











एक विश्वसनीय डेटाबेस स्कीमा डिज़ाइन करने के लिए सटीकता की आवश्यकता होती है। एंटिटी रिलेशनशिप डायग्राम (ERD) इस संरचना के लिए ब्लूप्रिंट के रूप में कार्य करता है, जो जटिल व्यावसायिक तर्क को एक दृश्य रूप में बदलता है जिसे डेवलपर्स और स्टेकहोल्डर्स समझ सकते हैं। हालांकि, उनके उपयोगिता के बावजूद, मॉडलिंग चरण के दौरान ERD अक्सर गलतफहमी के कारण बन जाते हैं। प्रतीकों में अस्पष्टता, कार्डिनैलिटी के गलत अर्थ निकालना और विशेषता प्रकारों के संबंध में भ्रम विकास चक्र के बाद के चरणों में महत्वपूर्ण पुनर्निर्माण के कारण बन सकता है।
यह मार्गदर्शिका डेटाबेस आर्किटेक्ट्स और इंजीनियर्स के बीच आमतौर पर तनाव पैदा करने वाले ERD के विशिष्ट घटकों का विस्तृत विश्लेषण प्रदान करती है। मजबूत और कमजोर एंटिटी के बीच अंतर स्पष्ट करके, संबंध नोटेशन को विभाजित करके और विशेषता वर्गीकरण का विश्लेषण करके, हम त्रुटियों को कम कर सकते हैं और यह सुनिश्चित कर सकते हैं कि परिणामी डेटा मॉडल संचालन आवश्यकताओं का सही प्रतिनिधित्व करता है।
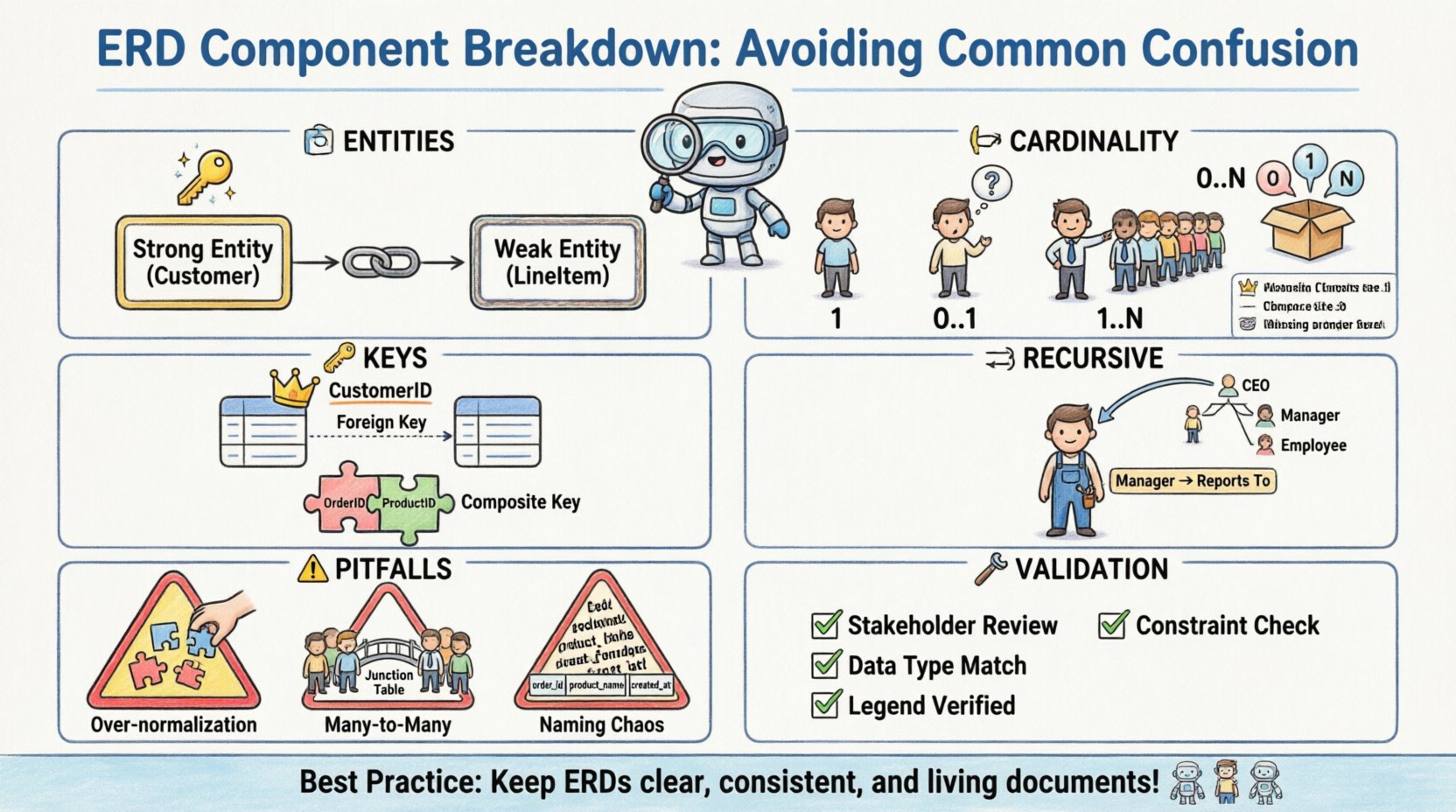
🏗️ एंटिटी प्रकार: मजबूत और कमजोर के बीच अंतर स्पष्ट करना
किसी भी ERD के केंद्र में एंटिटी होती हैं। ये उन वस्तुओं या अवधारणाओं का प्रतिनिधित्व करती हैं जिनके बारे में डेटा संग्रहीत किया जाता है। जबकि अधिकांश व्यवसायिक व्यक्ति टेबल की अवधारणा को समझते हैं, मजबूत और कमजोर एंटिटी के बीच अंतर वह बिंदु है जहां पहली बड़ी भ्रम की संभावना अक्सर होती है।
- मजबूत एंटिटी: इन एंटिटी में अपना ही प्राथमिक कुंजी होती है। वे स्वतंत्र होती हैं और पहचान के लिए अन्य एंटिटी पर निर्भर नहीं होती हैं। उदाहरण के लिए, एक
