











सॉफ्टवेयर आर्किटेक्चर के विकास में, ऐतिहासिक डेटा मॉडलिंग और आधुनिक स्केलेबिलिटी की आवश्यकताओं के बीच तनाव के बराबर चुनौतियाँ कम ही हैं। बहुत संगठन अपने बैकएंड सिस्टम को प्रबंधित करते हुए पाते हैं जो कई वर्षों पहले डिज़ाइन किए गए एंटिटी रिलेशनशिप डायग्राम (ERD) पर आधारित हैं, जो आमतौर पर लोड, समानांतरता और हार्डवेयर के बारे में अलग मान्यताओं के तहत बनाए गए थे। जब एक पुराना स्कीमा उच्च-प्रतिक्रिया आवश्यकताओं का सामना करता है, तो प्रदर्शन में गिरावट केवल एक असुविधा नहीं है; यह एक संरचनात्मक विफलता है। यह मार्गदर्शिका इन आरेखों को अनुकूलित करने की तकनीकी वास्तविकताओं का अध्ययन करती है, बिना उनके भीतर निहित व्यापार तर्क को छोड़े।
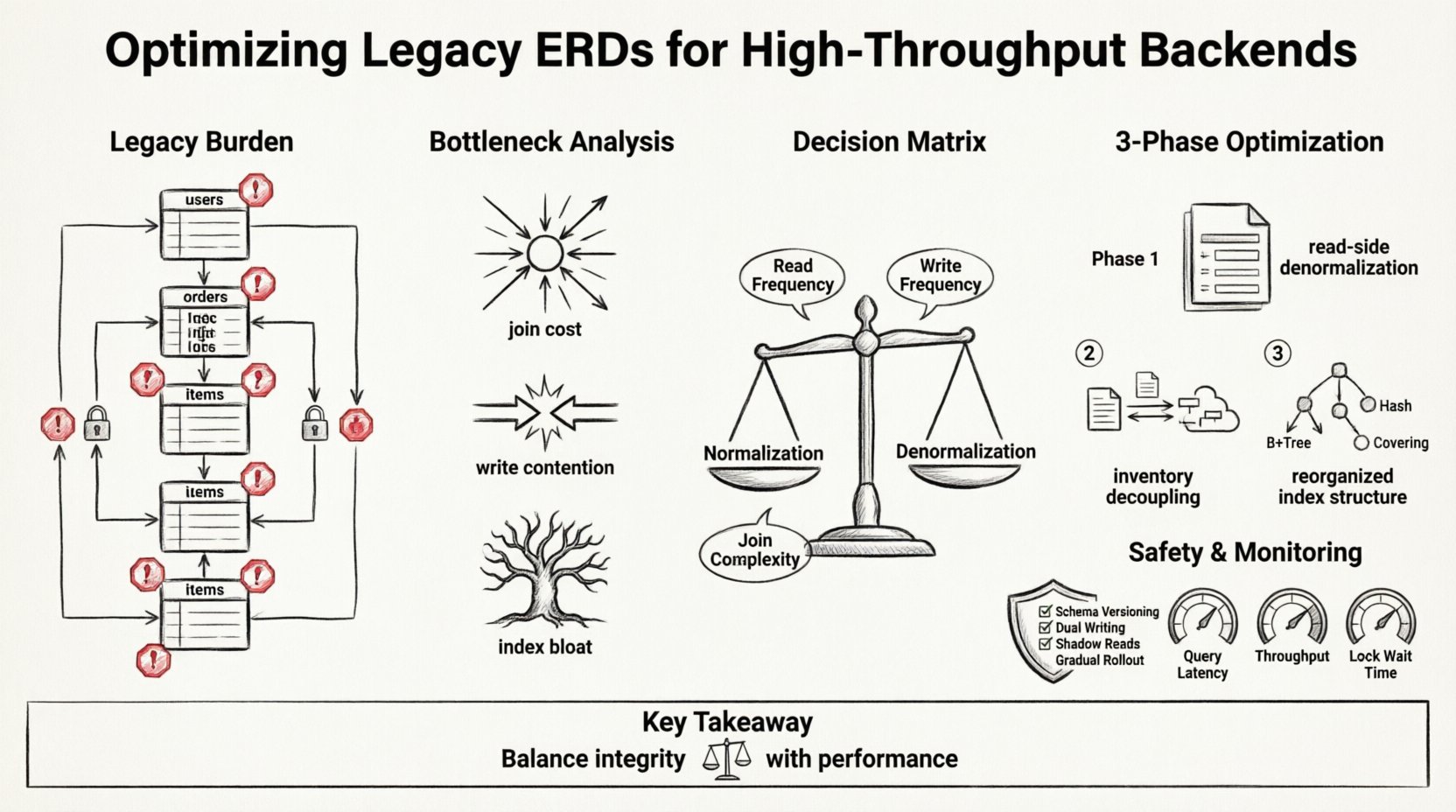
विरासत के बोझ को समझना 💾
पुराने ERD अक्सर भूतकाल की आवश्यकताओं को दर्शाते हैं। इनका प्राथमिकता डेटा अखंडता और सामान्यीकरण को सबसे ऊपर रखता है। मध्यम ट्रैफिक वाले एकल नोड वातावरण में, यह दृष्टिकोण अच्छा काम करता है। तृतीय विनियमित रूप (3NF) का कठोर अनुपालन अतिरेक को कम करता है और संगतता सुनिश्चित करता है। हालांकि, जब प्रणाली प्रति सेकंड मिलियन लेनदेन तक पहुंचती है, तो इन संबंधों की लागत असहनीय हो जाती है।
पुराने स्कीमा में पाए जाने वाली निम्नलिखित सामान्य विशेषताओं पर विचार करें:
- गहन जॉइन श्रृंखलाएँ:एक ही रिकॉर्ड प्राप्त करने के लिए पांच या अधिक जॉइन की आवश्यकता वाले प्रश्न।
- भारी विदेशी कुंजी प्रतिबंध:कठोर अखंडता जांच जो समानांतर लेखन को रोकती है।
- केंद्रीकृत लॉकिंग:विशिष्ट तालिकाओं पर गर्म बिंदु जो शीर्ष भार के दौरान बॉटलनेक बन जाते हैं।
- असामान्यीकरण के अंतराल:पढ़ने वाले ऑपरेशन के लिए अतिरिक्त डेटा स्टोर की कमी।
इन पैटर्न को आंतरिक रूप से “गलत” नहीं कहा जा सकता है। उनके समय के लिए वे सही थे। चुनौती इन्हें एक वितरित, उच्च-समानांतर परिवेश में अनुकूलित करने में है, जहां लेटेंसी मुख्य मुद्रा है।
बॉटलनेक्स का विश्लेषण 🔍
