











灾难恢复很少关乎灾难本身;它关乎我们在风暴来临前构建的结构的脆弱性。在我们最近的事件中,数据库模式设计中的一个看似微小的疏忽,却成了整个恢复过程的瓶颈。罪魁祸首是一个未能准确反映生产环境数据依赖关系的实体关系图(ERD)。本应只需四十五分钟的操作,却演变为长达三小时的手动干预和数据校验。 🕰️
本文详细分析了此次失败的技术原因,导致延迟的具体模式不一致之处,以及我们为防止再次发生而实施的流程改进。我们将探讨数据完整性在多大程度上依赖于设计文档的准确性,而不仅仅是代码本身。
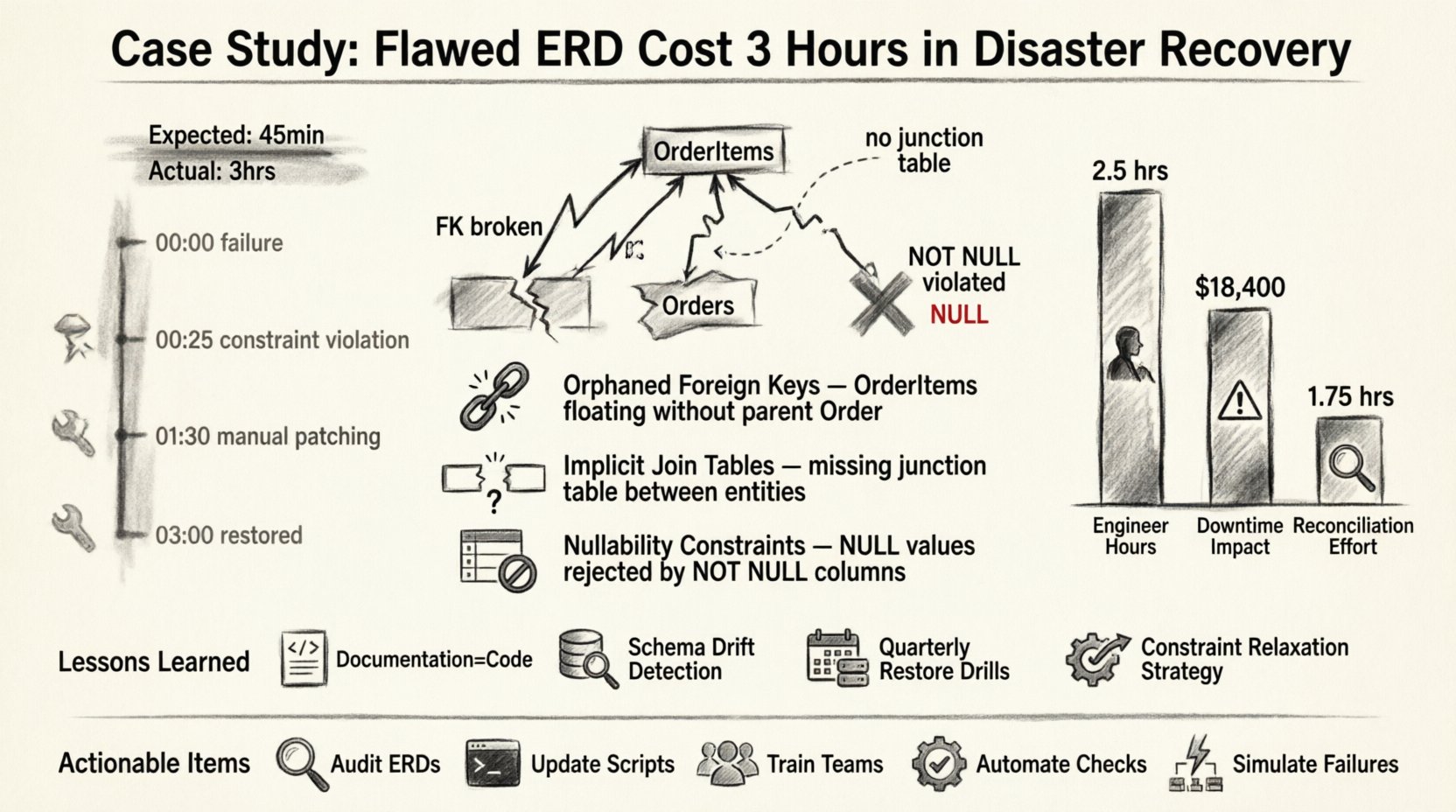
实体关系图在数据韧性中的关键作用 🛡️
实体关系图是数字基础设施的蓝图。它们描绘了表、字段、主键和外键,定义了数据如何连接和流动。当灾难发生时,这些图表是工程师尝试恢复系统状态时的首要参考。如果地图错误,旅程就会延误。
在灾难恢复的背景下,ERD具有三个主要功能:
- 验证: 它确认恢复后的模式与应用程序的预期状态一致。
- 依赖关系映射: 它识别出哪些表依赖于其他表,从而决定恢复的顺序。
- 约束验证: 它确保在导入过程中正确应用参照完整性规则。
当ERD与实际的数据库配置不一致时,恢复脚本会在验证阶段失败。这迫使工程师停止操作,进行调查,并手动修补模式。正是这个手动步骤导致了时间的损失。 ⏳
事件回顾:一系列错误的时间线 📉
此次事件始于主数据存储的故障。一次灾难性的硬件错误触发了向我们备用环境的故障转移。标准操作流程是启动恢复脚本,该脚本依赖于我们文档仓库中存储的静态ERD版本。
以下是故障的时间线:
- 00:00 – 检测到主系统故障。警报触发事件响应。
- 00:05 – 工程团队迅速集结。已授予对备用环境的访问权限。
- 00:15 – 根据文档中的ERD启动恢复脚本。
- 00:25 – 脚本停止。检测到外键约束违规。
- 00:30 – 调查开始。发现ERD与实时模式之间存在差异。
- 01:30 – 开始模式修补和手动数据校验。
- 03:00 – 系统恢复至正常运行状态。
三个小时的延迟并非由网络延迟或硬件缓慢引起。其原因是设计文档与实际物理现实之间的逻辑差距。🧩
已识别的具体模式缺陷 🔍
在将实时数据库与ERD进行比对后,我们发现了三个关键差异。这些并非语法错误,而是逻辑遗漏,只有在系统尝试强制实施关系时才显现出来。
1. 孤立的外键
ERD 描述了“订单”与“订单项”之间存在严格的 一对多 关系。然而,实际数据库中包含遗留数据,其中“订单项”存在,却没有对应的“订单”记录,这是由于之前未强制约束的迁移所致。ERD 未考虑这种孤立状态。当恢复脚本尝试重新建立外键时,数据库拒绝了数据,因为父记录缺失,或约束的强制方式与文档所述不同。
