











为企事业环境构建软件系统,不仅需要编写代码,更需要深刻理解驱动这些系统的业务逻辑。这种理解的核心在于领域模型。对于刚承担这一责任的新架构师而言,从理论设计到实际实现的过渡可能充满微妙但代价高昂的错误。一个健壮的领域模型充当单一事实来源,弥合业务需求与技术实现之间的鸿沟。然而,若缺乏细致关注,即使初衷良好的设计也可能在复杂性面前崩溃。
本指南探讨了企业架构设计阶段最常见的错误。通过及早识别这些陷阱,架构师可以构建出具有韧性、可维护性并符合组织目标的系统。我们将深入分析具体模式、常见误解以及实用策略,以确保您的模型经得起时间的考验。
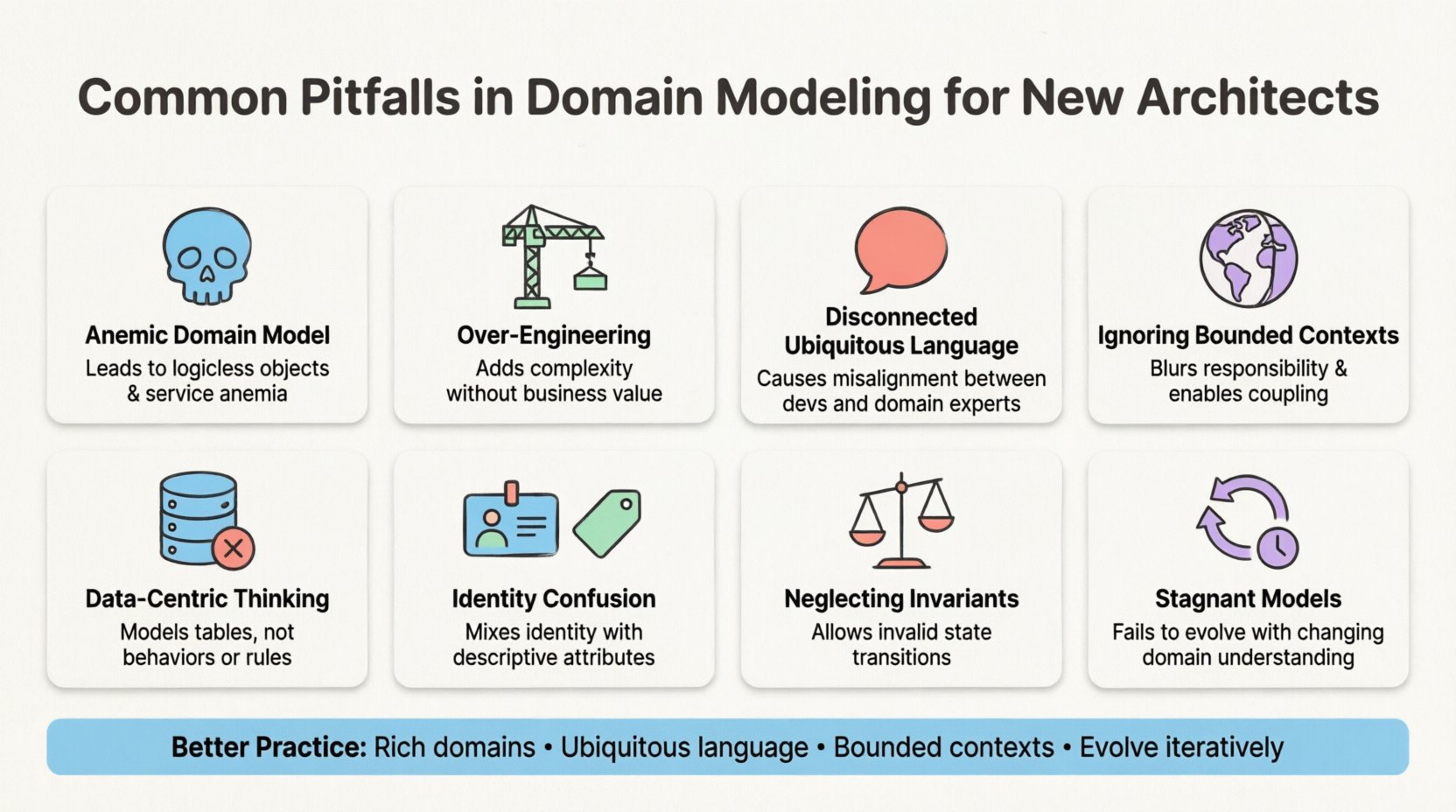
贫血领域模型陷阱 💀
现代软件开发中最普遍的问题之一,就是创建了贫血领域模型。这种情况发生在领域对象被简化为仅用于存储数据的容器时,它们拥有公共属性和getter/setter方法,但缺乏行为。在这种情形下,业务逻辑被移出领域层,分散在服务类或控制器中。
- 为什么会发生:开发者往往更重视数据库映射的便捷性,而非面向对象原则。他们主要将对象视为表格中的一行。
- 后果:领域失去了意义。验证规则变得分散,实体的生命周期难以追踪,因为对象本身无法维护其完整性。
- 影响:维护成本急剧上升。更改一个业务规则需要修改多个服务层,而不是仅修改一个领域方法。
为避免这种情况,请确保您的实体封装了其状态和行为。一个客户对象应知道如何下单,而不仅仅是保存创建订单所需的数据。关于订单限额、信用检查或账户状态的逻辑应存在于客户类本身。
脱离的通用语言 🗣️
领域驱动设计强调通用语言的重要性——这是业务利益相关者和技术团队共同使用的共享词汇。新架构师常见的陷阱是,允许业务语境与代码实现之间的语言出现脱节。
如果业务方称其为“客户”,而代码中使用的是“用户账户”,混乱必然产生。如果利益相关者讨论“订单履行”,而系统却建模为“发货状态”,模型便无法反映现实。这种脱节会导致:
- 沟通误解:在翻译阶段,需求被误解。
- 重构开销:不断修改代码库,仅仅为了匹配不断变化的业务术语。
- 信任丧失:开发者不再听取业务输入,因为他们的术语在系统中未被尊重。
对齐策略:
- 举办工作坊,明确界定术语。
- 使用与业务术语表完全一致的代码名称。
- 将术语表作为活文档进行记录,并与代码同步更新。
在理解之前过度设计 🏗️
建筑师有一种设计完美且灵活的系统以应对所有可能未来场景的诱惑。这通常被称为“YAGNI”(你不会需要它)原则的违反。新建筑师经常为了应对并不存在的需求,创建复杂的继承层次结构或通用接口。