ग्राहकएंटिटी के पास आमतौर पर एक अद्वितीय ग्राहक ID होता है, जिससे यह एक मजबूत एंटिटी बन जाती है। - कमजोर एंटिटी: इन एंटिटी को अपने विशेषताओं के आधार पर अकेले अद्वितीय रूप से पहचान नहीं किया जा सकता है। वे एक अन्य एंटिटी के साथ संबंध पर निर्भर होती हैं, जिसे पहचान वाला माता-पिता कहा जाता है, ताकि वे अस्तित्व में रह सकें। एक
लाइनआइटमऑर्डर प्रणाली में केवल एक विशिष्टऑर्डर.
भ्रम अक्सर इनके दृश्य प्रतिनिधित्व के तरीके से उत्पन्न होता है। एक मजबूत एंटिटी को आमतौर पर एक मानक आयत के रूप में खींचा जाता है। एक कमजोर एंटिटी को अक्सर डबल आयत के रूप में दर्शाया जाता है। इनके दृश्य रूप से अंतर न करने के कारण डेटाबेस कार्यान्वयन में त्रुटियां हो सकती हैं, जहां कमजोर एंटिटी की टेबल को आवश्यक विदेशी कुंजी प्रतिबंधों के बिना बनाया जाता है जो इसके निर्भरता को सुनिश्चित करते हैं।
गलत वर्गीकरण के प्रभाव
जब एक कमजोर एंटिटी को मजबूत के रूप में मॉडल किया जाता है, तो डेटाबेस में माता-पिता के बिना रिकॉर्ड के अस्तित्व की अनुमति दे सकता है। इससे अनाथ डेटा बनता है। विपरीत रूप से, एक मजबूत एंटिटी को कमजोर के रूप में मॉडल करने से अनावश्यक निर्भरता बनती है, जिससे एंटिटी की उपयोगिता उसके मुख्य संदर्भ के बाहर सीमित हो सकती है। एक वस्तु के स्वतंत्र रूप से अस्तित्व में होने की संभावना को निर्धारित करना महत्वपूर्ण है जब उसे मजबूत एंटिटी का दर्जा दिया जाता है।
- स्वतंत्रता जांच: क्या इस रिकॉर्ड का दूसरे रिकॉर्ड से जुड़े बिना अस्तित्व हो सकता है?