2. 隐式连接表
ERD 中将多对多关系表示为两个表之间的直接连接。在物理实现中,这通过一个连接表来处理。恢复逻辑期望的是直接连接,并试图将数据插入错误的列中。这导致了一系列类型不匹配错误,需要手动修改模式。
3. 可空性约束
ERD 表明多个字段是可选的(可为空)。然而,生产模式随着时间推移已更新,为保证数据质量而强制要求非空值。ERD 未更新以反映这一变化。在恢复过程中,脚本试图将 NULL 值插入非空列,导致事务立即回滚。
这些差异突显了技术文档中的一个常见问题:文档漂移。随着系统演进,文档变得过时,从而产生一种虚假的安全感。
成本分析:时间 vs. 准确性 💰
三小时停机的财务影响显著,但声誉损失更高。以下是延迟期间消耗的资源明细。
| 资源 | 消耗时间 | 影响 |
|---|---|---|
| 高级工程师 | 3 小时 | 高优先级工作被从开发中转移 |
| 系统停机 | 3 小时 | 服务可用性降低了15% |
| 数据核对 | 1.5小时 | 需要手动验证 |
| 文档更新 | 0.5小时 | 事件后跟进 |
该表格表明,大部分成本并非来自恢复操作本身,而是来自纠正恢复过程的纠正。如果ERD准确无误,恢复过程本可无缝进行。
技术分析:脚本失败的原因 🛠️
为了理解错误的严重性,我们必须查看恢复脚本与数据库引擎的交互方式。该脚本遵循了一个标准流程:
- 根据ERD定义创建表。
- 应用约束(主键、外键)。
- 验证完整性。
3. 插入数据。
当脚本执行到第2步时,它试图创建一个外键约束,将表A连接到表B。数据库引擎扫描了表B中的现有数据。它发现了一些违反约束的记录,因为缺少父键。由于脚本被设计为幂等且安全,因此选择停止而非破坏数据。这一安全特性虽然有利于数据完整性,却成为了恢复时间线的阻碍。
在表B的数据被清理之前,脚本无法继续。清理数据需要:
- 识别孤立记录。
- 决定是删除它们,还是创建虚拟父记录。
- 手动执行清理操作。
- 重新运行约束创建。
这个链条中的每一步都会增加时间。ERD应在设计阶段就标记出孤立数据的潜在风险,从而促使制定数据迁移策略,而不是简单的模式复制。
经验教训:强化模式生命周期 🔄
事件发生后,我们启动了对模式管理实践的严格审查。我们意识到,仅依赖静态文档进行灾难恢复是不够的。我们需要一种动态的、版本控制的模式设计方法。
以下是此次事件的关键教训:
- 文档即代码: ERD 不是一个独立的产物;它是代码库的一部分。它必须像应用逻辑一样,经历相同的版本控制和审查流程。
