











सॉफ्टवेयर आर्किटेक्चर की दुनिया में, एंटिटी रिलेशनशिप डायग्राम (ERD) के बराबर कोई अवधारणा इतना महत्वपूर्ण नहीं है। यह आपके डेटा का ब्लूप्रिंट है, वह नक्शा जो डेवलपर्स को टेबल, कीज़ और संबंधों के जटिल माहौल में रास्ता दिखाता है। जब कोई एप्लिकेशन धीमी होती है, तो पहली प्रतिक्रिया अक्सर स्कीमा को दोषी ठहराने की होती है। धारणा स्पष्ट है: अगर डायग्राम सही है, तो प्रदर्शन भी निश्चित रूप से सही होना चाहिए।
यह एक सामान्य गलतफहमी है। 🧐 जबकि एक अच्छी तरह से डिज़ाइन किया गया ERD आधारभूत है, यह गति के लिए एक सोने की गोली नहीं है। एक निर्दोष तार्किक मॉडल बिना बात के उच्च गति वाले भौतिक कार्यान्वयन में बदल नहीं जाता है। डिज़ाइन सिद्धांत और रनटाइम वास्तविकता के बीच के अंतर को समझना तब आवश्यक है जब दबाव में भी प्रतिक्रियाशील तंत्र बनाए जाएं।
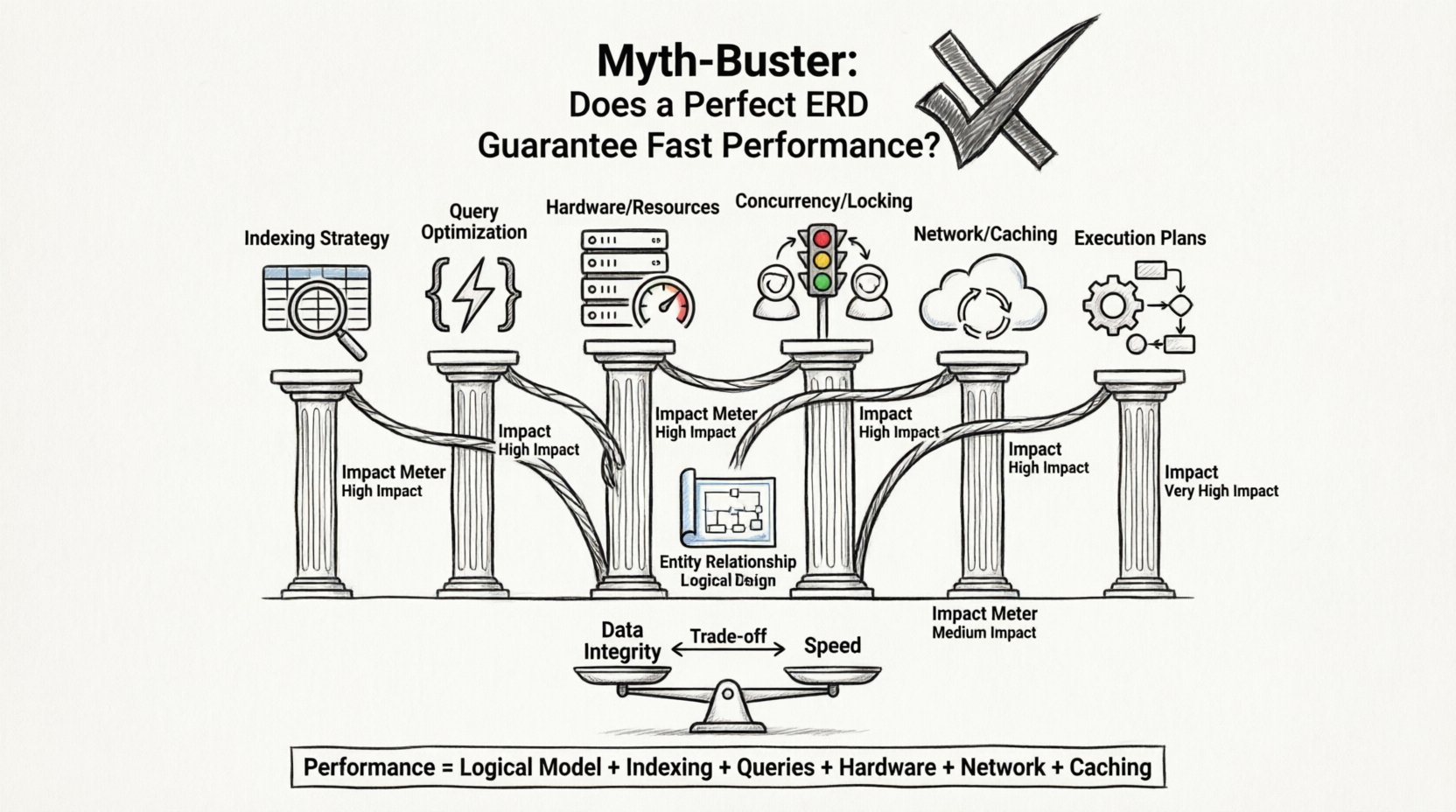
यह गाइड यह समझने का प्रयास करता है कि क्यों एक सही ERD तेज प्रतिक्रिया समय की गारंटी नहीं देता है और कौन से अन्य महत्वपूर्ण कारक डेटाबेस प्रदर्शन को प्रभावित करते हैं। हम डेटा हैंडलिंग की परतों को विश्लेषित करेंगे, स्टोरेज इंजन से लेकर नेटवर्क लेटेंसी तक, ताकि एप्लिकेशन गति के वास्तविक चालक बातें सामने आएं।
📐 एंटिटी रिलेशनशिप डायग्राम को समझना
प्रदर्शन मापदंडों में डूबने से पहले, हमें स्पष्ट करना होगा कि ERD वास्तव में क्या प्रतिनिधित्व करता है। ERD एक तार्किक कृत्रिम वस्तु है। यह वर्णन करता है क्या डेटा मौजूद है और कैसे यह अन्य डेटा से संबंधित है। यह एंटिटी (टेबल), एट्रिब्यूट (कॉलम) और संबंध (फॉरेन कीज़) को परिभाषित करता है।
- एंटिटीज़:ताबलों के रूप में दर्शाए गए वास्तविक दुनिया की वस्तुएं।
- एट्रिब्यूट्स:उन वस्तुओं के लक्षण जो कॉलम में संग्रहीत होते हैं।
- संबंध:एंटिटीज़ के बीच के लिंक, जो अक्सर प्राइमरी और फॉरेन कीज़ के माध्यम से बल द्वारा लागू किए जाते हैं।
- कार्डिनैलिटी:एंटिटीज़ के बीच संख्यात्मक संबंध (एक-एक, एक-बहुत)।
ERD का मुख्य लक्ष्य डेटा अखंडता है। यह सुनिश्चित करता है कि डेटा समय के साथ संगत, सटीक और उपयोगी बना रहे। यह ओर्फन रिकॉर्ड को रोकता है और संदर्भात्मक अखंडता बनाए रखता है। हालांकि, अखंडता वेग के बराबर नहीं है। एक ताला जो दरवाजे को बंद रखता है, अंदर की वस्तुओं की रक्षा करता है, लेकिन दरवाजे को तेजी से खोलने में मदद नहीं करता है।
⚡ प्रदर्शन समीकरण: स्कीमा से परे
