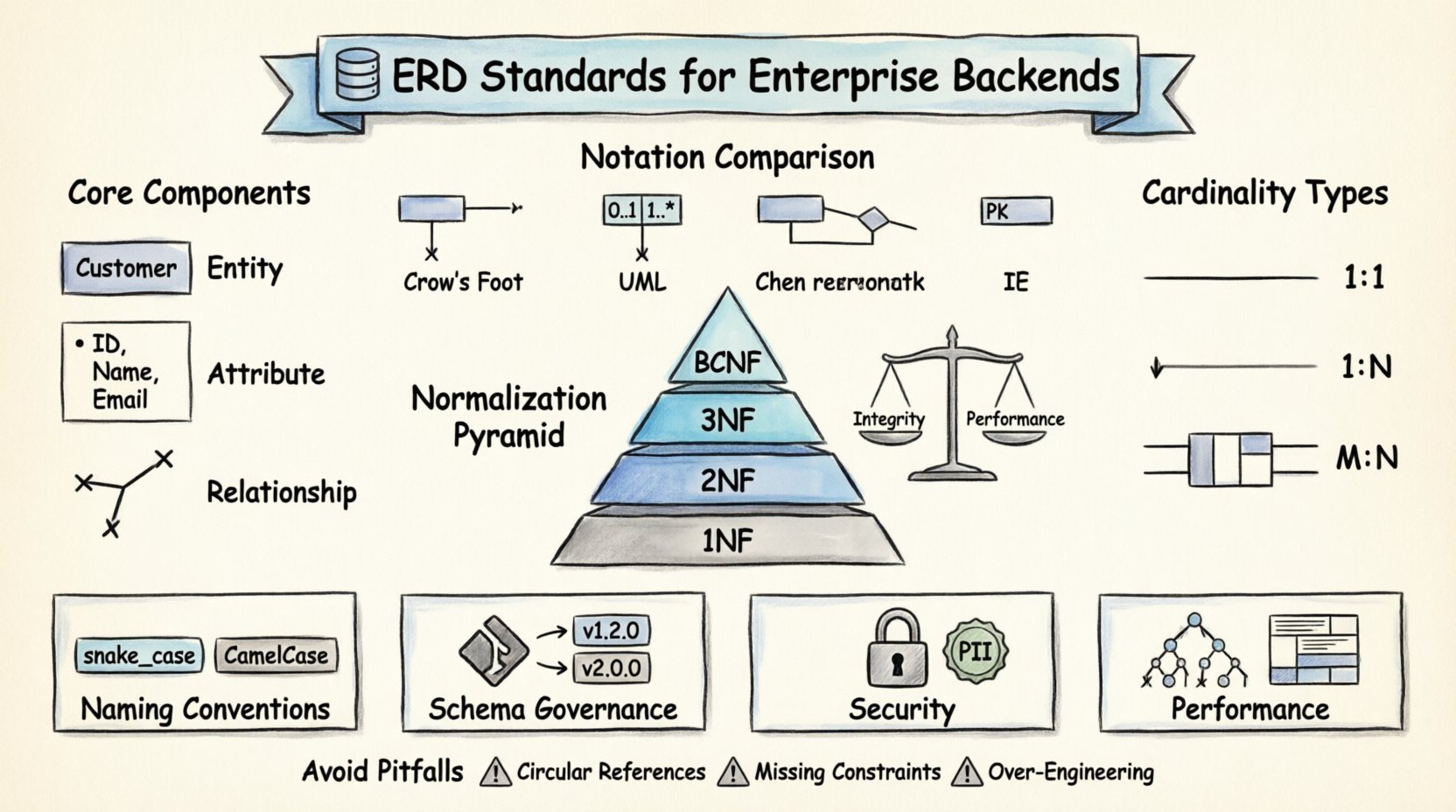
企业级ERD的核心组件 🧩
在深入探讨具体标准之前,理解构成ERD的基本构建模块至关重要。在专业环境中,每个图表都依赖于三个主要元素。这些元素协同工作,以描述数据的逻辑结构。
- 实体: 它们代表了存储数据的真实世界对象或概念。在后端环境中,实体通常直接映射到数据库表。例如:客户, 订单,或产品。实体必须明确定义,以确保每条记录都有唯一的标识。
- 属性: 属性描述实体的特定属性或特征。它们对应于表中的列。对于一个客户实体,属性可能包括客户ID, 姓名,以及电子邮箱地址。为属性正确定义数据类型对于数据完整性至关重要。
- 关系: 关系定义了实体之间的相互作用方式。它们建立了表之间的约束和关联。例如,一个客户可以下多个订单。这种关系决定了后端所需的外键约束和连接逻辑。
在企业级开发中,这些组件不仅仅是抽象概念,更是查询优化、访问控制和数据迁移策略的基础。一份详尽记录的ERD使开发人员能够在无需逐行检查代码的情况下理解数据流。
符号标准与视觉惯例 📐
绘制ERD没有单一的通用语法,但存在广泛接受的标准,可确保不同团队之间的一致性和清晰性。选择一种符号并坚持使用,是一项关键的治理决策。
陈氏符号与乌鸦足符号的对比
历史上,陈氏符号是标准,使用矩形表示实体,菱形表示关系。虽然清晰,但在现代软件开发工具中已不常见。乌鸦足符号之所以成为行业首选,原因有以下几点:
- 基数的清晰性: 它使用特定符号(线条、圆圈和“脚”)直观地表示一对一、一对多和多对多的关系。
- 工具支持: 大多数现代数据库设计工具和逆向工程工具原生支持乌鸦足符号或UML派生符号。
- 可读性: 在处理复杂且相互关联的模式时,通常更加紧凑,也更易于阅读。
符号系统对比
| 符号风格 | 实体表示 | 关系表示 | 最佳使用场景 |
|---|---|---|---|
| 乌鸦足符号 | 矩形 | 带符号的线条(乌鸦足、圆圈、直线) | 关系数据库设计 |
| UML类图 | 带分隔区的类框 | 带多重性的箭头(0..1, 1..*) | 面向对象建模 |
| 陈氏 | 矩形 | 连接实体的菱形 | 学术/理论模型 |
| IE(信息工程) | 带属性的矩形 | 带主键标识的线条 | 遗留系统文档 |
对于企业后端,通常推荐使用Crow’s Foot表示法,因为它能直接映射到关系约束。在开发人员实现过程中解读图表时,这种方法能最大限度地减少歧义。
规范化:确保数据完整性 🔄
规范化是通过组织数据库中的数据来减少冗余并提高数据完整性的过程。尽管现代系统有时为了性能而反规范化,但理解规范化规则对于设计一个合理的初始模式至关重要。
规范化形式
- 第一范式(1NF):每一列必须包含原子值。单个单元格中禁止包含值列表。这确保了每一行与每一列的交点都包含一个单一且不可分割的数据项。
- 第二范式(2NF):表必须处于1NF,且所有非键属性必须完全依赖于主键。这可以防止部分依赖,即某一列仅依赖于复合键的一部分。