आरेख में बदलाव करने से पहले, यह समझना आवश्यक है कि प्रणाली कहाँ प्रदर्शन की हानि करती है। उच्च-प्रतिक्रिया बैकएंड अक्सर I/O ऑपरेशन, सेवाओं के बीच नेटवर्क लेटेंसी और लॉक प्रतिस्पर्धा द्वारा सीमित होते हैं। ERD डेटा के प्राप्त करने के तरीके को निर्धारित करता है, जो इन मापदंडों को सीधे प्रभावित करता है।
1. जॉइन लागतें
प्रत्येक जॉइन एक डिस्क पढ़ाई और एक CPU साइकिल है। एक पुराने सिस्टम में, एक उपयोगकर्ता प्रोफाइल के लिए एक अनुरोध एक विस्तार के रूप में पांच तालिकाओं में खोज को ट्रिगर कर सकता है। जैसे-जैसे ट्रैफिक बढ़ता है, डेटाबेस रिलेशनशिप के नेविगेशन में अधिक समय बिताता है, ताकि तर्क को निष्पादित करने में। यह तब विशेष रूप से सच होता है जब इंडेक्स पूरी जॉइन पथ को कवर नहीं कर सकते।
2. लेखन प्रतिस्पर्धा
सामान्यीकरण के लिए डेटा को अखंडता बनाए रखने के लिए बहुत स्थानों पर लिखना आवश्यक होता है। यदि एक लेनदेन उपयोगकर्ता प्रोफाइल को अपडेट करता है और एक गतिविधि घटना को लॉग करता है, तो दो तालिकाओं को संशोधित करना होगा। यदि इन तालिकाओं को एक ही श्रेणी पर रखा गया है, तो लॉक की अवधि बढ़ जाती है। यदि वे वितरित हैं, तो लेनदेन दो चरणों वाले कॉमिट में बदल जाता है, जिससे महत्वपूर्ण ओवरहेड आता है।
3. इंडेक्स ब्लोट
जटिल जॉइन के समर्थन के लिए, पुराने सिस्टम इंडेक्स एकत्र करते हैं। समय के साथ, इन इंडेक्स के लिए लेखन ऑपरेशन धीमे हो जाते हैं। डेटाबेस को हर इंसर्ट या अपडेट पर प्रत्येक इंडेक्स को अपडेट करना होता है। उच्च-प्रतिक्रिया दशाओं में, इस लेखन विस्तारण के कारण स्टोरेज सबसिस्टम संतृप्त हो सकता है।
पुनर्गठन रणनीति: सामान्यीकरण बनाम असामान्यीकरण ⚖️
अनुकूलन का केंद्र डेटा अखंडता और प्रश्न गति के बीच व्यापार के पुनर्विचार में है। जबकि कठोर सामान्यीकरण संगतता सुनिश्चित करता है, उच्च प्रदर्शन वाली प्रणालियाँ अक्सर व्यावहारिक असामान्यीकरण की आवश्यकता महसूस करती हैं। इसका अर्थ ढांचे को छोड़ना नहीं है; यह लेटेंसी को कम करने के लिए अतिरेक स्वीकार करना है।
निम्नलिखित तालिका स्कीमा बदलाव के लिए निर्णय मैट्रिक्स को चित्रित करती है:
| मापदंड | सामान्यीकृत रखें | असामान्यीकरण लागू करें |
|---|---|---|
| पढ़ने की आवृत्ति | कम (बैच प्रोसेसिंग) | उच्च (रियल-टाइम डैशबोर्ड्स) |