- 模式漂移检测: 我们实施了自动化工具,将实时数据库模式与版本化的ERD进行比对。任何偏差都会立即触发警报。
- 恢复测试: 我们现在每季度在沙箱环境中进行恢复演练。这确保了ERD能准确反映恢复路径。
- 约束放宽: 我们调整了恢复脚本,使其在初始数据加载期间临时禁用外键约束,仅在所有数据验证完成后才重新启用。
ERD维护的最佳实践 📝
为防止未来再次出现延迟,我们制定了一套维护实体关系图的最佳实践。这些步骤确保蓝图在整个系统生命周期中始终保持有效。
1. 图表的版本控制
将ERD文件与源代码存储在同一个代码仓库中。每次发布都用对应的图表版本进行标记。这使得工程师可以在任何时间点获取模式的精确状态。
2. 自动化生成
尽可能从数据库模式直接生成ERD,而不是手动绘制。这可以减少人为错误的发生,并确保图表始终与实际情况一致。
3. 定期审计
每季度安排一次ERD审计。将图表与生产环境进行比对。记录任何在标准部署流程之外做出的更改。
4. 包含数据迁移说明
ERD不应仅展示表,还应展示数据的历史。用注释标注可能成为孤立或遗留数据的部分。这能让恢复团队预期到异常情况。
5. 在冲刺规划中进行审查
当新功能需要数据库变更时,ERD必须在同一工单中更新。不允许在没有相应图表更新的情况下部署模式变更。
技术错误中的人为因素 🧑💻
很容易将责任归咎于图表或脚本,但根本原因往往是沟通不畅。添加新字段的开发者没有更新图表,审查代码的工程师也没有检查模式文档。
技术流程的强弱取决于执行它们的人。我们引入了部署检查清单,其中包含模式验证步骤。每次部署都必须包含一份差异报告,显示数据库结构的变更。这迫使模式修改过程保持透明。
关于韧性的最终思考 🏗️
灾难恢复衡量的是我们的准备程度,而不仅仅是应对能力。三小时的延迟只是更大问题的症状:设计与实现之间的脱节。通过将实体关系图视为我们基础设施中一个动态、活跃的组成部分,我们可以显著缩短恢复时间。
数据完整性不是一项功能,而是一项基础。当这一基础出现裂痕时,整个结构都将面临风险。确保我们的蓝图准确无误,是迈向弹性架构的第一步。我们必须在文档上投入与编写代码同等的时间。
可操作事项摘要 ✅
- 审核当前的ERD:立即对照实时模式比对所有文档。
- 更新脚本:修改灾难恢复脚本,使其能够优雅地处理约束违规情况。
- 培训团队:确保所有工程师都理解模式文档的重要性。
- 自动化检查:实施能够对模式漂移发出警报的工具。
- 模拟故障:定期开展灾难恢复演练,以检验文档的准确性。
通过遵循这些实践,我们可以确保未来事件在几分钟内而非数小时内得到解决。准确性的成本远低于纠正错误的成本。