- 第三范式(3NF): 表必须处于2NF,且不能存在传递依赖。非键属性不应依赖于其他非键属性。例如,如果城市 依赖于邮政编码,并且邮政编码 依赖于ID, 城市城市应移至单独的表中。
- 博伊斯-科德范式(BCNF): 3NF的更严格版本。它要求对于每一个函数依赖X → Y,X必须是超键。这解决了3NF中某些特殊情况,即决定因素是候选键但不是主键的情形。
规范化权衡
| 级别 | 优势 | 成本 |
|---|---|---|
| 高规范化(3NF/BCNF) | 冗余最少,完整性高 | 查询需要更多的连接操作 |
| 低规范化(去规范化) | 更快的读取性能 | 数据不一致的风险更高 |
企业系统通常在其事务模式中力求达到第三范式(3NF)。当读取性能成为瓶颈时,会针对性地对特定视图或报表表进行去规范化处理,而不是对核心事务模式进行去规范化。
命名规范与模式整洁性 🏷️
一致的命名规范对于可维护性至关重要。当多个团队在同一个后端上工作时,命名上的模糊会导致错误。应制定标准并使用 lint 工具或模式验证脚本来强制执行。
表命名规则
- 复数与单数: 人们对此有争议,但一致性才是关键。复数名称(例如,用户, 订单)在英文句子中通常读起来更顺畅。单数名称(例如,用户, Order)在面向对象的上下文中通常更受青睐。选择一种并全局应用。
- 下划线与驼峰命名法: 下划线(snake_case)是 SQL 标识符的标准写法。驼峰命名法(camelCase)在应用程序代码中很常见。确保数据库层和应用层在转换策略上达成一致。
- 避免使用保留关键字: 永远不要使用数据库保留关键字来命名表或列(例如,Group, Select, Order).这可以防止在生成查询时出现语法错误。
- 元数据前缀: 使用类似这样的前缀 _audit, _log,或 _temp 来区分辅助表和核心业务实体。
列命名规则
- 外键: 明确表示关系。如果一列引用了 Users 表,应将其命名为 user_id 而不是 uid 或 fk_user.
- 布尔标志: 使用类似这样的前缀 is_ 或 has_。例如,is_active 或 has_subscription.
- 日期时间字段: 指定范围。使用 created_at 或 updated_at 而不是通用的 date 或 time.
关系与基数 🔄
理解基数是区分一个正常运行的数据库与一个崩溃的数据库的关键。基数定义了某一实体的实例与另一实体的实例之间可以或必须关联的具体数量。
关系类型
- 一对一(1:1): 实体A的一个实例与实体B的一个实例相关联。这在核心业务逻辑中很少见,但在安全或配置数据中很常见。示例:一个 User 有一个 Profile.
- 一对多(1:N): 实体A的一个实例与实体B的多个实例相关联。这是最常见的关系。示例:一个 Department 有多个 Employees.