एप्लिकेशन प्रतिक्रिया समय कई घटकों का योग है। डेटाबेस इस समीकरण का केवल एक हिस्सा है। भले ही डेटाबेस इंजन डेटा तुरंत प्राप्त कर ले, लेकिन अन्य जगहों पर बॉटलनेक्स के कारण एप्लिकेशन अभी भी धीमी महसूस कर सकती है।
यहां गति को प्रभावित करने वाले मुख्य कारक हैं, जो अक्सर स्कीमा डिज़ाइन को छांव में छोड़ देते हैं:
1. इंडेक्सिंग रणनीति
एक ERD प्राइमरी कीज़ और फॉरेन कीज़ को परिभाषित करता है, जो अक्सर स्वचालित रूप से इंडेक्स बनाते हैं। हालांकि, इन डिफ़ॉल्ट इंडेक्स का जटिल क्वेरी के लिए बहुत कम पर्याप्त होता है। प्रदर्शन को विशिष्ट क्वेरी पैटर्न के लिए अनुकूलित द्वितीयक इंडेक्स पर भारी निर्भरता होती है।
- गायब इंडेक्स:अक्सर फिल्टर किए जाने वाले कॉलम पर इंडेक्स न होने पर, डेटाबेस को पूरी टेबल स्कैन करना होता है। यह हर पंक्ति को पढ़ता है, जो बड़े डेटासेट पर एक्सपोनेंशियल रूप से धीमा होता है।
- इंडेक्स ओवरहेड:बहुत सारे इंडेक्स लिखने वाले ऑपरेशन को धीमा कर देते हैं। प्रत्येक इन्सर्ट या अपडेट के लिए उस टेबल से जुड़े हर इंडेक्स को अपडेट करना होता है।
- चयनशीलता:कम चयनशीलता वाले कॉलम (जैसे लिंग या स्थिति) पर इंडेक्स को क्वेरी ऑप्टिमाइज़र द्वारा नजरअंदाज किया जा सकता है।
2. प्रश्न अनुकूलन
डेटा के अनुरोध का तरीका उसके भंडारण के तरीके से अधिक महत्वपूर्ण है। खराब तरीके से लिखे गए प्रश्न एक आदर्श स्कीमा को भी बर्बाद कर सकते हैं। सामान्य समस्याएं इस प्रकार हैं:
- एन+1 समस्याएं:एक मुख्य रिकॉर्ड को खींचना और फिर उसके माध्यम से लूप करके बच्चों को अलग-अलग खींचना। इससे एकल JOIN के बजाय डेटाबेस में बहुत सारे राउंड ट्रिप उत्पन्न होते हैं।
- SELECT * का उपयोग:सभी कॉलम को प्राप्त करने से नेटवर्क ट्रैफिक और मेमोरी उपयोग बढ़ जाता है, भले ही केवल एक की आवश्यकता हो।
- गुप्त रूपांतरण:एक स्ट्रिंग की संख्या से तुलना या एक तारीख का समयचिह्न से तुलना करने से इंडेक्स के उपयोग को रोका जा सकता है।
- जटिल JOINs:उचित फ़िल्टरिंग के बिना बड़ी तालिकाओं को जोड़ने से गणनात्मक भार में काफी वृद्धि होती है।
3. हार्डवेयर और इंफ्रास्ट्रक्चर
सॉफ्टवेयर की कुशलता भौतिक सीमाओं को पार नहीं कर सकती है। नीचे वाला हार्डवेयर प्रदर्शन के ऊपरी सीमा को निर्धारित करता है।
- स्टोरेज प्रकार:यादृच्छिक I/O संचालन के लिए सॉलिड स्टेट ड्राइव (SSD) हार्ड डिस्क ड्राइव (HDD) की तुलना में काफी तेज हैं।
- मेमोरी (RAM):यदि डेटा का कार्यात्मक सेट RAM में फिट होता है, तो प्रश्न लगभग तुरंत होते हैं। यदि डेटा डिस्क से खींचना होता है, तो लेटेंसी बढ़ जाती है।
