











软件架构文档常常成为速度的牺牲品。在快速迭代的开发环境中,频繁发布功能的压力往往超过了维护系统最新视觉表示的需求。然而,过时的文档会产生技术债务,这种债务通常比代码债务更难偿还。C4模型提供了一种在不同抽象层次上记录软件架构的结构化方法。将该模型集成到持续集成(CI)流水线中,可以确保架构文档与代码库同步演进,保持清晰性并减少偏差。
本指南探讨了如何将架构图视为代码来对待。通过将C4实践嵌入构建流程,您可以创建一个反馈循环,使文档像应用程序逻辑一样被验证、版本化并部署。这种方法降低了团队间沟通误解的风险,并确保新开发人员能够快速上手,借助准确的视觉参考。
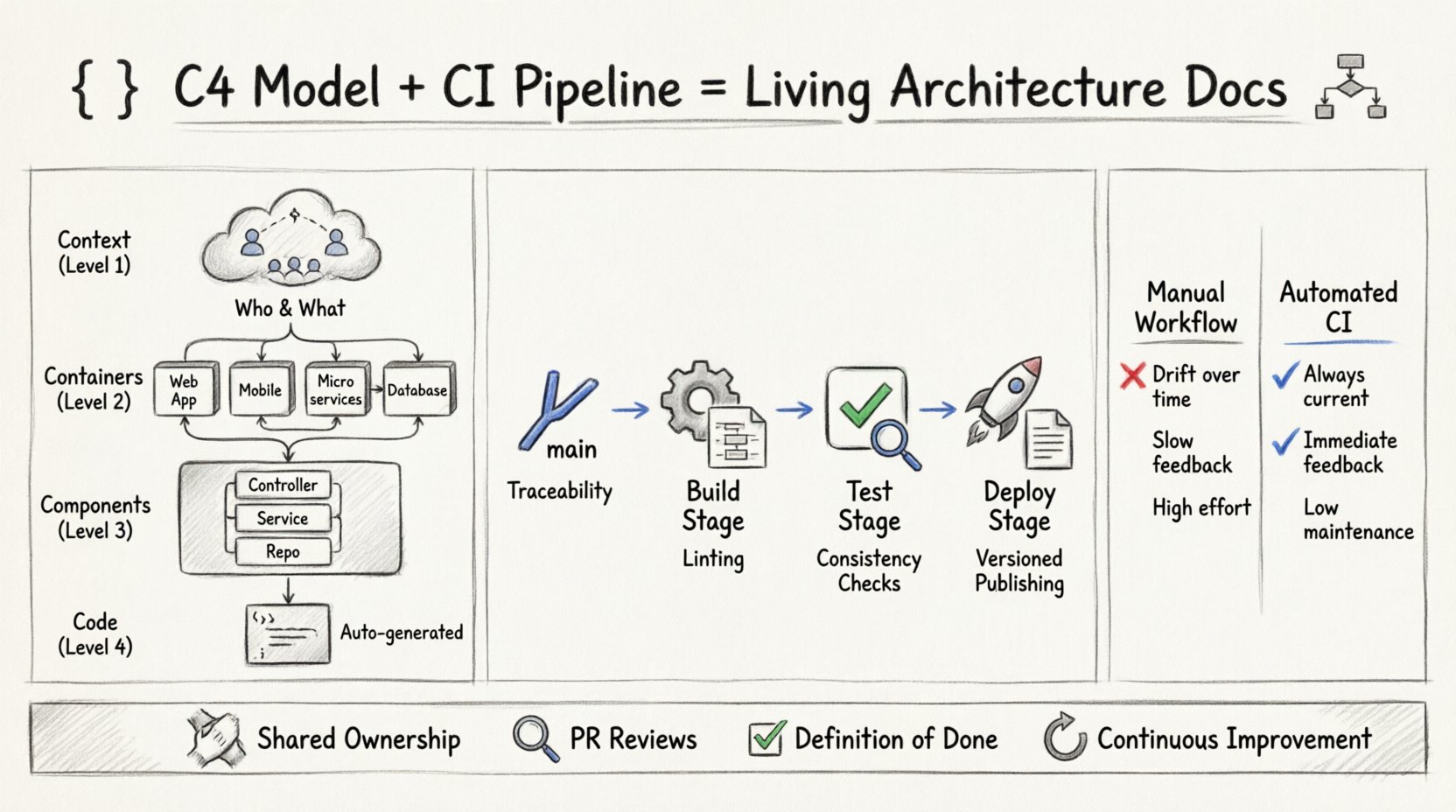
理解C4模型的层级 📐
在自动化流程之前,必须理解C4模型的四个层级。每个层级服务于特定的受众,并在流水线中需要不同的维护策略。
- 上下文(第1层):提供系统的高层次视图,包括其用户和外部依赖。它回答的问题是:这个系统做什么,由谁使用?该图对于利益相关者对齐至关重要,每当集成新的外部服务时都应更新。
- 容器(第2层):将系统分解为独立的运行时环境,包括Web应用、移动应用、微服务和数据库。该视图对基础设施团队至关重要,有助于理解部署拓扑结构。
- 组件(第3层):详细描述容器内的逻辑构建模块。该层级描述服务的内部结构,例如控制器、仓库和业务逻辑。主要面向负责特定服务的开发人员。
- 代码(第4层):这一层级很少以相同方式可视化。它指的是类或方法级别的结构。尽管通常可从源代码自动生成,但要使其与C4文档保持同步,需要严格的命名规范和自动化提取工具。
手动文档的问题 🛑
传统的文档工作流程依赖手动更新。开发人员创建一张图,保存后就继续前进。随着时间推移,随着代码的变更,图表变得不准确。这会导致:
- 架构漂移:实际系统不再与文档中的设计一致。
- 入职摩擦:新团队成员必须逆向工程系统,因为图表已经过时。
- 评审瓶颈:架构评审变成了讨论图表是否与现实相符,而不是评估设计本身。
- 知识流失:当团队成员离开时,如果其设计决策没有以持久且可版本化的方式记录下来,这些决策的背景信息就会丢失。
通过CI流水线自动化这些流程可以缓解这些风险。它将维护负担从手动操作转移到自动化验证。
将C4集成到CI流水线 🔗
嵌入C4实践需要在文档处理方式上发生转变。它不应是事后补充;而应成为“完成”的定义的一部分。集成贯穿流水线的各个阶段,确保图表能够自动生成、验证并自动发布。
1. 版本控制与事实来源
第一步是将图表定义存储在与源代码相同的版本控制系统中。这可以实现:
- 可追溯性:您可以准确查看是哪一次代码更改触发了图表的更新。
- 协作:多名团队成员可以通过拉取请求提出更改。
- 历史记录: Git 历史记录充当了架构演进的审计轨迹。