- 多对多(M:N): 实体A的多个实例与实体B的多个实例相关联。这需要一个连接表(关联实体)。示例:Students 和 Courses.
可选性与约束
基数并不能说明全部情况;可选性才是关键。这指的是关系是强制性的还是可选的。
- 强制性(强制参与): 一个实体实例 必须 与另一个实体相关联。例如,一个 订单 必须 有一个 客户.
- 可选性(可选参与): 一个实体实例 可以 在没有关系的情况下存在。例如,一个 产品 可以在没有 订单 记录的情况下存在。
使用约束(NOT NULL、外键)在数据库层面强制执行这些规则,比在应用代码中强制执行要可靠得多。它能防止数据漂移,并确保模式始终是事实的唯一来源。
模式治理与版本控制 📜
在企业环境中,数据库模式就是代码。它必须进行版本控制、审查,并以与应用程序源代码相同的严格标准进行管理。ERD 不是一份静态文档;随着业务需求的变化,它也会不断演进。
迁移策略
- 向前兼容: 变更应设计为能够兼容旧数据。避免立即删除列;相反,应将其标记为已弃用。
- 向后兼容: 新的模式版本不应破坏现有的查询。使用视图将变更从应用层抽象出来。
- 原子性变更: 每个迁移脚本应代表一次单一的逻辑变更。如果发生错误,这将使回滚操作更加容易。
文档维护
未更新的ERD是一种风险。确保图表生成过程是自动化的。理想情况下,ERD应直接从模式定义文件(DML)生成,以防止文档与实际数据库状态之间出现偏差。
- 每次提交时都自动生成功能图。
- 在拉取请求流程中要求进行模式审查。
- 为重要模式版本打标签,以便与应用程序发布相对应。
安全与隐私考虑 🔒
企业后端处理敏感信息。ERD设计阶段必须考虑安全与隐私要求,特别是关于个人身份信息(PII)的问题。
数据分类
- 公开数据:可以公开共享的信息。无需特殊处理。
- 内部数据:仅限员工访问的信息。应考虑访问控制列表(ACL)。
- 受限数据:如密码、健康记录或财务信息等敏感数据。这些字段需要在静态和传输过程中进行加密。
掩码与匿名化
在ERD中,标记在非生产环境中需要掩码的字段。这有助于开发人员了解在测试期间哪些列需要特殊处理。虽然图表本身不强制执行安全措施,但它指导安全策略的实施。
- 明确标识包含PII的列。
- 定义审计字段(例如,最后修改人)以追踪谁访问或更改了数据。
- 确保外键不暴露可能被枚举的内部ID。
性能与可扩展性规划 🚀
尽管ERD侧重于结构,但也必须考虑性能。一个逻辑上合理但物理上缓慢的模式在负载下将无法正常工作。
索引策略
ERD中定义的关系决定了索引的必要位置。外键应建立索引以加快连接和约束检查。然而,过度索引会减慢写入操作。
- 主键: 始终被索引。
- 外键: 始终被索引以提升连接性能。
- 搜索列: 在 WHERE 子句中经常使用的列应建立索引。
分区与分片
对于大规模数据集,ERD 可能暗示分区策略。如果数据天然分组(例如按 区域 或 日期),这应在模式设计中体现出来。这使得数据库能够将负载分布在多个物理节点上。
应避免的常见陷阱 ⚠️
即使经验丰富的团队也会犯错。识别常见的失败模式有助于构建一个具有韧性的系统。
- 循环引用: 避免实体 A 依赖 B,而 B 又依赖 A 的关系,这种循环会增加数据删除或更新的复杂性。
- 缺失约束: 依赖应用程序代码来强制执行规则(例如确保 价格 为正数)是存在风险的。应在数据库中使用 CHECK 约束。
- 过度设计: 不要为每一个可能的未来场景建模。应根据当前需求进行设计,并保留足够的灵活性以适应变化,但避免为假设的使用场景创建表。
- 硬编码值: 避免在没有查找表的情况下将状态码以整数形式存储。对于像 订单状态 这样的状态,应使用参考表以保持清晰。
在您的工作流程中实施标准 🛠️
采用这些标准需要文化上的转变。仅仅绘制一张图是不够的;这张图必须推动开发流程。
- 先设计: 在编写任何迁移脚本之前,必须先批准 ERD。
- 代码审查: 将模式变更包含在标准的代码审查清单中。
- 培训: 确保所有后端工程师都理解规范化和基数的概念。
- 工具:投资于支持协作和版本控制的模式设计工具。
将实体关系图视为系统架构中一个动态且活跃的组成部分,企业团队可以确保其数据层保持稳健。在设计阶段投入标准化的努力,将在降低技术债务和提升系统可靠性方面带来回报。结构良好的数据库是构建可扩展应用程序的基石。
当您在数据建模中优先考虑清晰性、一致性和完整性时,您就建立了一个支持发展的基础。此处概述的标准为这一基础提供了框架。遵循这些标准,可确保随着组织的扩展,您的后端系统依然保持可维护性、安全性和高效性。