- सीपीयू शक्ति:जटिल गणनाएं, व्यवस्था और समग्री के लिए प्रोसेसिंग शक्ति की आवश्यकता होती है।
- नेटवर्क लेटेंसी:एप्लीकेशन सर्वर और डेटाबेस सर्वर के बीच की दूरी प्रत्येक अनुरोध में मिलीसेकंड जोड़ती है।
4. समानांतरता और लॉकिंग
जब एक साथ कई उपयोगकर्ता प्रणाली का उपयोग करते हैं, तो डेटाबेस को संघर्षों का प्रबंधन करना होता है। यहीं प्रदर्शन अक्सर घटता है।
- लॉक प्रतिस्पर्धा:यदि एक लेनदेन एक पंक्ति पर लॉक रखता है, तो अन्य को इंतजार करना होता है। उच्च प्रतिस्पर्धा समय सीमा समाप्त होने और धीमी प्रतिक्रिया समय के कारण होती है।
- मृत अवरोध:एक दूसरे का इंतजार कर रहे दो लेनदेन के कारण पूरी प्रणाली रुक सकती है।
- आइसोलेशन स्तर:उच्च आइसोलेशन स्तर (उदाहरण के लिए, सीरियलाइजेबल) अधिक मजबूत गारंटी प्रदान करते हैं, लेकिन समानांतरता और गति को कम करते हैं।
📊 ईआरडी प्रभाव अन्य प्रदर्शन कारकों की तुलना में
ईआरडी के अन्य चरों की तुलना में प्रभाव को दृश्याकृत करने के लिए निम्नलिखित विभाजन पर विचार करें। यह तालिका दिखाती है कि ईआरडी कहां मूल्य प्रदान करती है और कहां वह कमजोर है।
| कारक | पढ़ने की गति पर प्रभाव | लेखन गति पर प्रभाव | ERD की भूमिका |
|---|---|---|---|
| तालिका स्कीमा संरचना | मध्यम | मध्यम | संबंधों और सामान्यीकरण को परिभाषित करता है। |
| インडेक्सिंग | उच्च | निम्न | ERD कुंजियों को परिभाषित करता है, लेकिन सभी इंडेक्स नहीं। |
| प्रश्न तर्क | बहुत उच्च | मध्यम | ERD प्रश्न सिंटैक्स का निर्देश नहीं देता है। |
| हार्डवेयर संसाधन | उच्च | उच्च | कोई नहीं। स्कीमा से स्वतंत्र। |
| नेटवर्क लेटेंसी | उच्च | मध्यम | कोई नहीं। स्कीमा से स्वतंत्र। |
| कनेक्शन पूलिंग | मध्यम | मध्यम | कोई नहीं। एप्लिकेशन कॉन्फ़िगरेशन। |
🧱 सामान्यीकरण का व्यापार लाभ
डेटाबेस डिजाइन में सबसे अधिक चर्चा की जाने वाली विषयों में से एक सामान्यीकरण है। ERD आमतौर पर अतिरिक्त दोहराव को कम करने के लिए तृतीय सामान्य रूप (3NF) की ओर ध्यान केंद्रित करता है। यह स्थान बचाता है और सुसंगतता सुनिश्चित करता है, लेकिन यह प्रदर्शन को नुकसान पहुंचा सकता है।
जब डेटा बहुत अधिक सामान्यीकृत होता है, तो एक ही जानकारी एक ही स्थान पर संग्रहीत होती है। इसे प्राप्त करने के लिए, प्रणाली को कई JOINs के माध्यम से गुजरना होता है। प्रत्येक JOIN गणनात्मक ओवरहेड जोड़ता है।