使用领域特定语言或结构化文本格式来表示图表,可确保这些文件具有可读性和可合并性,与二进制图像文件不同。
2. 构建阶段:生成与验证
在构建阶段,流水线应能自动从源定义生成图表。此阶段应包含验证步骤,以确保图表在语法上正确且逻辑上一致。
- 编译:将图表定义转换为可视化格式(SVG、PNG)。
- 代码检查:检查命名规范、正确的关联类型以及缺失的组件。
- 验证:确保图表反映当前代码库的状态。例如,如果代码中移除了某个组件,图表应被更新或标记为需要审查。
3. 测试阶段:自动化一致性检查
自动化测试可以验证文档是否与代码一致。这对第3级(组件)图表尤其有效。静态分析工具可以解析代码,并将发现的组件与文档中记录的组件进行比对。
- 覆盖度检查:确保所有公共 API 都在图表中有所体现。
- 依赖项检查:验证图表中列出的外部依赖项确实存在且版本号正确。
- 链接验证:检查文档中的内部链接是否指向有效的部分。
4. 部署阶段:发布与分发
一旦图表通过验证,就应将其部署到文档网站或共享的构件仓库中。这确保了文档始终可访问,并与软件的已部署版本保持一致。
- 版本控制:将文档与版本标签一同存储。这使得用户可以同时查看 1.0.0 版本和 1.1.0 版本的架构。
- 访问控制:确保敏感的架构细节仅对授权人员可见。
- 更新通知: 在架构发生变化时触发通知,使利益相关者保持知情。
比较手动与自动化工作流程 📊
为了理解此集成的价值,请考虑以下工作流程的对比。
| 功能 | 手动工作流程 | 自动化CI工作流程 |
|---|---|---|
| 准确性 | 初始投入高,随时间推移逐渐下降 | 通过代码变更维护 |
| 一致性 | 依赖于个人自律 | 由流水线规则强制执行 |
| 反馈速度 | 缓慢(发布后) | 即时(在PR期间) |
| 可维护性 | 投入高 | 投入低(配置完成后) |
| 版本控制 | 手动文件管理 | 通过Git标签自动完成 |
特定C4层级的策略 🛠️
C4模型的不同层级需要在流水线中采用不同的自动化策略。
上下文图
这些图表变化较少,但对入职至关重要。自动化应重点确保新外部系统被标记以供审查。当代码中添加新依赖时,流水线可提醒架构师更新上下文图。
容器图
这些通常与基础设施即代码相关联。自动化可以从部署清单(如Kubernetes YAML文件)中提取容器定义,并自动生成容器图。这确保了视觉表示与部署配置完全一致。
组件图
这是最复杂的自动化层级。需要对源代码进行深度解析。流水线应运行静态分析工具以识别类和方法,然后将其映射到组件图。如果代码结构与图表不符,构建应失败,必须在合并前更新文档。
挑战与解决方案 ⚠️
实施自动化的C4实践并非没有挑战。团队经常因认为存在额外负担或复杂性而产生抵触情绪。
挑战1:初始配置时间
设置流水线以理解代码库并生成图表需要大量的前期投入。团队可能会觉得这会减缓初期开发速度。