- पहचानकर्ता स्रोत: क्या अद्वितीय ID एंटिटी स्वयं से आता है या संबंध से?
- अस्तित्व निर्भरता: क्या माता-पिता को हटाने से बच्चे को स्वचालित रूप से हटा दिया जाता है?
🔗 संबंध कार्डिनैलिटी और वैकल्पिकता
संबंध एंटिटी के बीच बातचीत के तरीके को परिभाषित करते हैं। कार्डिनैलिटी एक एंटिटी के उन उदाहरणों की संख्या निर्दिष्ट करती है जो दूसरी एंटिटी के प्रत्येक उदाहरण के साथ जुड़ सकते हैं या जुड़ने चाहिए। यह विभिन्न नोटेशन शैलियों के कारण सबसे आम भ्रम का क्षेत्र हो सकता है।
कार्डिनैलिटी नोटेशन
आरेख पर कार्डिनैलिटी को निरूपित करने के कई तरीके हैं। कुछ लेबल जैसे “1” या “N” का उपयोग करते हैं, जबकि अन्य क्राउ के फुट नोटेशन का उपयोग करते हैं। इन शैलियों को मिलाना या प्रतीकों के गलत अर्थ निकालना भौतिक स्कीमा में तार्किक अंतराल पैदा करता है।
| प्रतीक / लेबल | अर्थ | उदाहरण परिदृश्य |
|---|---|---|
| 1 | बिल्कुल एक | एक व्यक्ति के पास बिल्कुल एक सोशल सिक्योरिटी नंबर होता है। |
| 0..1 | शून्य या एक | एक व्यक्ति के पास शून्य या एक मध्य नाम हो सकता है। |
| 1..1 | एक और केवल एक | एक परियोजना में नियुक्त एक परियोजना प्रबंधक होना चाहिए। |
| 0..N | शून्य से बहुत सारे | एक आदेश में शून्य या बहुत सारे लाइन आइटम हो सकते हैं। |
| 1..N | एक से बहुत सारे | एक विभाग में एक या अधिक कर्मचारी होने चाहिए। |
वैकल्पिकता और नॉल अनुमति
वैकल्पिकता यह बताती है कि क्या संबंध अनिवार्य है या वैकल्पिक है। इसका सीधे तौर पर डेटाबेस तालिका में विदेशी कुंजी परिभाषा पर प्रभाव पड़ता है। यदि संबंध अनिवार्य है, तो विदेशी कुंजी कॉलम खाली नहीं हो सकता है। यदि वैकल्पिक है, तो यह खाली हो सकता है।
आलेख में ठोस रेखा बनाम बिंदीदार रेखा दिखाने पर अक्सर भ्रम पैदा होता है। स्पष्ट लेजेंड के बिना, डेवलपर्स ऐसे अनिवार्य संबंधों को मान लेते हैं जो वास्तव में नहीं होते हैं, जिससे डेटा दर्ज करते समय नियम उल्लंघन होता है। मॉडल दस्तावेज़ीकरण के भीतर रेखा शैलियों के अर्थ को स्पष्ट रूप से दर्ज करना आवश्यक है।
- अनिवार्य संबंध: बच्चे के रिकॉर्ड का अस्तित्व होना चाहिए ताकि माता-पिता का रिकॉर्ड वैध हो।
- वैकल्पिक संबंध: बच्चे के रिकॉर्ड को माता-पिता के बिना बनाया जा सकता है, या माता-पिता का अस्तित्व बच्चे के बिना भी हो सकता है।
- विदेशी कुंजी सीमा: को सेट किया जाना चाहिए
खाली नहींअनिवार्य के लिए,खालीवैकल्पिक के लिए अनुमति है।
🔑 विशेषताएँ और कुंजी पहचान
एट्रिब्यूट एक एंटिटी के गुण हैं। जैसा कि यह दिखता है कि बहुत सरल है, लेकिन एट्रिब्यूट को कीज़, फॉरेन कीज़ और सिंपल एट्रिब्यूट में वर्गीकृत करने से नॉर्मलाइजेशन और क्वेरी प्रदर्शन में अक्सर त्रुटियाँ होती हैं।
प्राइमरी बनाम फॉरेन कीज़