过度设计的风险:
- 复杂性增加:简单的用例变得难以实现,因为结构过于僵化。
- 隐藏的缺陷:复杂的逻辑路径会带来更多出错的机会。
- 交付更慢:花费时间设计“完美”的解决方案,会延迟实际价值的交付。
聚焦当前需求:
针对当前问题进行设计。与其构建一个永远无法完成的复杂模型,不如先拥有一个简单且可工作的模型,之后再重构。接受模型会不断演进的事实。只有在业务需求明确时,才添加特定的扩展点。
忽视有界上下文 🌍
在大型企业系统中,领域很少是一个单一统一的概念,而是由多个子领域组成。新建筑师可能会试图将整个企业建模为一个巨大的对象图。这忽视了有界上下文的概念,即同一个术语在业务的不同部分可能具有不同的含义。
例如,术语产品在销售场景中,它可能包含价格和可用性;而在库存场景中,它可能侧重于SKU和仓库位置。将它们合并为单一模型,会创建一个臃肿的实体,包含无关数据和混乱的逻辑。
- 上下文边界: 明确划分不同模型对特定数据的所有权边界。
- 上下文映射: 建立这些模型之间的通信方式。使用防腐层防止一个上下文通过其特定的实现细节污染另一个上下文。
- 共享内核: 在需要集成的地方,就模型的一个共享子集达成一致,但保持其余部分相互隔离。
以数据为中心的思维 vs. 以对象为中心的思维 💾
建筑师通常从数据库模式开始,然后围绕它构建领域模型。这颠倒了领域驱动设计的自然流程。数据库是持久化问题,而领域模型是业务问题。
当你根据数据库建模时:
- 你会将实现细节(外键、空值约束)引入到业务逻辑中。
- 重构数据库模式会成为业务逻辑的破坏性变更。
- 你将失去将领域视为纯粹对象模型的能力。
关注点分离:
保持领域模型的清晰。如果数据库列没有业务意义,就不要将其暴露为属性。使用映射层在对象图和关系结构之间进行转换。这确保了你的业务逻辑与存储技术保持独立。
忽视不变性与业务规则 ⚖️
不变量是一种必须始终为真的条件。在一个设计良好的领域中,不变量由模型本身强制执行。新架构师常常将验证逻辑推到UI或服务层,导致领域对象暂时处于无效状态。
被忽视的不变量示例:
- 一个
银行账户在透支保护未启用时允许出现负余额。 - 一个
订单处于已发货状态,但没有有效的追踪编号. - 一个
折扣被应用到低于最低门槛的订单上。
如果这些检查在对象外部发生,对象可能会被破坏。如果直接调用方法(绕过服务层),不变量可能会被违反。模型必须保护自身的完整性。
身份与值对象混淆 🆔
理解实体与值对象之间的区别至关重要。实体由其身份定义(例如一个特定的员工),而值对象由其属性定义(例如一个地址或货币).