| लेखन आवृत्ति | उच्च (मुख्य लेनदेन) | निम्न (ऑडिट लॉग्स) |
| सुसंगतता आवश्यकता | मजबूत ACID | अंततः सुसंगतता स्वीकार्य है |
| जॉइन कठिनाई | सरल (1-2 जॉइन्स) | जटिल (3+ जॉइन्स) |
| डेटा अस्थिरता | स्थिर (संदर्भ डेटा) | गतिशील (उपयोगकर्ता अवस्था) |
इस रणनीति को लागू करने के लिए सावधानीपूर्वक योजना बनाने की आवश्यकता होती है। आप सिर्फ टेबलों को बदल रहे हैं; आप ऐप्लिकेशन द्वारा डेटा को देखने के तरीके को बदल रहे हैं।
केस स्टडी वॉकथ्रू: ई-कॉमर्स लेनदेन इंजन 🛒
इस प्रक्रिया को समझाने के लिए एक काल्पनिक ई-कॉमर्स प्लेटफॉर्म को लें। पुराना सिस्टम ऑर्डर प्रोसेसिंग, इन्वेंट्री मैनेजमेंट और ग्राहक प्रोफाइल को संभालता है। ईआरडी को एकल डेटाबेस इंस्टेंस के लिए डिज़ाइन किया गया था, जिसमें स्टॉक के अतिरिक्त बिक्री को रोकने पर ध्यान केंद्रित किया गया था।
पुरानी स्थिति
मूल डिज़ाइन में, ऑर्डर्स टेबल ने ऑर्डर आइटम्स, जिसने उत्पादों. द उत्पादों टेबल ने इन्वेंट्री. ऑर्डर विवरण पृष्ठ दिखाने के लिए, बैकएंड ने सभी चार टेबल्स को जोड़ने वाला क्वेरी निष्पादित किया। साथ ही, प्रत्येक ऑर्डर अपडेट के लिए इन्वेंट्री टेबल पर लॉक लगाने की आवश्यकता होती थी ताकि सटीकता सुनिश्चित हो सके।
पहचाने गए मुख्य मुद्दे:
- लेटेंसी: बिक्री घटनाओं के दौरान पृष्ठ लोड समय 800ms तक बढ़ गया।
- डेडलॉक्स:इन्वेंट्री अपडेट पर उच्च समानांतरता के कारण लेनदेन वापस ले लिए गए।
- स्केलेबिलिटी: डेटाबेस ने शेयर करने में असमर्थ रहा
इन्वेंट्रीतालिका के कारण अक्सर क्रॉस-शेयर जॉइन के कारण।
अनुकूलन प्रक्रिया
टीम ने तीन चरणों में ईआरडी को पुनर्गठित करने का निर्णय लिया। लक्ष्य पढ़ने के मार्गों को लेखन मार्गों से अलग करना था।
चरण 1: पढ़ने के पक्ष का अनियमितता
पहला चरण ऑर्डर रिकॉर्ड्स के भीतर उत्पाद डेटा की एक स्नैपशॉट बनाने में शामिल था। प्रश्न समय जॉइन करने के बजाय उत्पाद तालिका के समय, सिस्टम ने उत्पाद का नाम, मूल्य और एसकेयू को ऑर्डर आइटम तालिका में खरीदारी के समय कॉपी किया।
- लाभ: ऑर्डर इतिहास बाद में उत्पाद डेटा बदलने पर भी सटीक रहता है।
- लाभ: प्रश्न को अब उत्पाद तालिका में जॉइन करने की आवश्यकता नहीं है।