एक ऐसे परिदृश्य पर विचार करें जहां आपको एक उपयोगकर्ता के प्रोफाइल के साथ उनका नवीनतम ऑर्डर और उत्पाद विवरण प्रदर्शित करने की आवश्यकता है। एक सामान्यीकृत ERD में, इसके लिए चार तालिकाओं को जोड़ने की आवश्यकता हो सकती है। यदि इन तालिकाओं का आकार बड़ा है, तो CPU को पंक्तियों को व्यवस्थित करने और मिलान करने में महत्वपूर्ण समय लगता है।
असामान्यीकरण इसके विरोध में उपयोग की जाने वाली एक तकनीक है। इसमें JOINs की आवश्यकता को कम करने के लिए डेटा की प्रतिलिपि बनाना शामिल है। इससे पढ़ने की गति में सुधार होता है, लेकिन लेखन संचालन को जटिल बनाता है और डेटा असंगति का जोखिम होता है। एक आदर्श ERD बिना खुद इस रेखा को कहां खींचना है, इसका निर्णय नहीं लेता है। यह पढ़ने/लिखने के अनुपात पर आधारित एक रणनीतिक निर्णय है।
🔍 गहन अध्ययन: प्रश्न क्रियान्वयन योजनाएं
डेटाबेस इंजन प्रश्नों को लिखे गए अनुसार बिल्कुल नहीं निष्पादित करता है। यह अनुरोध का विश्लेषण करता है और एक बनाता हैक्रियान्वयन योजना। इस योजना ऑपरेशन के क्रम, किन इंडेक्स का उपयोग करना है, और क्या स्कैन करना है या सीधे खोजना है, यह तय करती है।
एक ERD डेटा प्रकारों और सीमाओं के बारे में मेटाडेटा प्रदान करता है। हालांकि, ऑप्टिमाइज़र डेटा वितरण के आंकड़ों का उपयोग निर्णय लेने के लिए करता है। यदि आंकड़े अद्यतन नहीं हैं, तो ऑप्टिमाइज़र एक उपयुक्त योजना चुन सकता है, जिसमें उपलब्ध सर्वोत्तम इंडेक्स को नजरअंदाज कर दिया जाता है।
उदाहरण के लिए, यदि एक तालिका में 10 मिलियन पंक्तियां हैं, लेकिन आंकड़े के अनुसार इसमें केवल 100 हैं, तो ऑप्टिमाइज़र एक पूर्ण स्कैन को इंडेक्स खोज से सस्ता मान सकता है। इससे एक अच्छी तरह से बनी ERD के बावजूद धीमी प्रदर्शन की स्थिति बनती है।
🛡️ डेटा अखंडता बनाम गति
डेटा अखंडता सुनिश्चित करने और गति को अधिकतम करने के बीच एक आंतरिक तनाव है। एक ERD अनुबंधों और ट्रिगर्स जैसे अखंडता नियमों को लागू करता है।
- विदेशी कुंजी सीमाएं: संदर्भात्मक अखंडता सुनिश्चित करते हैं। हटाए जाने या अद्यतन करने पर, प्रणाली को संबंधित तालिकाओं की जांच करनी होती है। इससे लेखन संचालन में देरी जोड़ी जाती है।
- ट्रिगर्स: डेटा परिवर्तन पर चलने वाले स्वचालित स्क्रिप्ट। तर्क के लिए उपयोगी होने के बावजूद, वे प्रत्येक लेनदेन में प्रसंस्करण समय जोड़ते हैं।
- एकलता सीमाएं: प्रणाली को नए मानों को सम्मिलित करने से पहले मौजूदा मानों की जांच करने की आवश्यकता होती है।