常见错误:
将值对象当作实体处理。如果你为一个街道地址分配唯一ID,就会引入不必要的复杂性。如果你将一个员工当作值对象,你就失去了追踪其随时间变化历史的能力。
- 实体: 需要一个身份标识。两个名字相同员工是不同的人。
- 值对象: 没有身份标识。两个街道和城市相同的地址是相同的值。
混淆这两者会导致性能问题(不必要的ID查找)和逻辑错误(将本应不可变的数据当作可变数据处理)。
僵化模型 🔄
领域模型不是一次性交付物。它是一个必须随业务发展而演进的活体产物。一个常见陷阱是将初始设计视为最终真理。当业务需求发生变化时,模型也应随之调整。
僵化模型的迹象:
- 开发者感觉无法添加新功能而不破坏现有功能。
- 代码注释解释了为何某些变通方案被采用。
- 模型中仍包含多年前已弃用功能的逻辑。
持续优化:
鼓励将重构作为标准实践。定期与业务利益相关者一起审查领域模型。如果某个概念在业务中已不存在,就从代码中移除它。如果出现新概念,立即对其进行建模。一个不变化的模型就是正在死亡的模型。
常见陷阱 vs. 更佳实践
下表总结了常见错误与推荐架构方法之间的关键区别。
| 陷阱 | 影响 | 更佳实践 |
|---|---|---|
| 贫血领域对象 | 逻辑分散,难以维护 | 具有封装行为的丰富领域对象 |
| 数据库优先设计 | 与存储紧密耦合 | 领域优先,稍后映射到存储 |
| 单一的单体模型 | 复杂度爆炸,混乱 | 具有明确边界的限界上下文 |
| 在服务层进行验证 | 可能出现无效状态 | 在领域实体内部进行验证 |
| 过度设计 | 交付变慢,隐藏的缺陷 | 简单设计,按需演进 |
| 忽视通用语言 | 沟通不畅,返工 | 业务与技术之间的共享词汇 |
改进的实用步骤 🛠️
避免这些陷阱需要思维和流程的转变。以下是可操作的步骤,可融入你的架构工作流程中。
1. 开展领域故事会
不要仅仅收集需求,而是与领域专家坐下来,共同梳理场景。请他们描述交易的流转过程。将他们的叙述映射到你的模型中。这能确保模型反映实际工作,而不仅仅是理论上的理想状态。
2. 强制代码所有权
将领域模型的特定部分分配给特定的开发人员或团队。这能建立责任机制。如果订单模型出现故障时,负责订单的团队就知道需要修复它。这可以避免‘人人负责,人人无责’的困境。
3. 实施静态分析
使用工具来强制执行架构规则。例如,阻止服务类直接访问数据库实体,强制它们通过领域接口进行访问。这能自动维护关注点分离。
4. 定期进行模型评审
安排定期会议,团队共同评审领域模型。查找诸如过长的方法、上帝类或命名不一致等异味。对待模型应像对待生产代码一样严格。
5. 文档即代码
将文档与代码放在同一个代码仓库中。如果代码发生变化,文档也必须随之更新。使用能从代码结构生成图表的工具,确保可视化表示与实际实现一致。
架构的人性因素 👥
最后,请记住,领域建模不仅仅是技术工作,更是一种社会活动。模型的质量在很大程度上取决于架构师、开发人员与业务利益相关者之间的沟通。如果业务方无法理解模型,或者开发人员无法高效实现,再完美的模型也是无用的。
协作是关键。在设计阶段就让资深开发人员参与进来。他们对实现约束的经验可以避免那些无法落地的理论设计。让业务分析师参与命名规范的制定。他们的洞察力能确保模型始终与组织需求保持一致。
架构健康状况总结 ✅
构建高质量的领域模型是一段持续改进的旅程。它需要警惕为追求速度而走捷径的诱惑。它要求尊重业务规则以及执行这些规则的人。通过避免本指南中指出的陷阱——如贫血模型、语言脱节和以数据为中心的耦合——你为系统打下了坚实且灵活的基础。
聚焦清晰性、封装性和一致性。让模型服务于业务,而不是反过来。当领域模型准确反映了企业的实际情况时,代码将更易于编写、测试和理解。这才是架构成功的真实衡量标准。
持续迭代,持续倾听,持续优化。最好的模型不是一天建成的;它们是在时间中成长起来的,由反馈滋养,通过持续实践而变得更强。