- जोखिम: यदि ऑर्डर दर्ज करने के बाद उत्पाद को अपडेट किया जाता है तो मूल्य में अंतर हो सकता है।
- उपाय: यूआई खरीदारी के समय मूल्य को “ऐतिहासिक मूल्य” के रूप में प्रदर्शित करता है।
चरण 2: इन्वेंट्री का अलगाव
इन्वेंट्री तालिका विवाद का स्रोत थी। टीम ने इन्वेंट्री ट्रैकिंग को अलग, उच्च आवृत्ति लेखन स्टोर में स्थानांतरित कर दिया। ऑर्डर सिस्टम एक सिंक्रोनस एसक्यूएल लॉक निष्पादित करने के बजाय एक असिंक्रोनस संदेश भेजकर स्टॉक आरक्षित करता है।
- लाभ:लेखन थ्रूपुट में 400% की वृद्धि हुई।
- लाभ: मुख्य ऑर्डर लेनदेन पर अब ब्लॉकिंग नहीं होती है।
- व्यापार लाभ: स्टॉक अस्थायी रूप से असंगत होने पर भी ऑर्डर देने जा सकते हैं।
- उपाय: एक बैकग्राउंड प्रक्रिया ऑर्डर प्रणाली और स्टॉक के बीच अंतरों को सुलझाती है।
चरण 3: सूचकांक पुनर्गठन
अनियमित डेटा के साथ, विदेशी कुंजियों पर पुराने सूचकांक अतिरिक्त हो गए। टीम ने उन्हें हटा दिया और नए प्रश्न पैटर्न के लिए अनुकूलित संयुक्त सूचकांक जोड़े। उदाहरण के लिए, (ग्राहक_id, बनाए गए_समय) पूरे ऑर्डर तालिका को स्कैन करने की आवश्यकता को बदल दिया।
कार्यान्वयन चरण और सुरक्षा 🛡️
लाइव स्कीमा में बदलाव करना एक उच्च जोखिम वाला कार्य है। निम्नलिखित चरण संक्रमण के दौरान स्थिरता सुनिश्चित करते हैं।
1. स्कीमा संस्करण
पुराने कॉलम को तुरंत हटाएं नहीं। उन्हें जगह पर रखें लेकिन उन्हें अप्रचलित चिह्नित करें। यह अनुप्रयोग को वापस ले जाने की अनुमति देता है यदि नई तर्कसंगतता विफल हो जाती है। कॉलम को हटाने से पहले उन्हें जोड़ने वाले माइग्रेशन स्क्रिप्ट का उपयोग करें।
2. दोहरा लेखन
संक्रमण के दौरान, डेटा को पुरान strucutre और नए संरचना दोनों में लिखें। अनुप्रयोग तर्क पढ़ने को नए संरचना की ओर रूट करता है, लेकिन लेखन दोनों में जाता है। यह एक फॉलबैक प्रदान करता है यदि नया स्कीमा अपूर्ण है।
3. छाया पढ़ना
लाइव ट्रैफिक को रीडायरेक्ट करने से पहले, उत्पादन डेटा की एक प्रति पर नए प्रश्न चलाएं। पुराने प्रश्नों के परिणामों की तुलना अनुकूलित प्रश्नों के परिणामों से करें ताकि डेटा सटीकता सुनिश्चित हो।