- 解决方案:从小处着手。先自动化一级和二级。三级可以稍后添加。优先考虑关键服务,而非遗留系统。
挑战2:验证中的误报
如果逻辑过于僵化,自动化检查可能会将有效的架构变更标记为错误。
- 解决方案:调整验证规则。在特定情况下允许手动覆盖,但必须附上说明,解释为何需要覆盖。
挑战3:工具复杂性
选择合适的工具来解析代码并生成图表可能令人望而生畏。
- 解决方案:尽可能使用开放标准。避免使用会将你锁定在特定供应商的专有格式。重点关注图表的文本表示形式,而非渲染引擎。
需要文化转变 🧠
技术实现只是成功的一半。将C4实践融入团队需要团队文化的转变。
- 共同责任:文档不仅仅是架构师的责任。开发者应感到有责任保持其组件图的准确性。
- 拉取请求审查:架构图应像代码一样在拉取请求中进行审查。如果代码发生变化,图表也必须随之更新。
- 完成定义:更新“完成定义”,包含图表更新。在相关C4图表更新之前,功能不能视为完成。
- 持续改进:定期审查文档流程。图表是否仍然有用?自动化检查是否过于嘈杂?根据情况相应调整工作流程。
衡量成功 📈
为确保集成有效,需跟踪特定指标。这些指标有助于识别流程中出现问题的环节。
- 文档覆盖率:代码库中有多大比例拥有相关图表?
- 更新频率:图表相对于代码提交的频率是多久更新一次?
- 验证错误:有多少构建失败是由图表不一致引起的?
- 入职时间:新开发人员变得高效所需的时间是否随时间减少?
- 偏差率:代码变更与相应图表更新之间相隔多长时间?
处理遗留系统 🏛️
并非所有系统都以自动化为目标构建。遗留系统通常缺乏自动生成图表所需的结构。对于这些系统,需要采用混合方法。
- 逐步迁移:首先从记录上下文和容器层级开始。这些层级以最少的努力提供了最大的价值。
- 手动输入并验证:手动维护图表,但使用流水线验证代码结构是否与图表描述一致。
- 绞杀者模式:随着新功能的增加,以新的C4合规方式对其进行记录。随着系统的发展,逐步替换旧的文档。
拉取请求的作用 🔄
拉取请求是实施C4实践的自然场所。它们提供了审查和协作的机制。
- 图表变更:任何对图表文件的更改都应触发审查。审查者可以检查图表是否准确反映了代码变更。
- 评论:使用评论来讨论架构决策。这会创建一个历史记录,说明为何做出某些设计选择。
- 阻断规则:配置流水线,如果图表验证失败则阻止合并。这确保文档永远不会被落下。
结论 🎯
将C4模型嵌入持续集成流水线,可将文档从静态负担转变为动态资产。它使文档生命周期与代码生命周期保持一致,确保系统描述始终最新。尽管初始设置需要投入,但长期来看,减少偏差、加快入职速度和更清晰的沟通带来的好处是显著的。
通过将图表视为代码,团队可以利用与软件交付相同的自动化工具。这创建了一个统一的工作流程,其中质量被自动强制执行,架构始终保持为开发过程中的动态组成部分。目标不是完美,而是保持一致。通过正确的流水线集成,架构文档成为支持整个开发生命周期的可靠真相来源。