उच्च थ्रूपुट प्रणालियों में, इन जांचों को कभी-कभी अक्षम कर दिया जाता है या गति में सुधार के लिए स्थगित कर दिया जाता है। एक आदर्श ERD में इन सभी नियमों को शामिल किया जाता है, लेकिन उच्च प्रदर्शन वाली प्रणाली के लिए एक संशोधित दृष्टिकोण की आवश्यकता हो सकती है।
🚦 अनुकूलन के लिए व्यावहारिक चरण
यदि आपका एप्लिकेशन धीमा है, तो तुरंत अपने ERD को फिर से बनाने की कोशिश न करें। बैंडविड्थ को पहचानने के लिए एक व्यवस्थित दृष्टिकोण का पालन करें।
1. धीमे प्रश्नों का विश्लेषण करें
लंबे समय तक चलने वाले कथनों को कैप्चर करने के लिए प्रश्न लॉगिंग सक्षम करें। समय कहां बिताया जा रहा है, इसे देखने के लिए प्रोफाइलिंग टूल्स का उपयोग करें। क्या यह लॉक के लिए प्रतीक्षा कर रहा है? क्या यह पंक्तियों को स्कैन कर रहा है? क्या यह तर्क को प्रसंस्कृत कर रहा है?
2. इंडेक्स उपयोग की समीक्षा करें
जांचें कि कौन से इंडेक्स वास्तव में उपयोग किए जा रहे हैं। अनउपयोगी इंडेक्स स्टोरेज का उपयोग करते हैं और लेखन को धीमा करते हैं। अक्सर उपयोग किए जाने वाले प्रश्नों के WHERE और JOIN क्लॉज के अनुरूप इंडेक्स बनाएं।
3. हार्डवेयर आवंटन को अनुकूलित करें
यह सुनिश्चित करें कि डेटाबेस सर्वर के पास काम करने वाले सेट को कैश करने के लिए पर्याप्त RAM है। यदि डेटाबेस मेमोरी सीमित है, तो अधिक RAM जोड़ने से तुरंत परिणाम मिलेंगे। यदि यह CPU सीमित है, तो आपको प्रोसेसर को अपग्रेड करने या कोड को अनुकूलित करने की आवश्यकता हो सकती है।
4. कैशिंग कार्यान्वित करें
प्रत्येक अनुरोध को डेटाबेस पर नहीं मारने की आवश्यकता होती है। अक्सर प्राप्त किए जाने वाले डेटा के लिए इन-मेमोरी कैश (जैसे Redis या Memcached) का उपयोग करें। इससे पढ़ने के संचालन के लिए डेटाबेस को पूरी तरह से बाहर किया जा सकता है।
5. समानांतरता का निरीक्षण करें
लॉक वेट के लिए ध्यान रखें। यदि उपयोगकर्ता समय सीमा के अनुभव कर रहे हैं, तो लेनदेन की लंबाई की समीक्षा करें। लॉक जल्दी रिलीज करने के लिए लेनदेन को छोटा रखें।
🔄 स्कीमा विकास की भूमिका
एप्लिकेशन बदलते हैं। आवश्यकताएं बदलती हैं। एरडी को व्यवसाय के साथ विकसित होना चाहिए। छह महीने पहले आदर्श रूप से बना स्कीमा आज नए फीचर्स या बढ़ी हुई डेटा मात्रा के कारण अप्रचलित हो सकता है।
माइग्रेशन रणनीतियां महत्वपूर्ण हैं। एक छोटी टेबल से एक बड़ी पार्टीशन की टेबल में डेटा ले जाने से प्रदर्शन में सुधार हो सकता है। डेटा प्रकार को VARCHAR से INTस्टोरेज को कम करने और स्कैन गति में सुधार करने में मदद कर सकता है। ये निर्णय प्रारंभिक एरडी बनाए जाने के बाद होते हैं।