प्राइमरी की (PK) एक पंक्ति की अद्वितीय पहचान करती है। फॉरेन की (FK) एक पंक्ति को एक मातृ तालिका से जोड़ती है। जब प्राकृतिक कीज़ के स्थान पर सरोगेट कीज़ का उपयोग किया जाता है, या जब PK आरेख में एक समान तरीके से परिभाषित नहीं की जाती है, तो भ्रम उत्पन्न होता है।
- प्राकृतिक की: एक की जो डेटा में प्राकृतिक रूप से मौजूद होती है, जैसे सोशल सिक्योरिटी नंबर या ईमेल पता। इन्हें बदला जा सकता है, जिससे इंटीग्रिटी के मुद्दे उत्पन्न हो सकते हैं।
- सरोगेट की: एक कृत्रिम की जो सिस्टम द्वारा उत्पन्न की जाती है, जैसे ऑटो-इनक्रीमेंट इंटीजर। इन्हें स्थिरता के लिए आमतौर पर प्राथमिकता दी जाती है।
कॉम्पोजिट कीज़
एक कॉम्पोजिट की दो या अधिक कॉलम्स के समूह से बनती है जो मिलकर एक रिकॉर्ड की अद्वितीय पहचान करती है। यह बहु-से-बहु संबंधों को हल करने के लिए उपयोग किए जाने वाले जंक्शन तालिकाओं में सामान्य है। यहाँ भ्रम का कारण कॉलम्स के क्रम और वह तालिका है जो की को रखती है।
यदि कॉम्पोजिट की में कॉलम्स के क्रम को संबंधित तालिकाओं में एक समान रूप से बनाए रखा नहीं जाता है, तो जॉइन विफल हो जाएंगे या जटिल कास्टिंग की आवश्यकता होगी। प्राइमरी की परिभाषा में निर्दिष्ट कॉलम क्रम को दस्तावेज़ करना बहुत महत्वपूर्ण है।
🔁 रिकर्सिव संबंध
एक रिकर्सिव संबंध तब होता है जब एक एंटिटी खुद से संबंधित होती है। यह आयोग्राफिक चार्ट या बिल ऑफ मेटेरियल जैसी आर्थिक संरचनाओं के लिए अक्सर उपयोग किया जाता है। भ्रम दृश्य प्रस्तुतीकरण से उत्पन्न होता है, क्योंकि रेखा एंटिटी को खुद से जोड़ती है।
स्पष्ट लेबलिंग के बिना, अक्सर यह स्पष्ट नहीं होता है कि संबंध के किस पक्ष का प्रतिनिधित्व माता-पिता के रूप में और किस पक्ष का बच्चे के रूप में किया जाता है। उदाहरण के लिए, एक एम्प्लॉयी तालिका में, एक कर्मचारी दूसरे को प्रबंधित करता है। संबंध को स्पष्ट रूप से बताना चाहिए कि एक एम्प्लॉयी अन्य एम्प्लॉयी के मैनेजर हो सकता है।
- सेल्फ-रेफरेंस: तालिका में फॉरेन की उसी तालिका की प्राइमरी की की ओर इशारा करती है।
- नल हैंडलिंग: हायरार्की के रूट में आमतौर पर मैनेजर आईडी कॉलम में नल मान होता है।
- गहराई सीमाएँ: यदि हायरार्की बहुत गहरी है, तो रिकर्सिव क्वेरी प्रदर्शन के बॉटलनेक्स बन सकती हैं।
⚠️ सामान्य मॉडलिंग के फॉल्ट
विशिष्ट तत्वों के अलावा, कुछ संरचनात्मक पैटर्न आमतौर पर कार्यान्वयन के दौरान भ्रम उत्पन्न करते हैं। इन फॉल्ट को जल्दी से पहचानने से महंगे स्कीमा माइग्रेशन से बचा जा सकता है।
1. ओवर-नॉर्मलाइजेशन
जबकि नॉर्मलाइजेशन अतिरेक को कम करता है, ओवर-नॉर्मलाइजेशन क्वेरी को पढ़ने और निष्पादित करने में कठिनाई पैदा कर सकता है। प्रत्येक अलग-अलग एट्रिब्यूट के लिए अलग तालिका बनाना डेटा को अनावश्यक रूप से फ्रैगमेंट कर सकता है। तृतीय नॉर्मल फॉर्म (3NF) को व्यावहारिक क्वेरी प्रदर्शन के साथ संतुलित रखना महत्वपूर्ण है।