4. धीरे-धीरे लॉन्च
नए स्कीमा को छोटे प्रतिशत उपयोगकर्ताओं (उदाहरण के लिए, 1%) के लिए सक्षम करने के लिए फीचर फ्लैग का उपयोग करें। त्रुटि दर और लेटेंसी को मॉनिटर करें। यदि मापदंड स्थिर रहते हैं, तो प्रतिशत को धीरे-धीरे बढ़ाएं।
निगरानी और मान्यता 📊
अनुकूलन एक बार का कार्य नहीं है। यह लोड के तहत बदलावों के रहने की गारंटी देने के लिए निरंतर निगरानी की आवश्यकता होती है। रिफैक्टरिंग शुरू करने से पहले महत्वपूर्ण प्रदर्शन सूचकांक (KPIs) को स्थापित करना आवश्यक है।
ट्रैक करने के लिए मुख्य मापदंड:
- प्रश्न लेटेंसी: 95वें और 99वें पर्सेंटाइल प्रतिक्रिया समय।
- थ्रूपुट: त्रुटियों के बिना प्रति सेकंड लेनदेन (TPS)।
- लॉक प्रतीक्षा समय: एक लेनदेन द्वारा लॉक के लिए प्रतीक्षा करने वाला औसत समय।
- प्रतिलिपि देरी: प्राथमिक और प्रतिलिपि नोड्स के बीच देरी (यदि लागू हो)।
- कैश हिट अनुपात: पठन कैशिंग रणनीतियों की प्रभावकारिता।
चेतावनी के सीमा को परिवर्तनों से पहले collected बेसलाइन मेट्रिक्स के आधार पर सेट करना चाहिए। यदि लेटेंसी बढ़ती है, तो सिस्टम को स्वचालित रूप से पुराने स्कीमा में वापस लौटना चाहिए या ट्रैफिक को एक फॉलबैक सेवा में रूट करना चाहिए।
बचने के लिए सामान्य गलतियाँ ⚠️
एक मजबूत योजना के साथ भी, तकनीकी ऋण अक्सर अप्रत्याशित तरीकों से वापस आता है। इन सामान्य गलतियों के बारे में जागरूक रहें।
- डेटा माइग्रेशन लागत को नजरअंदाज करना:नए संरचनाओं में टेराबाइट्स डेटा ले जाने में समय लगता है। मेंटेनेंस विंडो या बैकग्राउंड माइग्रेशन टूल्स की योजना बनाएं।
- पढ़ने के लिए अत्यधिक अनुकूलन करना: यदि आप अत्यधिक डेनॉर्मलाइज़ करते हैं, तो लेखन प्रदर्शन प्रभावित होगा। अपने विशिष्ट वर्कलोड के पढ़ने/लेखन अनुपात को संतुलित करें।
- एप्लिकेशन लॉजिक को भूल जाना: स्कीमा परिवर्तन केवल आधा युद्ध है। एप्लिकेशन कोड को नए डेटा संरचना को हैंडल करने के लिए अपडेट किया जाना चाहिए।
- परीक्षण को नजरअंदाज करना: यूनिट परीक्षण अक्सर हैप्पी पाथ को कवर करते हैं। नए स्कीमा में रेस कंडीशन खोजने के लिए स्ट्रेस परीक्षण आवश्यक हैं।
लंबे समय तक रखरखाव की रणनीतियाँ 🔧