स्थिर एरडी डेटा वृद्धि को ध्यान में नहीं रखते हैं। जैसे-जैसे डेटा बढ़ता है, प्रदर्शन विशेषताएं बदल जाती हैं। 10,000 रिकॉर्ड्स के साथ काम करने वाला डिज़ाइन 1 करोड़ रिकॉर्ड्स के साथ विफल हो सकता है। इसी कारण प्रदर्शन समायोजन एक निरंतर प्रक्रिया है, न कि एक बार का कार्य।
🧩 नोस्कीमा पर विचार
एरडी की अवधारणा अधिकतम रूप से संबंधित डेटाबेस पर लागू होती है। नोस्कीमा वातावरण में, डेटा मॉडल अलग होता है। दस्तावेज़ स्टोर, की-वैल्यू स्टोर और ग्राफ डेटाबेस संबंधों को अलग तरीके से संभालते हैं।
एक दस्तावेज़ स्टोर में, जॉइन से बचने के लिए डेटा एम्बेड किया जा सकता है। इससे डिज़ाइन के अनुसार डेनॉर्मलाइज़ेशन का अनुकरण होता है। एक ग्राफ डेटाबेस में, संबंध प्रथम श्रेणी के नागरिक होते हैं, जो ट्रैवर्सल को अनुकूलित करने के लिए स्पष्ट रूप से संग्रहीत किए जाते हैं।
एरडी गारंटी के मिथक की बात यहां और भी अधिक उभरती है। नोस्कीमा में, स्कीमा अक्सर लचीला या गतिशील होता है। प्रदर्शन अक्सर एप्लिकेशन कोड में परिभाषित एक्सेस पैटर्न पर निर्भर करता है, न कि एक कठोर आरेख पर।
🏁 डेटा आर्किटेक्चर पर अंतिम विचार
एक तेज़ एप्लिकेशन बनाने के लिए समग्र दृष्टिकोण की आवश्यकता होती है। एरडी एक महत्वपूर्ण शुरुआत है, जो यह सुनिश्चित करता है कि डेटा तार्किक रूप से व्यवस्थित हो। यह अव्यवस्था को रोकता है और अखंडता बनाए रखता है। हालांकि, यह गति को बढ़ाने वाली इंजन नहीं है।
प्रदर्शन निम्नलिखित के बीच सहयोग का परिणाम है:
- एक ठोस तार्किक मॉडल।
- रणनीतिक इंडेक्सिंग।
- कुशल क्वेरी लेखन।
- उचित हार्डवेयर संसाधन।
- उचित नेटवर्क कॉन्फ़िगरेशन।
- प्रभावी कैशिंग रणनीतियां।
धीमी प्रतिक्रिया समय के लिए स्कीमा को दोषी ठहराना एक त्वरित रास्ता है जो गलत ठीक करने की ओर ले जाता है। कागज पर एक आदर्श आरेख धीमी डिस्क, नेटवर्क टाइमआउट या खराब लिखी गई क्वेरी की कमी को नहीं भर सकता है। वास्तविक प्रदर्शन � ingineering में ब्लूप्रिंट के बाहर देखना और वास्तविक डेटा प्रवाह को देखना शामिल है।
जब आप अपनी प्रणाली की समीक्षा करें, तो एरडी से शुरुआत करें ताकि सही होने की जांच की जा सके। फिर दक्षता सुनिश्चित करने के लिए निष्पादन योजना पर जाएं। अंत में, क्षमता सुनिश्चित करने के लिए इंफ्रास्ट्रक्चर का मूल्यांकन करें। केवल सभी परतों को संबोधित करके ही आप उपयोगकर्ताओं की अपेक्षा के अनुरूप प्रतिक्रियाशीलता प्राप्त कर सकते हैं।