2. जंक्शन तालिकाओं के बिना बहु-से-बहु
एक भौतिक डेटाबेस में, बहु-से-बहु संबंध सीधे नहीं हो सकता है। इसे जंक्शन तालिका (सह-संबंधित एंटिटी) के उपयोग से दो एक-से-बहु संबंधों में बदलना होगा। इस चरण को भूलने से एक मॉडल बनता है जिसे स्टैंडर्ड SQL में लागू नहीं किया जा सकता है।
- लॉजिकल बनाम फिजिकल: लॉजिकल मॉडल में दो एंटिटी के बीच एक सीधी रेखा दिखा सकता है जिसकी कार्डिनैलिटी N:N है।
- फिजिकल इम्प्लीमेंटेशन: इस रेखा को एक नई तालिका द्वारा विभाजित किया जाना चाहिए जिसमें दोनों ओरों की फॉरेन कीज़ हों।
3. असंगत नामकरण प्रणाली
मिश्रित नामकरण शैलियों का उपयोग करना (उदाहरण के लिए, ग्राहक_आईडी बनाम ग्राहकआईडी बनाम ग्राहकआईडी) डेवलपर्स के लिए प्रश्न लिखते समय भ्रम पैदा करता है। प्रोजेक्ट के शुरू में एक मानक नामकरण पद्धति बनाई जानी चाहिए।
- निचले अक्षरों के साथ अंडरस्कोर:
आर्डर_लाइन_आइटम्स - पैस्कलकेस:
आर्डरलाइनआइटम्स - कैमलकेस:
आर्डरलाइनआइटम्स
🛠️ सत्यापन रणनीतियाँ
ERD को सटीक और उपयोगी बनाए रखने के लिए, समीक्षा प्रक्रिया के दौरान विशिष्ट सत्यापन चरण लिए जाने चाहिए। इन चरणों में बाद में स्कीमा बंद होने से पहले भ्रम के बिंदुओं को पकड़ने में मदद मिलती है।
- हितधारकों के साथ चलचित्र: व्यवसाय उपयोगकर्ताओं के साथ आरेख की समीक्षा करें ताकि संबंध उनके प्रवाह के मानसिक मॉडल के अनुरूप हों।
- प्रतिबंध सत्यापन: जांचें कि प्रत्येक विदेशी कुंजी के लिए संबंधित मुख्य कुंजी संदर्भ हो।
- डेटा प्रकार सुसंगतता: सुनिश्चित करें कि एक तालिका में पूर्णांक के रूप में परिभाषित विशेषताएं दूसरी तालिका में स्ट्रिंग के रूप में परिभाषित नहीं हैं।
- प्रतीक संगतता: सुनिश्चित करें कि आरेख में उपयोग किए गए सभी प्रतीक प्रदान किए गए प्रतीक सूची या मानक के अनुरूप हैं।
📝 बेस्ट प्रैक्टिसेज का सारांश
एक एंटिटी रिलेशनशिप आरेख में स्पष्टता बनाए रखने के लिए अनुशासन की आवश्यकता होती है। मानक नोटेशन का पालन करने, कार्डिनैलिटी को स्पष्ट रूप से परिभाषित करने और एंटिटी प्रकारों के बीच अंतर करने से गलत व्याख्या के जोखिम में काफी कमी आती है। लक्ष्य केवल एक चित्र बनाना नहीं है, बल्कि एक विनिर्माण बनाना है जो सीधे एक स्थिर, विश्वसनीय डेटाबेस प्रणाली में बदल जाए।
याद रखें कि आरेख एक जीवंत दस्तावेज है। जैसे-जैसे आवश्यकताएं बदलती हैं, ERD को उन बदलावों को दर्शाने के लिए अपडेट किया जाना चाहिए। इससे यह सुनिश्चित होता है कि डेटा मॉडल समय के साथ व्यवसाय की सटीक आवश्यकताओं को पूरा करता रहे। नियमित समीक्षा और इस लेख में बताई गई संरचनात्मक दिशानिर्देशों का पालन करने से टीमों को डेटाबेस प्रोजेक्ट को विफल करने वाली आम गलतियों से बचने में मदद मिलेगी।