जब अनुकूलन पूरा हो जाता है, तो टीम को नए आर्किटेक्चर का रखरखाव करना होता है। दस्तावेज़ीकरण आवश्यक है। प्रत्येक टेबल, कॉलम और संबंध को उसके उद्देश्य और मालिकाना हक के साथ टैग किया जाना चाहिए।
नियमित ऑडिट:
ईआरडी की तिमाही समीक्षा की योजना बनाएं। ऐसी टेबलों को पहचानें जो अनुपात से अधिक बढ़ रही हैं या प्रश्न धीमे हो रहे हैं। डेटाबेस वृद्धि अक्सर नए बॉटलनेक्स को उजागर करती है जो प्रारंभिक रिफैक्टरिंग के दौरान मौजूद नहीं थे।
स्वचालित स्कीमा जांच:
स्कीमा सत्यापन को सीआई/सीडी पाइपलाइन में एकीकृत करें। विकासकर्मियों को बिना अनुमति के नए जॉइन जोड़ने या महत्वपूर्ण सीमाओं को हटाने से रोकें। इससे यह सुनिश्चित होता है कि सिस्टम समय के साथ अनुकूलित रहता है।
टीम प्रशिक्षण:
सुनिश्चित करें कि सभी बैकएंड इंजीनियर नए डेटा मॉडल को समझते हैं। स्कीमा के बारे में साझा समझ अस्थायी प्रश्नों के माध्यम से नए तकनीकी ऋण के उद्भव की संभावना को कम करती है।
डेटा मॉडलिंग पर अंतिम विचार 🔗
पुराने एंटिटी रिलेशनशिप डायग्राम को अनुकूलित करना ऐतिहासिक सटीकता और भविष्य की स्केलेबिलिटी के बीच संतुलन बनाने का काम है। कोई एक “सही” स्कीमा नहीं है। सही मॉडल वह है जो आपके वर्तमान व्यापार लक्ष्यों का समर्थन करता है और वृद्धि के लिए जगह छोड़ता है।
अपने सिस्टम के विशिष्ट बॉटलनेक्स पर ध्यान केंद्रित करके—चाहे वे जॉइन लागत हों, लॉक प्रतिस्पर्धा हो या इंडेक्स ब्लॉट—आप लक्षित सुधार कर सकते हैं। केस स्टडी यह दिखाती है कि भले ही संरचना गहराई से जड़ी हुई हो, एक पूरी रीराइटिंग के बिना भी उसे आधुनिक बनाया जा सकता है। मुख्य बात यह है कि विधिपूर्वक आगे बढ़ें, तीव्रता से मान्यता दें, और शामिल व्यापार विकल्पों को स्पष्ट रूप से बनाए रखें।
डेटा मॉडलिंग स्थिर नहीं है। यह उस ट्रैफिक के साथ विकसित होती है जिसे यह सेवा करती है। अपने ईआरडी को एक जीवित दस्तावेज़ के रूप में लें जिसे उस कोड के जैसे ही देखभाल और ध्यान देने की आवश्यकता होती है जो इसके बारे में प्रश्न पूछता है। सही दृष्टिकोण के साथ, आप एक पुराने सिस्टम को एक उच्च प्रदर्शन इंजन में बदल सकते हैं जो आधुनिक वेब की मांगों को संभाल सकता है।